Uso del reconocimiento del contexto con la integración de datos de Amazon Q en AWS Glue
Ahora puede crear trabajos de procesamiento de datos de manera más eficiente mediante la generación de código DataFrame de PySpark y contextualizado basado en consultas en la integración de datos de Amazon Q. Por ejemplo, puede utilizar esta petición para generar el código de PySpark: “crear un trabajo para cargar los datos de ventas de la tabla de Redshift 'analytics.salesorder' con la conexión 'erp_conn', filtrar order_amount por debajo de 50 dólares y guardar los datos en Amazon S3 en formato parquet”.
Amazon Q generará el script en función de su petición y configurará el flujo de trabajo de integración de datos con los detalles que haya proporcionado en su pregunta, como configuraciones de conexión, detalles del esquema, nombres de bases de datos o tablas y especificaciones de columnas para transformaciones. La información confidencial, como las contraseñas de las opciones de conexión, se sigue redactando.
Si la petición no proporciona la información requerida, Amazon Q colocará marcadores de posición, para los que tendrá que actualizar el código generado con los valores adecuados antes de ejecutar el código.
A continuación, encontrará algunos ejemplos de cómo utilizar el reconocimiento del contexto.
Ejemplo: Interacciones
Petición: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and
saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node S3DataSource S3DataSource_dsource1 = spark.read.format("csv").load( "s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv" ) # Script generated for node S3DataSink S3DataSource_dsource1.write.format("parquet").mode("append").save( "s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/" )

Petición: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table
my-target-table
En los campos en los que no se proporciona información (por ejemplo, el connectionName requerido es para el receptor de datos de MySQL y se completa de forma predeterminada con un marcador de posición <connection-name> en el código generado), se mantiene un marcador de posición para completar la información requerida antes de ejecutar el script.
Script generado:
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession from connectivity.adapter import CatalogConnectionHelper sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node S3DataSource S3DataSource_dsource1 = spark.read.format("parquet").load( "s3://amzn-lakehouse-demo-bucket/my-database/my-table" ) # Script generated for node ConnectionV2DataSink ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"} CatalogConnectionHelper(spark).write( S3DataSource_dsource1, "mysql", "<connection-name>", ConnectionV2DataSink_dsink1_additional_options, )

En el siguiente ejemplo se muestra cómo puede pedirle a AWS Glue que cree un script de AWS Glue para completar un flujo de trabajo de ETL con la siguiente petición: Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database
glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC'
after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format.
El flujo de trabajo incluye la lectura de diferentes orígenes de datos (dos tablas del catálogo de datos de AWS Glue) y un par de transformaciones después de la lectura: se une el resultado de dos lecturas, se filtra en función de alguna condición y se escribe la salida transformada en un destino de Amazon S3 en formato CSV.
El trabajo generado completará la información detallada para el origen de datos, la operación de transformación y absorción de datos con la información correspondiente extraída de la pregunta del usuario, como se muestra a continuación.
