Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Patrones de saga que se encadenan rápidamente
Al reinventar el encadenamiento rápido de LLM como una saga basada en eventos, descubrimos un nuevo modelo operativo: los flujos de trabajo se distribuyen, se pueden recuperar y coordinar semánticamente entre agentes autónomos. Cada paso de respuesta rápida se reformula como una tarea atómica, se emite como un evento, lo consume un agente especializado y se enriquece con metadatos contextuales.
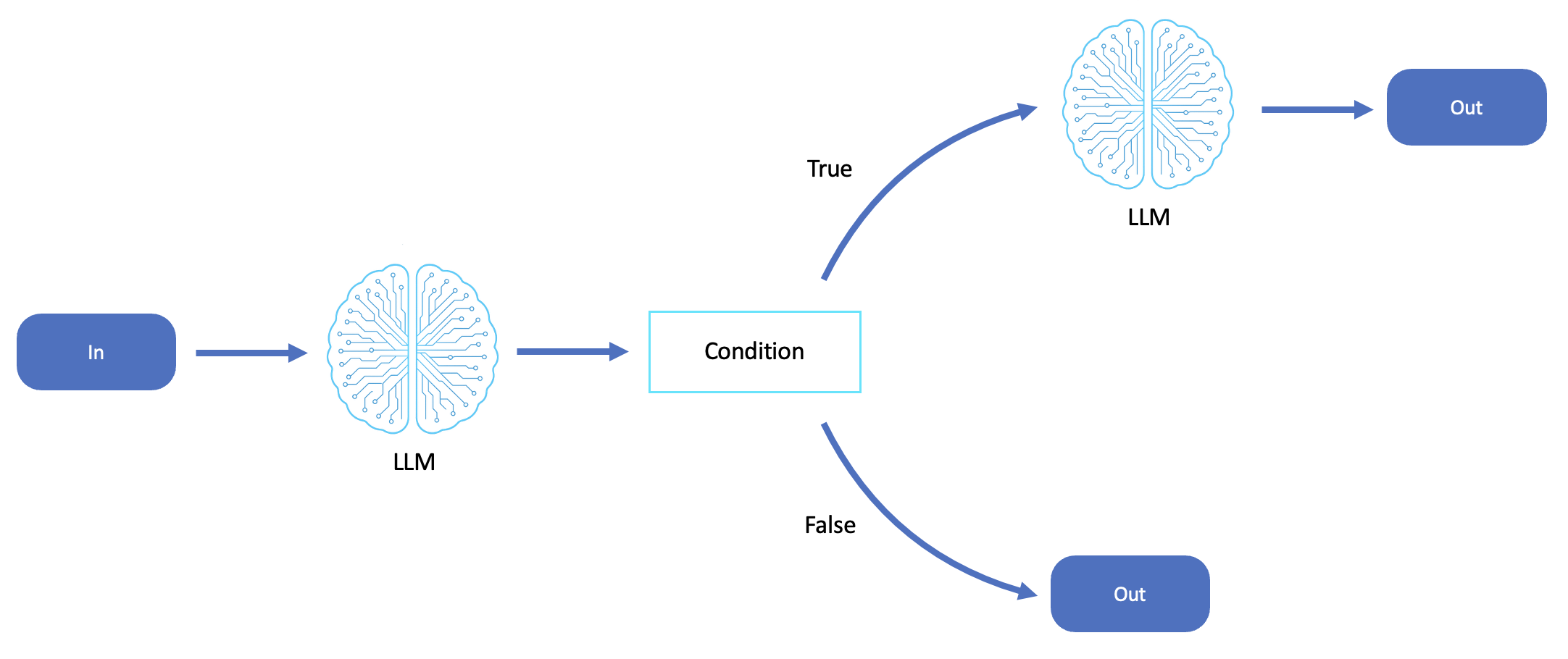
El siguiente diagrama es un ejemplo de encadenamiento de mensajes LLM:
Coreografía de la saga
El patrón coreográfico de la saga es un enfoque de implementación en sistemas distribuidos que no tiene un coordinador central. En su lugar, cada servicio o componente publica eventos que desencadenan la siguiente acción del flujo de trabajo. Este patrón se utiliza ampliamente en los sistemas distribuidos para gestionar las transacciones en varios servicios. En una saga, el sistema ejecuta una serie de transacciones locales coordinadas. Si una falla, el sistema activa acciones compensatorias para mantener la coherencia.
