Ayude a mejorar esta página
Para contribuir a esta guía del usuario, elija el enlace Edit this page on GitHub que se encuentra en el panel derecho de cada página.
Inicio rápido: inferencia de LLM de alto rendimiento con vLLM en Amazon EKS
Introducción
Esta guía de inicio rápido proporciona un recorrido por la implementación de modelos de lenguaje de gran tamaño (LLM) en Amazon EKS mediante vLLM y GPU para aplicaciones de inferencia en tiempo real basadas en texto.
La solución usa Amazon EKS para la orquestación de contenedores y vLLM para un servicio de modelos eficiente, lo que le permite crear aplicaciones de IA escalables con aceleración de GPU y servidores de inferencias de alto rendimiento. El modelo Llama 3.1 8B Instruct se utiliza para la demostración, pero puede implementar cualquier otro LLM compatible con vLLM (consulte la documentación de vLLM
Arquitectura de vLLM en EKS

Cuando complete este procedimiento, dispondrá de un punto de conexión de inferencia de vLLM optimizado para ofrecer un rendimiento y una baja latencia, y podrá interactuar con un modelo de Llama a través de una aplicación de frontend de chat, lo que demuestra un caso de uso típico para asistentes de chatbot y otras aplicaciones basadas en LLM.
Para obtener orientación adicional y recursos de implementación avanzados, consulte Guía de prácticas recomendadas de EKS sobre cargas de trabajo de IA y ML y los gráficos de inferencia de IA en EKS
Antes de empezar
Antes de comenzar, asegúrese de que disponga de lo siguiente:
-
Un clúster de Amazon EKS con los siguientes componentes principales: grupos de nodos de Karpenter con la familia de instancias de EC2 G5 o G6, el complemento para dispositivos de NVIDIA instalado en los nodos de trabajo con GPU y el controlador CSI de Mountpoint de S3 instalado. Para crear esta configuración de línea de base, siga los pasos de Guía de prácticas recomendadas para la configuración de clústeres para la inferencia en tiempo real en Amazon EKS hasta completar el paso 4.
-
Una cuenta de Hugging Face. Para registrarse, consulte https://huggingface.co/login.
Configuración de almacenamiento de modelos con Amazon S3
Almacene archivos de LLM de gran tamaño de forma eficiente en Amazon S3 para separar el almacenamiento de los recursos de computación. Este enfoque agiliza las actualizaciones de los modelos, reduce los costos y simplifica la administración en las configuraciones de producción. S3 administra archivos de gran tamaño de forma fiable, mientras que la integración con Kubernetes mediante el controlador CSI de Mountpoint permite a los pods acceder a modelos como el almacenamiento local sin necesidad de largas descargas durante el arranque. Siga estos pasos para crear un bucket de S3, cargar un LLM y montarlo como un volumen en su contenedor de servidores de inferencias.
También hay otras soluciones de almacenamiento disponibles en EKS para el almacenamiento en caché de modelos, como EFS y FSx para Lustre. Para obtener más información, consulte las prácticas recomendadas de EKS.
Configuración de las variables de entorno
Cree un nombre único para un nuevo bucket de Amazon S3 que crearemos más adelante en esta guía. Una vez creado, utilice el mismo nombre del bucket para todos los pasos. Por ejemplo:
MY_BUCKET_NAME=model-store-$(date +%s)
Defina las variables de entorno y guárdelas en un archivo:
cat << EOF > .env-quickstart-vllm export BUCKET_NAME=${MY_BUCKET_NAME} export AWS_REGION=us-east-1 export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) EOF
Cargue las variables de entorno en su entorno de intérprete de comandos. Si cierra el entorno de intérprete de comandos actual y abre uno nuevo, asegúrese de reutilizar las variables de entorno con este mismo comando:
source .env-quickstart-vllm
Creación de un bucket de S3 para almacenar archivos del modelo
Cree un bucket de S3 para almacenar los archivos del modelo:
aws s3 mb s3://${BUCKET_NAME} --region ${AWS_REGION}
Descarga del modelo desde Hugging Face
Hugging Face es uno de los principales centros de modelos para acceder a modelos de LLM. Para descargar el modelo Llama, tendrá que aceptar la licencia del modelo y configurar la autenticación mediante token:
-
Acepte la licencia del modelo Llama 3.1 8B Instruct en https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct.
