Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Planificación de la recuperación ante desastres
La recuperación ante desastres (DR) es un servicio fundamental para la continuidad empresarial y el cumplimiento normativo. AMS colabora con usted para ayudarle a planificar, implementar y mantener su estrategia de DR en AMS.
AMS landing zone (LZ), con varias cuentas y una sola cuenta, proporciona componentes nativos, Multi-AZ y de alta disponibilidad para los componentes de la infraestructura de AMS que cumplen con la mayoría de los escenarios de protección ante desastres. Sin embargo, en función de la cobertura geográfica de su empresa, es posible que necesite protección regional. Para la disponibilidad entre regiones y la DR, se requiere otra cuenta de AMS en una región diferente (esto es válido tanto para la zona de aterrizaje multicuenta como para la zona de aterrizaje de una sola cuenta).
AMS se ajusta a las directrices de recuperación ante desastres de AWS que se describen en este blog, Recuperación rápida de sistemas de misión crítica en caso de desastre
Varios sitios (o alta disponibilidad)
Modo de espera cálido
Luz piloto
Copia de seguridad y restauración
Estas opciones y la compatibilidad con AMS se describen en las siguientes secciones.
Multi-site o de alta disponibilidad (HA)
La solución de alta disponibilidad suele proporcionarse mediante la funcionalidad integrada de la aplicación, como la agrupación en clústeres o la replicación sincrónica. Los usuarios son dirigidos tanto a Prod como a los nodos. HA/DR El DNS apunta a los nodos directamente o a través de un balanceador de carga elástico (ELB).
Su arquitecto de nube (CA) de AMS trabajará con usted como parte de su planificación Well-Architected-Review y la de recuperación ante desastres.
HA DR utiliza funciones y servicios AWS nativos y de aplicaciones, como se muestra en el siguiente gráfico:
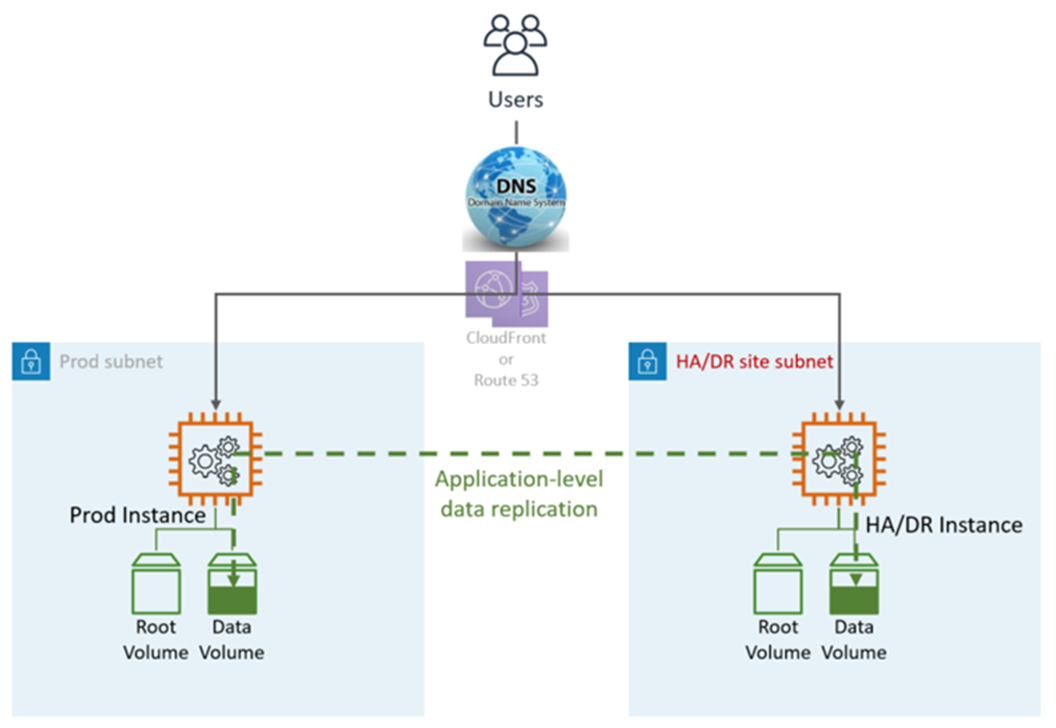
El sitio de recuperación ante desastres puede estar en el mismo sitio o en uno diferente Región de AWS.
nota
Una región diferente (Cross-Region) tendrá un entorno de Active Directory diferente.
