Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Qué ocurre cuando envía trabajo a un clúster virtual de Amazon EMR en EKS
Al registrar Amazon EMR con un espacio de nombres de Kubernetes en Amazon EKS, se crea un clúster virtual. Amazon EMR puede entonces ejecutar cargas de trabajo de análisis en ese espacio de nombres. Cuando utiliza Amazon EMR en EKS para enviar trabajos de Spark al clúster virtual, Amazon EMR en EKS solicita al programador de Kubernetes de Amazon EKS que programe los pods.
Los siguientes pasos y diagrama ilustran el flujo de trabajo de Amazon EMR en EKS:
-
Utilice un clúster de Amazon EKS existente o cree uno mediante la utilidad de línea de comandos eksctl o la consola de Amazon EKS.
-
Para crear un clúster virtual, registre Amazon EMR con un espacio de nombres en un clúster EKS.
-
Envíe su trabajo al clúster virtual mediante el SDK AWS CLI o el SDK.
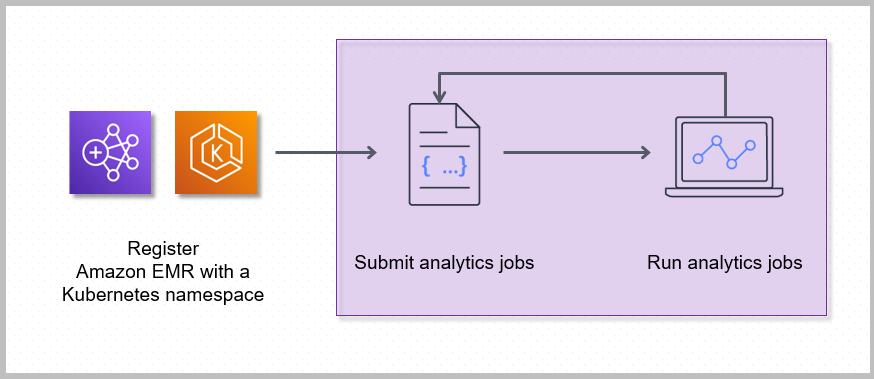
Por cada trabajo que ejecuta, Amazon EMR en EKS crea un contenedor con una imagen base de Amazon Linux 2, Apache Spark y las dependencias asociadas. Cada trabajo se ejecuta en un pod que descarga el contenedor y comienza a ejecutarlo. El pod termina una vez terminado el trabajo. Si la imagen del contenedor se implementó previamente en el nodo, se utiliza una imagen almacenada en caché y se omite la descarga. Los contenedores asociados, como los reenviadores de registros o métricas, se pueden implementar en el pod. Una vez finalizado el trabajo, podrá seguir depurándolo mediante la interfaz de usuario de la aplicación de Spark en la consola de Amazon EMR.
