Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Habilitación de Lake Formation con Amazon EMR en EKS
Con Amazon EMR versión 7.7 y versiones posteriores, puede aprovechar AWS Lake Formation para aplicar controles de acceso detallados en las tablas del catálogo de datos respaldadas por Amazon S3. Esta capacidad le permite configurar los controles de acceso a nivel de tabla, fila, columna y celda para las consultas de lectura dentro de sus trabajos de Spark de Amazon EMR en EKS.
En esta sección, explicamos cómo crear una configuración de seguridad y cómo configurar Lake Formation para que funcione con Amazon EMR. También explicamos cómo crear un clúster virtual con la configuración de seguridad que creó para Lake Formation. Estas secciones deben completarse en secuencia.
Paso 1: configurar permisos a nivel de columna, fila o celda basados en Lake Formation
En primer lugar, para aplicar permisos a nivel de fila y columna con Lake Formation, el administrador del lago de datos de Lake Formation debe establecer la etiqueta de LakeFormationAuthorizedCallersesión. Lake Formation usa esta etiqueta de sesión para autorizar a los intermediarios y proporcionar acceso al lago de datos.
Navegue a la consola de AWS Lake Formation y seleccione la opción de configuración de integración de aplicaciones en la sección Administración de la barra lateral. Luego, marque la casilla Permitir que motores externos filtren datos en las ubicaciones de Amazon S3 registradas en Lake Formation. Añade la AWS cuenta en la que IDs se ejecutarían los trabajos de Spark y los valores de la etiqueta de sesión.
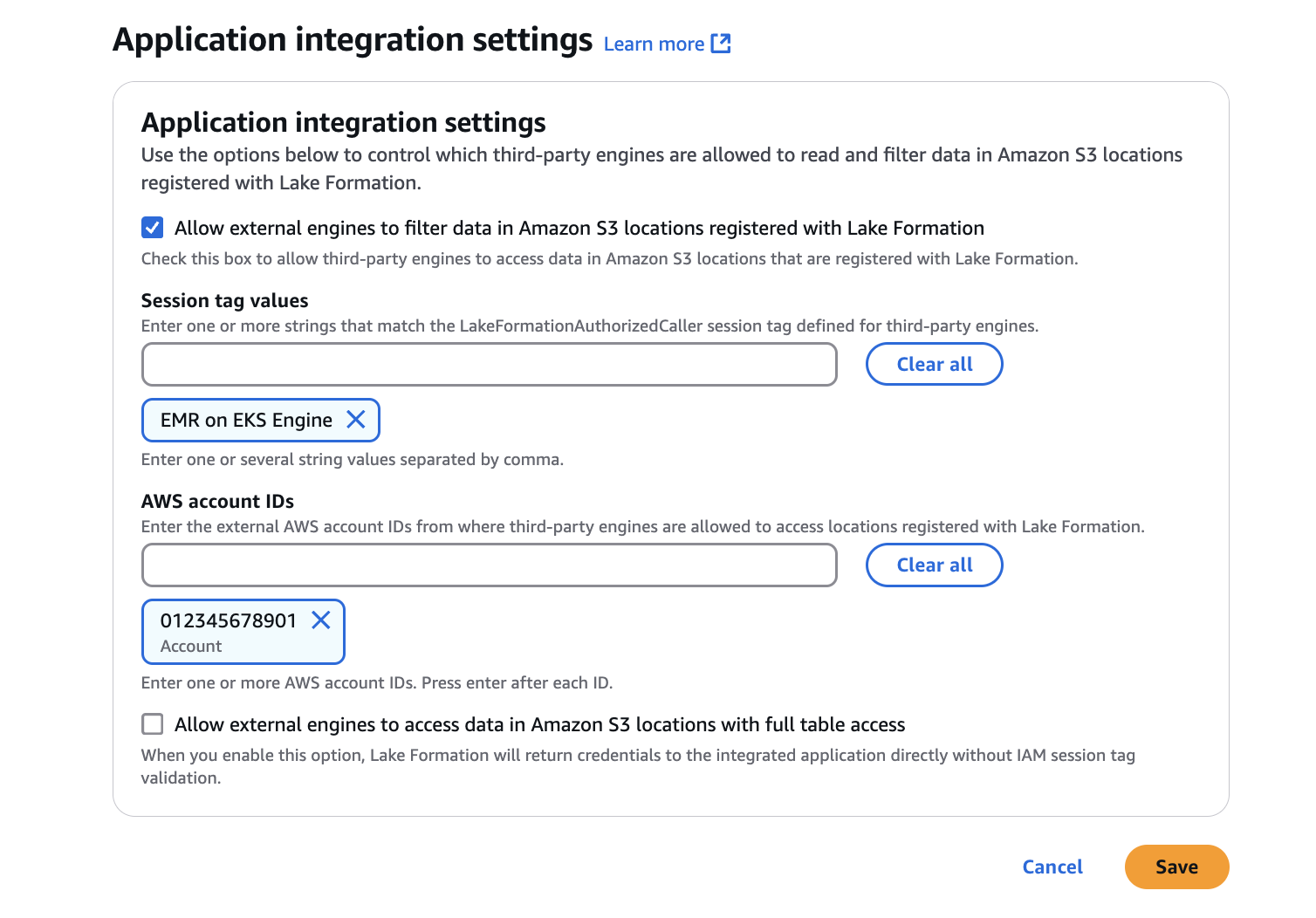
Ten en cuenta que la etiqueta de LakeFormationAuthorizedCallersesión que se pasa aquí se incluye SecurityConfigurationmás adelante cuando configuras las funciones de IAM, en la sección 3.
Paso 2: configurar los permisos RBAC de EKS
A continuación, configurará permisos para control de acceso basado en roles.
Proporcione permisos de clúster de EKS al servicio de Amazon EMR en EKS
El servicio Amazon EMR en EKS debe tener permisos de rol de clúster de EKS para poder crear permisos de espacios de nombres cruzados a fin de que el controlador del sistema genere ejecutores de usuarios en el espacio de nombres del usuario.
Cree su rol del clúster