Pasos de DR (conmutación por error): conmutación por error automática, no se requieren pasos manuales. En caso de que se produzca un error en la LZ principal, los usuarios se redirigirán automáticamente al nodo. DR/HA Esto se logra mediante la configuración del DNS y de la aplicación.
Métricas de DR de HA:
Objetivo de punto de recuperación (RPO): <5 minutos
Objetivo de tiempo de recuperación (RTO): <5 min
Mantenimiento: alto (se requieren cambios sincrónicos en ambos entornos, como la configuración de las aplicaciones, los parches, el SG o ALB, los certificados, etc.).
Costo: alto
Espera semiactiva
El término «modo de espera en espera» se utiliza para describir un escenario de recuperación ante desastres (DR) en el que una versión reducida del entorno se ejecuta en la nube.
La replicación de datos la realiza la capa de aplicación, normalmente de forma asíncrona, a una instancia en línea, mientras que el resto de las instancias (por ejemplo, los niveles de aplicación y web) pueden desactivarse para ahorrar costes. Los usuarios solo son dirigidos al sitio de producción. También se pueden aprovisionar previamente otros AWS recursos, como el balanceador de carga elástico (ELB), en el sitio de DR.
Su AMS Cloud Architect (CA) trabajará con usted como parte de su Well-Architected-Review planificación y la de recuperación ante desastres.
Warm Standby DR utiliza funciones y servicios AWS nativos y de aplicaciones, como se muestra en el siguiente gráfico:
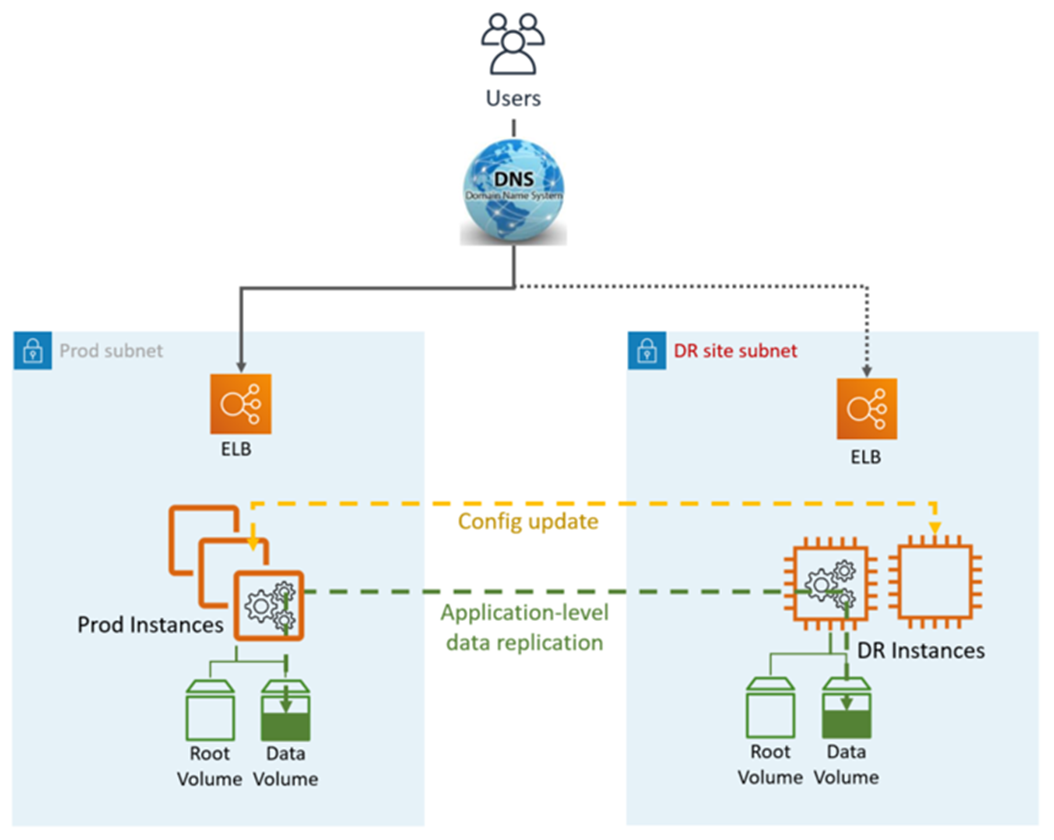
El sitio de DR puede estar en el mismo sitio o en uno diferente. Región de AWS
nota
Una región diferente (Cross-Region) tendrá un entorno de Active Directory diferente.
