Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejecutar aplicaciones de alta disponibilidad
Sus clientes esperan que su aplicación esté siempre disponible, incluso cuando realice cambios y, especialmente, durante los picos de tráfico. Una arquitectura escalable y resiliente permite que sus aplicaciones y servicios funcionen sin interrupciones, lo que hace que sus usuarios estén satisfechos. Una infraestructura escalable crece y se reduce en función de las necesidades de la empresa. Eliminar los puntos únicos de fallo es un paso fundamental para mejorar la disponibilidad de una aplicación y hacerla resiliente.
Con Kubernetes, puede operar sus aplicaciones y ejecutarlas de una manera resiliente y de alta disponibilidad. Su gestión declarativa garantiza que, una vez que haya configurado la aplicación, Kubernetes intentará continuamente hacer coincidir el estado actual con el estado deseado.
Recomendaciones
Configure los presupuestos de Pod Disrup
Los presupuestos de interrupción de los pods
Evita usar pods individuales
Si toda la aplicación se ejecuta en un solo pod, la aplicación no estará disponible si se cierra ese pod. En lugar de implementar aplicaciones mediante pods individuales, cree implementaciones.
Ejecuta varias réplicas
La ejecución de varios pods de réplicas de una aplicación mediante una implementación ayuda a que funcione con una alta disponibilidad. Si una réplica falla, las réplicas restantes seguirán funcionando, aunque con una capacidad reducida, hasta que Kubernetes cree otro pod para compensar la pérdida. Además, puedes usar el escalador automático de módulos horizontales para escalar las réplicas automáticamente
Programe réplicas en todos los nodos
Ejecutar varias réplicas no será muy útil si todas las réplicas se ejecutan en el mismo nodo y el nodo deja de estar disponible. Considere la posibilidad de utilizar restricciones de antiafinidad o dispersión de topología de pods para distribuir las réplicas de una implementación en varios nodos de trabajo.
Puede mejorar aún más la confiabilidad de una aplicación típica ejecutándola en varias zonas de disponibilidad.
Uso de las reglas de antiafinidad de Pod
En el siguiente manifiesto se indica al programador de Kubernetes que prefiera colocar los pods en nodos y zonas de disponibilidad separados. No requiere nodos distintos ni zonas de disponibilidad, ya que, si los tuviera, Kubernetes no podrá programar ningún módulo una vez que haya un módulo en ejecución en cada zona de disponibilidad. Si tu aplicación solo requiere tres réplicas, puedes utilizarla requiredDuringSchedulingIgnoredDuringExecution paratopologyKey: topology.kubernetes.io/zone, y el programador de Kubernetes no programará dos pods en la misma zona de disponibilidad.
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 4 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: topology.kubernetes.io/zone weight: 100 - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: kubernetes.io/hostname weight: 99 containers: - name: web-app image: nginx:1.16-alpine
Uso de restricciones de dispersión de la topología de Pod
Al igual que las reglas de antiafinidad de los pods, las restricciones de dispersión de la topología de los pods le permiten hacer que su aplicación esté disponible en diferentes dominios de errores (o topología), como hosts o AZ. Este enfoque funciona muy bien cuando se intenta garantizar la tolerancia a los errores y la disponibilidad, ya que dispone de varias réplicas en cada uno de los distintos dominios de topología. Las reglas de antiafinidad de los pods, por otro lado, pueden producir fácilmente un resultado cuando se tiene una única réplica en un dominio de topología, ya que los pods que tienen una antiafinidad entre sí tienen un efecto repelente. En esos casos, una réplica única en un nodo dedicado no es ideal para la tolerancia a errores ni supone un buen uso de los recursos. Con las restricciones de dispersión de la topología, tiene más control sobre la dispersión o distribución que el programador debería intentar aplicar en los dominios de la topología. Estas son algunas propiedades importantes que se pueden utilizar en este enfoque:
-
maxSkewSe usa para controlar o determinar el punto máximo en el que las cosas pueden ser desiguales en los dominios de la topología. Por ejemplo, si una aplicación tiene 10 réplicas y se despliega en 3 zonas de disponibilidad, no se puede obtener una distribución uniforme, pero sí se puede influir en el grado de desigualdad de la distribución. En este caso,maxSkewpuede estar entre 1 y 10. Un valor de 1 significa que puedes terminar con un diferencial similar4,3,33,4,3o3,3,4entre las 3 AZ. Por el contrario, un valor de 10 significa que puedes terminar con un diferencial igual10,0,00,10,0o0,0,10entre 3 AZ. -
La
topologyKeyes una clave para una de las etiquetas de los nodos y define el tipo de dominio de topología que se debe utilizar para la distribución de los módulos. Por ejemplo, una dispersión zonal tendría el siguiente par clave-valor:topologyKey: "topology.kubernetes.io/zone" -
La
whenUnsatisfiablepropiedad se usa para determinar cómo desea que responda el planificador si no se pueden cumplir las restricciones deseadas. -
labelSelectorSe utiliza para encontrar los módulos que coincidan, de modo que el planificador pueda conocerlos a la hora de decidir dónde colocar los módulos de acuerdo con las restricciones que se especifiquen.
