Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Configuración y personalización de las consultas y la generación de respuestas
Puede configurar y personalizar la recuperación y la generación de respuestas, lo que mejora aún más la pertinencia de las respuestas. Por ejemplo, puede aplicar filtros a los metadatos de los documentos fields/attributes para usar los documentos actualizados más recientemente o los documentos con tiempos de modificación recientes.
nota
Todas las siguientes configuraciones, excepto orquestación y generación, se aplican únicamente a orígenes de datos no estructurados.
Para obtener más información sobre estas configuraciones en la consola o la API, seleccione uno de los siguientes temas:
Cuando consulta una base de conocimientos, Amazon Bedrock devuelve hasta cinco resultados en la respuesta de forma predeterminada. Cada resultado corresponde a un fragmento de origen.
nota
El número real de resultados de la respuesta puede ser inferior al valor de numberOfResults especificado, ya que este parámetro establece el número máximo de resultados que se devuelven. Si ha configurado la fragmentación jerárquica para su estrategia de fragmentación, el parámetro numberOfResults se asigna al número de fragmentos secundarios que recuperará la base de conocimiento. Como los fragmentos secundarios que comparten el mismo fragmento principal se sustituyen por el fragmento principal en la respuesta final, es posible que la cantidad de resultados devueltos sea inferior a la cantidad solicitada.
Para modificar el número máximo de resultados que se devuelven, seleccione la pestaña correspondiente al método que prefiera y siga estos pasos:
El tipo de búsqueda define cómo se consultan los orígenes de datos en la base de conocimientos. Los tipos de búsqueda posibles son los siguientes:
nota
La búsqueda híbrida solo se admite en los almacenes vectoriales de Amazon RDS, Amazon OpenSearch Serverless y MongoDB que contienen un campo de texto filtrable. Si utiliza un almacén de vectores diferente o su almacén de vectores no contiene un campo de texto filtrable, la consulta utiliza la búsqueda semántica.
-
Predeterminada: Amazon Bedrock decide la estrategia de búsqueda por usted.
-
Híbrida: combina la búsqueda de incrustaciones vectoriales (búsqueda semántica) con la búsqueda en el texto sin procesar.
-
Semántica: solo busca incrustaciones vectoriales.
Para obtener información sobre cómo definir el tipo de búsqueda, seleccione la pestaña correspondiente al método que prefiera y siga los pasos:
Puede aplicar filtros al documento fields/attributes para mejorar aún más la relevancia de las respuestas. Sus fuentes de datos pueden incluir metadatos de documentos attributes/fields para filtrar y pueden especificar qué campos incluir en las incrustaciones.
Consideraciones sobre la base de conocimientos gestionada
Al utilizar el filtrado de metadatos con una base de conocimientos gestionada:
-
Los filtros
startsWithy destringContainsmetadatos no son compatibles. En su lugarequalsgreaterThanlessThan, utilicenotInlos operadoresin,, u. -
En el caso de las bases de conocimiento personalizadas, el servicio reserva
x-amz-bedrocklos campos de metadatos con el prefijo. En el caso de bases de conocimiento totalmente gestionadas, los campos de metadatos reservados utilizan un prefijo de subrayado (por ejemplo,_source_uri)._data_source_idNo puede anular los campos de metadatos reservados en ninguno de los tipos de bases de conocimientos.
Por ejemplo, “epoch_modification_time” representa el tiempo en segundos transcurridos desde el 1 de enero de 1970 (UTC) hasta que se actualizó el documento por última vez. Puede filtrar por los datos más recientes, donde “epoch_modification_time” es mayor que un número determinado. Estos documentos más recientes se pueden utilizar para la consulta.
Para utilizar filtros al consultar una base de conocimientos, compruebe que la base de conocimientos cumpla los siguientes requisitos:
-
Al configurar el conector del origen de datos, la mayoría de los conectores rastrea los principales campos de metadatos de los documentos. Si utiliza un bucket de Amazon S3 como origen de datos, el bucket debe incluir al menos un
fileName.extension.metadata.jsonpara el archivo o documento con el que está asociado. Consulte Campos de metadatos del documento Configuración de la conexión para obtener más información sobre cómo configurar el archivo de metadatos. -
Si el índice vectorial de su base de conocimientos se encuentra en un almacén vectorial de Amazon OpenSearch Serverless, compruebe que el índice vectorial esté configurado con el
faissmotor. Si el índice vectorial está configurado con el motornmslib, deberá realizar una de las siguientes acciones:-
Cree una nueva base de conocimientos en la consola y deje que Amazon Bedrock cree automáticamente un índice vectorial en Amazon OpenSearch Serverless por usted.