Pasos de DR (conmutación por error):
Frena la replicación de datos y convierte la instancia de datos en el sitio de DR en la maestra
Actualice la configuración de la aplicación según sea necesario (nueva IP, nombre del servidor, etc.)
Redirija el DNS al sitio de DR (ELB)
Dependencias de AD si es necesario (cuentas de servicio, SPN, GPO, etc.)
Métricas de DR de HA:
Objetivo de punto de recuperación (RPO): <1 hora
Objetivo y objetivo de tiempo de recuperación (RTO): menos de 1 hora (depende del número de instancias y de la orquestación)
Mantenimiento: alto (se requieren cambios sincrónicos en ambos entornos, como la configuración de las aplicaciones, los parches, los grupos de seguridad (SG) o el equilibrador de carga de aplicaciones (ALB), los certificados, etc.).
Costo: medio
Luz piloto
En este enfoque de recuperación ante desastres (DR), se replica parte de su entorno Prod para un conjunto limitado de servicios principales. Una pequeña parte de la infraestructura está siempre en funcionamiento y sincroniza simultáneamente datos mutables (como bases de datos o documentos), mientras que otras partes de la infraestructura se apagan y se utilizan únicamente durante las pruebas. A diferencia de un enfoque de respaldo y recuperación, debes asegurarte de que tus elementos principales más importantes ya estén configurados y funcionando en la zona de aterrizaje de DR (la luz piloto).
Su arquitecto de nube de AMS trabajará con usted como parte de su planificación Well-Architected-Review y de recuperación ante desastres.
Pilot Light DR utiliza funciones y servicios AWS nativos y de aplicaciones, como se muestra en el siguiente gráfico:
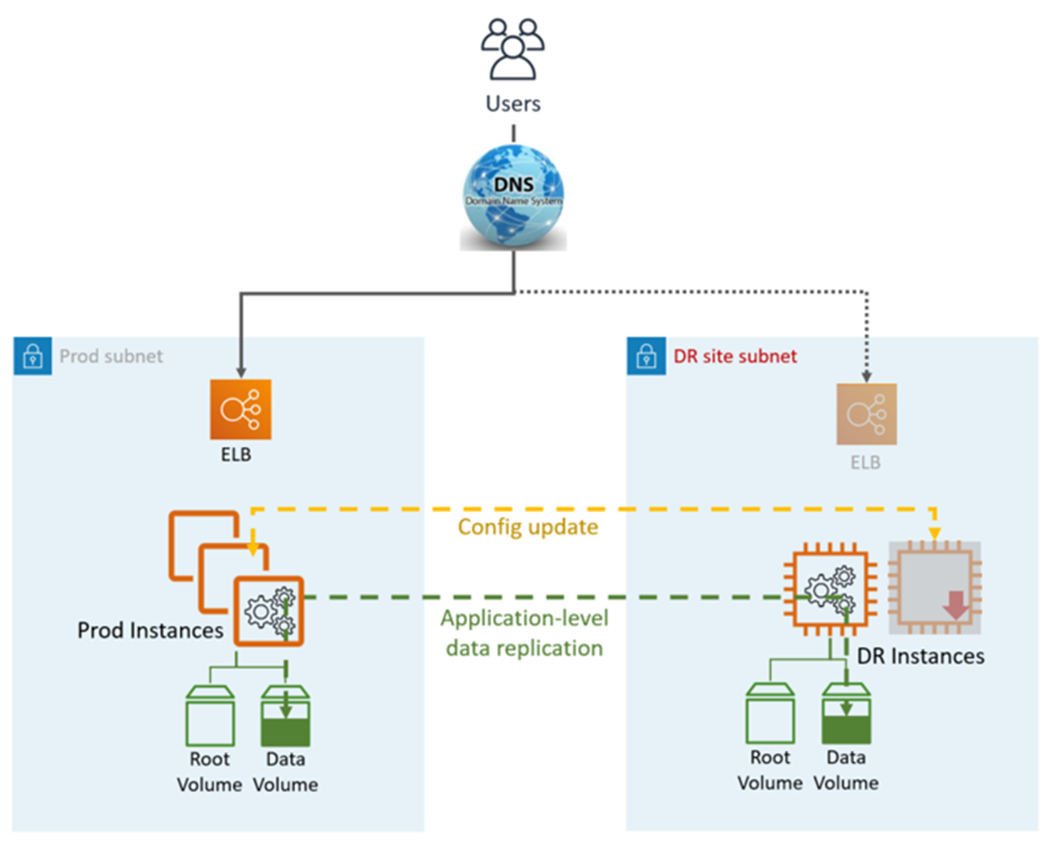
El sitio de DR puede estar en el mismo sitio o en uno diferente. Región de AWS
nota
Una región diferente (Cross-Region) tendrá un entorno de Active Directory diferente.