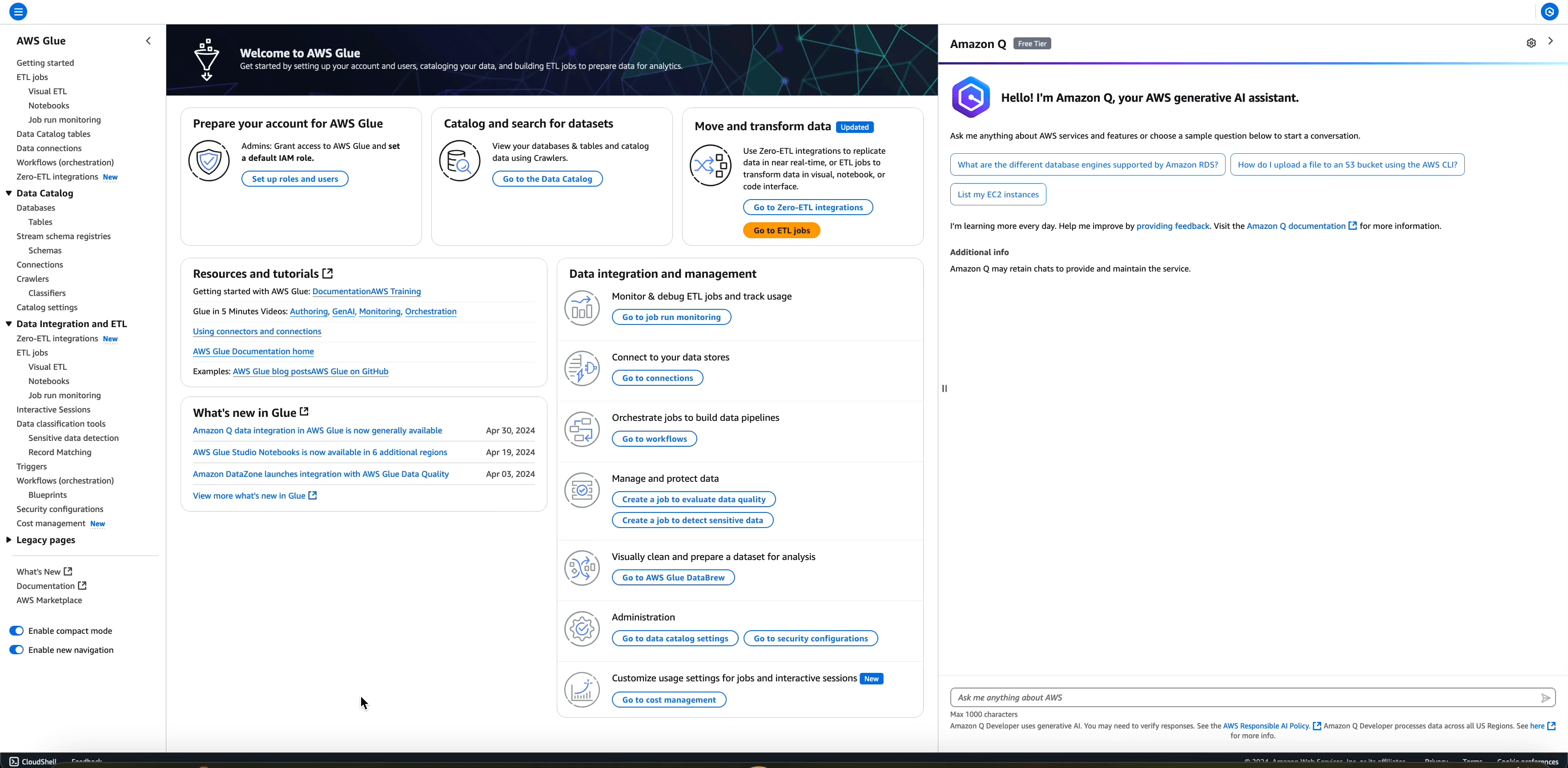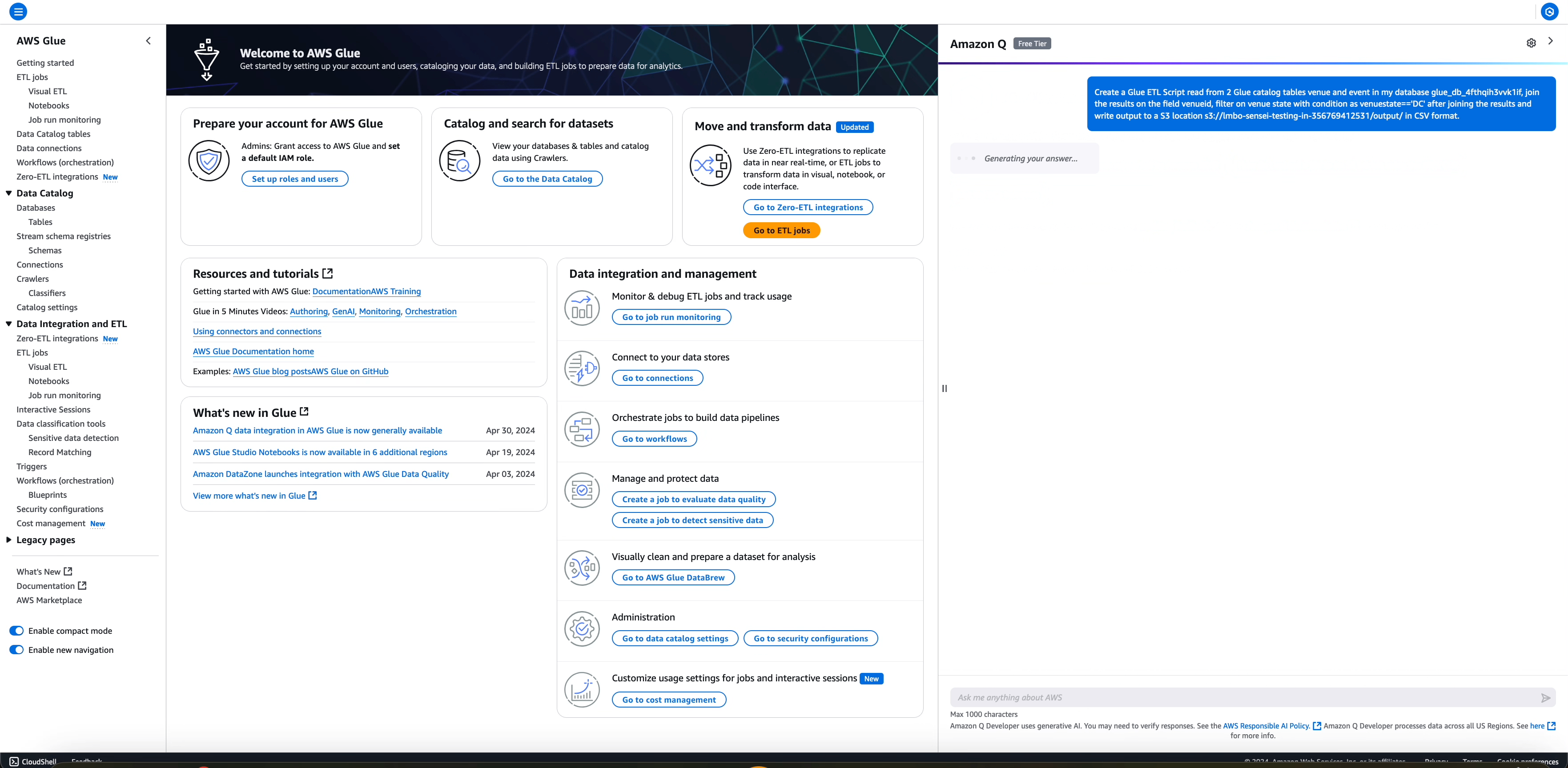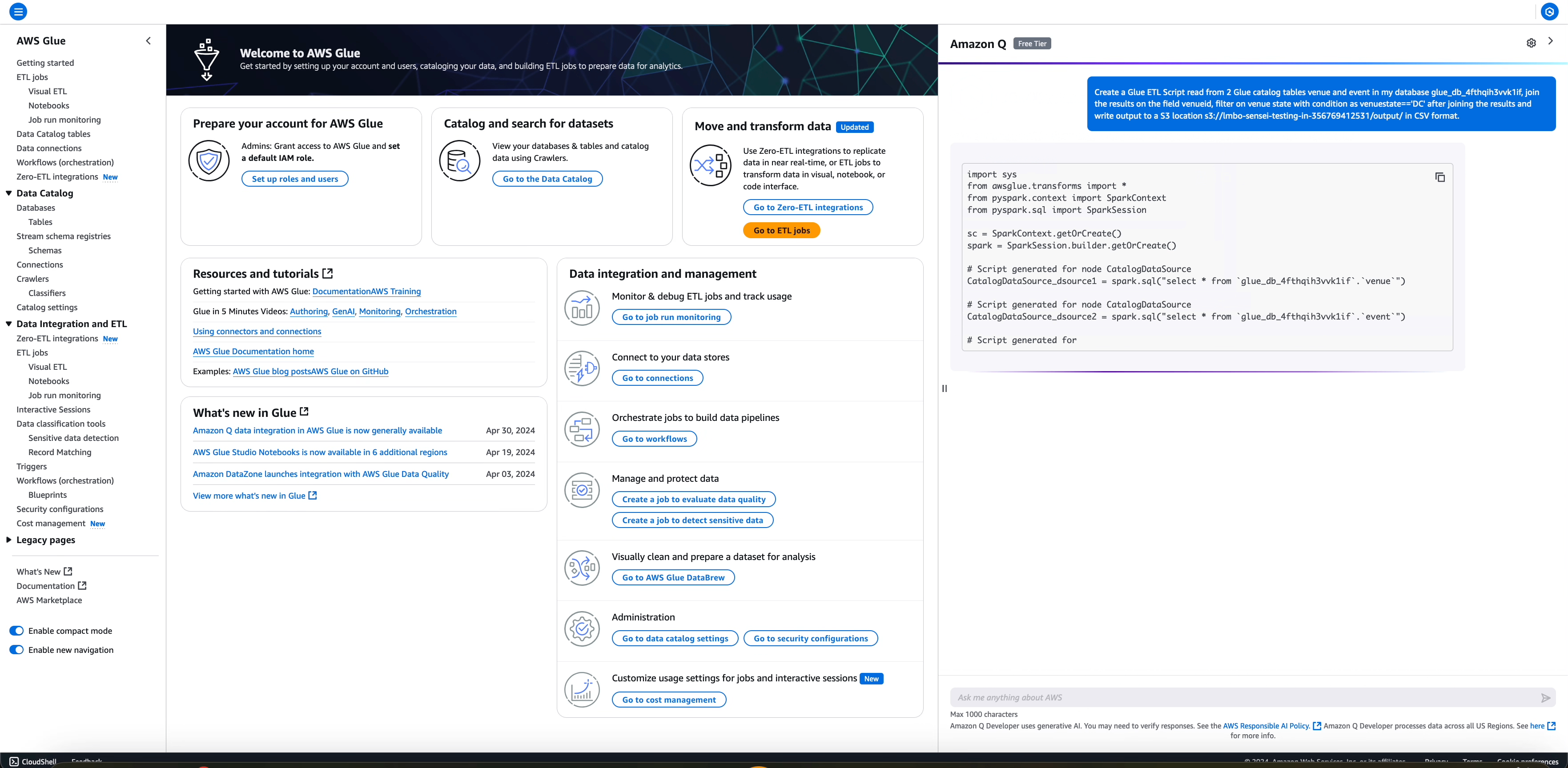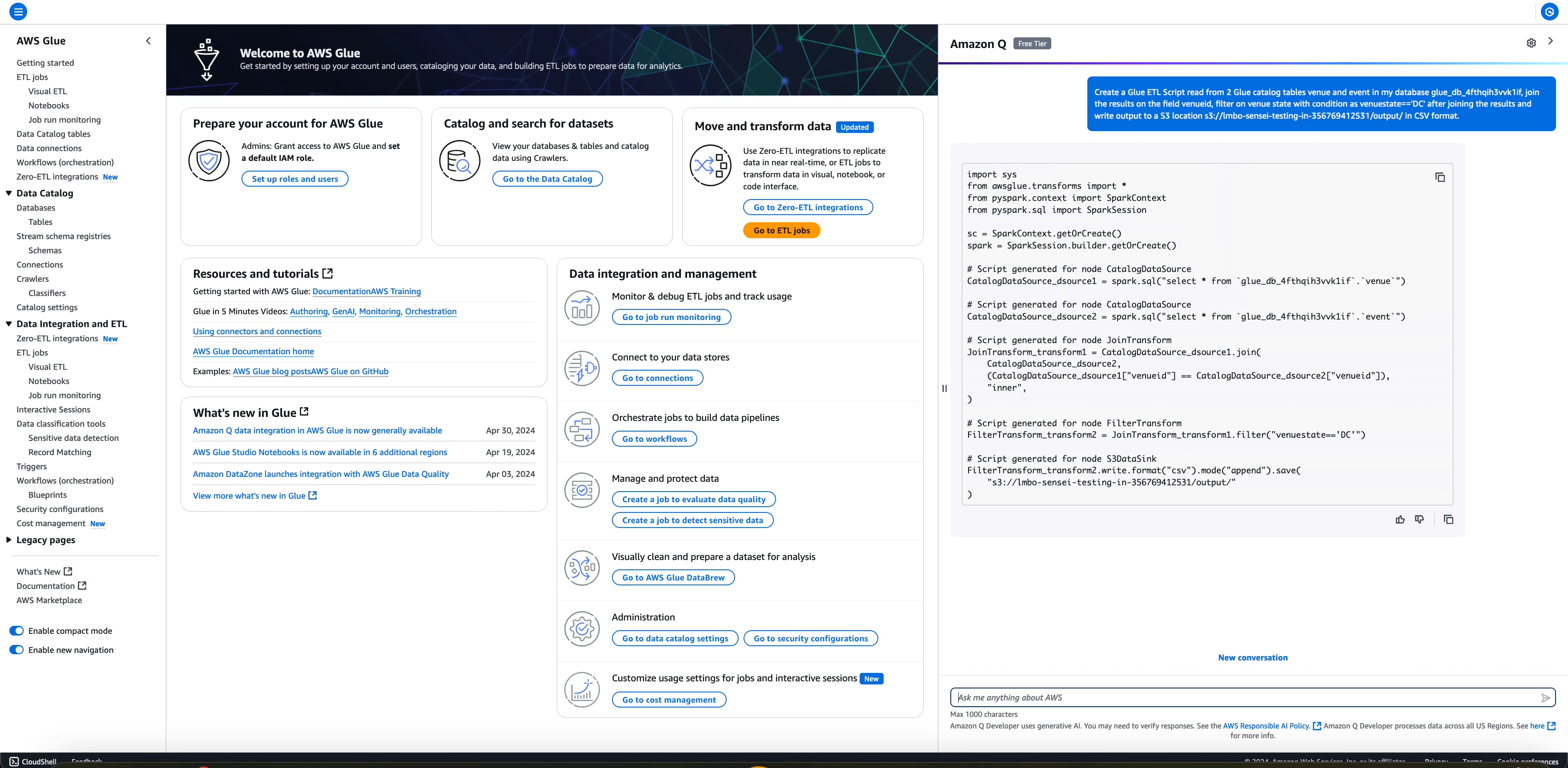
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node CatalogDataSource CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`") # Script generated for node CatalogDataSource CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`") # Script generated for node JoinTransform JoinTransform_transform1 = CatalogDataSource_dsource1.join( CatalogDataSource_dsource2, (CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]), "inner", ) # Script generated for node FilterTransform FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'") # Script generated for node S3DataSink FilterTransform_transform2.write.format("csv").mode("append").save( "s3://amz-s3-demo-bucket/output//output/" )
Limitaciones
-
Traspaso de contexto:
-
La característica de reconocimiento del contexto solo transfiere el contexto de la consulta anterior del usuario dentro de la misma conversación. No retiene el contexto más allá de la consulta inmediatamente anterior.
-
-
Compatibilidad para configuraciones de nodos:
-
Actualmente, el reconocimiento del contexto solo admite un subconjunto de las configuraciones requeridas de varios nodos.
-
La compatibilidad con campos opcionales está prevista en las próximas versiones.
-
-
Disponibilidad:
-
El reconocimiento del contexto y la compatibilidad con DataFrame están disponibles en los cuadernos de Q Chat y SageMaker Unified Studio. Sin embargo, estas funciones aún no están disponibles en los cuadernos de AWS Glue Studio.
-
