Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Patrones de paralelización y dispersión
Muchas tareas avanzadas de razonamiento y generación, como resumir documentos de gran tamaño, evaluar múltiples rutas de solución o comparar diversas perspectivas, se benefician de la ejecución paralela de las solicitudes. Los flujos de trabajo secuenciales tradicionales son insuficientes cuando se requieren escalabilidad, capacidad de respuesta y tolerancia a errores. Para superar esta situación, la paralelización basada en la LLM puede reinventarse mediante un patrón de dispersión y recopilación basado en eventos, en el que las tareas se distribuyen dinámicamente entre agentes autónomos y los resultados se sintetizan de forma inteligente.
El siguiente diagrama es un ejemplo de un flujo de trabajo de paralelización de LLM:
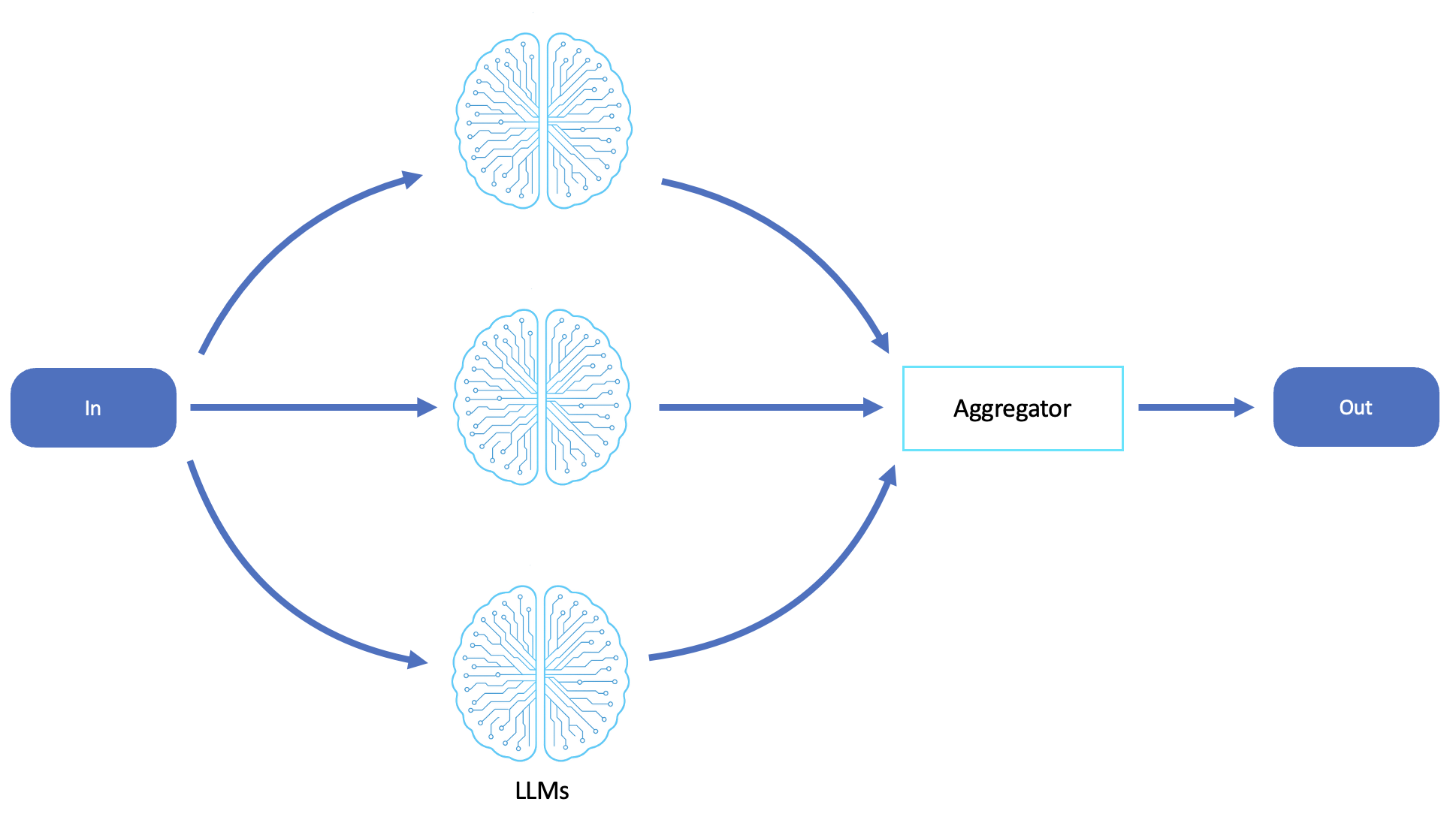
Dispersión y recopilación
En los sistemas distribuidos, un patrón de dispersión y recopilación envía las tareas a varios servicios o unidades de procesamiento en paralelo, espera sus respuestas y, a continuación, agrega los resultados en una salida consolidada. A diferencia de la dispersión, la dispersión y recolección se coordina porque espera respuestas y, por lo general, aplica la lógica para combinar, comparar y seleccionar los resultados.