Además de los anteriores, hay otros campos sobre los que puede obtener más información en la documentación de Kubernetes
La topología del pod distribuye las restricciones en 3 zonas de disponibilidad
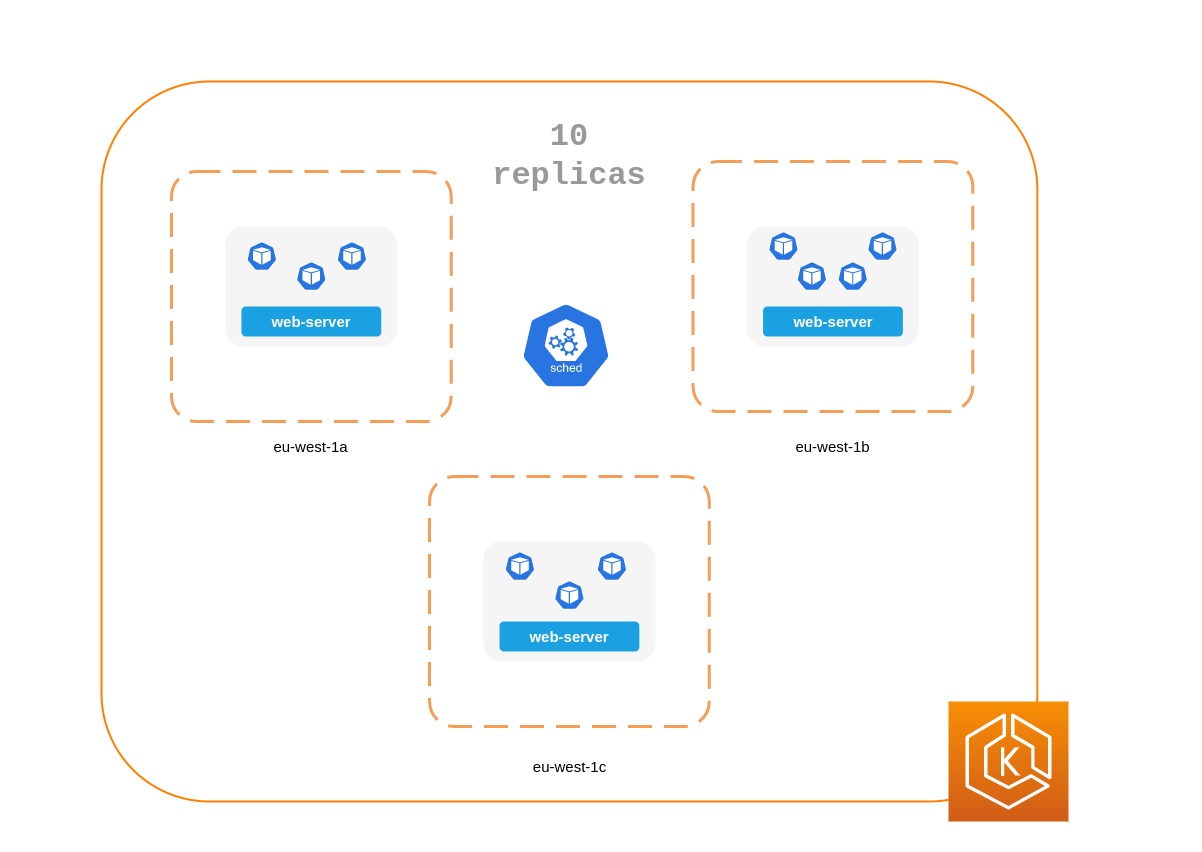
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 10 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test containers: - name: web-app image: nginx:1.16-alpine
Ejecute Kubernetes Metrics Server
Instala el servidor de métricas
El servidor de métricas no retiene ningún dato y no es una solución de monitorización. Su objetivo es exponer las métricas de uso de la CPU y la memoria a otros sistemas. Si quieres hacer un seguimiento del estado de tu aplicación a lo largo del tiempo, necesitas una herramienta de monitorización como Prometheus o Amazon. CloudWatch
Siga la documentación de EKS para instalar metrics-server en su clúster de EKS.
