Cómo procesa Lambda registros de orígenes de eventos basados en secuencias y colas
Una asignación de orígenes de eventos es un recurso de Lambda que lee elementos de servicios basados en secuencias y colas e invoca una función con lotes de registros. Dentro de la asignación de orígenes de eventos , los recursos denominados sondeos de eventos sondean activamente nuevos mensajes e invocan funciones. De forma predeterminada, Lambda escala automáticamente los sondeos de eventos, pero para determinados tipos de orígenes de eventos, puede usar el modo aprovisionado para controlar el número mínimo y máximo de sondeos de eventos dedicados la asignación de orígenes de eventos.
Los siguientes servicios utilizan asignaciones de orígenes de eventos para invocar las funciones de Lambda:
aviso
Las asignaciones de orígenes de eventos de Lambda procesan cada evento al menos una vez, y puede producirse un procesamiento duplicado de registros. Para evitar posibles problemas relacionados con la duplicación de eventos, le recomendamos encarecidamente que haga que el código de la función sea idempotente. Para obtener más información, consulte ¿Cómo puedo hacer que mi función de Lambda sea idempotente?
En qué se diferencian las asignaciones de orígenes de eventos de los desencadenadores directos
Algunos Servicios de AWS pueden invocar directamente las funciones de Lambda mediante desencadenadores. Estos servicios envían eventos a Lambda y la función se invoca inmediatamente cuando se produce el evento especificado. Los desencadenadores son adecuados para eventos discretos y para el procesamiento en tiempo real. Al crear un desencadenador mediante la consola de Lambda, esta interactúa con el servicio de AWS correspondiente para configurar la notificación de eventos en ese servicio. En realidad, el servicio que genera los eventos es el que almacena y administra el desencadenador, no Lambda. Estos son algunos ejemplos de servicios que utilizan desencadenadores para invocar funciones de Lambda:
-
Amazon Simple Storage Service (Amazon S3): invoca una función cuando se crea, elimina o modifica un objeto en un bucket. Para obtener más información, consulte Tutorial: Uso de un desencadenador de Amazon S3 para invocar una función de Lambda.
-
Amazon Simple Notification Service (Amazon SNS): invoca una función cuando se publica un mensaje en un tema de SNS. Para obtener más información, consulte Tutorial: Uso de AWS Lambda con Amazon Simple Notification Service.
-
Amazon API Gateway: invoca una función cuando se realiza una solicitud de la API a un punto de conexión específico. Para obtener más información, consulte Invocación de una función de Lambda mediante un punto de conexión de Amazon API Gateway.
Las asignaciones de orígenes de eventos son recursos de Lambda creados y administrados dentro del servicio Lambda. Las asignaciones de orígenes de eventos están diseñados para procesar grandes volúmenes de datos o mensajes de streaming procedentes de colas. Procesar los registros de una secuencia o una cola por lotes es más eficiente que procesar los registros de forma individual.
Comportamiento de procesamiento por lotes
De forma predeterminada, una asignación de origen de eventos agrupa los registros en una sola carga que Lambda envía a su función. Para ajustar el comportamiento de procesamiento por lotes, puede configurar una ventana de procesamiento por lotes (MaximumBatchingWindowInSeconds) y un tamaño del lote (BatchSize). Un periodo de procesamiento por lotes es la cantidad de tiempo máxima para recopilar registros en una sola carga. El tamaño del lote es el número máximo de registros de un solo lote. Lambda invoca su función cuando se cumple uno de los tres criterios siguientes:
-
El plazo de procesamiento por lotes alcanza su valor máximo. El comportamiento predeterminado del plazo de procesamiento por lotes varía en función del origen de eventos específico.
