AWS Data Pipeline ya no está disponible para nuevos clientes. Los clientes actuales de AWS Data Pipeline pueden seguir utilizando el servicio con normalidad. Más información
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Lanzar un clúster mediante la línea de comando
Si ejecuta habitualmente un clúster de Amazon EMR para analizar registros web o realizar análisis de datos científicos, puede utilizarlo AWS Data Pipeline para gestionar sus clústeres de Amazon EMR. Con AWS Data Pipeline, puede especificar las condiciones previas que deben cumplirse antes del lanzamiento del clúster (por ejemplo, asegurarse de que los datos del día de hoy se hayan cargado en Amazon S3). Este tutorial le mostrará cómo lanzar un clúster, que puede ser un modelo para una canalización sencilla basada en Amazon EMR o como parte de una canalización más compleja.
Requisitos previos
Antes de poder utilizar la CLI; debe llevar a cabo los pasos siguientes:
-
Instale y configure la interfaz de la línea de comandos (CLI). Para obtener más información, consulte Accediendo AWS Data Pipeline.
-
Asegúrese de que las funciones de IAM nombradas DataPipelineDefaultRoley DataPipelineDefaultResourceRolede que existan. La AWS Data Pipeline consola crea estos roles automáticamente. Si no ha utilizado la AWS Data Pipeline consola al menos una vez, debe crear estos roles manualmente. Para obtener más información, consulte Funciones de IAM para AWS Data Pipeline.
Tareas
Creación del archivo de definición de canalización
El código siguiente es el archivo de definición de canalización para un clúster sencillo de Amazon EMR que ejecuta un trabajo de Hadoop Streaming existente proporcionado por Amazon EMR. Esta aplicación de ejemplo se llama WordCount y también puede ejecutarla mediante la consola Amazon EMR.
Copie este código en un archivo de texto y guárdelo como MyEmrPipelineDefinition.json. Debe sustituir la ubicación del bucket de Amazon S3 por el nombre de un bucket de Amazon S3 de su propiedad. También debe sustituir las fechas de inicio y final. Para lanzar clústeres de forma inmediata, establezca una fecha startDateTime para un día en el pasado y endDateTime para un día en el futuro. AWS Data Pipeline a continuación, comienza a lanzar inmediatamente los clústeres «vencidos», en un intento de abordar lo que percibe como una acumulación de trabajo pendiente. Esta sobrecarga significa que no tendrá que esperar una hora para que se AWS Data Pipeline lance su primer clúster.
{ "objects": [ { "id": "Hourly", "type": "Schedule", "startDateTime": "2012-11-19T07:48:00", "endDateTime": "2012-11-21T07:48:00", "period": "1 hours" }, { "id": "MyCluster", "type": "EmrCluster", "masterInstanceType": "m1.small", "schedule": { "ref": "Hourly" } }, { "id": "MyEmrActivity", "type": "EmrActivity", "schedule": { "ref": "Hourly" }, "runsOn": { "ref": "MyCluster" }, "step": "/home/hadoop/contrib/streaming/hadoop-streaming.jar,-input,s3n://elasticmapreduce/samples/wordcount/input,-output,s3://myawsbucket/wordcount/output/#{@scheduledStartTime},-mapper,s3n://elasticmapreduce/samples/wordcount/wordSplitter.py,-reducer,aggregate" } ] }
Esta canalización tiene tres objetos:
-
Hourly, que representa el programa del trabajo. Puede establecer un programa como uno de los campos de una actividad. Cuando lo haga, la actividad se ejecutará de acuerdo con dicho programa o, en este caso, cada hora. -
MyCluster, que representa el conjunto de instancias Amazon EC2 utilizadas para ejecutar el clúster. Puede especificar el tamaño y el número de instancias EC2 que se ejecutarán como el clúster. Si no especifica el número de instancias, el clúster se lanzará con dos, un nodo principal y un nodo de tarea. Puede especificar una subred en la que lanzar el clúster. Puede añadir configuraciones adicionales al clúster, tales como acciones de arranque para cargar software adicional en la AMI proporcionada por Amazon EMR. -
MyEmrActivity, que representa el cálculo que se procesará con el clúster. Amazon EMR admite varios tipos de clústeres, entre los que se incluyen streaming, Cascading y Scripted Hive. ElrunsOncampo hace referencia a MyCluster, usándolo como especificación para los fundamentos del clúster.
Actualización y activación de la definición de la canalización
Debe cargar la definición de su canalización y activarla. En los siguientes comandos de ejemplo, pipeline_name sustitúyala por una etiqueta para la canalización y pipeline_file por la ruta completa para el archivo de definición de la canalización. .json
AWS CLI
Para crear su definición de canalización y activarla, use el siguiente comando create-pipeline. Anote el ID de su canalización, ya que utilizará este valor con la mayoría de los comandos de la CLI.
aws datapipeline create-pipeline --name{ "pipelineId": "df-00627471SOVYZEXAMPLE" }pipeline_name--unique-idtoken
Para cargar la definición de tu canalización, usa el siguiente put-pipeline-definitioncomando.
aws datapipeline put-pipeline-definition --pipeline-id df-00627471SOVYZEXAMPLE --pipeline-definition file://MyEmrPipelineDefinition.json
Si la canalización se valida correctamente, el campo validationErrors estará vacío. Debe revisar todas las advertencias.
Para activar la canalización, utilice el siguiente comando activate-pipeline:
aws datapipeline activate-pipeline --pipeline-id df-00627471SOVYZEXAMPLE
Puede comprobar que su canalización aparece en la lista de canalizaciones mediante el siguiente comando list-pipelines.
aws datapipeline list-pipelines
Supervisar las ejecuciones de la canalización
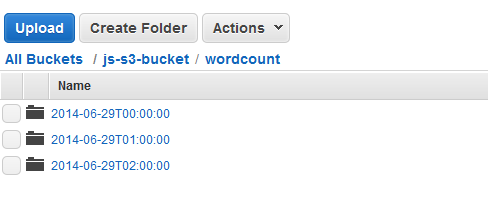
Puede ver los clústeres lanzados AWS Data Pipeline mediante la consola Amazon EMR y puede ver la carpeta de salida mediante la consola Amazon S3.
Para comprobar el progreso de los clústeres lanzados por AWS Data Pipeline
-
Abra la consola de Amazon EMR.
-
Los clústeres generados por AWS Data Pipeline tienen un nombre con el siguiente formato:
<pipeline-identifier><emr-cluster-name>_@ _.<launch-time>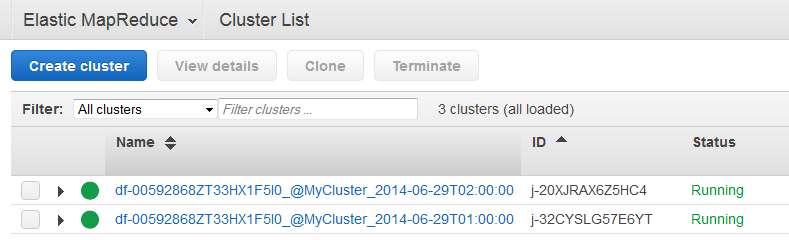
-
Cuando finalice una de las ejecuciones, abra la consola de Amazon S3 y compruebe que la carpeta de salida con marca temporal existe y contiene los resultados esperados del clúster.