Escalador automático de pod horizontal (HPA)
HPA puede escalar automáticamente su aplicación en respuesta a la demanda y ayudarle a evitar que sus clientes se vean afectados durante los picos de tráfico. Se implementa como un bucle de control en Kubernetes que consulta periódicamente las métricas de las API que proporcionan métricas de recursos.
HPA puede recuperar métricas de las siguientes API: 1. metrics.k8s.iotambién conocida como API de métricas de recursos: proporciona el uso de CPU y memoria para los pods 2. custom.metrics.k8s.io — Proporciona métricas de otros recopiladores de métricas, como Prometheus; estas métricas son internas de su clúster de Kubernetes. 3. external.metrics.k8s.io — Proporciona métricas externas a su clúster de Kubernetes (E.g., profundidad de cola de SQS, latencia de ELB).
Debe usar una de estas tres API para proporcionar la métrica necesaria para escalar su aplicación.
Escalar las aplicaciones en función de métricas personalizadas o externas
Puede usar métricas personalizadas o externas para escalar su aplicación en función de métricas distintas de la utilización de la CPU o la memoria. Los servidores de la API de métricas personalizadascustom-metrics.k8s.io API que HPA puede usar para escalar automáticamente las aplicaciones.
Puede usar el adaptador de Prometheus para las API de métricas de Kubernetes para
Una vez que haya implementado el adaptador Prometheus, podrá consultar métricas personalizadas mediante kubectl. kubectl get —raw /apis/custom.metrics.k8s.io/v1beta1/
Las métricas externas, como su nombre indica, proporcionan al escalador automático del pod horizontal la capacidad de escalar las implementaciones mediante métricas externas al clúster de Kubernetes. Por ejemplo, en las cargas de trabajo de procesamiento por lotes, es habitual escalar el número de réplicas en función del número de trabajos en curso en una cola de SQS.
Para escalar automáticamente las cargas de trabajo de Kubernetes, puedes usar KEDA (Kubernetes Event-driven Autoscaling), un proyecto de código abierto que puede impulsar el escalado de contenedores en función de una serie de eventos personalizados. En este blog de AWS
Escalador automático de cápsulas verticales (VPA)
El VPA ajusta automáticamente la reserva de CPU y memoria de tus Pods para ayudarte a ajustar el tamaño correcto a tus aplicaciones. En el caso de las aplicaciones que deban escalarse verticalmente (lo que se consigue aumentando la asignación de recursos), puedes usar el VPA
Es posible que tu aplicación deje de estar disponible temporalmente si VPA necesita escalarla, ya que la implementación actual del VPA no realiza ajustes in situ en los pods, sino que recrea el pod que necesita escalarse.
La documentación de EKS incluye un tutorial para configurar el VPA.
El proyecto Goldilocks de Fairwinds
Actualización de aplicaciones
Las aplicaciones modernas requieren una innovación rápida con un alto grado de estabilidad y disponibilidad. Kubernetes le proporciona las herramientas para actualizar sus aplicaciones de forma continua sin interrumpir a sus clientes.
Veamos algunas de las mejores prácticas que permiten implementar cambios rápidamente sin sacrificar la disponibilidad.
