Utilizar Auto Scaling para AWS Glue
El escalado automático está disponible para trabajos ETL, sesiones interactivas y trabajos de transmisión de AWS Glue con AWS Glue versión 3.0 o posterior.
Con Auto Scaling habilitado, obtendrá los siguientes beneficios:
-
AWS Glue agrega automáticamente y elimina empleados del clúster en función del paralelismo en cada etapa o microlote de la ejecución del trabajo.
-
Elimina la necesidad de experimentar y decidir el número de empleados que asignará a sus trabajos de ETL de AWS Glue.
-
Si elije el número máximo de empleados, AWS Glue elegirá el tamaño correcto de recursos para la carga de trabajo.
-
Puede ver cómo cambia el tamaño del clúster durante la ejecución del trabajo si mira las métricas de CloudWatch en la página de detalles de ejecución de trabajo de AWS Glue Studio.
El escalado automático para trabajos de ETL de AWS Glue y streaming permite escalar horizontalmente y reducir horizontalmente bajo demanda los recursos de computación de sus trabajos de AWS Glue. El escalado vertical bajo demanda lo ayuda a asignar solo los recursos informáticos necesarios, en principio, en el inicio de la ejecución de trabajos, así como a aprovisionar los recursos necesarios según la demanda durante el trabajo.
El escalado automático también admite la reducción horizontal dinámica de los recursos de trabajo de AWS Glue durante el transcurso de un trabajo. Durante la ejecución de un trabajo, cuando la aplicación Spark solicite más ejecutores, se agregarán más empleados al clúster. Cuando el ejecutor ha estado inactivo sin tareas de cálculo activas, se eliminarán el ejecutor y el empleado correspondiente.
Los escenarios comunes en los que el escalado automático ayuda con el costo y el uso de sus aplicaciones de Spark incluyen:
-
un controlador de Spark que enumera un gran número de archivos en Amazon S3 o lleva a cabo una carga mientras los ejecutores se encuentran inactivos
-
etapas en las que Spark se ejecuta con solo unos pocos ejecutores debido al sobreaprovisionamiento
-
sesgos de datos o demanda de cálculo desigual en todas las etapas de Spark
Requisitos
El escalado automático solo se encuentra disponible para la versión 3.0 o posterior de AWS Glue. Para utilizar el escalado automático, puede seguir la guía de migración a fin de migrar los trabajos existentes a la versión 3.0 o posterior de AWS Glue, o bien crear trabajos nuevos con la versión 3.0 o posterior de AWS Glue.
El escalado automático se encuentra disponible para trabajos de AWS Glue con los tipos de trabajadores G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, R.8X o G.025X (solo con trabajos de streaming). Las DPU estándar no son compatibles con el escalado automático.
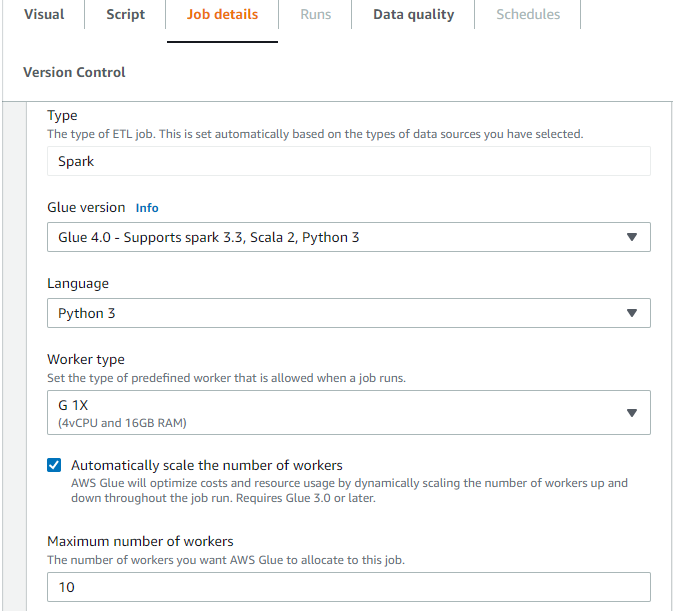
Habilitar Auto Scaling en AWS Glue Studio
En la página Detalles del trabajo en AWS Glue Studio, elija el tipo como Spark o Spark Streaming y Versión de Glue como Glue 3.0 o posterior. A continuación, se mostrará una casilla de verificación debajo de Tipo de trabajador.
-
Seleccione la opción Automatically scale the number of workers (Escalar automáticamente el número de empleados).
-
Establezca el Maximum number of workers (Número máximo de empleados) para definir el número máximo de empleados que se pueden asignar a la ejecución de trabajos.