-
Crear otro índice vectorial en el almacén vectorial y seleccionar
faisscomo el motor. A continuación, cree una nueva base de conocimientos y especifique el nuevo índice vectorial.
-
-
Si su base de conocimiento utiliza un índice vectorial en un bucket vectorial de S3, no puede utilizar los filtros
startsWithystringContains. -
Si va a añadir metadatos a un índice vectorial existente en un clúster de base de datos de Amazon Aurora, le recomendamos que proporcione el nombre de campo de la columna de metadatos personalizada para almacenar todos los metadatos en una sola columna. Durante la ingesta de datos, esta columna se utilizará para rellenar toda la información de los archivos de metadatos de los orígenes de datos. Si decide proporcionar este campo, debe crear un índice en esta columna.
-
Cuando cree una nueva base de conocimiento en la consola y deje que Amazon Bedrock configure su base de datos de Amazon Aurora, creará automáticamente una sola columna para usted y la rellenará con la información de sus archivos de metadatos.
-
Si decide crear otro índice vectorial en el almacén de vectores, debe proporcionar el nombre del campo de metadatos personalizado para almacenar la información de sus archivos de metadatos. Si no proporciona este nombre de campo, debe crear una columna para cada atributo de metadatos de sus archivos y especificar el tipo de datos (texto, número o booleano). Por ejemplo, si existiera el atributo
genreen el origen de datos, añadiría una columna con el nombregenrey especificaríatextcomo tipo de datos. Durante la ingesta de datos, estas columnas se rellenarán con los valores de atributo correspondientes.
-
