Configuración de un destino de una integración zero-ETL
Al configurar un destino de una integración zero-ETL, AWS Glue ofrece varias opciones. El destino puede ser un almacenamiento de datos cifrado de Amazon Redshift o una arquitectura de lake house de Amazon SageMaker.
Antes de seleccionar el destino para la integración zero-ETL, debe configurar uno de los siguientes recursos de destino. Las opciones de configuración de un destino en una integración zero-ETL incluyen:
Un bucket de Amazon S3 de uso general que utiliza la arquitectura de lake house de Amazon SageMaker. Consulte Configuración de un destino de bucket de S3 de uso general.
Un bucket de Tablas de Amazon S3 que utiliza la arquitectura de lake house de Amazon SageMaker. Consulte Configuración de un destino de bucket de Tablas de Amazon S3.
Un almacenamiento administrado de Amazon Redshift que utiliza la arquitectura de lake house de Amazon SageMaker. Consulte Configuración de un destino de almacenamiento administrado de Amazon Redshift.
Un almacenamiento de datos de Amazon Redshift identificado por un espacio de nombres de Redshift. Consulte Configuración de un destino de almacén de datos de Amazon Redshift.
nota
No puede modificar el destino de una integración zero-ETL después de su creación.
Configuración de un destino de bucket de S3 de uso general
En esta sección se describen los requisitos previos y los pasos de configuración para configurar un bucket de S3 de uso general como almacenamiento para el destino de una integración zero-ETL con la arquitectura de lake house de Amazon SageMaker.
Antes de crear una integración zero-ETL con la arquitectura de lake house de Amazon SageMaker mediante el almacenamiento de S3 de uso general, debe completar las siguientes tareas de configuración:
Configurar una base de datos de AWS Glue
Proporcionar la política de RBAC del catálogo
Crear el rol de IAM de destino
Asociación del rol de destino, KMS (opcional) y la conexión (opcional) al recurso de destino
(Opcional) Configuración de las propiedades de la tabla de destino
Configuración de una base de datos de AWS Glue
Para configurar una base de datos de destino en el Catálogo de datos con una ubicación de bucket de Amazon S3 de uso general:
En la página de inicio de la consola de AWS Glue, seleccione Base de datos en el catálogo de datos.
Seleccione Añadir base de datos en la parte superior derecha. Si ya ha creado una base de datos, asegúrese de que la ubicación con el URI de Amazon S3 esté configurada para la base de datos.
Introduzca un nombre y una ubicación (URI de Amazon S3). Tenga en cuenta que la ubicación es necesaria para la integración zero-ETL. Haga clic en Crear base de datos cuando haya terminado.
nota
El bucket de Amazon S3 de uso general debe estar en la misma región que la base de datos de AWS Glue.
Para obtener información sobre cómo crear una nueva base de datos en AWS Glue, consulte Introducción al Catálogo de datos.
También puede usar la CLI de create-database para crear la base de datos en AWS Glue. Tenga en cuenta que es necesario incluir LocationUri en --database-input.
Optimización de las tablas de Iceberg
Una vez que AWS Glue cree una tabla en la base de datos de destino, puede habilitar la compactación para acelerar las consultas en Amazon Athena. Para obtener información sobre cómo configurar los recursos (rol de IAM) para la compactación, consulte los requisitos previos de optimización de la tabla.
Para obtener más información sobre cómo configurar la compactación en la tabla de AWS Glue que creó la integración, consulte Optimización de las tablas de Iceberg.
Cómo proporcionar una política de acceso basado en recursos (RBAC) al catálogo
En el caso de las integraciones que utilizan una base de datos de AWS Glue, añada los siguientes permisos a la política de RBAC del catálogo para permitir las integraciones entre el origen y el destino.
nota
Para las integraciones entre cuentas, tanto el usuario que crea la política de roles de integración como la política de recursos del catálogo deben permitir glue:CreateInboundIntegration en el recurso. En el caso de que sean las mismas cuentas, basta con una política de recursos o una política de roles que permita glue:CreateInboundIntegration en el recurso. Aun así, es necesario que ambos escenarios permitan glue.amazonaws.com en glue:AuthorizeInboundIntegration.
