Conector de DynamoDB con compatibilidad con Spark DataFrame
El conector de DynamoDB con compatibilidad con Spark DataFrame permite leer y escribir en tablas de DynamoDB mediante las API de Spark DataFrame. Los pasos de configuración del conector son los mismos que los del conector basado en DynamicFrame y pueden consultarse aquí.
Para cargar la biblioteca del conector basado en DataFrame, asegúrese de adjuntar una conexión de DynamoDB a la tarea de Glue.
nota
La interfaz de usuario (UI) de la consola de Glue actualmente no admite la creación de una conexión de DynamoDB. Puede usar la CLI de Glue (CreateConnection) para crear una conexión de DynamoDB:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
Una vez creada la conexión de DynamoDB, puede adjuntarla a su tarea de Glue mediante la CLI (CreateJob, UpdateJob) o directamente desde la página «Job details»:
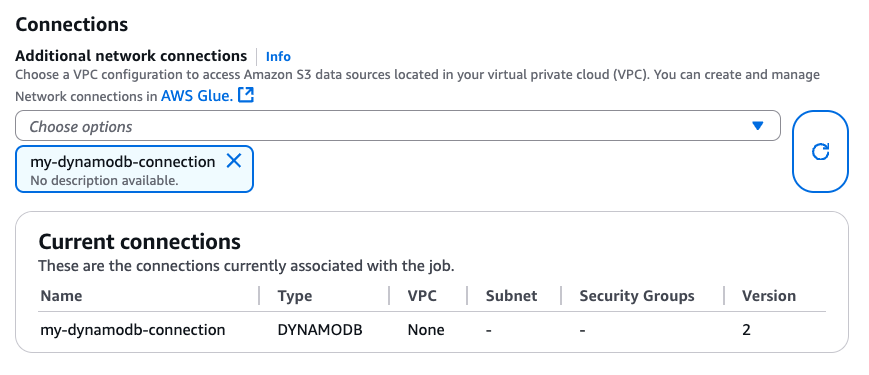
Una vez que se asegure de que una conexión de tipo DYNAMODB esté adjunta a su tarea de Glue, podrá utilizar las siguientes operaciones de lectura, escritura y exportación del conector basado en DataFrame.
Lectura y escritura en DynamoDB con el conector basado en DataFrame
En los siguientes ejemplos de código, se muestra cómo leer y escribir en tablas de DynamoDB mediante el conector basado en DataFrame. Demuestran la lectura de una tabla y la escritura en otra tabla.
Uso de la exportación de DynamoDB mediante el conector basado en DataFrame
Se prefiere la operación de exportación a la de lectura para tablas de DynamoDB con tamaños superiores a 80 GB. En los siguientes ejemplos de código, se muestra cómo leer desde una tabla, exportar a S3 e imprimir el número de particiones mediante el conector basado en DataFrame.
nota
La funcionalidad de exportación de DynamoDB está disponible a través del objeto Scala DynamoDBExport. Los usuarios de Python pueden acceder a esta funcionalidad mediante la interoperabilidad con la JVM de Spark o usar el AWS SDK para Python (boto3) con la API DynamoDB ExportTableToPointInTime.