El siguiente diagrama es un ejemplo de coreografía de una saga:
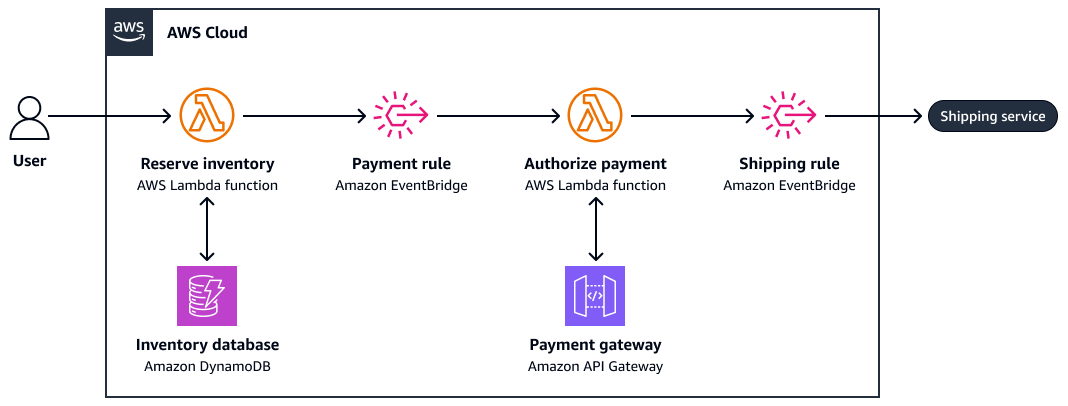
-
Inventario de reserva
-
Autoriza el pago
-
Crea una orden de envío
Si el paso 3 no funciona, el sistema invoca acciones compensatorias (por ejemplo, cancelar un pago o liberar el inventario).
Este patrón es especialmente valioso en las arquitecturas basadas en eventos, en las que los servicios están poco acoplados y los estados deben resolverse de forma coherente a lo largo del tiempo, incluso en caso de que se produzca un fallo parcial.
Patrón de encadenamiento rápido
El encadenamiento rápido se parece al patrón de la saga tanto en estructura como en propósito. Ejecuta una serie de pasos de razonamiento que se desarrollan de forma secuencial, preservando el contexto y permitiendo retrocesos y revisiones.
Coreografía de agentes
-
LLM interpreta una consulta de usuario compleja y genera una hipótesis
-
LLM elabora un plan para resolver la tarea
-
LLM ejecuta una subtarea (por ejemplo, mediante una llamada a una herramienta o recuperando conocimientos)
-
El LLM refina el resultado o retoma un paso anterior si considera que el resultado no es satisfactorio
Si un resultado intermedio es defectuoso, el sistema puede realizar una de las siguientes acciones:
-
Vuelva a intentar los pasos con un enfoque diferente
-
Vuelva a la solicitud anterior y vuelva a planificar
-
Utilice un bucle de evaluación (por ejemplo, del patrón evaluador-optimizador) para detectar y corregir los errores
Al igual que el patrón de las sagas, el encadenamiento rápido permite avanzar parcialmente y retroceder. Esto ocurre mediante un refinamiento iterativo y una corrección dirigida por la LLM, en lugar de compensar las transacciones de la base de datos.
El siguiente diagrama es un ejemplo de coreografía de agentes:
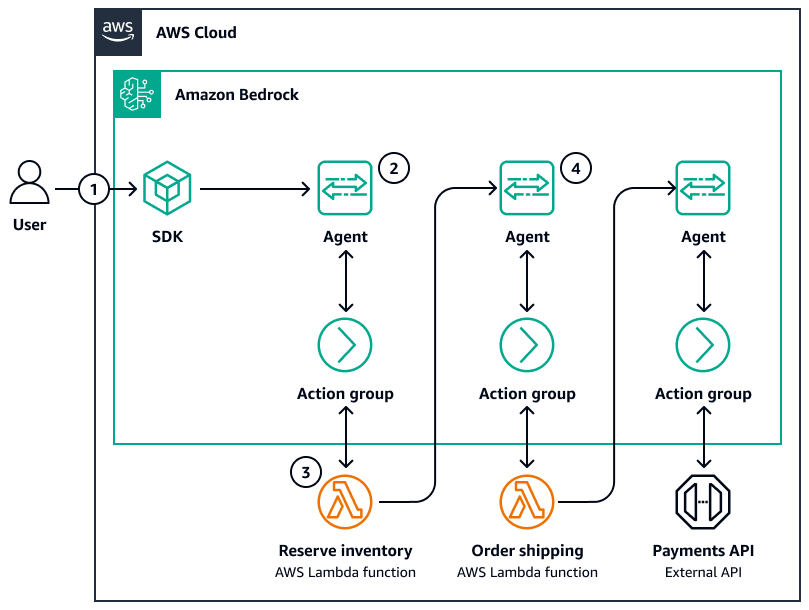
-
Un usuario envía una consulta a través de un SDK.
-
Un agente de Amazon Bedrock organiza el razonamiento de la siguiente manera:
-
Interpretación (LLM)
-
Planificación (LLM)
-
Ejecución a través de una herramienta o base de conocimientos
-
Construcción de respuestas
-
-
Si una herramienta falla o no devuelve datos suficientes, el agente puede replanificar o reformular la tarea de forma dinámica.
-
La memoria (por ejemplo, un almacén vectorial a corto plazo) puede conservar su estado en todos los pasos
Conclusiones
Mientras que el patrón saga gestiona las llamadas de servicio distribuidas con una lógica de compensación, el encadenamiento rápido gestiona las tareas de razonamiento mediante una secuenciación reflexiva y una replanificación adaptativa. Ambos sistemas permiten el progreso gradual, la descentralización de los puntos de decisión y la recuperación de los fallos, y todo ello mediante un razonamiento fundamentado en lugar de una reversión rígida.
El encadenamiento rápido introduce el razonamiento transaccional, que es el equivalente cognitivo de las sagas. Es decir, cada «pensamiento» es reevaluado, revisado o abandonado como parte de un diálogo más amplio dirigido a un objetivo.