Si tiene documentos PDF en su fuente de datos y utiliza Amazon OpenSearch Serverless o Amazon Aurora como almacén vectorial: las bases de conocimiento de Amazon Bedrock generarán los números de página de los documentos y los almacenarán en un metadato field/attribute denominado x-amz-bedrock-kb-document-page-number. Tenga en cuenta que los números de página almacenados en un campo de metadatos no se admiten si elige no fragmentar sus documentos.
Puede utilizar los siguientes operadores de filtrado para filtrar los resultados al realizar consultas:
| Operador | Consola | Nombre del filtro de la API | Tipos de datos de atributos compatibles | Resultados filtrados |
|---|---|---|---|---|
| Igual a | = | equals | cadena, número, booleano | El atributo coincide con el valor que ha proporcionado |
| No es igual a | != | notEquals | cadena, número, booleano | El atributo no coincide con el valor que ha proporcionado |
| Mayor que | > | greaterThan | número | El atributo es mayor que el valor que ha proporcionado |
| Mayor que o igual a | >= | mayor ThanOrEquals | número | El atributo es mayor que o igual al valor que ha proporcionado |
| Menor que | < | lessThan | número | El atributo es menor que el valor que ha proporcionado |
| Menor que o igual a | <= | menos ThanOrEquals | número | El atributo es menor que o igual al valor que ha proporcionado |
| In | : | in | lista de cadenas | El atributo está en la lista que usted proporciona (actualmente es más compatible con las tiendas de vectores GraphRag de Amazon OpenSearch Serverless y Neptune Analytics) |
| No en | !: | notIn | lista de cadenas | El atributo no está en la lista que has proporcionado (actualmente es más compatible con las tiendas vectoriales GraphRag de Amazon OpenSearch Serverless y Neptune Analytics) |