Para los orígenes de eventos de Kinesis, DynamoDB y Amazon SQS: el plazo de procesamiento por lotes predeterminado es de 0 segundos. Esto significa que Lambda invoca su función tan pronto como los registros estén disponibles. Para establecer un plazo de procesamiento por lotes, configure
MaximumBatchingWindowInSeconds. Puede establecer este parámetro en cualquier valor entre 0 y 300 segundos, en incrementos de 1 segundo. Si configura un plazo de procesamiento por lotes, el siguiente plazo comienza tan pronto como se completa la invocación de la función anterior.En el caso de los orígenes de eventos de Amazon MSK, Apache Kafka autoadministrado, Amazon MQ y Amazon DocumentDB: el periodo de procesamiento por lotes predeterminado es de 500 ms. Puede configurar
MaximumBatchingWindowInSecondscomo cualquier valor entre 0 segundos y 300 segundos, en incrementos de segundos. En el modo aprovisionado para las asignaciones de orígenes de eventos de Kafka, al configurar una ventana de procesamiento por lotes, la siguiente ventana comienza tan pronto como se completa el lote anterior. En el modo no aprovisionado para las asignaciones de orígenes de eventos de Kafka, al configurar una ventana de procesamiento por lotes, la siguiente ventana comienza tan pronto como se completa la invocación de la función anterior. Para minimizar la latencia al utilizar las asignaciones de orígenes de eventos de Kafka en el modo aprovisionado, establezcaMaximumBatchingWindowInSecondsen 0. Esta configuración garantiza que Lambda comenzará a procesar el siguiente lote inmediatamente después de completar la invocación de la función actual. Para obtener información adicional sobre el procesamiento de baja latencia, consulte Apache Kafka de baja latencia.-
En el caso de los orígenes de eventos de Amazon MQ y Amazon DocumentDB: la ventana de procesamiento por lotes predeterminada es de 500 ms. Puede configurar
MaximumBatchingWindowInSecondscomo cualquier valor entre 0 segundos y 300 segundos, en incrementos de segundos. Un plazo de procesamiento por lotes comienza en cuanto llega el primer registro.nota
Como solo puede cambiar
MaximumBatchingWindowInSecondsen incrementos de segundos, no puede volver al plazo de procesamiento por lotes predeterminado de 500 ms después de haberlo cambiado. Para restaurar el plazo de procesamiento por lotes predeterminado, debe crear una nueva asignación de origen de eventos.
-
Se cumple el tamaño del lote. El tamaño mínimo del lote es 1. El tamaño predeterminado y máximo del lote depende del origen de eventos. Para obtener más información sobre estos valores, consulte la especificación BatchSize para la operación de la API de
CreateEventSourceMapping. -
El tamaño de la carga alcanza los 6 MB. Este límite no se puede modificar.
En el siguiente diagrama se ilustran estas tres condiciones. Supongamos que un plazo de procesamiento por lotes comienza a los t = 7 segundos. En el primer escenario, el plazo de procesamiento por lotes alcanza su máximo de 40 segundos a los t = 47 segundos después de acumular 5 registros. En el segundo escenario, el tamaño del lote llega a 10 antes de que venza el plazo de procesamiento por lotes, por lo que el plazo de procesamiento por lotes finaliza antes de tiempo. En el tercer escenario, se alcanza el tamaño máximo de la carga antes de que venza el plazo de procesamiento por lotes, por lo que el plazo de procesamiento por lotes finaliza antes de tiempo.
