Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Agentes de razonamiento básicos
Un agente de razonamiento básico es la forma más simple de inteligencia artificial que realiza inferencias lógicas o toma de decisiones en respuesta a una consulta. Acepta la información de un usuario o un sistema y procesa las consultas y genera respuestas mediante indicaciones estructuradas.
Este patrón es útil para las tareas que requieren un razonamiento, una clasificación o un resumen en un solo paso en función de un contexto determinado. No usa memoria, herramientas ni administración de estados, lo que lo hace sin estado, liviano y altamente componible en grandes flujos de trabajo.
Arquitectura
El flujo de un agente de razonamiento básico se muestra en el siguiente diagrama:
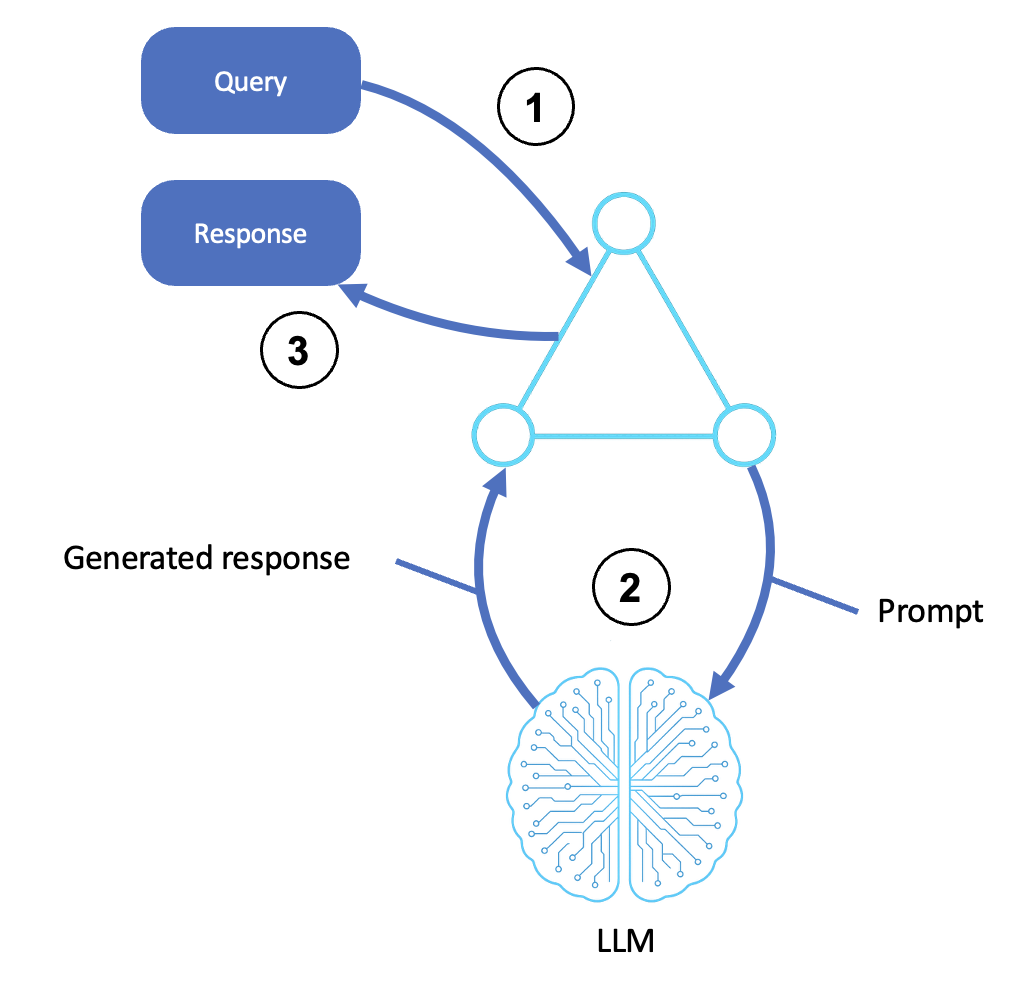
Description (Descripción)
-
Recibe una entrada
-
Un usuario, un sistema o un agente principal envía una consulta o instrucción.
-
La entrada se transfiere al shell del agente o a la capa de orquestación.
-
Este paso incluye el preprocesamiento, la creación rápida de plantillas y la identificación de los objetivos.
-
-
Invoca el LLM
-
El agente transforma la consulta en una solicitud estructurada y la envía a un LLM (por ejemplo, a través de Amazon Bedrock).
-
El LLM genera una respuesta basada en el mensaje utilizando el conocimiento y el contexto previamente entrenados.
-
El resultado generado puede incluir pasos de razonamiento (cadena de pensamiento), respuestas finales u opciones clasificadas.
-
-
Devuelve una respuesta
-
El resultado generado se retransmite a la interfaz del agente.
-
Esto puede incluir el formateo, el posprocesamiento o una respuesta de la API.
-
Capacidades
-
Admite lenguaje natural o entrada estructurada
-
Utiliza una ingeniería rápida para guiar el comportamiento
-
Sin estado y escalable
-
Se puede integrar en la interfaz de usuario, la CLI, las API y las canalizaciones
Limitaciones
-
Sin memoria ni conocimiento histórico
-
Sin interacción con herramientas o fuentes de datos externas
-
Limitado a lo que el LLM sabe en el momento de la inferencia
Casos de uso comunes
-
Preguntas y respuestas conversacionales
-
Explicaciones y resúmenes de las políticas
-
Guía para la toma de decisiones
-
Flujos de chatbots ligeros y automatizados
-
Clasificación, etiquetado y puntuación
Guía para la implementación
Puede utilizar las siguientes herramientas y servicios para crear un agente de razonamiento básico:
-
Amazon Bedrock para la invocación de LLM (Anthropic, AI21, Meta)
-
Amazon API Gateway o AWS Lambda para exponerlo como un microservicio sin estado
-
Plantillas de solicitudes almacenadas en el almacén de parámetros o como código AWS Secrets Manager
Resumen
El agente de razonamiento básico es fundamental debido a su estructura simple. Tiene capacidades básicas que convierten los objetivos en vías de razonamiento que conducen a resultados inteligentes. Este patrón suele ser un punto de partida para patrones avanzados, como los agentes basados en herramientas y los agentes que utilizan la generación aumentada por recuperación (RAG). También es un componente fiable y modular de grandes flujos de trabajo.
Agente RAG
Retrieval-augmented La generación (RAG) es una técnica que combina la recuperación de información con la generación de texto para crear respuestas precisas y contextuales. El RAG permite a los agentes recuperar información externa relevante antes de contratar el LLM. Amplía la memoria efectiva y la precisión del razonamiento de un agente al basar sus decisiones en información actualizada, fáctica o específica de un dominio. A diferencia de los LLM apátridas, que se basan únicamente en pesas previamente entrenadas, RAG tiene una capa de búsqueda de conocimientos externa que mejora de forma dinámica las solicitudes en función del contexto.
Arquitectura
La lógica del patrón RAG se ilustra en el siguiente diagrama:
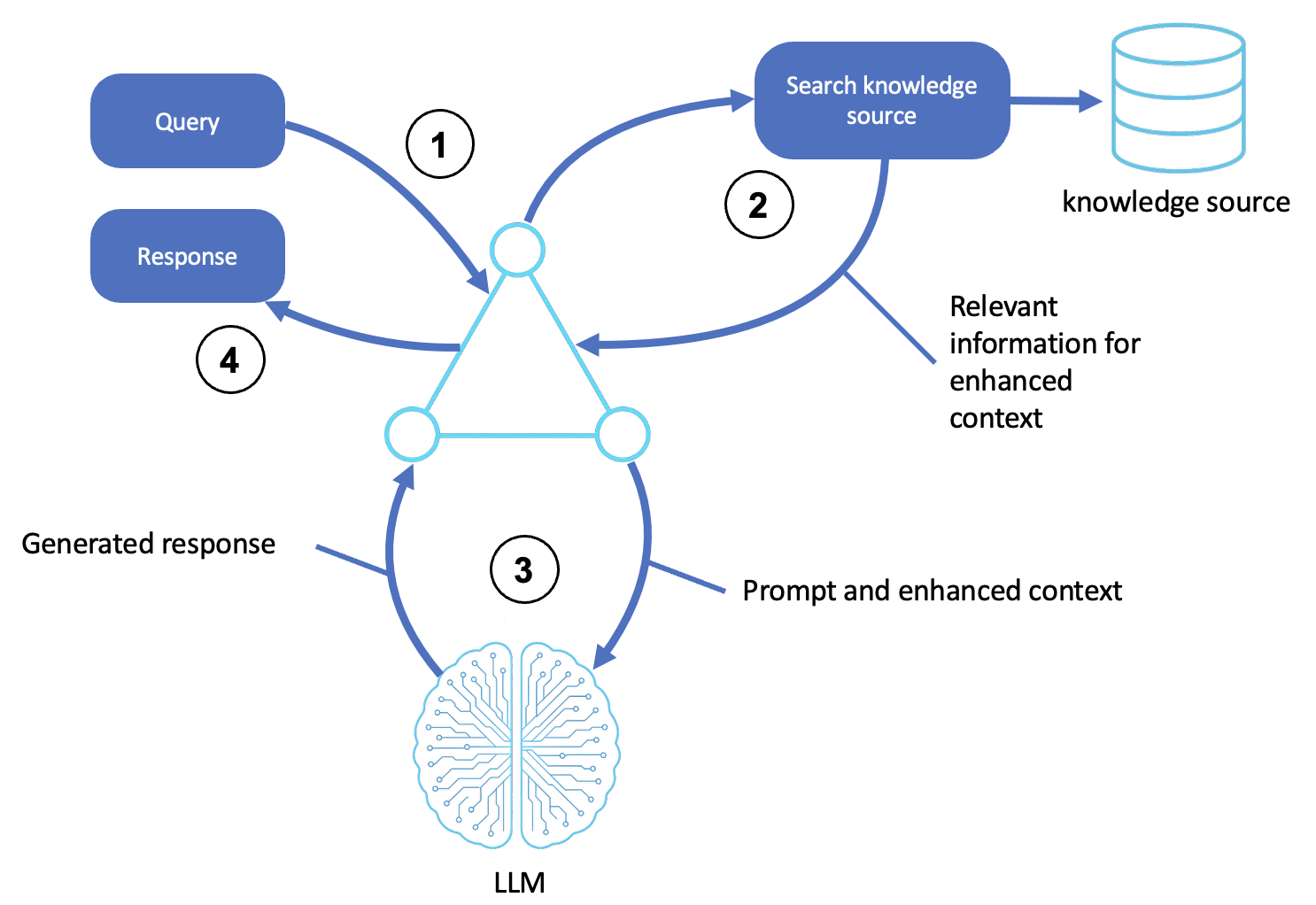
Description (Descripción)
-
Recibe una consulta
-
Un usuario o un sistema anterior envía una consulta o un objetivo al agente.
-
El intérprete de comandos acepta la solicitud y la formatea como una solicitud de razonamiento.