Pasos de DR (conmutación por error):
Frena la replicación de datos y convierte la instancia de datos en el sitio de DR en la maestra
Inicie las instancias y la infraestructura desactivadas
Actualice la configuración de la aplicación según sea necesario (nueva IP, nombre del servidor, etc.)
Añada las instancias al ELB según sea necesario
Redirija el DNS al sitio de DR (ELB)
Dependencias de AD, si son necesarias (cuentas de servicio, SPN, GPO, etc.)
Métricas de Pilot Light DR:
Objetivo de punto de recuperación (RPO): <1 hora
Objetivo y objetivo de tiempo de recuperación (RTO): aproximadamente 1 hora (depende del número de instancias y de la orquestación)
Mantenimiento: Medio
Costo: Medio
Copia de seguridad y restauración
Este enfoque de recuperación ante desastres (DR) simple y de bajo coste hace copias de seguridad de sus datos y aplicaciones desde cualquier lugar hasta la landing zone de DR para utilizarlos durante la recuperación tras un desastre.
Su AMS Cloud Architect trabaja con usted como parte de su planificación de Backup y DR.
Backup and Restore DR utiliza herramientas y procesos automatizados de AMS, como se muestra en el siguiente gráfico:
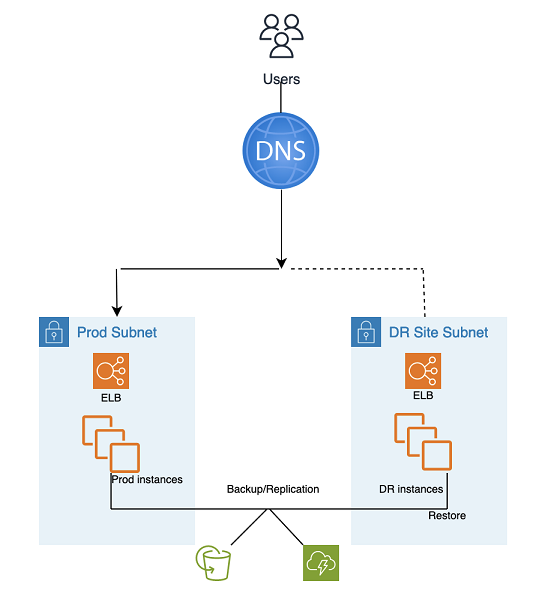
Se pueden utilizar dos métodos de copia de seguridad y replicación:
Instantánea de EBS (objetivo de punto de recuperación (RPO) > 1 hora), conocida como «EBS»
AWS Elastic Disaster Recovery (Objetivo de punto de recuperación (RPO) de aproximadamente 0,25 horas), conocido como «DRS»
El sitio de recuperación ante desastres puede estar en el mismo sitio o en uno diferente. Región de AWS
nota
Una región diferente (Cross-Region) tiene un entorno de Active Directory diferente.
Pasos de DR (conmutación por error):
Restaure las instancias a partir de instantáneas (proceso de dos pasos, primero con la instancia de marcador de posición)
Actualice la configuración de la aplicación (nueva IP, nombre del servidor, etc.)
Configure otra infraestructura según sea necesario (SG, ELB, etc.)
