Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Multirregión de MemoryDB
Multirregión de MemoryDB es una base de datos multirregión totalmente gestionada, activa-activa y multirregional que le permite crear aplicaciones multirregionales con una disponibilidad de hasta el 99,999 % y latencias de lectura de microsegundos y de escritura de un solo dígito de milisegundos. Puede mejorar tanto la disponibilidad como la resiliencia frente a la degradación regional y a la vez beneficiarse de lecturas y escrituras locales de baja latencia para aplicaciones multirregión.
Con Multirregión de MemoryDB, puede crear aplicaciones multirregionales de alta disponibilidad para aumentar la resiliencia. Ofrece replicación activa-activa para atender lecturas y escrituras localmente desde las regiones más cercanas a sus clientes, con una latencia de lectura de microsegundos y una latencia de un solo dígito en milisegundos. Multirregión de MemoryDB replica los datos de forma asíncrona entre las regiones y los datos suelen propagarse en menos de un segundo. Resuelve automáticamente los conflictos de actualización y corrige los problemas de divergencia de datos, lo que le permite centrarse en su aplicación.
Actualmente, MemoryDB Multi-Region es compatible con las siguientes AWS regiones: EE.UU. Este (Norte de Virginia y Ohio), EE.UU. Oeste (Oregón, Norte de California), Europa (Irlanda, Fráncfort y Londres) y Asia-Pacífico (Tokio, Sídney, Bombay, Seúl y Singapur).
Puede empezar fácilmente a utilizar MemoryDB Multi-Region con tan solo unos clics desde el SDK más reciente, Consola de administración de AWS o bien utilizando el SDK más reciente. AWS AWS CLI
Temas
Coherencia y resolución de conflictos
Cualquier actualización realizada en una clave de uno de los clústeres regionales se propaga a otros clústeres regionales de forma asíncrona en el clúster multirregional, normalmente en menos de un segundo. Si una región se encuentra aislada o degradada, Multirregión de MemoryDB lleva un seguimiento de las operaciones de escritura que se han realizado pero que todavía no se han propagado a todos los clústeres miembros. Cuando la región vuelva a estar en línea, Multirregión de MemoryDB reanudará la propagación de cualquier operación de escritura pendiente desde esa región a los clústeres miembros en otras regiones. Asimismo, reanudará la propagación de las operaciones de escritura de otros clústeres miembros a la región que ahora está en línea. Todas las escrituras realizadas correctamente con anterioridad se propagarán finalmente sin importar el tiempo que la región permanezca aislada.
Pueden surgir conflictos si su aplicación actualiza la misma clave en diferentes regiones aproximadamente al mismo momento. Multirregión de MemoryDB utiliza el tipo de datos replicados sin conflictos (CRDT) para conciliar escrituras simultáneas conflictivas. La CRDT es una estructura de datos que se puede actualizar de forma independiente y simultánea sin coordinación. Esto significa que el conflicto de escritura-escritura se fusiona de forma independiente en cada réplica para lograr una coherencia definitiva.
En concreto, MemoryDB utiliza dos niveles de Last Writer Wins (LWW, último escritor gana) para resolver conflictos. Para el tipo de datos String, LWW resuelve los conflictos en un nivel clave. Para otros tipos de datos, LWW resuelve los conflictos a nivel de subclave. La resolución de conflictos está totalmente administrada y se produce en segundo plano sin ningún impacto en la disponibilidad de la aplicación. A continuación se muestra un ejemplo del tipo de datos Hash:
La región A ejecuta “HSET K F1 V1” en la marca temporal T1; la región B ejecuta “HSET K F2 V2” en la marca temporal T2; tras la replicación, las regiones A y B tendrán la clave K con ambos campos. Cuando diferentes regiones actualizan simultáneamente diferentes subclaves de la misma colección, dado que MemoryDB resuelve un conflicto a nivel de subclave para el tipo de datos Hash, las dos actualizaciones no entran en conflicto entre sí. Por lo tanto, los datos finales contendrían el efecto de ambas actualizaciones.
| Time | Región A | Región B |
|---|---|---|
|
T1 |
HSET K F1 V1 |
|
|
T2 |
HSET K F2 V2 |
|
|
T3 |
sync (sincronizar) |
sync (sincronizar) |
|
T4 |
K: {F1:V1, F2:V2} |
K: {F1:V1, F2:V2} |
CRDT y ejemplos
Multirregión de MemoryDB implementa tipos de datos replicados sin conflictos (CRDT) para resolver conflictos de escritura simultáneos originados por varias regiones. La CRDT permite que diferentes regiones logren de forma independiente la coherencia eventual una vez que han recibido el mismo conjunto de operaciones, independientemente de la ordenación.