| Contiene una cadena | No disponible | stringContains | cadena | El atributo debe ser una cadena. El nombre del atributo coincide con la clave y su valor es una cadena que contiene el valor que ha proporcionado como subcadena, o una lista con un miembro que contiene el valor que ha proporcionado como subcadena (actualmente es más compatible con el almacén de vectores de Amazon OpenSearch Serverless). El almacén de vectores GraphRag de Neptune Analytics admite la variante de cadena (pero no la variante de lista) de este filtro. |
| Contiene una lista | No disponible | listContains | cadena | El atributo debe ser una lista de cadenas. El nombre del atributo coincide con la clave y su valor es una lista que contiene el valor que usted proporcionó como uno de sus miembros (actualmente es más compatible con las tiendas de vectores de Amazon OpenSearch Serverless). |
Para combinar los operadores de filtrado, puede usar los siguientes operadores lógicos:
Para obtener información sobre cómo filtrar los resultados con los metadatos, seleccione la pestaña correspondiente al método que prefiera y siga estos pasos:
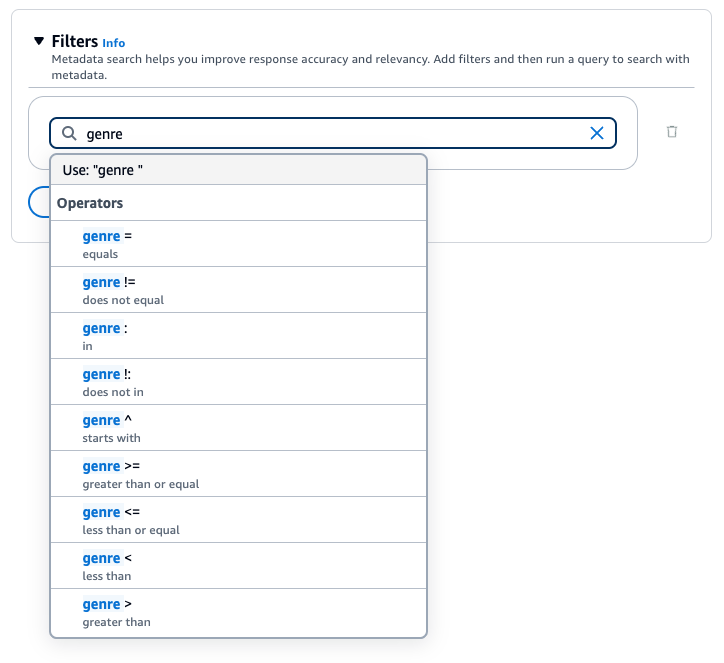
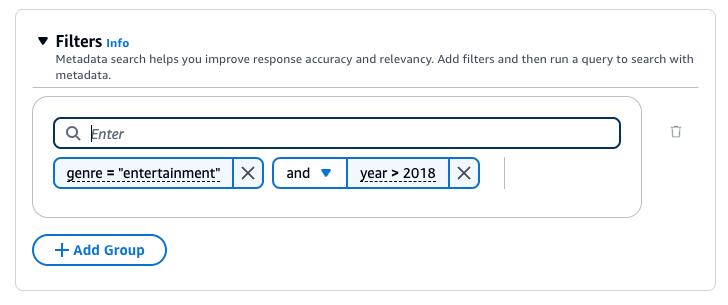
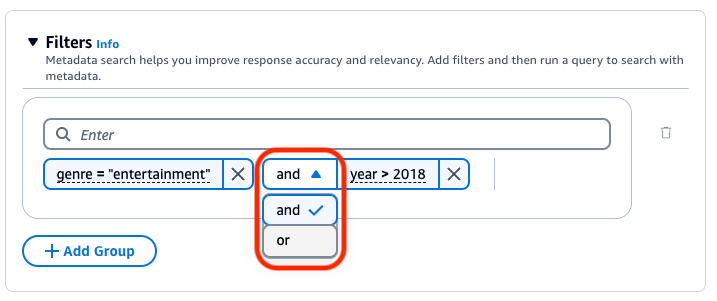
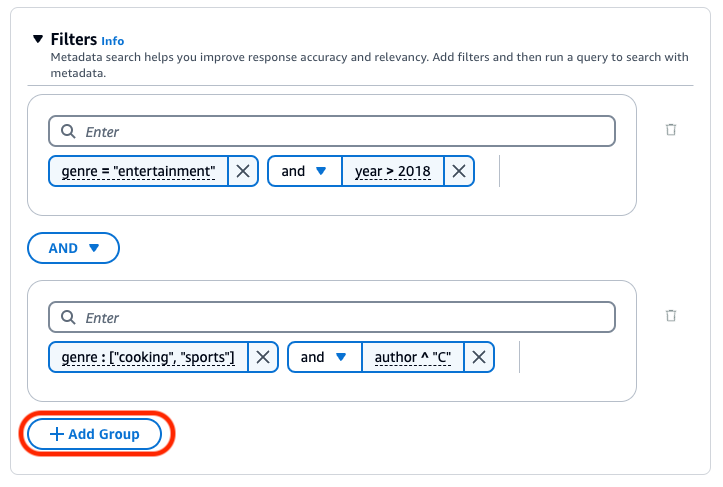
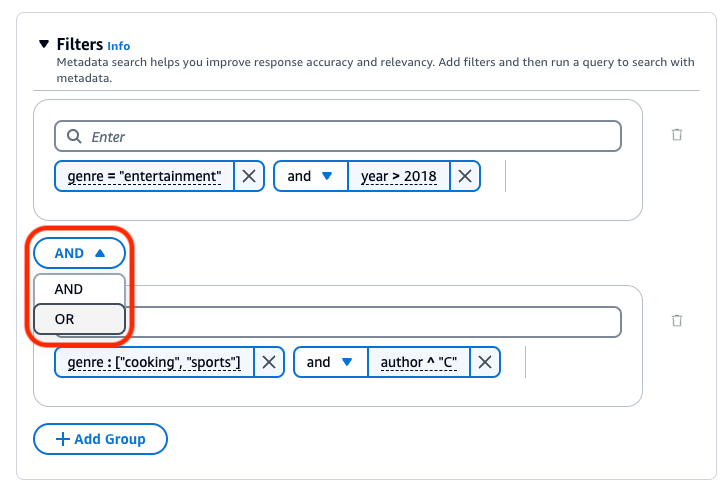
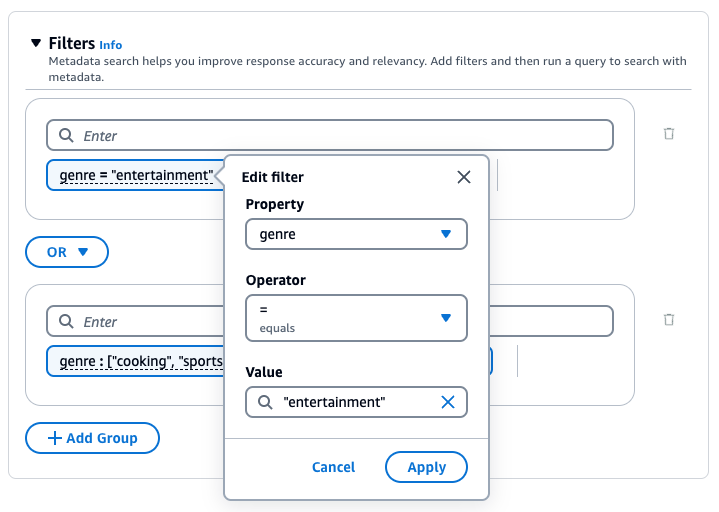
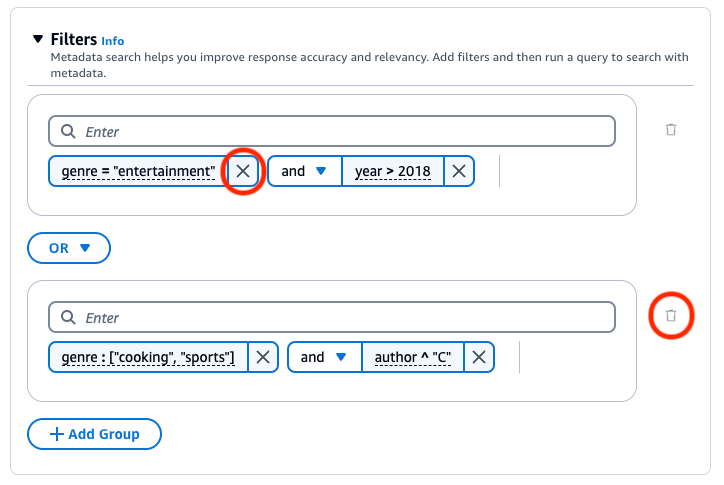
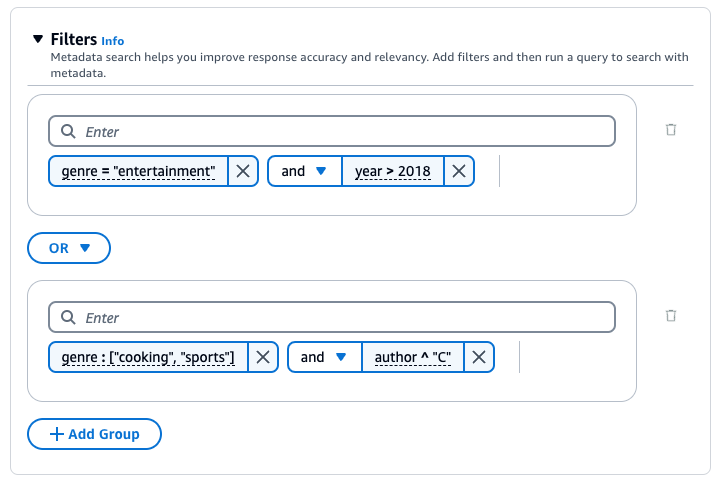
Bases de conocimiento de Amazon Bedrock genera y aplica un filtro de recuperación basado en la consulta del usuario y en un esquema de metadatos.
nota
Los Anthropic Claude modelos admiten el filtrado de metadatos implícito. Para obtener más información sobre los modelos compatibles, consulte los modelos de un vistazo.