-
Genere un token de acceso (vaya a Perfil > Configuración > Tokens de acceso y, a continuación, cree un nuevo token con el tipo de token de lectura).
Establezca una variable de entorno con el token de Hugging Face:
export HF_TOKEN=your_token_here
Instale el paquete pip3 si aún no está instalado en su entorno. Comando de ejemplo en Amazon Linux 2023:
sudo dnf install -y python3-pip
Instale la CLI de Hugging Face
pip install huggingface-hub
Descargue el modelo Llama-3.1-8B-Instruct desde Hugging Face (~15 GB) con el indicador --exclude para omitir el formato PyTorch heredado y descargar solo los archivos optimizados en formato safetensors, lo que reduce el tamaño de la descarga y mantiene la compatibilidad total con los motores de inferencia más populares:
huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct \ --exclude "original/*" \ --local-dir ./llama-3.1-8b-instruct \ --token $HF_TOKEN
Compruebe los archivos descargados:
$ ls llama-3.1-8b-instruct
El resultado esperado debe tener el siguiente aspecto:
LICENSE config.json model-00002-of-00004.safetensors model.safetensors.index.json tokenizer_config.json README.md generation_config.json model-00003-of-00004.safetensors special_tokens_map.json USE_POLICY.md model-00001-of-00004.safetensors model-00004-of-00004.safetensors tokenizer.json
Carga de archivos del modelo
Active Common Runtime (CRT) de AWS para mejorar el rendimiento de las transferencias de S3. El cliente de transferencia basado en CRT proporciona un rendimiento y una fiabilidad mejorados para operaciones con archivos de gran tamaño:
aws configure set s3.preferred_transfer_client crt
Cargue el modelo:
aws s3 cp ./llama-3.1-8b-instruct s3://$BUCKET_NAME/llama-3.1-8b-instruct \ --recursive
El resultado esperado debe tener el siguiente aspecto:
... upload: llama-3.1-8b-instruct/tokenizer.json to s3://model-store-1753EXAMPLE/llama-3.1-8b-instruct/tokenizer.json upload: llama-3.1-8b-instruct/model-00004-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00004-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00002-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00002-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00003-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00003-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00001-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00001-of-00004.safetensors
Configuración los permisos de CSI de Mountpoint de S3
El controlador CSI de Mountpoint de S3 permite la integración nativa entre Kubernetes y S3, lo que permite a los pods acceder directamente a archivos del modelo como si se tratara de un almacenamiento local, lo que elimina la necesidad de llevar a cabo copias locales durante el arranque del contenedor.
Cree una política de IAM para permitir que Mountpoint de S3 lea desde su bucket de S3:
aws iam create-policy \ --policy-name S3BucketAccess-${BUCKET_NAME} \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:GetObjectVersion\", \"s3:ListBucket\", \"s3:GetBucketLocation\"], \"Resource\": [\"arn:aws:s3:::${BUCKET_NAME}\", \"arn:aws:s3:::${BUCKET_NAME}/*\"]}]}"
Para buscar el nombre del rol de IAM que utiliza el controlador CSI de Mountpoint de S3, consulte las anotaciones de la cuenta de servicio del controlador CSI de S3:
ROLE_NAME=$(kubectl get serviceaccount s3-csi-driver-sa -n kube-system -o jsonpath='{.metadata.annotations.eks\.amazonaws\.com/role-arn}' | cut -d'/' -f2)
Adjunte su política de IAM al rol de CSI de Mountpoint de S3:
aws iam attach-role-policy \ --role-name ${ROLE_NAME} \ --policy-arn arn:aws:iam::${AWS_ACCOUNT_ID}:policy/S3BucketAccess-${BUCKET_NAME}
Si CSI de Mountpoint de S3 no está instalado en el clúster, siga los pasos de implementación que se indican en Guía de prácticas recomendadas para la configuración de clústeres para la inferencia en tiempo real en Amazon EKS.
Montaje de un bucket de S3 como un volumen de Kubernetes
Cree un volumen persistente (PV) y una recuperación de volumen persistente (PVC) para proporcionar acceso de solo lectura al bucket de S3 en varios pods de inferencia. El modo de acceso ReadOnlyMany garantiza el acceso simultáneo a los archivos del modelo, mientras que el controlador CSI se encarga del montaje del bucket de S3:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: model-store spec: storageClassName: "" capacity: storage: 100Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain mountOptions: - region ${AWS_REGION} csi: driver: s3.csi.aws.com volumeHandle: model-store volumeAttributes: bucketName: ${BUCKET_NAME} --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-store spec: storageClassName: "" volumeName: model-store accessModes: - ReadOnlyMany resources: requests: storage: 100Gi EOF
Configuración de la infraestructura de GPU
Nodos del clúster
Estamos utilizando el clúster de EKS creado en Guía de prácticas recomendadas para la configuración de clústeres para la inferencia en tiempo real en Amazon EKS. Este clúster incluye grupos de nodos de Karpenter que pueden aprovisionar nodos habilitados para GPU con suficiente almacenamiento de nodos para descargar la imagen del contenedor de vLLM. Si utiliza un clúster de EKS personalizado, asegúrese de que pueda lanzar nodos habilitados para GPU.
Selección de una instancia
La selección correcta de instancias para la inferencia de LLM requiere garantizar que la memoria de GPU disponible sea suficiente para cargar el peso del modelo. El peso del modelo para Llama 3.1 8B Instruct es de aproximadamente 16 GB (tamaño de los archivos del modelo .safetensor), por lo que debemos proporcionar al menos esta cantidad de memoria al proceso vllm para cargar el modelo.
Tanto las instancias de EC2 G5 de Amazon
Controladores para dispositivos de NVIDIA
Los controladores de NVIDIA proporcionan el entorno de tiempo de ejecución necesario para que los contenedores accedan a los recursos de GPU de forma eficiente. Permite la asignación y administración de recursos de GPU en Kubernetes, lo que permite que las GPU estén disponibles como recursos programables.
Nuestro clúster utiliza AMI de Bottlerocket de EKS, que incluyen todos los complementos y controladores para dispositivos de NVIDIA necesarios en todos los nodos con GPU, lo que garantiza una accesibilidad inmediata a la GPU para las cargas de trabajo en contenedores sin necesidad de configuración adicional. Si utiliza otros tipos de nodos de EKS, debe asegurarse de que estén instalados todos los controladores y complementos necesarios.
Prueba de la infraestructura de GPU
Para probar las capacidades de GPU del clúster, siga los pasos que se indican a continuación a fin de garantizar que los pods puedan acceder a los recursos de GPU de NVIDIA y programarlos correctamente en nodos habilitados para GPU.
Implemente un pod de prueba de SMI de NVIDIA:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: gpu-nvidia-smi-test spec: restartPolicy: OnFailure tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker # Matches GPU NodePool's label containers: - name: cuda-container image: nvidia/cuda:12.9.1-base-ubuntu20.04 command: ["nvidia-smi"] resources: requests: memory: "24Gi" limits: nvidia.com/gpu: 1 EOF
Consulte los registros del pod para comprobar que se muestren los detalles de GPU, de forma similar a la salida siguiente (no necesariamente el mismo modelo de GPU):
$ kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/gpu-nvidia-smi-test $ kubectl logs gpu-nvidia-smi-test
Wed Jul 30 15:39:58 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 | | 0% 30C P8 9W / 300W | 0MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
Este resultado muestra que los pods pueden acceder correctamente a los recursos de GPU.
IMPORTANTE: Este pod utiliza una configuración de nodeSelector que se alinea con los grupos de nodos de Karpenter en Guía de prácticas recomendadas para la configuración de clústeres para la inferencia en tiempo real en Amazon EKS. Si utiliza grupos de nodos diferentes, asegúrese de que el pod coincida con nodeSelector y las tolerancias en consecuencia.
Implementación de un contenedor de inferencia
La pila de distribución determina las capacidades de rendimiento y escalabilidad de la infraestructura de inferencia. vLLM se ha convertido en una solución líder para las implementaciones de producción. La arquitectura de vLLM proporciona un procesamiento continuo por lotes para el procesamiento dinámico de solicitudes, optimizaciones del kernel para una inferencia más rápida y una administración eficiente de la memoria de GPU a través de PagedAttention. Estas características, combinadas con una API de REST lista para la producción y la compatibilidad con los formatos de modelos más populares, la convierten en una opción óptima para las implementaciones de inferencias de alto rendimiento.
Selección de la imagen de contenedor de aprendizaje profundo de AWS
Los contenedores de aprendizaje profundo de AWS
Para esta implementación, utilizaremos el DLC de AWS para vLLM 0.9, que incluye bibliotecas de NVIDIA y configuraciones de rendimiento de GPU optimizadas diseñadas específicamente para la inferencia de modelos de transformadores en instancias de GPU de AWS.
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2
Aplicación de los manifiestos de Kubernetes de vLLM
Se puede implementar vLLM de varias formas en EKS. En esta guía, se muestra la implementación de vLLM mediante una implementación de Kubernetes, que es una forma sencilla y nativa de Kubernetes para comenzar. Para ver las opciones de implementación avanzadas, consulte los documentos de vLLM
Defina los parámetros de implementación mediante los manifiestos de Kubernetes para controlar la asignación de recursos, la ubicación de los nodos, los sondeos de estado, la exposición del servicio, etc. Configure su implementación para ejecutar un pod habilitado para GPU mediante la imagen del contenedor de aprendizaje profundo de AWS para vLLM. Establezca parámetros optimizados para la inferencia de LLM y exponga el punto de conexión compatible con OpenAPI de vLLM mediante el servicio del equilibrador de carga de AWS:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker containers: - name: vllm-inference image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2 ports: - containerPort: 8000 env: - name: MODEL_PATH value: "/mnt/models/llama-3.1-8b-instruct" args: - "--model=/mnt/models/llama-3.1-8b-instruct" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" readinessProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 resources: limits: nvidia.com/gpu: 1 requests: memory: "24Gi" cpu: "4" ephemeral-storage: "25Gi" # Ensure enough node storage for vLLM container image volumeMounts: - name: models mountPath: /mnt/models readOnly: true volumes: - name: models persistentVolumeClaim: claimName: model-store --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: type: LoadBalancer ports: - port: 80 targetPort: 8000 protocol: TCP selector: app: vllm-inference-app EOF
Compruebe que el estado del pod de vLLM sea Ready 1/1:
kubectl get pod -l app=vllm-inference-app -w
Resultado previsto:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
Es posible que pasen varios minutos hasta que se extraiga la imagen del contenedor y vLLM cargue los archivos del modelo en la memoria de GPU. Continúe solo cuando el pod esté listo y disponible.
Exposición del servicio
Exponga el punto de conexión de inferencia de forma local mediante el reenvío de puertos de Kubernetes para su desarrollo y pruebas locales. Deje este comando en ejecución en una ventana de terminal independiente:
export POD_NAME=$(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') kubectl port-forward pod/$POD_NAME 8000:8000
El controlador del equilibrador de carga de AWS crea automáticamente un equilibrador de carga de red que expone externamente el punto de conexión del servicio de vLLM. Para obtener el punto de conexión del NLB, ejecute:
NLB=$(kubectl get service vllm-inference-svc -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
¿Debe instalar el controlador del equilibrador de carga de AWS? Siga los pasos de implementación de Enrutamiento del tráfico de internet con el controlador del equilibrador de carga de AWS.
Ejecutar una inferencia
Validación del pod de inferencia
Valide la funcionalidad del contenedor de inferencias de forma local a través del puerto reenviado. Envíe una solicitud de conexión y asegúrese de que la respuesta incluya el código HTTP 200:
$ curl -IX GET "http://localhost:8000/v1/models"
HTTP/1.1 200 OK date: Mon, 13 Oct 2025 23:24:57 GMT server: uvicorn content-length: 516 content-type: application/json
Para probar las capacidades de inferencia y validar la conectividad externa, envíe una solicitud de finalización al LLM a través del punto de conexión del NLB:
curl -X POST "http://$NLB:80/v1/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/models/llama-3.1-8b-instruct", "prompt": "Explain artificial intelligence:", "max_tokens": 512, "temperature": 0.7 }'
Este punto de conexión sigue el formato de la API de OpenAI, lo que lo hace compatible con las aplicaciones existentes y, al mismo tiempo, proporciona parámetros de generación configurables, como la longitud de respuesta y la temperatura, para controlar la diversidad de la salida.
Ejecución de la aplicación de chatbot
A modo de demostración, en esta guía se ejecuta un ejemplo de aplicación de chatbot con el proyecto nextjs-vllm-ui
Ejecute la interfaz de usuario del chatbot como un contenedor de Docker que asigne el puerto 3000 a localhost y se conecte al punto de conexión del NLB de vLLM:
docker run --rm \ -p 3000:3000 \ -e VLLM_URL="http://${NLB}:80" \ --name nextjs-vllm-ui-demo \ ghcr.io/yoziru/nextjs-vllm-ui:latest
Abra el navegador web y vaya a http://localhost:3000/
Debería ver la interfaz de chat en la que puede interactuar con el modelo Llama.
Interfaz de usuario de chat

Optimización del rendimiento de inferencia
Los motores de inferencia especializados, como vLLM, proporcionan características avanzadas que aumentan considerablemente el rendimiento de inferencia, como el procesamiento continuo por lotes, el almacenamiento en caché de KV eficiente y los mecanismos optimizados de atención de la memoria. Puede ajustar los parámetros de configuración de vLLM para mejorar el rendimiento de inferencia y, al mismo tiempo, cumplir con los requisitos específicos de sus casos de uso y sus patrones de carga de trabajo. Una configuración adecuada es esencial para lograr la saturación de la GPU, ya que permite aprovechar al máximo los costosos recursos de GPU y, al mismo tiempo, ofrecer un alto rendimiento, baja latencia y operaciones rentables. Las siguientes optimizaciones lo ayudarán a maximizar el rendimiento de su implementación de vLLM en EKS.
Configuraciones de VLLM de referencia
Para ajustar los parámetros de configuración de vLLM para su caso de uso, compare diferentes configuraciones mediante una herramienta integral de comparación de inferencias como GuideLLM
Configuración de vLLM de línea de base
Esta es la configuración de línea de base que se utilizó para ejecutar vLLM:
| Parámetro de vLLM | Descripción |
|---|---|
|
tensor_parallel_size: 1 |
Distribución del modelo en 1 GPU |
|
gpu_memory_utilization: 0,90 |
Reserva de un 10 % de memoria de GPU para cubrir la sobrecarga del sistema |
|
max_sequence_length: 8192 |
Longitud máxima total de la secuencia (entrada + salida) |
|
max_num_seqs: 1 |
Número máximo de solicitudes simultáneas por GPU (procesamiento por lotes) |
Ejecute GuideLLM con esta configuración básica para establecer una línea de base de rendimiento. Para esta prueba, GuideLLM está configurado para generar 1 solicitud por segundo, con solicitudes de 256 tokens y respuestas de 128 tokens.
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
Resultado previsto:
Resultados de la referencia de línea de base

Configuración de VLLM ajustada
Ajuste los parámetros de vLLM para utilizar mejor los recursos de GPU y la paralelización:
| Parámetro de vLLM | Descripción |
|---|---|
|
tensor_parallel_size: 1 |
Manténgalo en 1 GPU. La paralelización del tensor debe coincidir con la cantidad de GPU que utilizará vLLM. |
|
gpu_memory_utilization: 0,92 |
Reduzca la sobrecarga de memoria de GPU si es posible y, al mismo tiempo, asegúrese de que vLLM continúe ejecutándose sin errores. |
|
max_sequence_length: 4096 |
Ajuste la secuencia máxima según los requisitos de su caso de uso: si se reduce la secuencia máxima, se liberan recursos que se pueden utilizar para aumentar la paralelización. |
|
max_num_seqs: 8 |
El aumento del máximo de secuencias aumenta el rendimiento, pero también aumenta la latencia. Aumente este valor para maximizar el rendimiento y, al mismo tiempo, garantizar que la latencia se mantenga dentro de los requisitos de su caso de uso. |
Aplique estos cambios a la implementación en ejecución mediante el comando patch de kubectl:
kubectl patch deployment vllm-inference-app --type='json' -p='[ {"op": "replace", "path": "/spec/template/spec/containers/0/args/4", "value": "--gpu-memory-utilization=0.92"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/5", "value": "--max-model-len=4096"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/6", "value": "--max-num-seqs=8"} ]'
Compruebe que el estado del pod de vLLM sea Ready 1/1:
kubectl get pod -l app=vllm-inference-app -w
Resultado previsto:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
A continuación, ejecute GuideLLM de nuevo con los mismos valores de referencia que antes:
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
Resultado previsto:
Resultados de la referencia optimizados
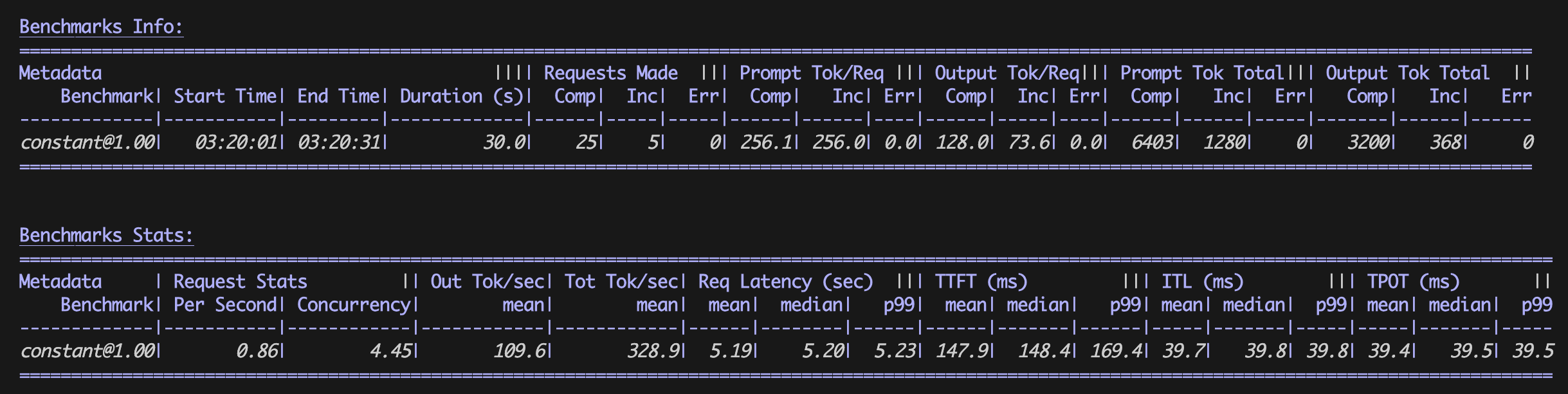
Resultados de la referencia
Calcule los resultados de la referencia en una tabla para la configuración de vLLM optimizada y de línea de base:
| Valores medios | Configuración de línea de base | Configuración optimizada |
|---|---|---|
|
RPS |
0,23 solicitudes/s |
0,86 solicitudes/s |
|
E2E |
12,99 s |
5,19 s |
|
TTFT |
8637,2 ms |
147,9 ms |
|
TPOT |
34,0 ms |
39,5 ms |
Las configuraciones de vLLM optimizadas mejoraron significativamente el rendimiento de inferencia (RPS) y redujeron la latencia (E2E, TTFT) con solo un pequeño aumento de milisegundos en el tiempo por token de salida (TPOT). Estos resultados demuestran cómo vLLM mejora considerablemente el rendimiento de inferencia, ya que permite que cada contenedor procese más solicitudes en menos tiempo, lo que supone un funcionamiento rentable.