Habilitación de Auto Scaling con AWS CLI o SDK
Para habilitar el escalado automático desde la CLI de AWS para la ejecución de un trabajo, ejecute start-job-run con la siguiente configuración:
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
Una vez que haya finalizado la ejecución de un trabajo de ETL, también puede llamar a get-job-run para comprobar el uso real de recursos de la ejecución del trabajo en segundos de DPU. Nota: El nuevo campo DPUSeconds solo se mostrará para los trabajos por lotes en AWS Glue 4.0 o posterior con el escalado automático activado. Este campo no es compatible con trabajos de streaming.
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
También se pueden configurar ejecuciones de trabajos con Auto Scaling mediante el AWS Glue SDK con la misma configuración.
Habilitación del escalado automático con sesiones interactivas
Para habilitar el escalado automático al crear trabajos de AWS Glue con sesiones interactivas, consulte Configuring AWS Glue interactive sessions.
Sugerencias y consideraciones
Sugerencias y consideraciones para afinar el escalado automático de AWS Glue con precisión:
-
En caso de que no sepa el valor inicial del número máximo de trabajadores, puede empezar con el cálculo aproximado que se explica en Estimate AWS Glue DPU. No debe configurar un valor extremadamente alto en el número máximo de trabajadores para un volumen de datos muy bajo.
-
El escalado automático para AWS Glue configura
spark.sql.shuffle.partitionsyspark.default.parallelismen función del número máximo de DPU (calculada con el número máximo de trabajadores y el tipo de trabajador) configurado en el trabajo. Si prefiere el valor fijo en esas configuraciones, puede sobrescribir estos parámetros con los siguientes parámetros de trabajo:-
Clave:
--conf -
Valor:
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
Para los trabajos de streaming, de forma predeterminada, AWS Glue no se escala automáticamente dentro de los microlotes y se requieren varios microlotes para iniciar el escalado automático. En caso de que desee habilitar el escalado automático en microlotes, proporcione
--auto-scale-within-microbatch. Para obtener más información, consulte Job parameter reference.
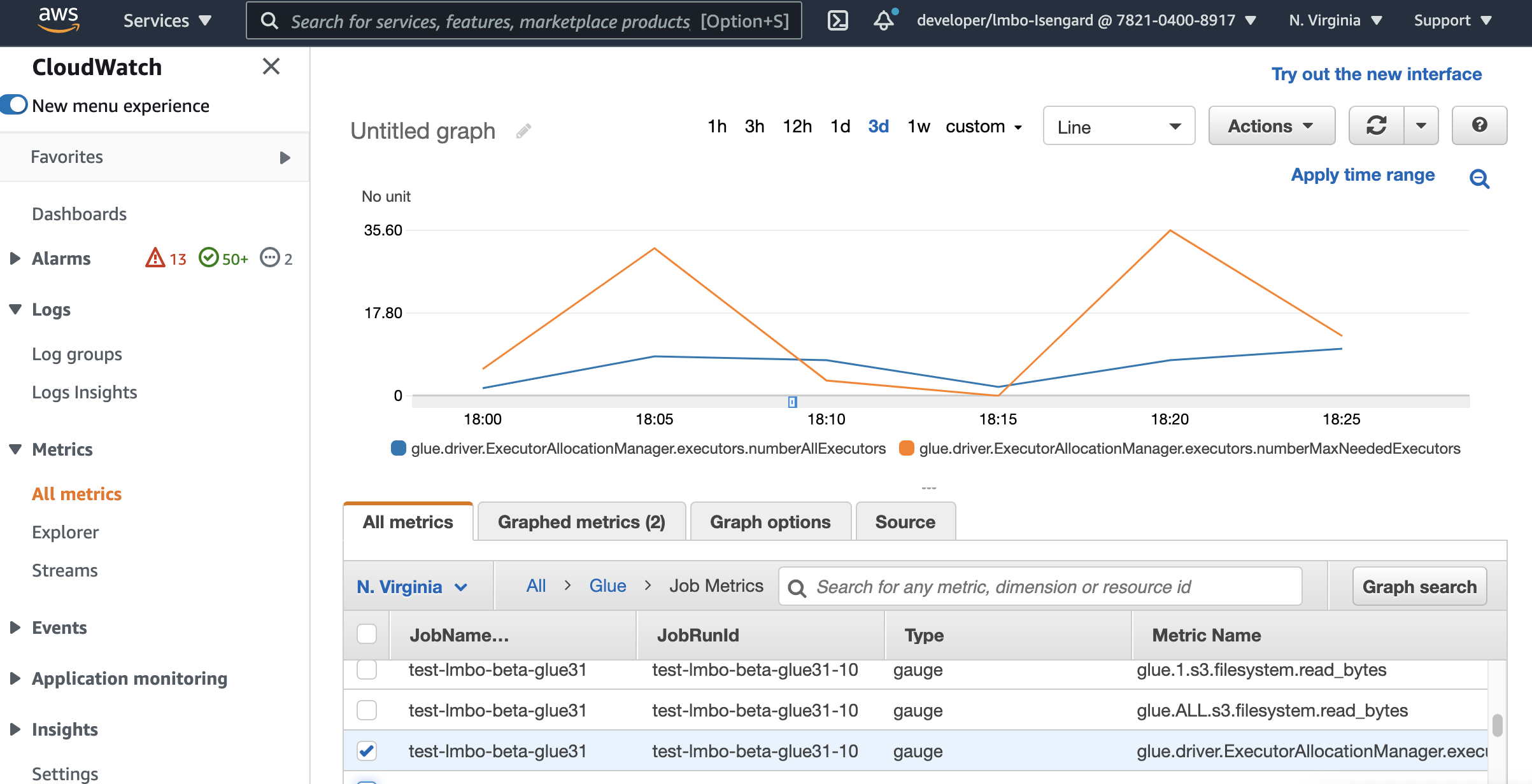
Monitorear Auto Scaling con las métricas de Amazon CloudWatch.