Puede acceder a la configuración del catálogo en Catálogo de datos. A continuación, proporcione los siguientes permisos y rellene la información que falta.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Creación de un rol de IAM de destino
Cree un rol de IAM de destino con los siguientes permisos y relaciones de confianza:
{ "Version": "2012-10-17", "Statement": [ { "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::amzn-s3-bucket", "Effect": "Allow" }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/*", "Effect": "Allow" }, { "Action": [ "glue:GetDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Effect": "Allow" }, { "Action": [ "glue:CreateTable", "glue:GetTable", "glue:GetTables", "glue:DeleteTable", "glue:UpdateTable", "glue:GetTableVersion", "glue:GetTableVersions", "glue:GetResourcePolicy" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name", "arn:aws:glue:us-east-1:111122223333:table/database-name/*" ], "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Agregue la siguiente política de confianza para permitir que el servicio AWS Glue asuma el rol:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Asociación del rol de destino, KMS (opcional) y la conexión (opcional) al recurso de destino
Asocie el rol de destino anterior al recurso de destino, es decir, la base de datos de AWS Glue. Opcionalmente, se puede configurar KMS para cifrar los datos antes de almacenarlos en la tabla iceberg de destino y el ARN de conexión para acceder al bucket de S3 para la base de datos de AWS Glue de destino. Esto permitirá que AWS Glue acceda a los datos de la ubicación de S3 de destino mediante el rol proporcionado y, opcionalmente, cifrarlos con la clave de KMS proporcionada. Si el bucket de S3 de destino está configurado para que sea accesible mediante una VPC determinada, se puede asociar el ARN de conexión para permitir que AWS Glue ejecute el procesamiento dentro de esa VPC. Para obtener más información sobre la configuración de una VPC, consulte Creación de una VPC.
Uso de la AWS Glue CLI o API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --target-processing-properties '{"RoleArn": "arn:aws:iam::123456789012:role/gmi_target_role"}' \ --region us-east-1
(Opcional) Configuración de las propiedades de la tabla de destino
Opcionalmente, las propiedades de la tabla de destino se pueden configurar para las tablas de destino que se van a sincronizar con el destino.
Puede configurar estos ajustes en la sección Configuración de salida del flujo de trabajo de creación de integraciones de la consola de AWS Glue:

Al seleccionar Especificar claves de partición personalizadas, puede configurar las claves de partición y sus especificaciones de función y conversión:

Si el origen y el destino están en la misma cuenta, esta configuración se puede realizar como parte del flujo de trabajo de creación de integraciones desde la interfaz de usuario de la consola de AWS Glue. Sin embargo, si el destino está en una cuenta diferente, es necesario completar esta configuración antes de crear la integración. Al usar la CLI o la API, esto debe hacerse antes de invocar la API Create-Integration, incluso cuando el origen y el destino estén en la misma cuenta. La interfaz de usuario de la consola de AWS Glue simplemente encapsula esta llamada a la API para el mismo escenario de cuenta.
Si no está configurado, se utilizarán los valores predeterminados al sincronizar la tabla. Esta configuración también se puede cambiar en cualquier momento después de la creación de la integración.
nota
Si esta propiedad se actualiza después de crear la integración, podría provocar una nueva sincronización completa de la tabla cuando la configuración actualizada entre en conflicto con la configuración existente. Por ejemplo, actualizar la tabla “un-nesting” de “No-Unnest” a “Full-Unnest” o cambiar la columna de particiones.
Mediante la CLI o la API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --table-nametable-name\ --target-table-config '{ "UnnestSpec":"TOPLEVEL"|"FULL"|"NOUNNEST", "PartitionSpec": [ { "FieldName":"string", "FunctionSpec":"string", "ConversionSpec":"string"} ... ], "TargetTableName":"string" }' \ --region us-east-1
Tras configurar la arquitectura de lake house de Amazon SageMaker con el almacenamiento del bucket de Amazon S3 de uso general, puede ir a Configuración de la integración con su destino para completar la configuración de la integración.
