Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Tutorial: Ingerir datos en una colección mediante Amazon OpenSearch Ingestion
En este tutorial, se muestra cómo utilizar Amazon OpenSearch Ingestion para configurar una canalización sencilla e ingerir datos en una colección de Amazon OpenSearch Serverless. Una canalización es un recurso que OpenSearch Ingestion aprovisiona y administra. Puede usar una canalización para filtrar, enriquecer, transformar, normalizar y agregar datos para el análisis y la visualización posteriores en OpenSearch Service.
Para ver un tutorial que muestra cómo incorporar datos en un dominio de OpenSearch servicio aprovisionado, consulte. Tutorial: Ingerir datos en un dominio mediante Amazon OpenSearch Ingestion
En este tutorial, deberá completar los siguientes pasos:
En este tutorial creará los recursos siguientes:
-
Una colección llamada
ingestion-collectiondonde escribirá la canalización -
Una canalización llamada
ingestion-pipeline-serverless
Permisos necesarios
Para completar este tutorial, su usuario o rol debe tener una política basada en identidad adjunta con los siguientes permisos mínimos. Estos permisos le permiten crear un rol de canalización y adjuntar una política (iam:Create* y iam:Attach*), crear o modificar una colección (aoss:*) y trabajar con canalizaciones (osis:*).
Además, se requieren varios permisos de IAM para crear automáticamente la función de canalización y pasarla a OpenSearch Ingestion para que pueda escribir datos en la colección.
Paso 1: Crear una colección
A continuación, cree una colección para incorporar datos. El nombre que le pondremos a la colección será ingestion-collection.
-
Ve a la consola OpenSearch de Amazon Service en https://console.aws.amazon.com/aos/home
. -
Seleccione Colecciones del panel de navegación de la izquierda y elija Crear colección.
-
En el campo Generación sin servidor, selecciona Cambiar a versión clásica.
-
Nombre la colección ingestion-collection.
-
En Seguridad, elija Creación estándar.
-
En Configuración de acceso a la red, cambie el tipo de acceso a Público.
-
Mantenga todas las demás configuraciones en sus valores predeterminados y elija Siguiente.
-
Ahora, configure una política de acceso a los datos para la colección. Anule la selección de Coincidir automáticamente la configuración de la política de acceso.
-
Seleccione JSON para el Método de definición y pegue la siguiente política en el editor. Esta política realiza dos tareas:
-
Permite que el rol de canalización escriba en la colección.
-
Le permite leer de la colección. Más adelante, después de incorporar algunos datos de muestra a la canalización, consultará la colección para garantizar que los datos se hayan incorporado y escrito correctamente en el índice.
[ { "Rules": [ { "Resource": [ "index/ingestion-collection/*" ], "Permission": [ "aoss:CreateIndex", "aoss:UpdateIndex", "aoss:DescribeIndex", "aoss:ReadDocument", "aoss:WriteDocument" ], "ResourceType": "index" } ], "Principal": [ "arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole", "arn:aws:iam::your-account-id:role/Admin" ], "Description": "Rule 1" } ]
-
-
Modifique los
Principalelementos para incluir su Cuenta de AWS ID. Para la segunda entidad principal, especifique un usuario o rol que pueda utilizar para consultar la colección más tarde. -
Elija Siguiente. Nombre la política de acceso pipeline-collection-access y elija Siguiente de nuevo.
-
Revise la configuración de la colección y seleccione Enviar.
Paso 2: Crea una canalización
Ahora que tiene una colección, puede crear una canalización.
Creación de una canalización
-
En la consola de Amazon OpenSearch Service, selecciona Pipelines en el panel de navegación izquierdo.
-
Seleccione Create pipeline.
-
Seleccione la canalización en blanco y, a continuación, elija Seleccionar esquema.
-
En este tutorial, crearemos una canalización simple que utiliza el complemento de origen HTTP
. El complemento acepta datos de registro en un formato de matriz JSON. Especificaremos una única colección OpenSearch sin servidor como sumidero e incorporaremos todos los datos al índice. my_logsEn el menú Fuente, seleccione HTTP. Para la ruta, ingrese /logs.
-
Para simplificar este tutorial, configuraremos el acceso público para la canalización. En las opciones de red de origen, seleccione Acceso público. Para obtener información acerca de la configuración del acceso a VPC, consulte Configuración del acceso a la VPC para las canalizaciones de Amazon Ingestion OpenSearch.
-
Elija Siguiente.
-
En Procesador, introduzca la fecha y seleccione Agregar.
-
Habilite Desde la hora de recepción. Deje el resto de opciones con sus valores predeterminados.
-
Elija Siguiente.
-
Configure los detalles del destino. Para el tipo de OpenSearch recurso, elija Colección (sin servidor). A continuación, elija la colección de OpenSearch servicios que creó en la sección anterior.