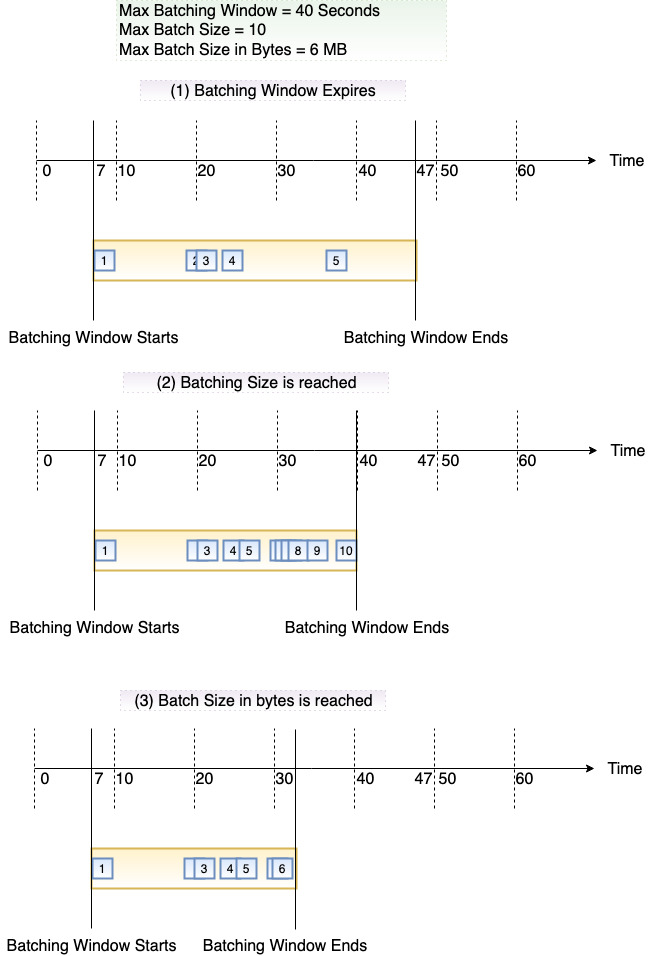
Recomendamos que pruebe con diferentes tamaños de lote y de registro para que la frecuencia de sondeo de cada origen de eventos se ajuste a la velocidad con la que la función es capaz de completar su tarea. El parámetro CreateEventSourceMapping de BatchSize controla el número máximo de registros que se pueden enviar a la función en cada invocación. A menudo, un tamaño de lote mayor puede absorber de forma más eficiente el tráfico adicional asociado a un conjunto de registros mayor, mejorando el desempeño.
Lambda no espera a que se complete una extensión configurada antes de enviar el siguiente lote para su procesamiento. En otras palabras, las extensiones pueden seguir ejecutándose mientras Lambda procesa el siguiente lote de registros. Esto puede provocar problemas de limitación si infringe alguno de los ajustes o límites de simultaneidad de la cuenta. Para detectar si se trata de un posible problema, supervise sus funciones y compruebe si ve métricas de simultaneidad más elevadas de lo esperado para la asignación de orígenes de eventos. Debido a los tiempos cortos entre invocaciones, Lambda puede informar brevemente un uso de simultaneidad superior al número de particiones. Esto puede ser cierto incluso para las funciones de Lambda sin extensiones.
De forma predeterminada, si su función devuelve un error, la asignación de origen de eventos vuelve a procesar todo el lote hasta que la función se complete correctamente o los elementos del lote venzan. Para garantizar el procesamiento en orden, la asignación de origen de eventos mantiene en pausa el procesamiento de la partición afectada hasta que se resuelve el error. Para los orígenes de flujos (DynamoDB y Kinesis), puede configurar la cantidad máxima de reintentos que Lambda puede realizar cuando la función devuelva un error. Los errores del servicio o las limitaciones que se producen cuando el lote no llega a la función no se tienen en cuenta para la cantidad de reintentos. También puede configurar la asignación de orígenes de eventos para enviar un registro de invocación a un destino cuando descarta un lote de eventos.
Modo aprovisionado
La asignación de orígenes de eventos de Lambda utiliza sondeos de eventos para sondear el origen de eventos en busca de nuevos mensajes. De forma predeterminada, Lambda administra el escalado automático de estos sondeadores en función del volumen de los mensajes. Cuando el tráfico de mensajes aumenta, Lambda aumenta automáticamente el número de sondeos de eventos para gestionar la carga y los reduce cuando el tráfico disminuye.
En el modo aprovisionado, puede refinar el rendimiento de la asignación de orígenes de eventos si define límites mínimos y máximos para los recursos de sondeo específicos que permanecen listos para gestionar los patrones de tráfico esperados. Estos recursos se escalan automáticamente 3 veces más rápido para gestionar picos repentinos en el tráfico de eventos y proporcionan una capacidad 16 veces mayor para procesar millones de eventos. Esto lo ayuda a crear cargas de trabajo impulsadas por eventos con una alta capacidad de respuesta y requisitos de rendimiento estrictos.