Entre las implementaciones habituales de la paralelización y la recopilación de dispersión se incluyen las siguientes:
-
AWS Step Functions mapear un estado para la ejecución de tareas en paralelo
-
AWS Lambda con simultaneidad, coordinando los resultados de múltiples funciones invocadas
-
Amazon EventBridge con flujos de trabajo de correlación IDs y agregación
-
Patrón de controlador personalizado para gestionar la distribución y recopilar resultados mediante Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB o colas
El siguiente diagrama es un ejemplo de scatter-gather:
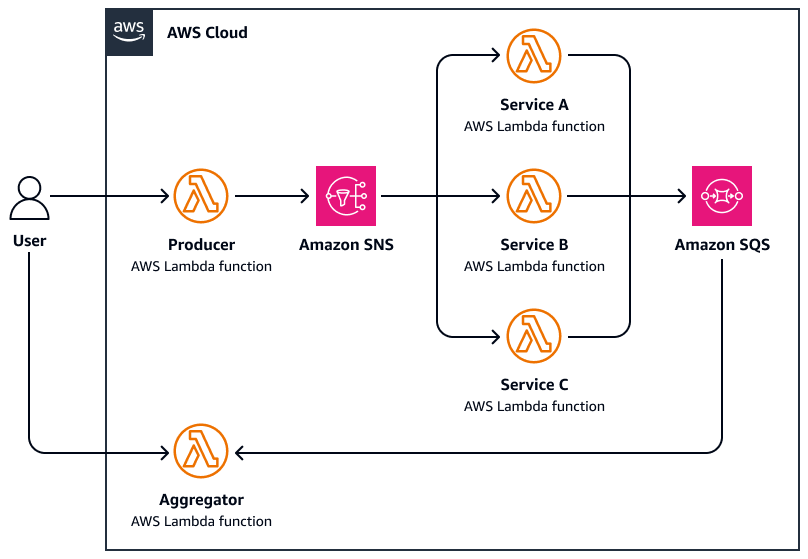
-
Un usuario envía una solicitud a una función de coordinación central que dispersa la tarea publicando mensajes paralelos en un tema del Amazon Simple Notification Service (Amazon SNS).
-
Cada mensaje incluye metadatos de la tarea y se envía a un trabajador especializado. AWS Lambda
-
Cada trabajador procesa de AWS Lambda forma independiente la subtarea asignada (por ejemplo, consulta una API externa, procesa un documento y analiza datos).
-
Los resultados se escriben en una capa de almacenamiento común, como Amazon Simple Queue Service (Amazon SQS).