Configuración de un destino de bucket de Tablas de Amazon S3
En esta sección se describen los requisitos previos y los pasos de configuración para configurar las tablas de Amazon S3 como destino para su integración zero-ETL mediante la arquitectura de lake house de Amazon SageMaker.
Antes de crear una integración zero-ETL con las tablas de Amazon S3 como destino, debe completar las siguientes tareas de configuración:
Configuración del bucket de Tablas de Amazon S3 (y la integración de los servicios de análisis)
Proporcionar la política de RBAC del catálogo
Crear el rol de IAM de destino
Asociación del rol de destino, KMS (opcional) y la conexión (opcional) al recurso de destino
(Opcional) Configuración de las propiedades de la tabla de destino
Configuración del bucket de Tablas de Amazon S3 (con la integración de los servicios de análisis)
Cree un bucket de las tablas de S3 en su cuenta siguiendo las instrucciones de Introducción a las tablas de Amazon S3.
Habilite las integraciones de análisis con el bucket de las tablas de S3 siguiendo estas instrucciones: Integración de los servicios de AWS con las tablas de Amazon S3.
Esto creará un nuevo catálogo S3-Table en AWS Lake Formation.
Proporcionar la política de RBAC del catálogo
Los siguientes permisos deben añadirse a la política de RBAC del catálogo para permitir las integraciones entre el origen y el destino del catálogo de las tablas de Amazon S3.
La política de recursos del catálogo de AWS Glue de destino debe incluir los permisos del servicio de AWS Glue en AuthorizeInboundIntegration. Además, se requiere el permiso CreateInboundIntegration en la entidad principal de origen que crea la integración o en la política de recursos de AWS Glue de destino.
nota
En un escenario con varias cuentas, tanto la entidad principal de origen como la política de recursos del catálogo de AWS Glue de destino deben incluir los permisos glue:CreateInboundIntegration en el recurso.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
nota
Reemplace s3tablescatalogs3tablescatalog.
Crear el rol de IAM de destino
Cree un rol de IAM de destino con los siguientes permisos y relaciones de confianza:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3tables:ListTableBuckets", "s3tables:GetTableBucket", "s3tables:GetTableBucketEncryption", "s3tables:GetNamespace", "s3tables:CreateNamespace", "s3tables:ListNamespaces", "s3tables:CreateTable", "s3tables:DeleteTable", "s3tables:GetTable", "s3tables:GetTableEncryption", "s3tables:ListTables", "s3tables:GetTableMetadataLocation", "s3tables:UpdateTableMetadataLocation", "s3tables:GetTableData", "s3tables:PutTableData" ], "Resource": "arn:aws:s3tables:us-east-1:111122223333:bucket/s3-table-bucket", "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Agregue la siguiente política de confianza en el rol de IAM de destino para permitir que el servicio de AWS Glue asuma el rol:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
nota
Asegúrese de que no haya una declaración DENY explícita para este rol de IAM de destino en la política de recursos del bucket de las tablas de S3. Una declaración DENY explícita anularía cualquier permiso ALLOW e impediría que la integración funcionara correctamente.
Asociación del rol de destino, KMS (opcional) y la conexión (opcional) al recurso de destino
Asocie el rol de destino anterior al recurso de destino. Opcionalmente, se puede configurar KMS para cifrar los datos antes de almacenarlos en la tabla iceberg de destino y el ARN de conexión para acceder al bucket de S3 de destino. Si el bucket de S3 de destino está configurado para que sea accesible mediante una VPC determinada, se puede asociar el ARN de conexión para permitir que AWS Glue ejecute el procesamiento dentro de esa VPC. Para obtener más información sobre la configuración de una VPC, consulte Creación de una VPC.