Las métricas de ejecutor de CloudWatch se encuentran disponibles para sus trabajos de AWS Glue 3.0 o posterior si habilita el escalado automático. Las métricas se pueden utilizar para monitorear la demanda y la utilización optimizada de los ejecutores en sus aplicaciones Spark habilitadas con Auto Scaling. Para obtener más información, consulte Supervisión de AWS Glue con métricas de Amazon CloudWatch.
También puede utilizar las métricas de observabilidad de AWS Glue para obtener información sobre la utilización de los recursos. Por ejemplo, al supervisar glue.driver.workerUtilization, puede supervisar la cantidad de recursos que se usó realmente con y sin el escalado automático. Por otro ejemplo, al supervisar glue.driver.skewness.job y glue.driver.skewness.stage, puede ver cómo están sesgados los datos. Esa información le ayudará a decidir si se habilita el escalado automático y se afinan las configuraciones. Para obtener más información, consulte Supervisión con Monitorización con métricas de observabilidad de AWS Glue.
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors
-
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
Para obtener más información sobre estas métricas, consulte Monitorización de la planificación de la capacidad de DPU.
nota
Las métricas de ejecución de CloudWatch no están disponibles para las sesiones interactivas.
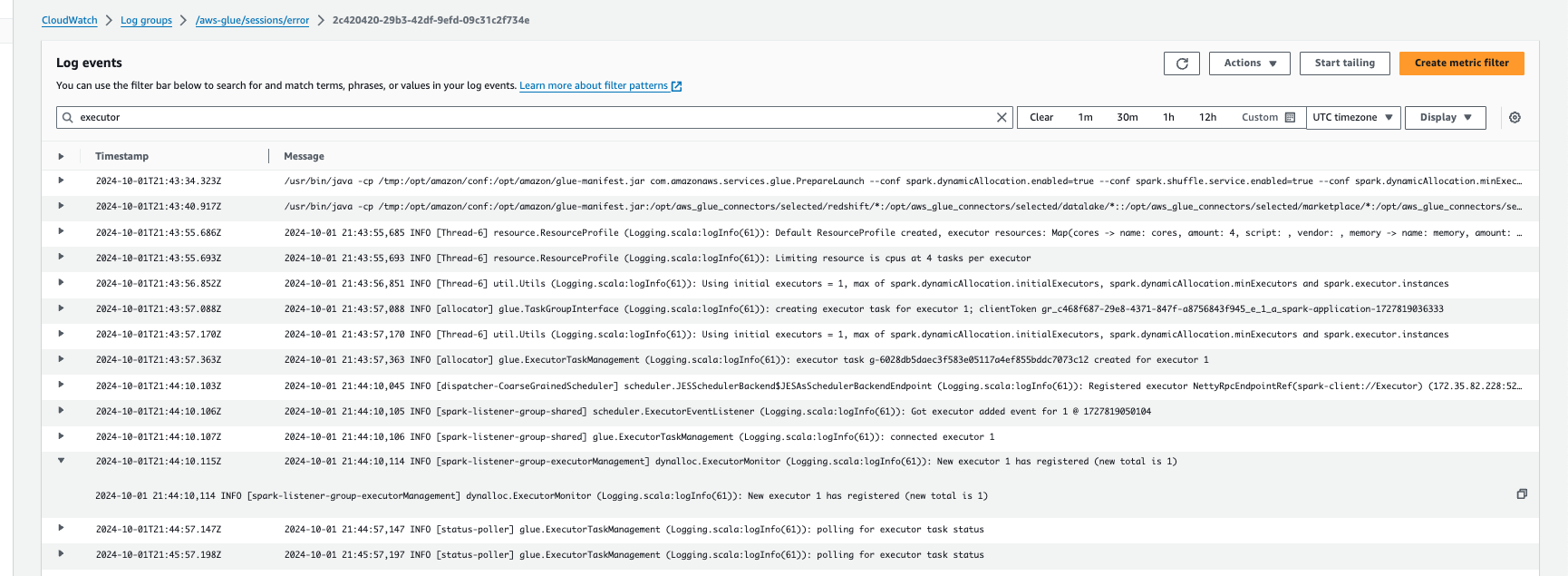
Supervisión del escalado automático con Registros de Amazon CloudWatch
Si usa sesiones interactivas, puede supervisar el número de ejecutores al activar los Registros de Amazon CloudWatch continuos y buscar “executor” en los registros, o bien mediante la interfaz de usuario de Spark. Para ello, utilice el comando mágico %%configure para habilitar el registro continuo junto con enable auto scaling.