Redirija el DNS al sitio de DR (ELB)
Actualice o restaure las dependencias de AD si es necesario (cuentas de servicio, nombres principales de servicio (SPN), objetos de política de grupo (GPO), etc.)
Métricas de recuperación ante desastres de Backup and Restore:
Objetivo de punto de recuperación (RPO): más de 1 hora o aproximadamente 0,25 horas (según la solución seleccionada: EBS o DRE)
Objetivo de tiempo de recuperación y (RTO): aproximadamente 1 hora (depende del número de instancias y de la orquestación)
Mantenimiento: alto (se requieren cambios sincrónicos en ambos entornos, como la configuración de las aplicaciones, los parches, los grupos de seguridad o los balanceadores de carga de las aplicaciones, los certificados, etc.)
Costo: medio
Protección contra desastres para EC2 con instantáneas de EBS en AMS
Requisitos previos:
Zona de aterrizaje de AMS Prod (fuente)
Zona de aterrizaje AMS DR (objetivo DR)
Las instantáneas de EBS están habilitadas para las instancias EC2 ()AWS Backup
Solución de replicación de instantáneas:
Cross AZ: no se aplica: las instantáneas de EBS están muy disponibles en la región por diseño
Cross-Region: AWS Backup
El siguiente diagrama representa el proceso de restauración de EC2 a partir de instantáneas de EBS en AMS:
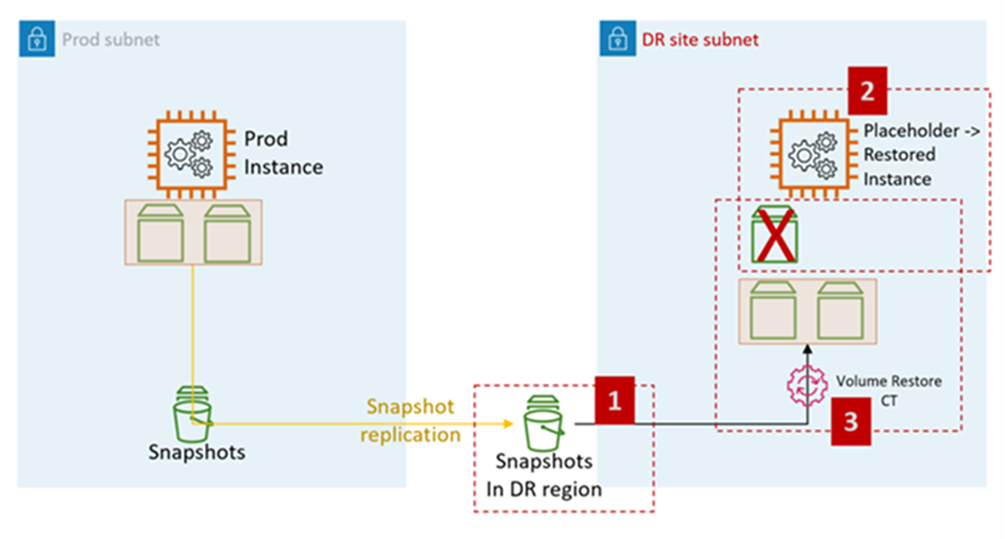
Los pasos de DR de EC2 en AMS:
Genere una RFC para compartir las instantáneas de EBS con la cuenta de destino (necesaria para la recuperación ante desastres). Cross-Region
: Administración, Advanced Stack Components, EBS Snapshot, Share
Cree una pila AMS EC2 como marcador de posición en la subred de destino (subred del sitio de DR). La recomendación es utilizar la ingesta de CFN para crear la pila, ya que el cliente puede combinar los pasos de asignación de grupos de seguridad y otros (como añadir la instancia a un ELB) en la misma pila.
Tipo de cambio: implementación, ingestión, apilamiento a partir de una plantilla, creación CloudFormation
Genere una RFC para restaurar el volumen de la pila de EC2.
Tipo de cambio: administración, componentes de pila avanzados, pila de instancias EC2, volúmenes de restauración.
El CT restaura los volúmenes a partir de las instantáneas compartidas en el paso 1 y los adjunta a la instancia de marcador de posición creada en el paso 2.