Disponga de un mecanismo para realizar reversiones
Tener un botón de deshacer puede evitar desastres. Se recomienda probar las implementaciones en un entorno inferior independiente (entorno de prueba o desarrollo) antes de actualizar el clúster de producción. El uso de una CI/CD canalización puede ayudarle a automatizar y probar las implementaciones. Con un proceso de implementación continuo, puede volver rápidamente a la versión anterior si la actualización resulta defectuosa.
Puede usar Deployments para actualizar una aplicación en ejecución. Por lo general, esto se hace actualizando la imagen del contenedor. Puedes usarlo kubectl para actualizar una implementación como esta:
kubectl --record deployment.apps/nginx-deployment set image nginx-deployment nginx=nginx:1.16.1
El --record argumento registra los cambios en la implementación y le ayuda si necesita realizar una reversión. kubectl rollout history deploymentmuestra los cambios registrados en las implementaciones de su clúster. Puede deshacer un cambio mediante. kubectl rollout undo deployment <DEPLOYMENT_NAME>
De forma predeterminada, cuando actualizas una implementación que requiere una recreación de los pods, Deployment realizará una actualización progresivaRollingUpdateStrategy
Al realizar una actualización sucesiva de una implementación, puedes usar la Max UnavailableMax Surge propiedad de despliegue te permite establecer el número máximo de pods que se pueden crear en lugar del número deseado de pods.
Considere la posibilidad max unavailable de realizar ajustes para garantizar que una implementación no cause molestias a sus clientes. Por ejemplo, Kubernetes establece un 25% de forma max unavailable predeterminada, lo que significa que si tienes 100 pods, es posible que solo tengas 75 pods funcionando activamente durante el lanzamiento. Si tu aplicación necesita un mínimo de 80 pods, esta implementación puede ser perjudicial. En su lugar, puedes max unavailable configurarlo en un 20% para asegurarte de que haya al menos 80 pods funcionales durante la implementación.
Usa despliegues blue/green
Los cambios son intrínsecamente riesgosos, pero los cambios que no se pueden deshacer pueden ser potencialmente catastróficos. Los procedimientos de cambio que permiten retroceder en el tiempo de forma eficaz mediante una reversión hacen que las mejoras y la experimentación sean más seguras. Blue/green las implementaciones le proporcionan un método para retirar rápidamente los cambios si las cosas van mal. En esta estrategia de despliegue, se crea un entorno para la nueva versión. Este entorno es idéntico a la versión actual de la aplicación que se está actualizando. Una vez que se aprovisiona el nuevo entorno, el tráfico se enruta al nuevo entorno. Si la nueva versión produce los resultados deseados sin generar errores, se cierra el entorno anterior. De lo contrario, el tráfico se restablece a la versión anterior.
Puedes realizar blue/green despliegues en Kubernetes creando un nuevo despliegue que sea idéntico al despliegue de la versión existente. Una vez que compruebes que los pods de la nueva implementación funcionan sin errores, puedes empezar a enviar tráfico a la nueva implementación cambiando la selector especificación del servicio que dirige el tráfico a los pods de tu aplicación.
Muchas herramientas de integración continua, como Flux
Utilice las implementaciones de Canary
Las implementaciones de Canary son una variante de las blue/green implementaciones que pueden eliminar significativamente el riesgo derivado de los cambios. En esta estrategia de despliegue, se crea un despliegue nuevo con menos módulos junto con el despliegue anterior y se desvía un pequeño porcentaje del tráfico al nuevo despliegue. Si las métricas indican que la nueva versión tiene un rendimiento igual o superior al de la versión existente, debe aumentar progresivamente el tráfico a la nueva implementación y, al mismo tiempo, ampliarlo hasta que todo el tráfico se desvíe a la nueva implementación. Si hay algún problema, puede dirigir todo el tráfico a la implementación anterior y dejar de enviar tráfico a la nueva implementación.
Aunque Kubernetes no ofrece una forma nativa de realizar despliegues automáticos, puedes usar herramientas como Flagger con Istio.