%%configure{ "--enable-continuous-cloudwatch-log": "true", "--enable-auto-scaling": "true" }
En los eventos de registro de Amazon CloudWatch, busque “executor” en los registros:
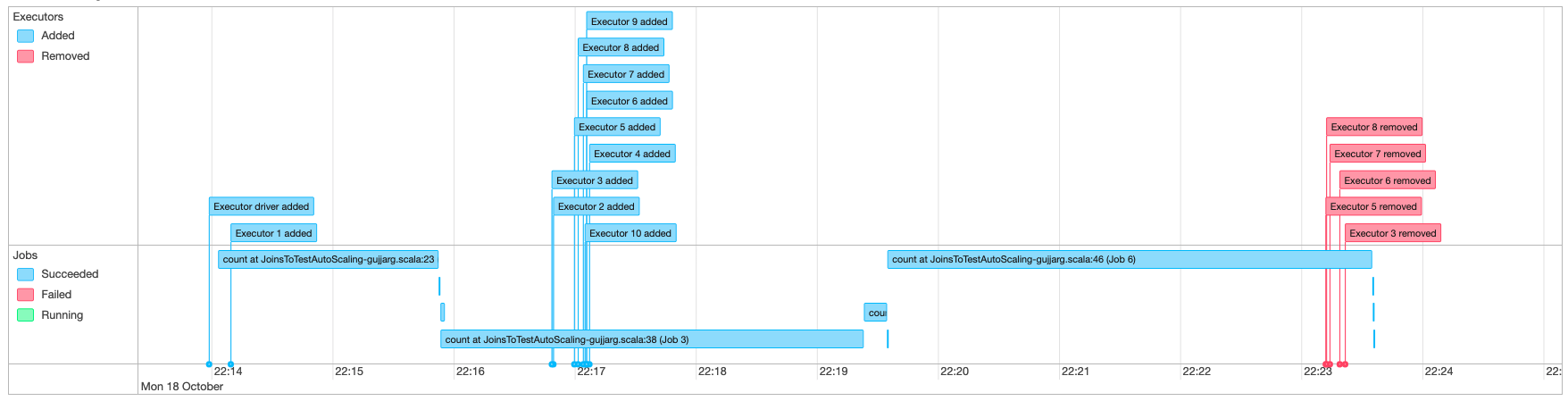
Monitorear Auto Scaling con la IU de Spark
Con Auto Scaling habilitado, también puede supervisar los ejecutores que se agregan y eliminan con escalado vertical y reducción vertical dinámicos en función de la demanda de sus trabajos de AWS Glue mediante la IU de Glue Spark. Para obtener más información, consulte Habilitación de la interfaz de usuario web de Apache Spark para trabajos de AWS Glue.
Cuando usa sesiones interactivas desde el cuaderno de Jupyter, puede ejecutar el siguiente comando mágico para habilitar el escalado automático junto con la interfaz de usuario de Spark:
%%configure{ "--enable-auto-scaling": "true", "--enable-continuous-cloudwatch-log": "true" }
Supervisión del uso de DPU en ejecución de trabajos de Auto Scaling
Puede utilizar la Vista de ejecución de trabajos de AWS Glue Studio para comprobar el uso de DPU de los trabajos de escalado automático.
-
Elija Supervisión en el panel de navegación de AWS Glue Studio. Aparecerá la página Monitoring (Supervisión).
-
Desplácese hacia abajo hasta el gráfico Job runs (Ejecuciones de trabajos).
-
Navegue hasta la ejecución del trabajo que le interese y desplácese hasta la columna DPU hours (Horas de DPU) para comprobar el uso de la ejecución del trabajo en cuestión.
Limitaciones
En la actualidad, el streaming de AWS Glue de Auto Scaling no soporta una unión de DataFrame en streaming con un DataFrame estático creado fuera de ForEachBatch. Un DataFrame estático creado dentro de ForEachBatch funcionará según lo previsto.
