Técnicas de peticiones para la comprensión visual
nota
Esta documentación corresponde a la versión 1 de Amazon Nova. Para obtener información sobre cómo formular peticiones de comprensión multimodal en Amazon Nova 2, consulte Prompting multimodal inputs.
Las siguientes técnicas de peticiones visuales le ayudarán a crear mejores peticiones para Amazon Nova.
El orden importa
Le recomendamos que coloque los archivos multimedia (como imágenes o videos) antes de añadir cualquier documento y, a continuación, incluya el texto instructivo o las peticiones que sirvan de guía para el modelo. Aunque las imágenes colocadas después del texto o intercaladas con el texto seguirán funcionando adecuadamente, si el caso de uso lo permite, la estructura {media_file}-then-{text} es el enfoque preferido.
La siguiente plantilla se puede utilizar para colocar los archivos multimedia antes del texto al realizar una comprensión visual.
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
No se siguió ninguna estructura |
Petición optimizada |
|
|---|---|---|
Usuario |
Explica qué sucede en la imagen [Image1.png] |
[Image1.png] Explica qué sucede en la imagen. |
Varios archivos multimedia con componentes visuales
En situaciones en las que proporcione varios archivos multimedia en diferentes turnos, introduzca cada imagen con una etiqueta numerada. Por ejemplo, si usa dos imágenes, etiquételas con Image
1: y Image 2:. Si utiliza tres videos, etiquételos con Video
1:, Video 2: y Video 3:. No necesita líneas nuevas entre las imágenes ni entre las imágenes y la petición.
La siguiente plantilla se puede utilizar para colocar varios archivos multimedia:
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
Petición no optimizada |
Petición optimizada |
|---|---|
|
Describe lo que ves en la segunda imagen. [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] Describe lo que ves en la segunda imagen. |
|
¿Se describe la segunda imagen en el documento incluido? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] ¿Se describe la segunda imagen en el documento incluido? |
Debido a la longitud de los tokens de contexto de los tipos de archivos multimedia, es posible que, en determinadas ocasiones, no se respete la petición del sistema indicada al principio de esta. En este caso, le recomendamos que traslade las instrucciones del sistema a los turnos del usuario y siga las instrucciones generales de {media_file}-then-{text}. Esto no afecta a las peticiones del sistema relacionadas con RAG, los agentes o el uso de herramientas.
Utilice las instrucciones del usuario para mejorar el seguimiento de instrucciones en tareas de comprensión visual
Para la comprensión de video, el número de tokens en contexto hace que las recomendaciones en El orden importa sean muy importantes. Utilice la petición del sistema para cosas más generales, como el tono y el estilo. Le recomendamos que incluya las instrucciones relacionadas con el video en la petición del usuario para obtener un mejor rendimiento.
La siguiente plantilla se puede utilizar para mejorar las instrucciones:
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
Al igual que con el texto, recomendamos aplicar una cadena de pensamiento a las imágenes y los videos para mejorar el rendimiento. También recomendamos que coloque las directivas de cadena de pensamiento en el mensaje del sistema, mientras mantiene otras peticiones en el mensaje del usuario.
importante
El modelo Amazon Nova Premier es un modelo de inteligencia superior de la familia Amazon Nova, capaz de gestionar tareas más complejas. Si sus tareas requieren un pensamiento avanzado de cadena de pensamiento, le recomendamos que utilice la plantilla de peticiones que se especifica en Dele tiempo a Amazon Nova para pensar (cadena de pensamiento). Este enfoque puede ayudar a mejorar las capacidades analíticas y de resolución de problemas del modelo.
Ejemplos con pocas muestras
Al igual que con los modelos de texto, le recomendamos que proporcione ejemplos de imágenes para mejorar el rendimiento de la comprensión de imágenes (no se pueden proporcionar ejemplos de videos debido a la limitación de un solo video por inferencia). Le recomendamos que coloque los ejemplos en la petición del usuario, después del archivo multimedia, en lugar de proporcionarlos en la petición del sistema.
| 0-Shot | 2-Shot | |
|---|---|---|
| User | [Image 1] | |
| Assistant | The image 1 description | |
| User | [Image 2] | |
| Assistant | The image 2 description | |
| User | [Image 3] Explique qué sucede en la imagen. |
[Image 3] Explique qué sucede en la imagen. |
Detección del cuadro delimitador
Si necesita identificar las coordenadas del cuadro delimitador de un objeto, puede utilizar el modelo de Amazon Nova para generar cuadros delimitadores en una escala de [0, 1000). Una vez obtenidas estas coordenadas, puede redimensionarlas basándose en las dimensiones de la imagen como paso de posprocesamiento. Para obtener información más detallada sobre cómo realizar este paso de posprocesamiento, consulte el cuaderno Localización de imágenes de Amazon Nova
El siguiente es un ejemplo de petición para la detección de cuadros delimitadores:
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
Salidas o estilo más elaborados
La salida de comprensión de video puede ser muy corta. Si desea salidas más largas, le recomendamos crear una personalidad para el modelo. Puede indicarle a esta personalidad que responda de la manera que desee, de forma similar a como si utilizara el rol del sistema.
Se pueden hacer más modificaciones en las respuestas con técnicas de un paso y pocos pasos. Proporcione ejemplos de lo que debería ser una buena respuesta y el modelo podrá imitar algunos aspectos de ella mientras genera respuestas.
Extraer el contenido del documento en Markdown
Amazon Nova Premier demuestra capacidades mejoradas para comprender los gráficos integrados en los documentos y capacidad de leer y comprender el contenido de dominios complejos, como artículos científicos. Además, Amazon Nova Premier muestra un rendimiento mejorado al extraer el contenido de los documentos y puede generar esta información en los formatos de tabla Markdown y Latex.