Health chequeos y autocuración
Ningún software está libre de errores, pero Kubernetes puede ayudarte a minimizar el impacto de los fallos de software. En el pasado, si una aplicación fallaba, alguien tenía que solucionar la situación reiniciándola manualmente. Kubernetes te permite detectar errores de software en tus Pods y sustituirlos automáticamente por réplicas nuevas. Con Kubernetes, puedes supervisar el estado de tus aplicaciones y reemplazar automáticamente las instancias en mal estado.
Kubernetes admite tres tipos de controles de estado:
-
Sonda de vivacidad
-
Sonda de inicio (compatible con la versión 1.16+ de Kubernetes)
-
Sonda de preparación
Kubelet
Si eliges un sondeo exec basado, que ejecute un script de shell dentro de un contenedor, asegúrate de que el comando shell se cierre antes de que caduque el valor. timeoutSeconds De lo contrario, el nodo tendrá <defunct> procesos, lo que provocará una falla en el nodo.
Recomendaciones
Utilice Liveness Probe para eliminar las cápsulas insalubres
La sonda Liveness puede detectar situaciones de bloqueo en las que el proceso continúa ejecutándose, pero la aplicación deja de responder. Por ejemplo, si ejecutas un servicio web que escucha en el puerto 80, puedes configurar una sonda Liveness para que envíe una solicitud HTTP GET al puerto 80 del Pod. Kubelet envía periódicamente una solicitud GET al Pod y espera una respuesta; si el Pod responde entre 200 y 399, el kubelet considera que el Pod está en buen estado; de lo contrario, el Pod se marcará como en mal estado. Si un pod no pasa las comprobaciones de estado continuas, el kubelet lo cancelará.
Puedes usarlo initialDelaySeconds para retrasar la primera sonda.
Cuando utilices el Liveness Probe, asegúrate de que tu aplicación no se encuentre en una situación en la que todos los pods no apaguen simultáneamente el Liveness Probe, ya que Kubernetes intentará reemplazar todos los pods, lo que dejará la aplicación fuera de línea. Además, Kubernetes seguirá creando nuevos pods que también fallarán con los Liveness Probes, lo que supondrá una carga innecesaria para el plano de control. Evita configurar el Liveness Probe para que dependa de un factor externo a tu Pod, por ejemplo, una base de datos externa. En otras palabras, una base de datos externa a tu POD que no responda no debería hacer que tus Pods no superen sus Liveness Probes.
El libro posterior a LIVENESS PROBES ARE DANGEROUS, de Sandor Szücs, describe los problemas que pueden provocar las sondas mal configuradas
Utilice Startup Probe para las aplicaciones que tardan más en iniciarse
Cuando tu aplicación necesite más tiempo para iniciarse, puedes usar la sonda de inicio para retrasar la sonda de vitalidad y preparación. Por ejemplo, una aplicación Java que necesita hidratar la memoria caché de una base de datos puede tardar hasta dos minutos en ser completamente funcional. Cualquier sonda de vitalidad o preparación hasta que esté completamente operativa podría fallar. La configuración de una sonda de inicio permitirá que la aplicación Java se mantenga en buen estado antes de que se ejecuten Liveness o Readiness Probe.
Hasta que la sonda de inicio tenga éxito, todas las demás sondas se desactivarán. Puedes definir el tiempo máximo que debe esperar Kubernetes para que se inicie la aplicación. Si, transcurrido el tiempo máximo configurado, el pod sigue fallando en las pruebas de inicio, se cerrará y se creará un nuevo pod.
El Startup Probe es similar al Liveness Probe: si fallan, se vuelve a crear el Pod. Como explica Ricardo A. en su artículo Fantastic Probes And How To Configure Them, losinitialDelaySeconds en su lugar.
Utilice Readiness Probe para detectar una falta de disponibilidad parcial
Mientras que la sonda Liveness detecta errores en una aplicación y se resuelven cerrando el pod (es decir, reiniciando la aplicación), Readiness Probe detecta situaciones en las que la aplicación puede no estar disponible temporalmente. En estas situaciones, es posible que la aplicación deje de responder temporalmente; sin embargo, se espera que vuelva a estar en buen estado una vez finalizada la operación.
Por ejemplo, durante I/O operaciones de disco intensas, es posible que las aplicaciones no estén disponibles temporalmente para gestionar las solicitudes. En este caso, cerrar el Pod de la aplicación no es una solución; al mismo tiempo, las solicitudes adicionales que se envíen al Pod pueden fallar.
Puedes usar la sonda de preparación para detectar la falta de disponibilidad temporal en tu aplicación y dejar de enviar solicitudes a su pod hasta que vuelva a funcionar. A diferencia de Liveness Probe, en el que un error provocaría la recreación del Pod, un error en el Readiness Probe implicaría que el Pod no recibirá tráfico del servicio de Kubernetes. Cuando la sonda de preparación se ejecute correctamente, el Pod volverá a recibir tráfico del servicio.
Al igual que la sonda Liveness Probe, evita configurar las sondas de preparación que dependan de un recurso externo al pod (como una base de datos). Esta es una situación en la que una configuración incorrecta de Readiness puede hacer que la aplicación deje de funcionar: si la sonda de preparación de un pod falla cuando no se puede acceder a la base de datos de la aplicación, otras réplicas del pod también fallarán simultáneamente, ya que comparten los mismos criterios de comprobación de estado. Si configuras la sonda de esta forma, se garantizará que, cuando la base de datos no esté disponible, las sondas de preparación del Pod fallarán y Kubernetes dejará de enviar tráfico a todos los pods.
Un efecto secundario del uso de las sondas de preparación es que pueden aumentar el tiempo que se tarda en actualizar las implementaciones. Las réplicas nuevas no recibirán tráfico a menos que las pruebas de preparación se realicen correctamente; hasta entonces, las réplicas antiguas seguirán recibiendo tráfico.
Hacer frente a las interrupciones
Los pods tienen una vida útil limitada. Incluso si tienes pods de larga duración, es prudente asegurarte de que los pods terminen correctamente cuando llegue el momento. En función de tu estrategia de actualización, las actualizaciones de los clústeres de Kubernetes pueden requerir la creación de nuevos nodos de trabajo, lo que requiere que todos los pods se vuelvan a crear en los nodos más nuevos. Una gestión adecuada de las terminaciones y los presupuestos de interrupción de los pods pueden ayudarte a evitar interrupciones en el servicio, ya que los pods se retiran de los nodos más antiguos y se vuelven a crear en los nodos más nuevos.
La forma preferida de actualizar los nodos de trabajo es crear nuevos nodos de trabajo y cerrar los antiguos. Antes de cerrar los nodos de trabajo, debería drain hacerlo. Cuando se vacía un nodo trabajador, todos sus módulos se desalojan de forma segura. En este caso, la palabra clave es «proteger»; cuando se desalojan las cápsulas de un trabajador, no se les envía simplemente una SIGKILL señal. En su lugar, se envía una SIGTERM señal al proceso principal (PID 1) de cada contenedor de las cápsulas que se va a desalojar. Una vez enviada la SIGTERM señal, Kubernetes concederá al proceso un SIGKILL tiempo (período de gracia) antes de que se envíe la señal. Este período de gracia es de 30 segundos de forma predeterminada; puedes anular el predeterminado usando grace-period flag en kubectl o declare en tu Podspec. terminationGracePeriodSeconds
kubectl delete pod <pod name> —grace-period=<seconds>
Es habitual tener contenedores en los que el proceso principal no tenga el PID 1. Considere este recipiente Python-based de muestra:
$ kubectl exec python-app -it ps PID USER TIME COMMAND 1 root 0:00 {script.sh} /bin/sh ./script.sh 5 root 0:00 python app.py
En este ejemplo, el script shell recibeSIGTERM, el proceso principal, que resulta ser una aplicación de Python en este ejemplo, no recibe ninguna SIGTERM señal. Cuando se cierre el Pod, la aplicación de Python se cerrará abruptamente. Esto se puede solucionar cambiando el ENTRYPOINT
También puedes usar Container HooksPreStop enganche se ejecuta antes de que el contenedor reciba una SIGTERM señal y debe completarse antes de que se envíe esta señal. El terminationGracePeriodSeconds valor se aplica desde el momento en que la acción de PreStop enganche comienza a ejecutarse, no cuando se envía la SIGTERM señal.
Recomendaciones
Proteja la carga de trabajo crítica con Pod Disruption Budgets
Pod Disruption Budget o PDB pueden detener temporalmente el proceso de desalojo si el número de réplicas de una aplicación cae por debajo del umbral declarado. El proceso de desalojo continuará una vez que el número de réplicas disponibles supere el umbral. Puede utilizar el PDB para declarar el maxUnavailable número minAvailable y el número de réplicas. Por ejemplo, si quieres que estén disponibles al menos tres copias de tu aplicación, puedes crear una PDB.
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: my-svc-pdb spec: minAvailable: 3 selector: matchLabels: app: my-svc
La política de PDB anterior indica a Kubernetes que detenga el proceso de desalojo hasta que haya tres o más réplicas disponibles. El PodDisruptionBudgets agotamiento de los nodos se respeta. Durante una actualización de un grupo de nodos gestionada por EKS, los nodos se agotan con un tiempo de espera de quince minutos. Transcurridos quince minutos, si la actualización no es forzada (la opción se denomina actualización progresiva en la consola de EKS), la actualización no se realizará correctamente. Si la actualización es forzada, se eliminan los pods.
Para los nodos autogestionados, también puede utilizar herramientas como AWS Node Termination Handler
Puedes usar la antiafinidad de los pods para programar los pods de una implementación en diferentes nodos y evitar demoras relacionadas con la PDB durante las actualizaciones de los nodos.
Practica la ingeniería del caos
La ingeniería del caos es la disciplina que consiste en experimentar con un sistema distribuido para generar confianza en la capacidad del sistema para soportar condiciones turbulentas durante la producción.
En su blog, Dominik Tornow explica que Kubernetes es un sistema declarativo en el que «el usuario proporciona al sistemareplica se bloquea, el controlador de despliegue creará uno nuevoreplica De esta forma, los controladores de Kubernetes corrigen automáticamente los fallos.
Las herramientas de ingeniería del caos, como Gremlin
Utilice una malla de servicios
Puede utilizar una malla de servicios para mejorar la resiliencia de su aplicación. Las mallas de servicio permiten la comunicación entre servicios y aumentan la observabilidad de su red de microservicios. La mayoría de los productos de malla de servicios funcionan con un pequeño proxy de red junto a cada servicio que intercepta e inspecciona el tráfico de red de la aplicación. Puede colocar la aplicación en una malla sin necesidad de modificarla. Con las funciones integradas del proxy de servicio, puede hacer que genere estadísticas de red, cree registros de acceso y añada encabezados HTTP a las solicitudes salientes para el rastreo distribuido.
Una malla de servicios puede ayudarle a hacer que sus microservicios sean más resilientes con funciones como los reintentos automáticos de solicitudes, los tiempos de espera, la interrupción de circuitos y la limitación de velocidad.
Si opera varios clústeres, puede utilizar una malla de servicios para permitir la comunicación entre clústeres de servicio a servicio.
Mallas de servicios
Observabilidad
La observabilidad es un término general que incluye el monitoreo, el registro y el rastreo. Las aplicaciones basadas en microservicios se distribuyen por naturaleza. A diferencia de las aplicaciones monolíticas, en las que basta con monitorear un solo sistema, en una arquitectura de aplicaciones distribuidas, es necesario monitorear el rendimiento de cada componente. Puede usar sistemas de monitoreo, registro y rastreo distribuido a nivel de clúster para identificar los problemas en su clúster antes de que afecten a sus clientes.
Las herramientas integradas de Kubernetes para la resolución de problemas y la supervisión son limitadas. El servidor de métricas recopila las métricas de los recursos y las almacena en la memoria, pero no las conserva. Puedes ver los registros de un pod con kubectl, pero Kubernetes no conserva los registros automáticamente. Además, la implementación del rastreo distribuido se realiza a nivel de código de la aplicación o mediante mallas de servicios.
La extensibilidad de Kubernetes brilla aquí. Kubernetes le permite ofrecer la solución centralizada de monitoreo, registro y rastreo que prefiera.