Cuando una sola clave se actualiza simultáneamente en varias regiones, es necesario resolver un conflicto escritura-escritura para lograr la coherencia de datos. Multirregión de MemoryDB utiliza la estrategia Last Writer Wins (LWW, último escritor gana) para determinar la operación ganadora y solo se observarán finalmente los efectos de la operación “después”. Decimos que una operación op1 “ocurrió antes” que una operación op2 si los efectos de la op1 se aplicaron en la región en que se ejecutó originalmente cuando se ejecutó op2.
En el caso de las colecciones (Hash, Set y SortedSet) MemoryDB Multi-Region, resuelva los conflictos a nivel de elemento. Esto permite a MemoryDB Multi-Region utilizar LWW para resolver conflictos en cada elemento. write/write Por ejemplo, si se agregan simultáneamente diferentes elementos a la misma colección desde varias regiones, la colección contendrá todos los elementos.
Ejecución simultánea: el último escritor gana
En Multirregión de MemoryDB, cuando hay una creación simultánea de una clave, la última operación que se ejecutó en cualquier región determinará el resultado de la clave. Por ejemplo:
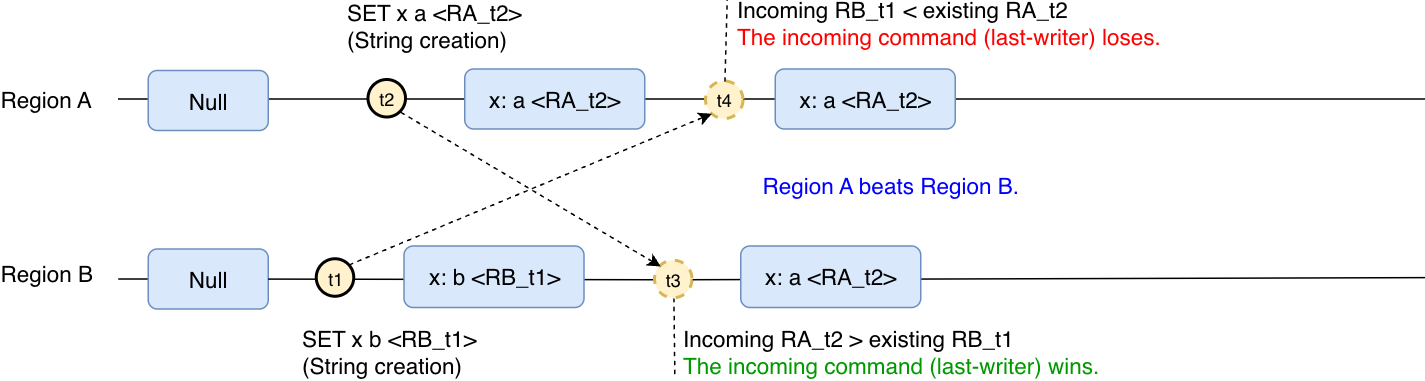
La clave x se creó en la región B con el valor “b”, pero después se creó la misma clave en la región A con el valor “a”. Con el tiempo, la clave convergerá y tendrá el valor “a”, ya que la operación realizada en la región A fue la última operación realizada.
Ejecución simultánea con tipos de datos contradictorios: el último escritor gana
En el ejemplo anterior, la clave se creó con el mismo tipo en ambas regiones. También se observará un comportamiento similar si la clave se crea con tipos de datos diferentes:
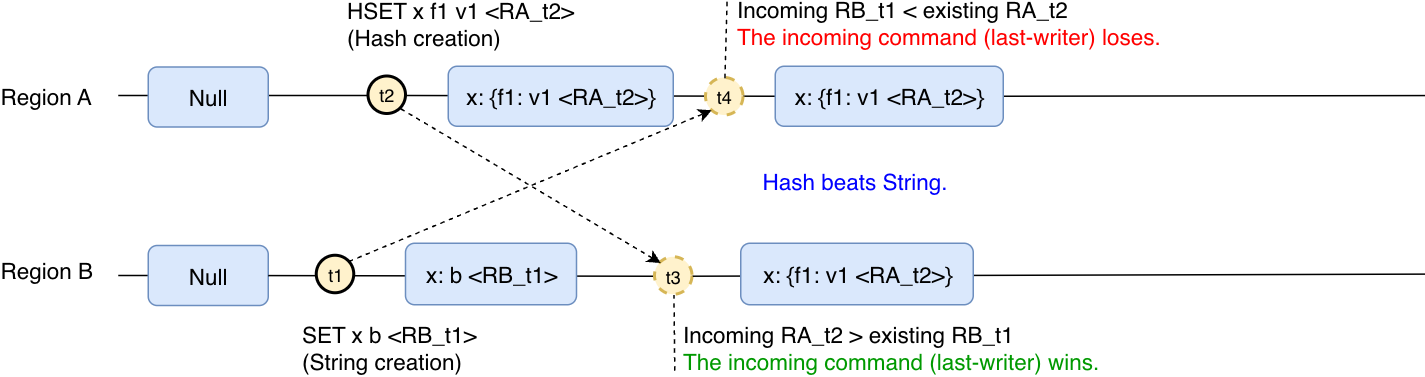
La clave x se creó como cadena en la región B con el valor "b". Pero después de eso, y antes de que la operación se replicara en la región A, se crea la misma clave en la región A como un Hash. Con el tiempo, la clave convergerá y tendrá el Hash creado en la región A, ya que la operación realizada en la región A fue la última operación realizada.