Mediante la AWS Glue CLI o API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --target-processing-properties '{ "RoleArn": "arn:aws:iam::123456789012:role/target_role" }' \ --region us-east-1
(Opcional) Configuración de las propiedades de la tabla de destino
Opcionalmente, las propiedades de la tabla de destino se pueden configurar para las tablas de destino que se van a sincronizar con el destino. Se aplican las mismas reglas que se describen en la sección de destinos de S3 de uso general.
Mediante la CLI o la API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --table-nametable-name\ --target-table-config '' \ --region us-east-1
Tras configurar el almacenamiento de Tablas de Amazon S3 con la arquitectura de lake house Amazon SageMaker, puede ir a Configuración de la integración con su destino para completar la configuración de la integración.
Configuración de un destino de almacenamiento administrado de Amazon Redshift
En esta sección se describen los requisitos previos y los pasos de configuración para configurar un almacenamiento administrado de Amazon Redshift (RMS) como destino para la integración zero-ETL mediante la arquitectura de lake house de Amazon SageMaker.
Antes de crear una integración zero-ETL con una arquitectura de lake house de Amazon SageMaker mediante el uso del almacenamiento administrado de Redshift, debe completar las siguientes tareas de configuración:
Configurar un grupo de trabajo sin servidor o clúster de Amazon Redshift
Registrar la integración de Amazon Redshift con Lake Formation
Crear un catálogo administrado en Lake Formation
Configurar los permisos de IAM
Configuración del almacenamiento administrado de Amazon Redshift
Para configurar un almacenamiento administrado de Amazon Redshift para su integración zero-ETL:
Cree o utilice un grupo de trabajo sin servidor o un clúster de Amazon Redshift existente. Asegúrese de que el clúster o el grupo de trabajo de Amazon Redshift de destino tenga el parámetro
enable_case_sensitive_identifieractivado para que la integración se complete correctamente. Para obtener más información sobre cómo habilitar la distinción entre mayúsculas y minúsculas, consulte Activación de la distinción entre mayúsculas y minúsculas en el almacenamiento de datos en la Guía de administración de Amazon Redshift.Registre una integración de Redshift en el catálogo de AWS Lake Formation. Consulte Registro de clústeres y espacios de nombres de Amazon Redshift en el Data Catalog.
Cree un catálogo federado o administrado en AWS Lake Formation. Para obtener más información, consulte:
Configure los permisos de IAM para el rol de destino. El rol necesita permisos para acceder a los recursos de Redshift y Lake Formation. El rol debe tener, como mínimo, lo siguiente:
Permisos para acceder al clúster o al grupo de trabajo de Redshift
Permisos para acceder al catálogo de Lake Formation
Permisos para crear y administrar tablas en el catálogo
Permisos de los registros de CloudWatch y CloudWatch para la supervisión
Tras configurar el catálogo de Amazon SageMaker Lakehouse con el almacenamiento administrado de Amazon Redshift, puede ir a Configuración de la integración con su destino para completar la configuración de la integración.
Configuración de un destino de almacén de datos de Amazon Redshift
En esta sección se describen los requisitos previos y los pasos de configuración para configurar un almacén de datos de Amazon Redshift como destino para su integración zero-ETL.
Antes de crear una integración zero-ETL con un destino del almacén de datos de Amazon Redshift, debe completar las siguientes tareas de configuración:
Configurar un grupo de trabajo sin servidor o clúster de Amazon Redshift
Configurar la distinción entre mayúsculas y minúsculas
Configurar los permisos de IAM
Configuración del almacén de datos de Amazon Redshift
Para configurar un almacén de datos de Amazon Redshift en su integración zero-ETL:
Navegue a la consola de Amazon Redshift
y haga clic en Crear clúster o use un clúster existente. Para crear un clúster de Amazon Redshift, consulte Creación de un clúster. Para Amazon Redshift sin servidor, haga clic en Crear grupo de trabajo. Para crear un grupo de trabajo de Amazon Redshift sin servidor, consulte Creación de un grupo de trabajo con un espacio de nombres. Si va a crear un clúster nuevo, elija un tamaño de clúster adecuado y asegúrese de que el clúster esté cifrado. Para el servicio sin servidor, ajuste la configuración del grupo de trabajo según sus requisitos.