Esta muestra define los permisos para una colección de recursos.
vim emr-containers-cluster-role.yaml --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: emr-containers rules: - apiGroups: [""] resources: ["namespaces"] verbs: ["get"] - apiGroups: [""] resources: ["serviceaccounts", "services", "configmaps", "events", "pods", "pods/log"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "deletecollection", "annotate", "patch", "label"] - apiGroups: [""] resources: ["secrets"] verbs: ["create", "patch", "delete", "watch"] - apiGroups: ["apps"] resources: ["statefulsets", "deployments"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "annotate", "patch", "label"] - apiGroups: ["batch"] resources: ["jobs"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "annotate", "patch", "label"] - apiGroups: ["extensions", "networking.k8s.io"] resources: ["ingresses"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "annotate", "patch", "label"] - apiGroups: ["rbac.authorization.k8s.io"] resources: ["clusterroles","clusterrolebindings","roles", "rolebindings"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "deletecollection", "annotate", "patch", "label"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "deletecollection", "annotate", "patch", "label"] - apiGroups: ["kyverno.io"] resources: ["clusterpolicies"] verbs: ["create", "delete"] ---
kubectl apply -f emr-containers-cluster-role.yaml
Cree enlaces de roles de clúster
vim emr-containers-cluster-role-binding.yaml --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: emr-containers subjects: - kind: User name: emr-containers apiGroup: rbac.authorization.k8s.io roleRef: kind: ClusterRole name: emr-containers apiGroup: rbac.authorization.k8s.io ---
kubectl apply -f emr-containers-cluster-role-binding.yaml
Proporcione acceso de espacio de nombres al servicio de Amazon EMR en EKS
Cree dos espacios de nombres de Kubernetes, uno para el controlador de usuario y los ejecutores, y otro para el controlador y los ejecutores del sistema. Habilite el acceso al servicio Amazon EMR en EKS para enviar trabajos en los espacios de nombres de usuario y sistema. Siga la guía existente para proporcionar acceso a cada espacio de nombres, que está disponible en Enable cluster access using aws-auth.
