Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Validación de la coherencia de datos durante una migración en línea
El siguiente paso del proceso de migración en línea es la validación de los datos. Las escrituras duales añaden nuevos datos a su base de datos de Amazon Keyspaces y ha completado la migración de los datos históricos mediante la carga por lotes o la caducidad de los datos con TTL.
Ahora puede utilizar la fase de validación para confirmar que ambos almacenes de datos contienen realmente los mismos datos y devuelven los mismos resultados de lectura. Puede elegir una de las dos opciones siguientes para validar que ambas bases de datos contengan datos idénticos.
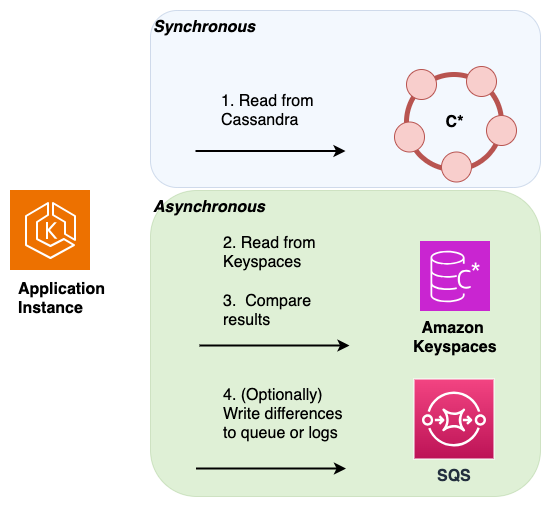
Lecturas duales: para validar que tanto la base de datos de origen como la de destino contengan el mismo conjunto de datos históricos y recién escritos, puede implementar lecturas duales. Para ello, debe leer tanto la base de datos principal de Cassandra como la base de datos secundaria de Amazon Keyspaces, de forma similar al método de escritura dual, y comparar los resultados de forma asíncrona.
Los resultados de la base de datos principal se devuelven al cliente y los resultados de la base de datos secundaria se utilizan para validarlos con el conjunto de resultados principal. Las diferencias detectadas se pueden registrar o enviar a una cola de mensajes fallidos (DLQ) para su posterior conciliación.
En el siguiente diagrama, la aplicación realiza una lectura sincrónica desde Cassandra (que es el almacén de datos principal) y una lectura asincrónica desde Amazon Keyspaces, que es el almacén de datos secundario.
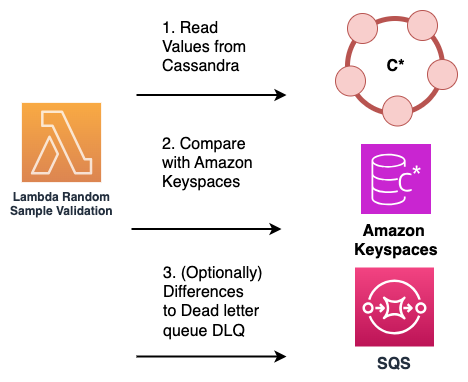
Lecturas de muestra: una solución alternativa que no requiere cambios en el código de la aplicación consiste en utilizar AWS Lambda funciones para muestrear de forma periódica y aleatoria los datos del clúster Cassandra de origen y de la base de datos Amazon Keyspaces de destino.
Estas funciones de Lambda se pueden configurar para que se ejecuten a intervalos regulares. La función de Lambda recupera un subconjunto aleatorio de datos de los sistemas de origen y destino y, a continuación, realiza una comparación de los datos muestreados. Cualquier discrepancia o discordancia entre los dos conjuntos de datos se puede registrar y enviar a una cola de mensajes fallidos (DLQ) específica para su posterior conciliación.
Este proceso se ilustra en el siguiente diagrama.