El siguiente ejemplo proporciona una tabla en una imagen, junto con una petición para que Amazon Nova Premier convierta el contenido de la imagen en una tabla Markdown. Una vez creada la tabla Markdown (o la representación Latex), puede utilizar herramientas para convertir el contenido en JSON u otro formato de salida estructurado.
Make a table representation in Markdown of the image provided.
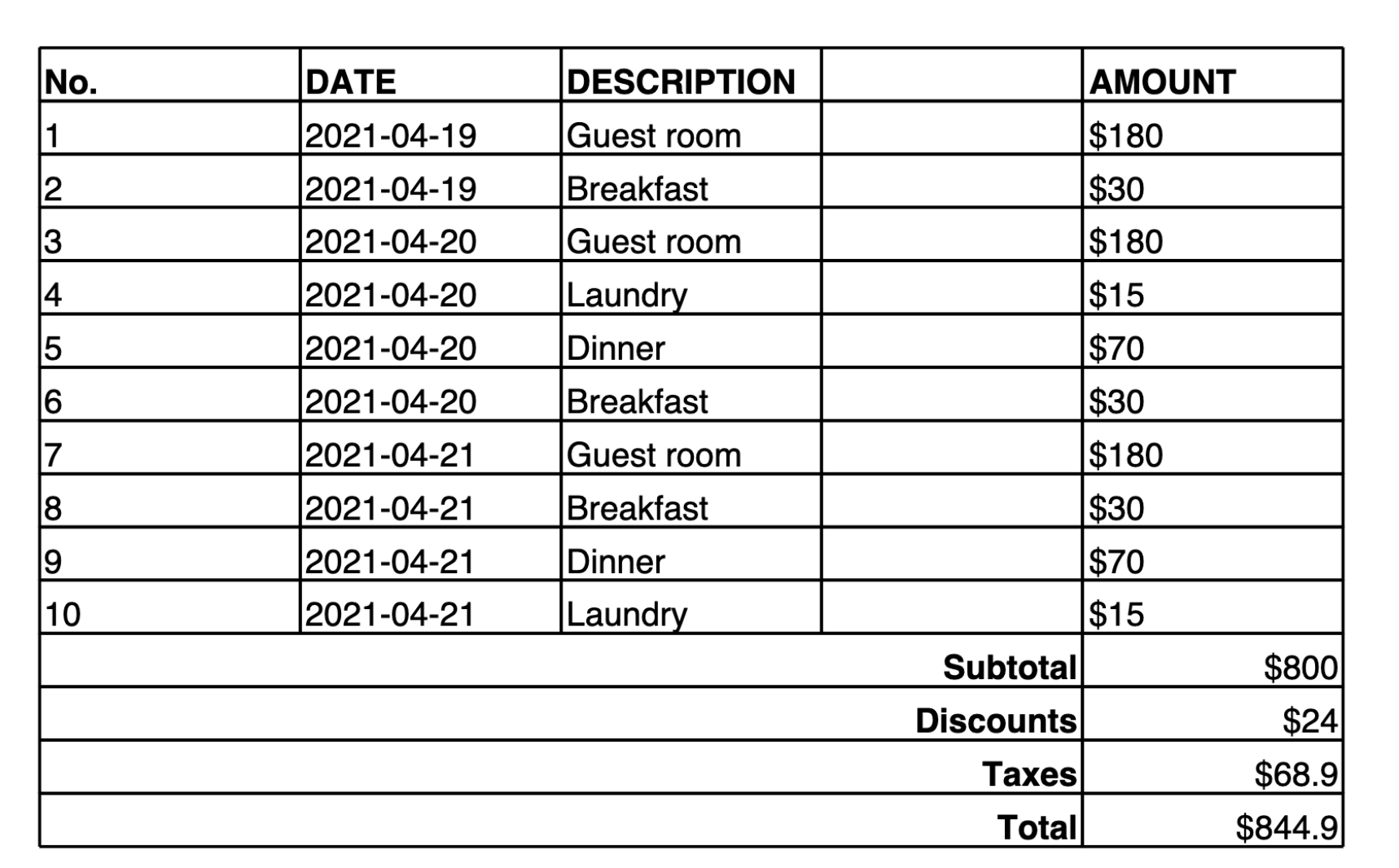
A continuación se muestra la salida proporcionada por el modelo:
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
Esta salida utiliza una notación de tabla personalizada donde || se usa como separador de columnas y && como separador de filas.
Configuración de los parámetros de inferencia para la comprensión visual
Para los casos de uso de comprensión visual, le recomendamos que comience con los parámetros de inferencia temperature establecido en 0 y topK establecido en 1. Tras observar el resultado del modelo, puede ajustar los parámetros de inferencia en función del caso de uso. Estos valores suelen depender de la tarea y de la varianza requerida. Aumente el ajuste de temperatura para inducir más variaciones en las respuestas.
Clasificación de vídeo
Para clasificar de manera eficaz el contenido de video en las categorías adecuadas, proporcione categorías que el modelo pueda utilizar para la clasificación. Considere el siguiente ejemplo de petición:
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
Etiquetado de videos
Amazon Nova Premier presenta una funcionalidad mejorada para crear etiquetas de video. A fin de obtener mejores resultados, utilice la siguiente instrucción que solicita etiquetas separadas por comas: “Usa comas para separar cada etiqueta”. A continuación se muestra una petición de ejemplo:
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
Subtitulado denso de videos
Amazon Nova Premier demuestra capacidades mejoradas para proporcionar subtítulos densos: descripciones textuales detalladas generadas para múltiples segmentos del video. A continuación se muestra una petición de ejemplo:
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