En Lambda, un sondeador de eventos es una unidad de cómputo con capacidades de rendimiento que varían según el tipo de origen del evento. En el caso de Amazon MSK y Apache Kafka autoadministrado, cada sondeador de eventos puede gestionar hasta 5 MB/s de rendimiento o hasta 5 invocaciones simultáneas. Por ejemplo, si el origen de eventos produce una carga útil media de 1 MB y la duración media de la función es de 1 segundo, un único sondeador de eventos de Kafka puede admitir un rendimiento de 5 MB/s y 5 invocaciones simultáneas de Lambda (si se supone que no haya transformación de la carga útil). En el caso de Amazon SQS, cada sondeador de eventos puede gestionar hasta 1 MB/s de rendimiento o hasta 10 invocaciones simultáneas. El uso del modo aprovisionado incurre en costos adicionales en función del uso de sondeadores de eventos. Para obtener más información sobre precios, consulta precios de AWS Lambda
El modo aprovisionado solo es compatible con orígenes de eventos de Amazon MSK, Apache Kafka autoadministrado y Amazon SQS. Si bien la configuración de simultaneidad permite controlar la escala de su función, el modo aprovisionado permite controlar el rendimiento de la asignación de orígenes de eventos. Para garantizar el máximo rendimiento, puede que tenga que establecer ambos ajustes de forma independiente.
El modo aprovisionado es ideal para aplicaciones en tiempo real que requieren una latencia constante para el procesamiento de eventos, como las empresas de servicios financieros que procesan fuentes de datos de mercado, las plataformas de comercio electrónico que ofrecen recomendaciones personalizadas en tiempo real y las empresas de juegos que administran las interacciones de los jugadores en directo.
Cada sondeador de eventos admite una capacidad de rendimiento diferente:
-
En el caso de Amazon MSK y Apache Kafka autoadministrado: hasta 5 MB/s de rendimiento o hasta 5 invocaciones simultáneas.
-
Para Amazon SQS: hasta 1 MB/s de rendimiento o hasta 10 invocaciones simultáneas o hasta 10 llamadas a la API de sondeo de SQS por segundo.
Para las asignaciones de orígenes de eventos de Amazon SQS, puede establecer el número mínimo de sondeadores entre 2 y 200, con un valor predeterminado de 2, y el número máximo entre 2 y 2000, con un valor predeterminado de 200. Lambda escala el número de sondeadores de eventos entre el mínimo y el máximo configurados, y suma rápidamente hasta 1000 concurrencias por minuto para proporcionar un procesamiento coherente de baja latencia de sus eventos.
Para las asignaciones de orígenes de eventos de Kafka, puede establecer el número mínimo de sondeadores entre 1 y 200, con un valor predeterminado de 1, y el número máximo entre 1 y 2000, con un valor predeterminado de 200. Lambda escala el número de sondeadores de eventos entre el mínimo y el máximo configurados en función de la acumulación de eventos en el tema para proporcionar un procesamiento de baja latencia de sus eventos.
Tenga en cuenta que, en el caso de los orígenes de eventos de Amazon SQS, la configuración de concurrencia máxima no se puede utilizar con el modo aprovisionado. Cuando utiliza el modo aprovisionado, controla la concurrencia mediante la configuración del número máximo de sondeadores de eventos.
Para obtener información sobre cómo configurar el modo de aprovisionamiento, consulte las secciones siguientes:
Para minimizar la latencia en el modo aprovisionado, configure MaximumBatchingWindowInSeconds en 0. Esta configuración garantiza que Lambda comenzará a procesar el siguiente lote inmediatamente después de completar la invocación de la función actual. Para obtener información adicional sobre el procesamiento de baja latencia, consulte Apache Kafka de baja latencia.
Tras configurar el modo aprovisionado, puede observar el uso de los sondeos de eventos para su carga de trabajo supervisando la métrica ProvisionedPollers. Para obtener más información, consulte Métricas de asignación de orígenes de eventos.
API de asignación de orígenes de eventos
Para administrar un origen de eventos con la AWS Command Line Interface (AWS CLI) o un AWS SDK