-
-
Busca una fuente externa
-
El agente identifica los conceptos y la intención a partir de la consulta.
-
Consulta una fuente de conocimiento, como un almacén vectorial, una base de datos o un índice de documentos, mediante la búsqueda semántica o la coincidencia de palabras clave.
-
Los pasajes, documentos o entidades más relevantes se recuperan para usarlos en el siguiente paso.
-
-
Genera una respuesta contextual
-
El agente amplía el mensaje con la información recuperada, lo que constituye una entrada mejorada por el contexto para el LLM.
-
El LLM procesa cualquier entrada mediante el razonamiento generativo (por ejemplo, una cadena de pensamiento o una reflexión) para producir una respuesta precisa.
-
-
Devuelve el resultado final
-
El agente prepara el resultado envolviéndolo en cualquier encabezado de comunicación o en el formato requerido y, a continuación, lo devuelve al usuario o al sistema de llamada.
-
(Opcional) Los documentos recuperados y la salida de LLM se pueden registrar, calificar y almacenar en la memoria para futuras consultas.
-
Capacidades
-
Fact-grounded generan resultados incluso en dominios de larga duración o específicos de la empresa
-
Ampliación de la memoria sin ajustar el modelo
-
Contexto dinámico basado en cada consulta y estado de usuario
-
Totalmente compatible con bases de datos vectoriales, índices semánticos y filtrado de metadatos
Casos de uso comunes
-
Asistentes de conocimiento empresarial
-
Bots de cumplimiento normativo
-
Copilotos de atención al cliente
-
Search-enhanced chatbots
-
Agentes de documentación para desarrolladores
Guía para la implementación
Utilice las siguientes herramientas y servicios para crear un agente que utilice RAG:
-
Amazon Bedrock para la invocación de LLM
-
Amazon Kendra o Amazon Aurora para documentación o una búsqueda estructurada de datos OpenSearch
-
Amazon Simple Storage Service (Amazon S3) para almacenamiento de documentos
-
AWS Lambda para organizar la búsqueda, la solicitud y la inferencia de LLM
-
Knowledge-based integraciones con agentes (mediante complementos de memoria, recuperadores semánticos o Amazon Bedrock)
Resumen
El agente RAG conecta el razonamiento de modelos estáticos con la inteligencia dinámica del mundo real. Proporciona a los agentes la capacidad de buscar lo que no saben, sintetizar las respuestas a partir del conocimiento recuperado y producir respuestas auditables y de alta confianza.
Los patrones RAG son la base para crear agentes inteligentes que amplíen el acceso al conocimiento sin necesidad de volver a capacitarse. Suele ser un precursor de patrones de orquestación más complejos que implican el uso de herramientas, la planificación y la memoria a largo plazo.