Deje el nombre de la política de red como predeterminado. En Nombre de índice, escribe my_logs. OpenSearch Ingestión crea automáticamente este índice en la colección si aún no existe.
-
Elija Siguiente.
-
Asigne el nombre ingestion-pipeline-serverless a la canalización. Deje la configuración de capacidad con sus valores predeterminados.
-
Para el rol de canalización, seleccione Crear y usar un nuevo rol de servicio. El rol de canalización proporciona los permisos necesarios para que una canalización escriba en el destino de colección y lea desde orígenes basados en extracción. Al seleccionar esta opción, permite que OpenSearch Ingestion cree el rol por usted, en lugar de crearlo manualmente en IAM. Para obtener más información, consulte Configuración de roles y usuarios en Amazon OpenSearch Ingestion.
-
En el sufijo del nombre del rol de servicio, introduzca. PipelineRole En IAM, el rol tendrá el formato
arn:aws:iam::.your-account-id:role/OpenSearchIngestion-PipelineRole -
Elija Siguiente. Revise la configuración de la canalización y elija Crear canalización. La canalización tarda entre 5 y 10 minutos en activarse.
Paso 3: Ingiera algunos datos de muestra
Cuando el estado de la canalización sea Active, puede empezar a incorporarle datos. Debe firmar todas las solicitudes HTTP que se envíen a la canalización mediante la versión 4 de Signature. Use una herramienta HTTP como Postman
nota
La entidad principal que firma la solicitud debe tener el permiso de IAM osis:Ingest.
Primero, obtenga la URL de incorporación en la página de Configuración de canalización:
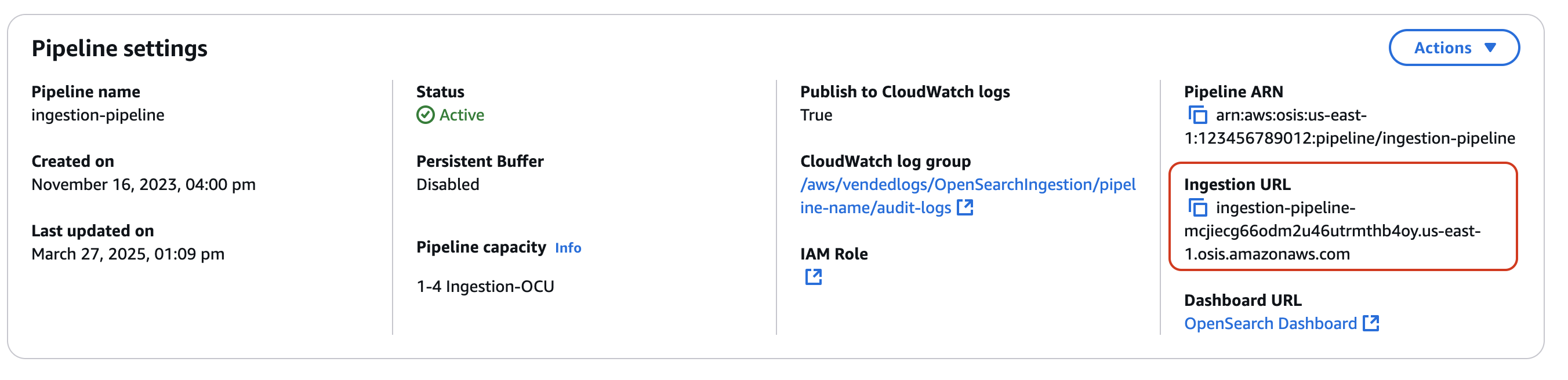
A continuación, envíe algunos datos de muestra a la ruta de ingesta. La siguiente solicitud de muestra utiliza awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
Debería ver una respuesta 200 OK.
Ahora, consulte el índice my_logs para asegurarse de que la entrada del registro se haya incorporado correctamente:
awscurl --service aoss --regionus-east-1\ -X GET \ https://collection-id.us-east-1.aoss.amazonaws.com/my_logs/_search | json_pp
Respuesta de ejemplo:
{ "took":348, "timed_out":false, "_shards":{ "total":0, "successful":0, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"my_logs", "_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2023-04-26T05:22:16.204Z" } } ] } }
Recursos relacionados
Este tutorial presenta un caso práctico sencillo de incorporación de un único documento a través de HTTP. En escenarios de producción, configurará las aplicaciones cliente (como Fluent Bit, Kubernetes o The OpenTelemetry Collector) para que envíen datos a una o más canalizaciones. Es probable que sus canalizaciones sean más complejas que en el ejemplo sencillo de este tutorial.
Para empezar a configurar sus clientes e incorporar datos, consulte los siguientes recursos:
