Ayude a mejorar esta página
Para contribuir a esta guía del usuario, elija el enlace Edit this page on GitHub que se encuentra en el panel derecho de cada página.
Supervisión del tráfico de cargas de trabajo de Kubernetes con la observabilidad de la red de contenedores
Amazon EKS ofrece características de observabilidad de la red mejoradas que proporcionan información más detallada sobre el entorno de redes de contenedores. Estas capacidades lo ayudan a comprender, supervisar y solucionar mejor los problemas de su entorno de red de Kubernetes en AWS. Con una observabilidad de la red de contenedores mejorada, puede aprovechar las métricas detalladas relacionadas con la red para detectar mejor y proactivamente las anomalías en el tráfico de clústeres, los flujos entre zonas de disponibilidad y los servicios de AWS. Con estas métricas, puede medir el rendimiento del sistema y visualizar las métricas subyacentes con su pila de observabilidad preferida.
Además, Amazon EKS ahora ofrece visualizaciones de supervisión de la red en la consola de AWS que aceleran y mejoran la solución de problemas precisa para un análisis más rápido de la causa raíz. También puede aprovechar estas capacidades visuales para identificar los recursos con un mayor consumo y los flujos de red que causan las retransmisiones y los tiempos de espera de las retransmisiones, lo que elimina los puntos ciegos durante los incidentes.
Amazon CloudWatch Network Flow Monitor permite el uso de estas capacidades.
Casos de uso
Medición del rendimiento de la red para detectar anomalías
Varios equipos estandarizan una pila de observabilidad que les permite medir el rendimiento del sistema, visualizar las métricas del sistema y alarmarse en caso de que se supere un umbral específico. La observabilidad de la red de contenedores en EKS se alinea con esto, ya que expone las métricas clave del sistema que puede extraer para ampliar la observabilidad del rendimiento de la red del sistema en los pods y nodos de trabajo.
Uso de las visualizaciones de la consola para una solución de problemas más precisa
En caso de que se active una alarma en su sistema de supervisión, puede que desee centrarse en el clúster y la carga de trabajo en los que se originó el problema. Para ello, puede usar las visualizaciones de la consola de EKS, que reducen el ámbito de la investigación al clúster y aceleran la divulgación de los flujos de red responsables de la mayoría de las retransmisiones, los tiempos de espera de las retransmisiones y el volumen de datos transferidos.
Seguimiento de los recursos con mayor consumo en su entorno de Amazon EKS
Muchos equipos ejecutan EKS como base para sus plataformas, lo que lo convierte en el punto central de la actividad de red de un entorno de aplicaciones. Con las capacidades de supervisión de red de esta característica, puede hacer un seguimiento de las cargas de trabajo responsables de la mayor parte del tráfico (medido por el volumen de datos) dentro del clúster, entre zonas de disponibilidad, así como del tráfico a destinos externos dentro de AWS (DynamoDB y S3) y fuera de la nube de AWS (Internet o en las instalaciones). Además, puede supervisar el rendimiento de cada uno de estos flujos en función de las retransmisiones, los tiempos de espera de las retransmisiones y los datos transferidos.
Características
-
Métricas de rendimiento: esta característica le permite extraer las métricas del sistema relacionadas con la red para los pods y los nodos de trabajo directamente desde el agente de Network Flow Monitor (NFM) que se ejecuta en su clúster de EKS.
-
Mapa de servicios: esta característica visualiza de forma dinámica la intercomunicación entre las cargas de trabajo del clúster, lo que le permite revelar rápidamente las métricas clave (retransmisiones [RT], tiempos de espera de retransmisiones [RTO] y datos transferidos [DT] asociadas a los flujos de red entre los módulos que se comunican.
-
Tabla de flujos: con esta tabla, puede supervisar los recursos con mayor consumo en las cargas de trabajo de Kubernetes de su clúster desde tres ángulos diferentes: vista de servicio de AWS, vista de clúster y vista externa. Para cada vista, puede ver las retransmisiones, los tiempos de espera de las retransmisiones y los datos transferidos entre el pod de origen y su destino.
-
Vista de servicio de AWS: muestra los recursos con mayor consumo de los servicios de AWS (DynamoDB y S3)
-
Vista de clúster: muestra los recursos con mayor consumo dentro del clúster (del este ← al → oeste)
-
Vista externa: muestra los recursos con mayor consumo de los destinos externos al clúster fuera de AWS
-
Introducción
Para comenzar, active la observabilidad de la red de contenedores en la consola de EKS para un clúster nuevo o existente. De este modo, se automatizará la creación de dependencias de Network Flow Monitor (NFM) (recursos de ámbito y supervisión). Además, tendrá que instalar el complemento Agente de Network Flow Monitor. Como alternativa, puede instalar estas dependencias mediante la
AWS CLI, las API de EKS (para el complemento), las API de NFM o infraestructura como código (como Terraform
Al utilizar Network Flow Monitor en EKS, puede mantener su flujo de trabajo de observabilidad y la pila de tecnología actuales y, al mismo tiempo, aprovechar un conjunto de características adicionales que le permiten comprender y optimizar aún más la capa de red de su entorno de EKS. Puede obtener más información sobre los precios de Network Flow Monitor aquí.
Requisitos previos y notas importantes
-
Como se mencionó anteriormente, si habilita la observabilidad de la red de contenedores desde la consola de EKS, las dependencias de recursos de NFM subyacentes (ámbito y supervisión) se crearán automáticamente en su nombre y se le guiará durante el proceso de instalación del complemento de EKS para NFM.
-
Si desea activar esta característica mediante infraestructura como código (IaC) como Terraform, tendrá que definir las siguientes dependencias en su IaC: ámbito de NFM, supervisión de NFM, complemento de EKS para NFM. Además, tendrá que otorgar los permisos pertinentes al complemento de EKS mediante Pod Identity o roles de IAM para cuentas de servicio (IRSA).
-
Debe ejecutar como mínimo la versión 1.1.0 para el complemento de EKS del agente de NFM.
-
Debe utilizar la versión 6.21.0 o una posterior del Proveedor de AWS de Terraform
para admitir los recursos de Network Flow Monitor.
Permisos de IAM necesarios
Complemento de EKS para el agente de NFM
Puede usar la política administrada de AWS CloudWatchNetworkFlowMonitorAgentPublishPolicy con Pod Identity. Esta política contiene permisos para que el agente de NFM envíe informes de telemetría (métricas) al punto de conexión de Network Flow Monitor.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect" : "Allow", "Action" : [ "networkflowmonitor:Publish" ], "Resource" : "*" } ] }
Observabilidad de la red de contenedores en la consola de EKS
Se requieren los siguientes permisos para activar la característica y visualizar el mapa de servicios y la tabla de flujos en la consola.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect": "Allow", "Action": [ "networkflowmonitor:ListScopes", "networkflowmonitor:ListMonitors", "networkflowmonitor:GetScope", "networkflowmonitor:GetMonitor", "networkflowmonitor:CreateScope", "networkflowmonitor:CreateMonitor", "networkflowmonitor:TagResource", "networkflowmonitor:StartQueryMonitorTopContributors", "networkflowmonitor:StopQueryMonitorTopContributors", "networkflowmonitor:GetQueryStatusMonitorTopContributors", "networkflowmonitor:GetQueryResultsMonitorTopContributors" ], "Resource": "*" } ] }
Uso de la AWS CLI, la API de EKS y la API de NFM
#!/bin/bash # Script to create required Network Flow Monitor resources set -e CLUSTER_NAME="my-eks-cluster" CLUSTER_ARN="arn:aws:eks:{Region}:{Account}:cluster/{ClusterName}" REGION="us-west-2" AGENT_NAMESPACE="amazon-network-flow-monitor" echo "Creating Network Flow Monitor resources..." # Check if Network Flow Monitor agent is running in the cluster echo "Checking for Network Flow Monitor agent in cluster..." if kubectl get pods -n "$AGENT_NAMESPACE" --no-headers 2>/dev/null | grep -q "Running"; then echo "Network Flow Monitor agent exists and is running in the cluster" else echo "Network Flow Monitor agent not found. Installing as EKS addon..." aws eks create-addon \ --cluster-name "$CLUSTER_NAME" \ --addon-name "$AGENT_NAMESPACE" \ --region "$REGION" echo "Network Flow Monitor addon installation initiated" fi # Get Account ID ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) echo "Cluster ARN: $CLUSTER_ARN" echo "Account ID: $ACCOUNT_ID" # Check for existing scope echo "Checking for existing Network Flow Monitor Scope..." EXISTING_SCOPE=$(aws networkflowmonitor list-scopes --region $REGION --query 'scopes[0].scopeArn' --output text 2>/dev/null || echo "None") if [ "$EXISTING_SCOPE" != "None" ] && [ "$EXISTING_SCOPE" != "null" ]; then echo "Using existing scope: $EXISTING_SCOPE" SCOPE_ARN=$EXISTING_SCOPE else echo "Creating new Network Flow Monitor Scope..." SCOPE_RESPONSE=$(aws networkflowmonitor create-scope \ --targets "[{\"targetIdentifier\":{\"targetId\":{\"accountId\":\"${ACCOUNT_ID}\"},\"targetType\":\"ACCOUNT\"},\"region\":\"${REGION}\"}]" \ --region $REGION \ --output json) SCOPE_ARN=$(echo $SCOPE_RESPONSE | jq -r '.scopeArn') echo "Scope created: $SCOPE_ARN" fi # Create Network Flow Monitor with EKS Cluster as local resource echo "Creating Network Flow Monitor..." MONITOR_RESPONSE=$(aws networkflowmonitor create-monitor \ --monitor-name "${CLUSTER_NAME}-monitor" \ --local-resources "type=AWS::EKS::Cluster,identifier=${CLUSTER_ARN}" \ --scope-arn "$SCOPE_ARN" \ --region $REGION \ --output json) MONITOR_ARN=$(echo $MONITOR_RESPONSE | jq -r '.monitorArn') echo "Monitor created: $MONITOR_ARN" echo "Network Flow Monitor setup complete!" echo "Monitor ARN: $MONITOR_ARN" echo "Scope ARN: $SCOPE_ARN" echo "Local Resource: AWS::EKS::Cluster (${CLUSTER_ARN})"
Uso de la infraestructura como código (IaC)
Terraform
Si utiliza Terraform para administrar su infraestructura en la nube de AWS, puede incluir las siguientes configuraciones de recursos para activar la observabilidad de la red de contenedores en su clúster.
Ámbito de NFM
data "aws_caller_identity" "current" {} resource "aws_networkflowmonitor_scope" "example" { target { region = "us-east-1" target_identifier { target_type = "ACCOUNT" target_id { account_id = data.aws_caller_identity.current.account_id } } } tags = { Name = "example" } }
Supervisión de NFM
resource "aws_networkflowmonitor_monitor" "example" { monitor_name = "eks-cluster-name-monitor" scope_arn = aws_networkflowmonitor_scope.example.scope_arn local_resource { type = "AWS::EKS::Cluster" identifier = aws_eks_cluster.example.arn } remote_resource { type = "AWS::Region" identifier = "us-east-1" # this must be the same region that the cluster is in } tags = { Name = "example" } }
Complemento de EKS para NFM
resource "aws_eks_addon" "example" { cluster_name = aws_eks_cluster.example.name addon_name = "aws-network-flow-monitoring-agent" }
¿Cómo funciona?
Métricas de desempeño
Métricas del sistema
Si ejecuta herramientas de terceros (3P) para supervisar su entorno de EKS (como Prometheus y Grafana), puede extraer las métricas del sistema compatibles directamente desde el agente de Network Flow Monitor. Estas métricas se pueden enviar a la pila de supervisión para ampliar la medición del rendimiento de la red del sistema en los pods y nodos de trabajo. Las métricas disponibles se muestran en la tabla, en Métricas del sistema compatibles.

Para activar estas métricas, anule las siguientes variables de entorno mediante las variables de configuración durante el proceso de instalación (consulte: https://aws.amazon.com/blogs/containers/amazon-eks-add-ons-advanced-configuration/):
OPEN_METRICS: Enable or disable open metrics. Disabled if not supplied Type: String Values: [“on”, “off”] OPEN_METRICS_ADDRESS: Listening IP address for open metrics endpoint. Defaults to 127.0.0.1 if not supplied Type: String OPEN_METRICS_PORT: Listening port for open metrics endpoint. Defaults to 80 if not supplied Type: Integer Range: [0..65535]
Métricas de flujos
Además, Network Flow Monitor captura los datos de los flujos de red junto con las métricas de flujos: retransmisiones, tiempos de espera de las retransmisiones y datos transferidos. Network Flow Monitor procesa estos datos y los puede ver en la consola de EKS para detectar el tráfico en el entorno del clúster y su rendimiento en función de estas métricas de flujos.
En el siguiente diagrama se muestra un flujo de trabajo en el que se pueden aprovechar ambos tipos de métricas (del sistema y de flujos) para obtener más inteligencia operativa.

-
El equipo de la plataforma puede recopilar y visualizar las métricas del sistema en su pila de supervisión. Una vez implementadas las alertas, puede detectar anomalías en la red o problemas que afecten a pods o nodos de trabajo mediante las métricas del sistema del agente de NFM.
-
Como siguiente paso, los equipos de la plataforma pueden aprovechar las visualizaciones nativas de la consola de EKS para reducir aún más el ámbito de la investigación y acelerar la solución de problemas en función de las representaciones de los flujos y las métricas asociadas.
Nota importante: La extracción de las métricas del sistema del agente de NFM y el proceso por el que el agente de NFM envía las métricas de flujos al backend de NFM son procesos independientes.
Métricas del sistema compatibles
Nota importante: las métricas del sistema se exportan en formato OpenMetrics
| Nombre de métrica | Tipo | Dimensiones | Descripción |
|---|---|---|---|
|
ingress_flow |
Calibre |
instance_id, iface, pod, espacio de nombres, nodo |
Recuento de flujos de TCP de entrada (TcpPassiveOpens) |
|
egress_flow |
Calibre |
instance_id, iface, pod, espacio de nombres, nodo |
Recuento de flujos de TCP de salida (TcpActiveOpens) |
|
ingress_packets |
Calibre |
instance_id, iface, pod, espacio de nombres, nodo |
Recuento de paquetes de entrada (delta) |
|
egress_packets |
Calibre |
instance_id, iface, pod, espacio de nombres, nodo |
Recuento de paquetes de salida (delta) |
|
ingress_bytes |
Calibre |
instance_id, iface, pod, espacio de nombres, nodo |
Recuento de bytes de entrada (delta) |
|
egress_bytes |
Calibre |
instance_id, iface, pod, espacio de nombres, nodo |
Recuento de bytes de salida (delta) |
|
bw_in_allowance_exceeded |
Calibre |
instance_id, eni, nodo |
Paquetes puestos en cola o descartados debido al límite de ancho de banda de entrada |
|
bw_out_allowance_exceeded |
Calibre |
instance_id, eni, nodo |
Paquetes puestos en cola o descartados debido al límite de ancho de banda de salida |
|
pps_allowance_exceeded |
Calibre |
instance_id, eni, nodo |
Paquetes puestos en cola o descartados debido al límite de PPS bidireccional |
|
conntrack_allowance_exceeded |
Calibre |
instance_id, eni, nodo |
Paquetes descartados debido al límite de seguimiento de la conexión |
|
linklocal_allowance_exceeded |
Calibre |
instance_id, eni, nodo |
Paquetes descartados debido al límite de PPS del servicio de proxy local |
Métricas de flujos compatibles
| Nombre de métrica | Tipo | Descripción |
|---|---|---|
|
Retransmisiones de TCP |
Contador |
Número de veces que un remitente reenvía un paquete que se perdió o se dañó durante la transmisión. |
|
Tiempos de espera de las retransmisiones de TCP |
Contador |
Número de veces que un remitente inició un periodo de espera para determinar si un paquete se perdió en tránsito. |
|
Datos (bytes) transferidos |
Contador |
Volumen de datos transferidos entre un origen y un destino para un flujo determinado. |
Mapa de servicios y tabla de flujos
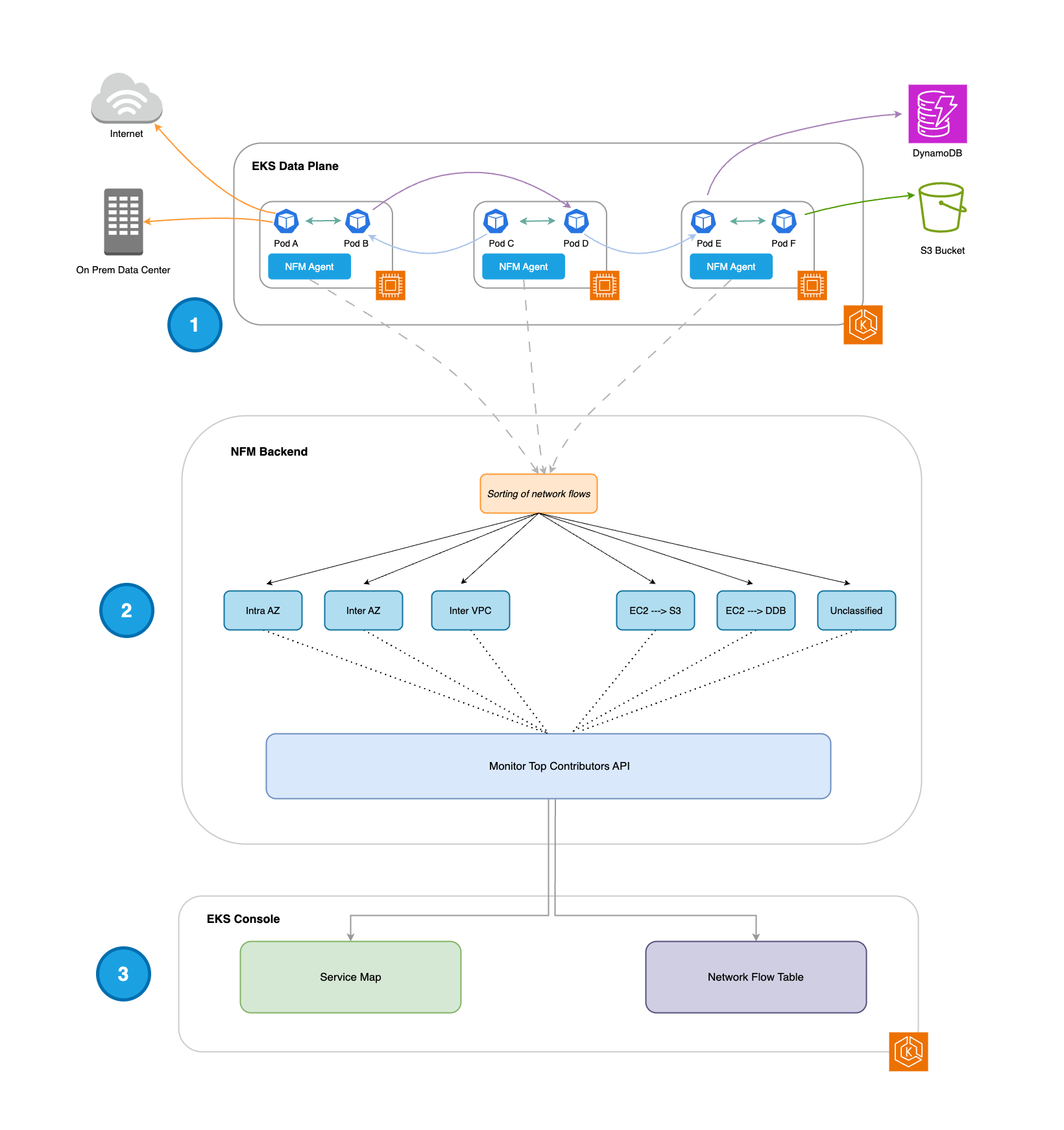
-
Una vez instalado, el agente de Network Flow Monitor se ejecuta como un DaemonSet en cada nodo de trabajo y recopila los 500 flujos de red principales (en función del volumen de datos transferidos) cada 30 segundos.
-
Estos flujos de red se clasifican en las siguientes categorías: Intra AZ, Inter AZ, EC2 → S3, EC2 → DynamoDB (DDB) y Sin clasificar. Cada flujo tiene 3 métricas asociadas: retransmisiones, tiempos de espera de las retransmisiones y datos transferidos (en bytes).
-
Intra AZ: flujos de red entre pods en la misma zona de disponibilidad
-
Inter AZ: flujos de red entre pods en diferentes zonas de disponibilidad
-
EC2 → S3: flujos de red de pods a S3
-
EC2 → DDB: flujos de red de pods a DDB
-
Sin clasificar: flujos de red de pods a Internet o en las instalaciones
-
-
Los flujos de red de la API de contribuidores principales de Network Flow Monitor se utilizan para mejorar las siguientes experiencias en la consola de EKS:
-
Mapa de servicios: visualización de los flujos de red dentro del clúster (Intra AZ e Inter AZ).
-
Tabla de flujos: presentación en una tabla de los flujos de red dentro del clúster (Intra AZ e Inter AZ), de pods a servicios de AWS (EC2 → S3 y EC2 → DDB) y de pods a destinos externos (sin clasificar).
-
Los flujos de red extraídos de la API de contribuidores principales tienen un ámbito de intervalo de 1 hora y pueden incluir hasta 500 flujos de cada categoría. En el caso del mapa de servicios, esto significa que se pueden obtener y presentar hasta 1000 flujos de las categorías de flujos Intra AZ e Inter AZ en un intervalo de tiempo de 1 hora. En el caso de la tabla de flujos, esto significa que se pueden obtener y presentar hasta 2500 flujos de red de las 5 categorías de flujos de red en un intervalo de tiempo de 2 horas.
Ejemplo: mapa de servicios
Vista de implementación
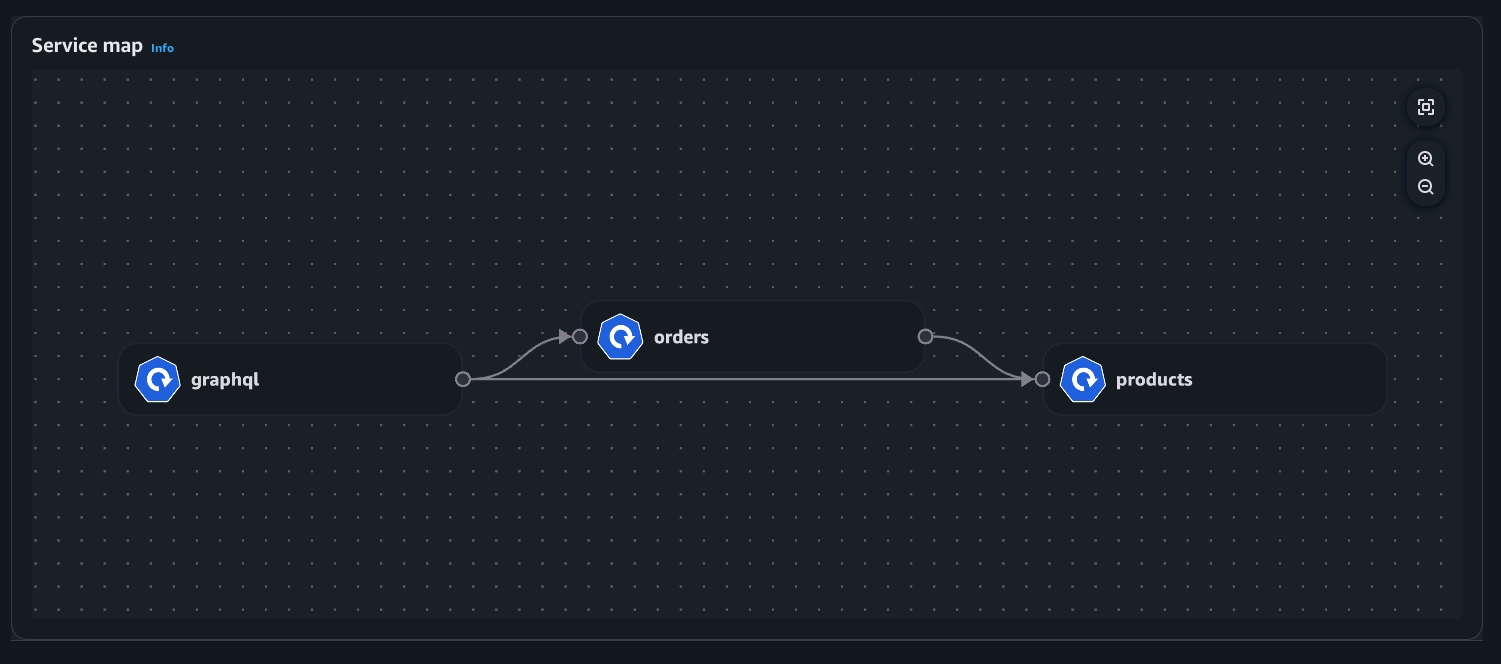
Vista de pod
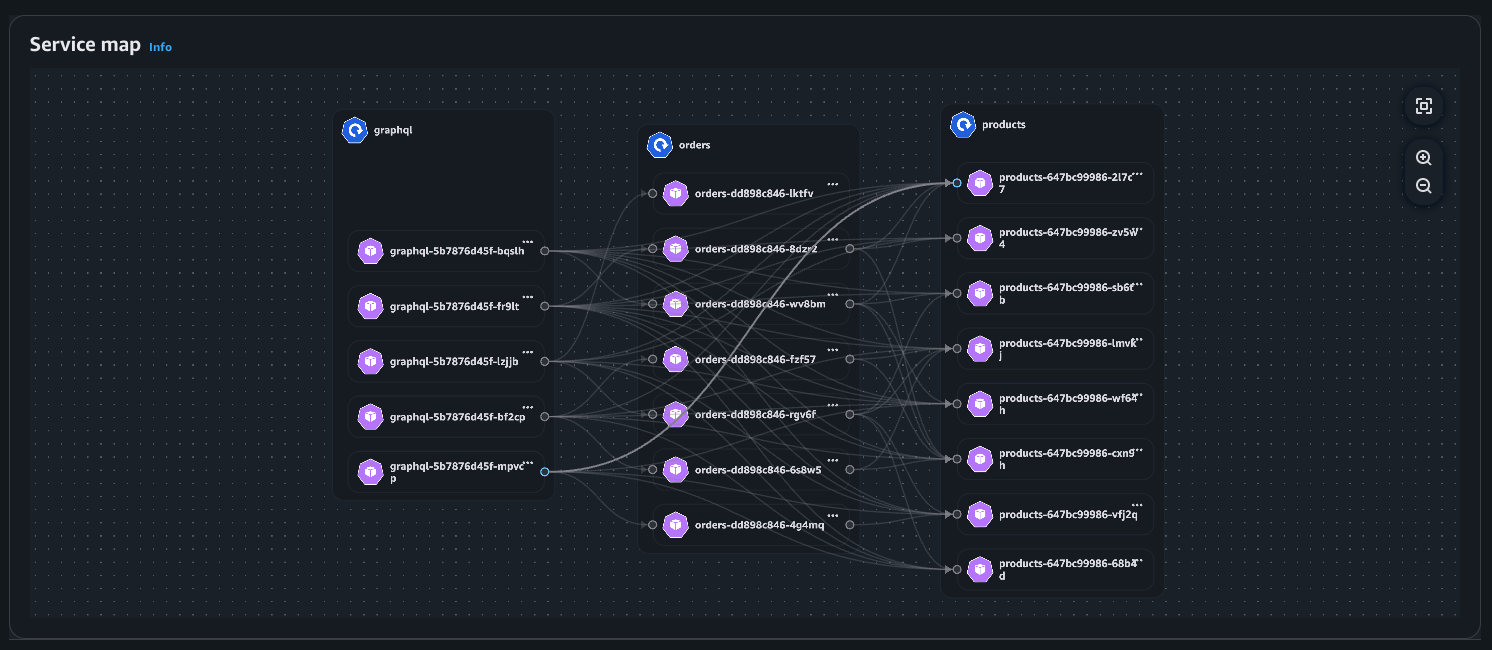
Vista de implementación

Vista de pod

Ejemplo: tabla de flujos
AWS Vista de servicio de

Vista de clúster
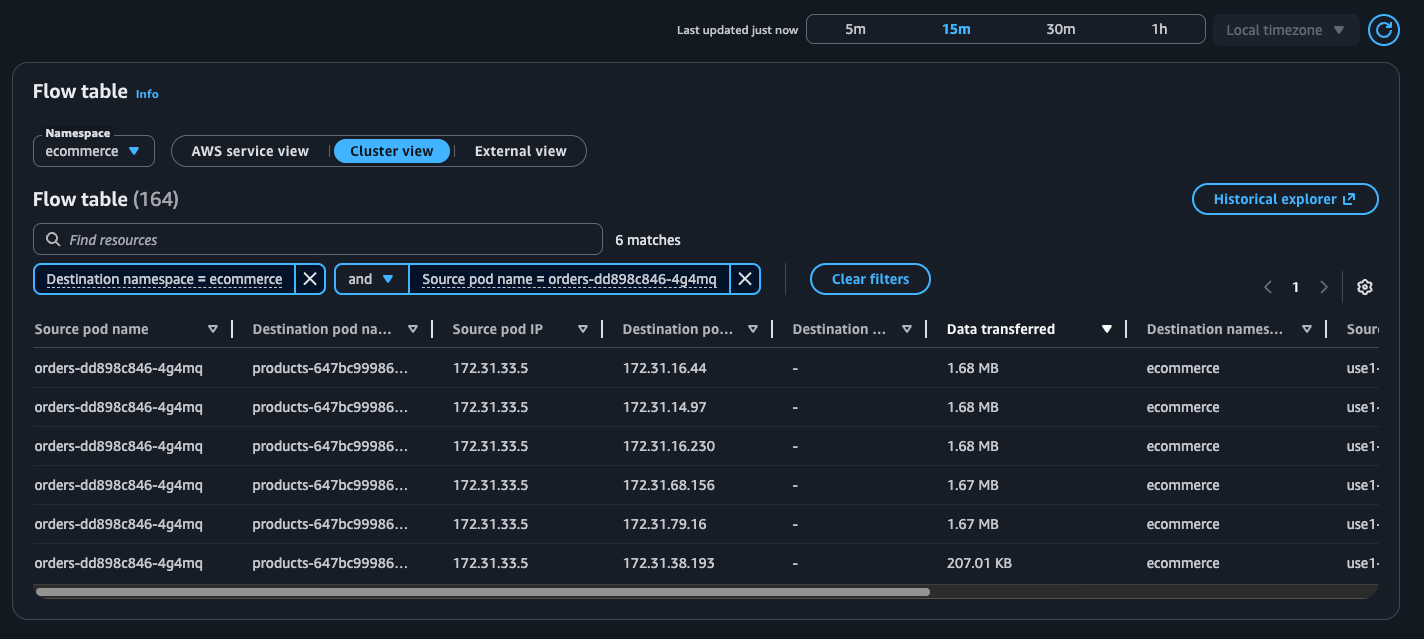
Consideraciones y limitaciones
-
La observabilidad de la red de contenedores en EKS solo está disponible en las regiones en las que se admite Network Flow Monitor.
-
Las métricas del sistema compatibles están en formato OpenMetrics y se pueden extraer directamente del agente de Network Flow Monitor (NFM).
-
Para activar la observabilidad de la red de contenedores en EKS mediante infraestructura como código (IaC) como Terraform
, es necesario definir y crear estas dependencias en las configuraciones: el ámbito de NFM, la supervisión de NFM y el agente de NFM. -
Network Flow Monitor admite aproximadamente hasta 5 millones de flujos por minuto. Se trata de aproximadamente 5000 instancias de EC2 (nodos de trabajo de EKS) con el agente Network Flow Monitor instalado. La instalación de agentes en más de 5000 instancias puede afectar al rendimiento de la supervisión hasta que se disponga de capacidad adicional.
-
Debe ejecutar como mínimo la versión 1.1.0 para el complemento de EKS del agente de NFM.
-
Debe utilizar la versión 6.21.0 o una posterior del Proveedor de AWS de Terraform
para admitir los recursos de Network Flow Monitor. -
Para enriquecer los flujos de red con metadatos de los pods, los pods deben ejecutarse en su propio espacio de nombres de red aislado, no en el espacio de nombres de la red host.