Creación y eliminación simultáneas: el último escritor gana
En el caso de que haya una eliminación y una «creación» simultáneas (es decir, replacement/addition de valor), ganará la última operación realizada. El resultado final vendrá determinado por el orden de la operación de eliminación. Si la eliminación se produce antes:

La clave x de tipo de conjunto se eliminó en la región B. Después, se agregó un nuevo miembro a esa clave en la región A. Finalmente, la clave convergerá para añadir el conjunto con el único elemento agregado en la región A, ya que la operación en la región A fue la última operación realizada.
Si la eliminación se produce después de:
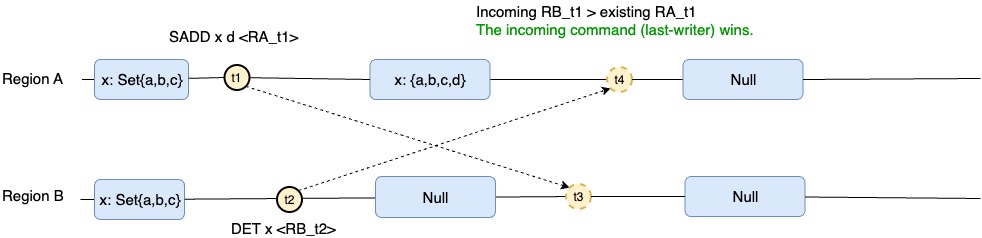
Se agregó un nuevo miembro a la clave x de tipo de conjunto en la región A. Después de eliminar la clave en la región B. Con el tiempo, convergerá y se eliminará la clave, ya que la operación en la región B fue la última operación realizada.
Contadores, operaciones simultáneas: la replicación del valor total con el último escritor gana
Los contadores de MemoryDB Multi-Region se comportan de manera similar a los tipos que no son contadores, ya que replican y aplican todos los valores. last-writer-strategy Las operaciones simultáneas no se combinarán, sino que ganará la última operación. Por ejemplo:
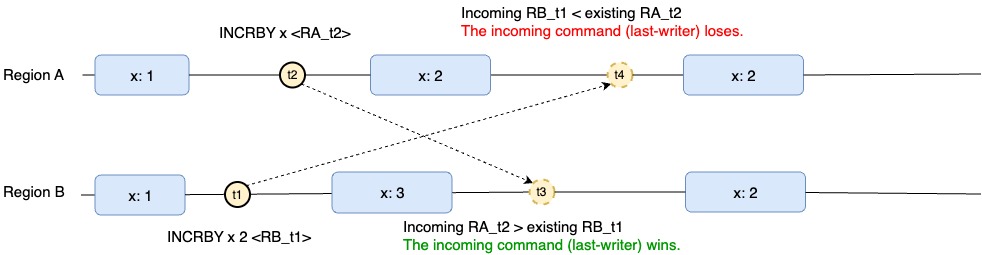
En este escenario, la clave x tiene el valor inicial 1. Luego, la región B aumenta el contador x en 2 y, poco después, la región A aumenta el contador en 1. Como la región A fue la última operación realizada, la clave x finalmente convergerá al valor 2, ya que la última operación realizada fue aumentar en 1.
Los comandos no deterministas se replican como deterministas
Para garantizar la coherencia de los valores en las diferentes regiones, en Multirregión de MemoryDB los comandos no deterministas se replican como deterministas. Los comandos no deterministas son aquellos que dependen de factores externos, como SETNX. SETNX depende de que la clave esté presente o no, y la clave puede estar presente en una región remota pero no en la región local que recibe el comando. Por este motivo, los comandos que de otro modo no serían deterministas, se replican como réplicas de valor total. En el caso de una cadena, se replicará como un comando SET.

En resumen, todas las operaciones de tipo String se replican como SET o DEL, todas las operaciones de tipo Hash se replican como HSET o HDEL, todas las operaciones de tipo Set se replican como SADD o SREM y todas las operaciones de conjuntos ordenados se replican como ZADD o ZREM.