-
La función de agregación espera a que se completen todas las respuestas y, a continuación, hace lo siguiente:
-
Recopila y agrega los resultados (por ejemplo, combina resúmenes y selecciona las mejores coincidencias)
-
Envía una respuesta final o desencadena un flujo de trabajo posterior
-
Los casos de uso más comunes de los patrones de dispersión y recolección incluyen los siguientes:
-
Búsqueda federada
-
Motores de comparación de precios
-
Análisis de datos agregados
-
Inferencia multimodelo
Paralelización basada en LLM (cognición dispersa-recopilada)
En los sistemas agenciales, la paralelización refleja de cerca la dispersión y la recopilación mediante la distribución de las subtareas entre varios agentes o llamadas de LLM, cada uno de los cuales analiza de forma independiente una parte del problema. Los resultados devueltos se recopilan y sintetizan mediante un proceso de agregación, que suele ser otro LLM o agente controlador.
Paralelización de agentes
-
Un agente envía una solicitud para «Resumir la información recopilada en estos 10 informes».
-
Distribuye los informes en 10 tareas de resumen LLM paralelas.
-
Cuando devuelve todos los resúmenes, el agente hace lo siguiente:
-
Reúne los resúmenes en un resumen unificado
-
Identifica temas o contradicciones
-
Envía la salida sintetizada al usuario
-
Este flujo de trabajo de agencia permite un razonamiento paralelo escalable, modular y adaptativo. Esto es ideal para casos de uso que requieren un alto rendimiento cognitivo.
El siguiente diagrama es un ejemplo de paralelización de agentes:
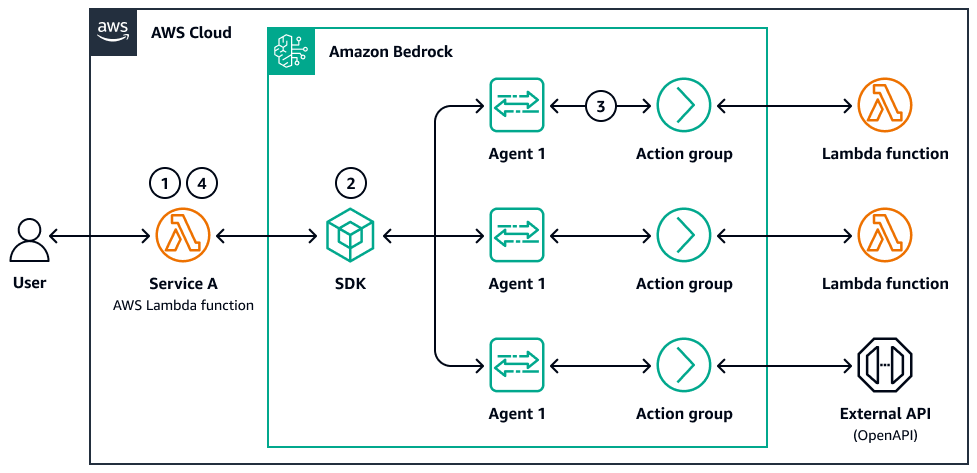
-
Un usuario envía una consulta o un conjunto de documentos de varias partes.
-
Un controlador AWS Lambda o una función escalonada distribuye las subtareas. Cada tarea invoca una llamada o un subagente de Amazon Bedrock LLM con su propio mensaje.
-
Cuando se completan las llamadas y las subtareas, los resultados se almacenan (por ejemplo, en Amazon S3 o en un almacén de memoria) y un paso de agregación fusiona, compara o filtra los resultados.
-
El sistema devuelve la respuesta final al usuario o al agente intermedio.
Este sistema tiene un circuito de razonamiento distribuido con trazabilidad, tolerancia a errores y lógica opcional de ponderación o selección de resultados.
Conclusiones
La paralelización de agentes utiliza patrones de dispersión y recolección para distribuir las tareas de LLM, lo que permite el procesamiento paralelo y la síntesis inteligente de resultados.