Opciones de configuración
Opciones de lectura
| Opción | Descripción | Valor predeterminado |
|---|---|---|
dynamodb.input.tableName |
Nombre de la tabla de DynamoDB (obligatorio) | - |
dynamodb.throughput.read |
Las unidades de capacidad de lectura (RCU) que se van a utilizar. Si no se especifica, dynamodb.throughput.read.ratio se utiliza para el cálculo. |
- |
dynamodb.throughput.read.ratio |
La proporción de unidades de capacidad de lectura (RCU) que se va a utilizar | 0,5 |
dynamodb.table.read.capacity |
La capacidad de lectura de la tabla bajo demanda que se utiliza para calcular el rendimiento Este parámetro solo es efectivo en tablas con capacidad bajo demanda. Usa de forma predeterminada unidades de rendimiento de lectura en estado semiactivo. | - |
dynamodb.splits |
Define cuántos segmentos se utilizan en operaciones de escaneo en paralelo. Si no se proporciona, el conector calculará un valor predeterminado razonable. | - |
dynamodb.consistentRead |
Uso de lecturas altamente coherentes | FALSO |
dynamodb.input.retry |
Define cuántos reintentos se realizan cuando se produce una excepción que admite reintento. | 10 |
Opciones de escritura
| Opción | Descripción | Valor predeterminado |
|---|---|---|
dynamodb.output.tableName |
Nombre de la tabla de DynamoDB (obligatorio) | - |
dynamodb.throughput.write |
Las unidades de capacidad de escritura (WCU) que se van a utilizar Si no se especifica, se utiliza dynamodb.throughput.write.ratio para el cálculo. |
- |
dynamodb.throughput.write.ratio |
La proporción de unidades de capacidad de escritura (WCU) que se va a utilizar | 0,5 |
dynamodb.table.write.capacity |
La capacidad de escritura de la tabla bajo demanda que se utiliza para calcular el rendimiento. Este parámetro solo es efectivo en tablas con capacidad bajo demanda. Usa de forma predeterminada unidades de rendimiento de escritura en estado semiactivo. | - |
dynamodb.item.size.check.enabled |
Si es «true», el conector calcula el tamaño del elemento e interrumpe la operación si dicho tamaño supera el tamaño máximo, antes de escribir en la tabla de DynamoDB. | TRUE |
dynamodb.output.retry |
Define cuántos reintentos se realizan cuando se produce una excepción que admite reintento. | 10 |
Opciones de exportación
| Opción | Descripción | Valor predeterminado |
|---|---|---|
dynamodb.export |
Si se configura como ddb, se habilita el conector de exportación de DynamoDB de AWS Glue, mediante el cual se invocará una nueva ExportTableToPointInTimeRequet durante la tarea de AWS Glue. Se generará una nueva exportación con la ubicación pasada desde dynamodb.s3.bucket y dynamodb.s3.prefix. Si se configura como s3, se habilita el conector de exportación de DynamoDB de AWS Glue, pero se omite la creación de una nueva exportación de DynamoDB y, en su lugar, se usan dynamodb.s3.bucket y dynamodb.s3.prefix como la ubicación en Amazon S3 de la exportación anterior de esa tabla. |
ddb |
dynamodb.tableArn |
La tabla de DynamoDB desde la que se va a leer Obligatorio si dynamodb.export se establece en ddb. |
|
dynamodb.simplifyDDBJson |
Si se configura como true, realiza una transformación para simplificar el esquema de la estructura JSON de DynamoDB presente en las exportaciones. |
FALSO |
dynamodb.s3.bucket |
El bucket de S3 para almacenar datos temporales durante la exportación de DynamoDB (obligatorio). | |
dynamodb.s3.prefix |
El prefijo de S3 para almacenar datos temporales durante la exportación de DynamoDB | |
dynamodb.s3.bucketOwner |
Indica el propietario del bucket necesario para el acceso entre cuentas a Amazon S3. | |
dynamodb.s3.sse.algorithm |
El tipo de cifrado utilizado en el bucket donde se almacenarán los datos temporales Los valores válidos son AES256 y KMS. |
|
dynamodb.s3.sse.kmsKeyId |
El ID de la clave administrada de AWS KMS utilizada para cifrar el bucket de S3 donde se almacenarán los datos temporales (si corresponde). | |
dynamodb.exportTime |
Un punto en el tiempo en el que debe realizarse la exportación. Valores válidos: cadenas que representan instantes ISO-8601 |
Opciones generales
| Opción | Descripción | Valor predeterminado |
|---|---|---|
dynamodb.sts.roleArn |
El ARN del rol de IAM que se debe asumir para el acceso entre cuentas. | - |
dynamodb.sts.roleSessionName |
Nombre de la sesión de STS | glue-dynamodb-sts-session |
dynamodb.sts.region |
Región del cliente de STS (para la asunción de roles entre regiones) | Igual que la opción region |