Recomendaciones
Supervise sus aplicaciones
La cantidad de métricas que necesita monitorear en las aplicaciones modernas crece continuamente. Es útil disponer de una forma automatizada de realizar el seguimiento de las aplicaciones, de modo que pueda centrarse en resolver los desafíos de sus clientes. Cluster-wide Las herramientas de monitoreo como Prometheus CloudWatch
Las herramientas de monitoreo le permiten crear alertas a las que su equipo de operaciones puede suscribirse. Considere la posibilidad de establecer reglas para activar las alarmas en caso de eventos que, si se agravan, pueden provocar una interrupción o afectar al rendimiento de las aplicaciones.
Si no tienes claro qué métricas debes monitorear, puedes inspirarte en estos métodos:
-
Método RED
. Representa las solicitudes, los errores y la duración. -
Método USE
. Representa la utilización, la saturación y los errores.
El post de Sysdig sobre las mejores prácticas para emitir alertas en Kubernetes
Utilice la biblioteca de clientes de Prometheus para exponer las métricas de la aplicación
Además de supervisar el estado de la aplicación y agregar métricas estándar, también puede usar la biblioteca cliente de Prometheus
Utilice herramientas de registro centralizadas para recopilar y conservar los registros
El registro en EKS se divide en dos categorías: registros del plano de control y registros de aplicaciones. El registro del plano de control de EKS proporciona registros de auditoría y diagnóstico directamente desde el plano de control a CloudWatch los registros de su cuenta. Los registros de aplicaciones son registros generados por los pods que se ejecutan dentro de tu clúster. Los registros de aplicaciones incluyen los registros producidos por los pods que ejecutan las aplicaciones de lógica empresarial y los componentes del sistema de Kubernetes, como CoredNS, Cluster Autoscaler, Prometheus, etc.
Los EKS proporcionan cinco tipos de registros del plano de control:
-
Registros de los componentes del servidor de la API de Kubernetes
-
Auditoría
-
Autenticador
-
Gestor de controladores
-
Programador
Los registros del administrador del controlador y del planificador pueden ayudar a diagnosticar problemas en el plano de control, como los cuellos de botella y los errores. De forma predeterminada, los registros del plano de control de EKS no se envían a Logs. CloudWatch Puede habilitar el registro del plano de control y seleccionar los tipos de registros del plano de control de EKS que desea capturar para cada clúster de su cuenta
Para recopilar los registros de las aplicaciones, es necesario instalar en el clúster una herramienta de agregación de registros como Fluent Bit
Las herramientas de agregación de registros de Kubernetes se ejecutan como DaemonSets registros de contenedores y los extraen de los nodos. Luego, los registros de las aplicaciones se envían a un destino centralizado para su almacenamiento. Por ejemplo, CloudWatch Container Insights puede usar FluentBit o Fluentd para recopilar registros y enviarlos a CloudWatch Logs para su almacenamiento. Fluent Bit y Fluentd son compatibles con muchos de los sistemas de análisis de registros más populares, como Elasticsearch e InfluxDB, lo que le permite cambiar el backend de almacenamiento de sus registros modificando Fluentbit o la configuración de registros de Fluentd.
Utilice un sistema de rastreo distribuido para identificar los cuellos de botella
Una aplicación moderna típica tiene componentes distribuidos por la red y su confiabilidad depende del correcto funcionamiento de cada uno de los componentes que componen la aplicación. Puede utilizar una solución de rastreo distribuido para comprender cómo fluyen las solicitudes y cómo se comunican los sistemas. Los rastreos pueden mostrarle dónde existen cuellos de botella en la red de aplicaciones y evitar problemas que puedan provocar errores en cascada.
Tiene dos opciones para implementar el rastreo en sus aplicaciones: puede implementar el rastreo distribuido a nivel de código mediante bibliotecas compartidas o usar una malla de servicios.
Implementar el rastreo a nivel de código puede ser desventajoso. En este método, debe realizar cambios en el código. Esto se complica aún más si tiene aplicaciones políglotas. También es responsable del mantenimiento de otra biblioteca en todos sus servicios.
Las mallas de servicio, como LinkerD
Con herramientas de rastreo como AWS X-Ray
Considere la posibilidad de utilizar una herramienta de rastreo como AWS X-Ray