Paso 3: configurar los roles de IAM para los componentes del perfil de usuario y del sistema
En tercer lugar, debe configurar los roles para componentes específicos. Un trabajo de Spark habilitado para Lake Formation tiene dos componentes: usuario y sistema. El controlador de usuario y los ejecutores se ejecutan en el espacio de nombres de usuario y están vinculados al JobExecutionRole que se transfiere a la API. StartJobRun El controlador y los ejecutores del sistema se ejecutan en el espacio de nombres del sistema y están vinculados a la función. QueryEngine
Configure el rol Query Engine
El QueryEngine rol está vinculado a los componentes del espacio del sistema y tendría permisos para asumir la etiqueta JobExecutionRolewith LakeFormationAuthorizedCallerSession. La política de permisos de IAM del rol Query Engine es la siguiente:
Configure la política de confianza del rol Query Engine para que confíe en el espacio de nombres del sistema Kubernetes.
aws emr-containers update-role-trust-policy \ --cluster-nameeks cluster\ --namespaceeks system namespace\ --role-namequery_engine_iam_role_name
Para obtener más información, consulte Actualización de una política de confianza de rol.
Configurar el rol de ejecución de tareas
Los permisos de Lake Formation controlan el acceso a los recursos del catálogo de datos de AWS Glue, a las ubicaciones de Amazon S3 y a los datos subyacentes en esas ubicaciones. Los permisos de la IAM controlan el acceso a Lake Formation and AWS Glue APIs y a los recursos. Aunque es posible que tenga el permiso de Lake Formation para acceder a una tabla del Catálogo de datos (SELECT), la operación fallará si no tiene el permiso de IAM en la operativa de la API glue:Get*.
Política de permisos de IAM de JobExecutionRole: El JobExecutionrol debe incluir las declaraciones de política en su política de permisos.
Política de confianza de IAM para: JobExecutionRole
Configure el rol de la política de confianza del trabajo para que confíe en el espacio de nombres de usuario de Kubernetes:
aws emr-containers update-role-trust-policy \ --cluster-nameeks cluster\ --namespaceeks User namespace\ --role-namejob_execution_role_name
Para obtener más información, consulte Update the trust policy of the job execution role.
Paso 4: establecer la configuración de seguridad
Para ejecutar un trabajo habilitado para Lake Formation, debe crear una configuración de seguridad.
aws emr-containers create-security-configuration \ --name 'security-configuration-name' \ --security-configuration '{ "authorizationConfiguration": { "lakeFormationConfiguration": { "authorizedSessionTagValue": "SessionTag configured in LakeFormation", "secureNamespaceInfo": { "clusterId": "eks-cluster-name", "namespace": "system-namespace-name" }, "queryEngineRoleArn": "query-engine-IAM-role-ARN" } } }'
Asegúrese de que la etiqueta de sesión introducida en el campo authorizedSessionTagValue pueda autorizar a Lake Formation. Establezca el valor como el configurado en Lake Formation en Paso 1: configurar permisos a nivel de columna, fila o celda basados en Lake Formation.
Paso 5: crear un clúster virtual
Cree un clúster virtual de Amazon EMR en EKS con una configuración de seguridad.
aws emr-containers create-virtual-cluster \ --name my-lf-enabled-vc \ --container-provider '{ "id": "eks-cluster", "type": "EKS", "info": { "eksInfo": { "namespace": "user-namespace" } } }' \ --security-configuration-idSecurityConfiguraionId
Asegúrese de pasar el SecurityConfigurationID del paso anterior para que la configuración de autorización de Lake Formation se aplique a todos los trabajos que se ejecutan en el clúster virtual. Para obtener más información, consulte Register the Amazon EKS cluster with Amazon EMR.
Paso 6: Enviar un trabajo en el FGAC Enabled VirtualCluster
El proceso de presentación de trabajos es el mismo tanto para los trabajos que son de Lake Formation como los que no lo son. Para obtener más información, consulte Submit a job run with StartJobRun.
El controlador Spark, el ejecutor y los registros de eventos del controlador del sistema se almacenan en el depósito S3 de la cuenta de AWS servicio para su depuración. Recomendamos configurar una clave KMS administrada por el cliente en Job Run para cifrar todos los registros almacenados en el AWS depósito de servicio. Para obtener más información sobre cómo habilitar el cifrado de registros, consulte Encrypting Amazon EMR on EKS logs.