Asegúrese de que el clúster o el grupo de trabajo de Amazon Redshift de destino tenga el parámetro
enable_case_sensitive_identifieractivado para que la integración se complete correctamente. Para obtener más información sobre cómo habilitar la distinción entre mayúsculas y minúsculas, consulte Turn on case sensitivity for your data warehouse en la Guía de administración de Amazon Redshift.Configure los permisos de IAM para permitir que la integración zero-ETL acceda a su almacén de datos de Amazon Redshift. Deberá crear un rol de IAM con los siguientes permisos:
Permisos para acceder al clúster o al grupo de trabajo de Amazon Redshift
Permisos para crear y administrar bases de datos y tablas en Amazon Redshift
Permisos de los registros de CloudWatch y CloudWatch para la supervisión
Una vez completada la configuración del grupo de trabajo o clúster de Amazon Redshift, debe configurar el almacén de datos para las integraciones zero-ETL. Para obtener más información, consulte Introducción a las integraciones zero-ETL en la Guía de administración de Amazon Redshift.
nota
Cuando se utiliza un almacén de datos de Amazon Redshift como destino, la integración crea un esquema en la base de datos especificada para almacenar los datos replicados. El nombre del esquema proviene del nombre de la integración.
nota
Para que la integración funcione, el clúster o el grupo de trabajo de Amazon Redshift de destino debe tener el parámetro enable_case_sensitive_identifier activado.
Tras configurar el almacén de datos de Amazon Redshift, puede ir a Configuración de la integración con su destino para completar la configuración de la integración.
Configuración de la integración con su destino
Tras configurar los recursos de origen y destino, siga estos pasos para completar la configuración de la integración:
Vaya a la página “Integraciones zero-ETL” e inicie el flujo de trabajo de creación de la integración.
Seleccione el recurso de origen configurado en los pasos anteriores.
Seleccione o especifique el recurso de destino (la misma cuenta o varias cuentas) configurado en los pasos anteriores.
Seleccione el rol de IAM de destino configurado anteriormente.
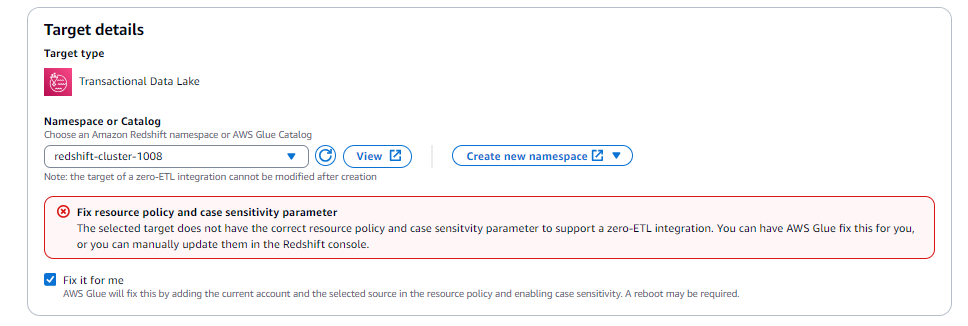
Seleccione la opción Solucionarlo por mí (solo está disponible cuando el destino está en la misma cuenta).
Para el destino habitual de Amazon S3 (base de datos de AWS Glue) y el destino de S3-Table (catálogo), esto hará lo siguiente:
Aplicar una entidad principal autorizada a la política de recursos del catálogo de destino.
Aplicar un ARN de entidad principal de origen de AWS Glue autorizado a la política de recursos del catálogo de destino.
Para el destino Amazon Redshift, hará lo siguiente:
Aplicar una entidad principal autorizada al grupo de trabajo sin servidor o al clúster de Amazon Redshift.
Aplicar un ARN de origen de AWS Glue autorizado al grupo de trabajo sin servidor o al clúster de Amazon Redshift.
Asociar un nuevo grupo de parámetros con
enable_case_sensitive_identifier = true.
Utilice lo siguiente para crear la integración mediante la API o la CLI: API CreateIntegration.