Funcionalidad CT de restauración de volúmenes:
Cierre la instancia de marcador de posición
Restaure los volúmenes a partir de las instantáneas
Cambie los volúmenes
Inicie la instancia
Abandone el dominio anterior
Cambiar el nombre de host
Reiniciar. Los scripts bootstrap de AMS unen la instancia al dominio de destino (DR) al iniciarse
Entrada CT de restauración de volumen:
InstanceId (ID de instancia de marcador de posición)
RootDeviceSnapshotId, la instantánea de EBS del volumen raíz restaurado
KMSKeyId, el identificador de clave de KMS, o ARN, para cifrar todos los volúmenes restaurados en la instancia EC2
DeviceNames, hasta 25 (opcional)
SnapshotIds, hasta 25 (opcional). Lista de instantáneas de los volúmenes que se van a restaurar
Protección ante desastres para EC2 con Elastic Disaster Recovery en AMS
Requisitos previos:
Zona de aterrizaje de AMS Prod (fuente)
Zona de aterrizaje AMS DR (objetivo DR)
Primero debes inicializar el servicio Elastic Disaster Recovery para todas las Regiones de AWS aplicaciones en las que planeas usarlo.
Crea un rol de IAM en tu DR landing zone (LZ) para el acceso a la consola de Elastic Disaster Recovery.
Importante: Un documento SSM se crea como una acción posterior al lanzamiento en DRS. Esta acción debe estar habilitada en todos sus servidores en la PostLaunch configuración.
la instancia de destino (marcador de posición) debe tener una clave de etiqueta: «AWSDRS», valor: "». AllowLaunchingIntoThisInstance La instancia de marcador de posición debe estar detenida. De lo contrario, AMS no podrá seleccionar la instancia de marcador de posición en la configuración de lanzamiento y Elastic Disaster Recovery no podrá restaurarla sobre la instancia de marcador de posición.
Para ver un diagrama del proceso de configuración y restauración de Elastic Disaster Recovery para EC2 en AMS, consulte Arquitectura general AWS Elastic Disaster Recovery (AWS DRS).
Pasos de recuperación ante desastres de EC2 con Elastic Disaster Recovery en AMS:
Cree una pila AMS de EC2 como marcador de posición en la subred de destino (subred del sitio de DR) con las etiquetas adecuadas; para obtener más información, consulte la sección anterior. Recomendamos utilizar la ingesta de CFN para crear la pila, ya que puede combinar los pasos de asignar grupos de seguridad y etiquetar la instancia, el volumen de EBS y otros (como añadir la instancia a un ELB) en la misma pila.
Tipo de cambio: implementación, transferencia, apilamiento a partir de una plantilla, creación CloudFormation
Detenga la instancia del marcador de posición.
Tipo de cambio: administración, componentes de pila avanzados, instancia EC2, parada
Si no lo ha hecho en el paso 1, etiquete la instancia de marcador de posición y su volumen de EBS con la clave: «AWSDRS», valor: "». AllowLaunchingIntoThisInstance
Tipo de cambio: administración, componentes de pila avanzados, etiqueta, actualización.
Utilice la instancia de marcador de posición del paso 1 como destino en Launch into instance ID, DRS Launch Settings, para el servidor de origen. Inicie el simulacro de recuperación de instancias desde la consola de Elastic Disaster Recovery para el servidor de origen.
nota
Los volúmenes de instancias marcadores de posición se conservan en la cuenta. Para eliminar estos volúmenes, envíe un archivo Management | Advanced stack components | EBS Volume | Delete change type (ct-3e3h8u0sp5z80) al final de la operación de recuperación ante desastres.
Flujo de trabajo de recuperación ante desastres de Elastic:
La instancia de destino (marcador de posición) debe estar detenida
Cambie los volúmenes y elimine el volumen raíz de origen (marcador de posición)
Inicie la instancia
Ejecuta las acciones posteriores al lanzamiento para completar los siguientes elementos:
Activa el agente SSM.
Cambie los volúmenes y elimine el volumen raíz de origen (marcador de posición).
Inicie la instancia
Ejecute PostLaunchScript el documento SSM. Este documento hace lo siguiente:
Abandona el dominio anterior.
Cambia el nombre de servidor.
Reiniciar. Los scripts bootstrap de AMS unen la instancia al dominio de destino (DR) durante el inicio.