El valor de implicitFilterConfiguration se especifica en el elemento vectorSearchConfiguration del cuerpo de la solicitud Retrieve. Puede incluir los siguientes campos:
-
metadataAttributes: en esta matriz, proporcione esquemas que describan los atributos de los metadatos para los que el modelo generará un filtro. -
modelArn: el ARN del modelo que se va a utilizar.
A continuación, se muestra un ejemplo de esquemas de metadatos que se pueden añadir a la matriz metadataAttributes.
[ { "key": "company", "type": "STRING", "description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc" }, { "key": "ticker", "type": "STRING", "description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL" }, { "key": "pe_ratio", "type": "NUMBER", "description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper." }, { "key": "is_us_company", "type": "BOOLEAN", "description": "Indicates whether the company is a US company." }, { "key": "tags", "type": "STRING_LIST", "description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc" } ]
Puede implementar protecciones en la base de conocimientos para sus casos de uso y políticas de IA responsable. Puede crear varias barreras de protección adaptadas a diferentes casos de uso y aplicarlas en diferentes condiciones de solicitud y respuesta para proporcionar una experiencia de usuario coherente y estandarizar los controles de seguridad en toda la base de conocimientos. Puede configurar los temas denegados para que no se admitan temas no deseados y filtros de contenido para bloquear el contenido dañino en las entradas y respuestas del modelo. Para obtener más información, consulte Detección y filtrado del contenido dañino mediante Barreras de protección para Amazon Bedrock.
nota
Actualmente, Claude 3 Sonnet y Haiku no admiten el uso de barreras de protección con fundamento contextual para las bases de conocimientos.
Para ver las directrices generales de ingeniería de peticiones, consulte Conceptos de ingeniería de peticiones.
Elija la pestaña del método que prefiera y siga estos pasos:
Puede utilizar un modelo reclasificador para recuperar los resultados de una consulta a la base de conocimiento. Siga los pasos de la consola que se indican en Consulta de una base de conocimiento y recuperación de datos o Consulta de una base de conocimiento y generación de respuestas en función de los datos recuperados. Cuando abra el panel Configuraciones, amplíe la sección Reordenamiento. Seleccione un modelo reclasificador, actualice los permisos si es necesario y modifique las opciones adicionales. Introduzca una petición y seleccione Ejecutar para probar los resultados después de la reclasificación.
La descomposición de consultas es una técnica que se usa para desglosar las consultas complejas en subconsultas más pequeñas y más fáciles de administrar. Este enfoque puede ayudar a recuperar información más precisa y pertinente, especialmente cuando la consulta inicial es multifacética o demasiado amplia. Si se activa esta opción, es posible que se ejecuten varias consultas en la base de conocimientos, lo que puede ayudar a obtener una respuesta final más precisa.
Por ejemplo, para una pregunta como «¿Quién marcó más en la Copa Mundial de la FIFA 2022, Argentina o Francia?» , las bases de conocimiento de Amazon Bedrock pueden generar primero las siguientes subconsultas antes de generar una respuesta final:
-
¿Cuántos goles marcó Argentina en la final de la Copa del Mundo de la FIFA 2022?
-
¿Cuántos goles marcó Francia en la final de la Copa del Mundo de la FIFA 2022?
Al generar respuestas basadas en la recuperación de información, puede utilizar parámetros de inferencia para tener un mayor control sobre el comportamiento del modelo durante la inferencia e influir en los resultados del modelo.
Para obtener información sobre cómo modificar los parámetros de inferencia, seleccione la pestaña correspondiente al método que prefiera y siga los pasos:
Cuando consulta una base de conocimiento y solicita la generación de respuestas, Amazon Bedrock utiliza una plantilla de petición que combina las instrucciones y el contexto con la consulta del usuario para crear la petición que se envía al modelo para la generación de respuestas. Puede personalizar la petición de orquestación, que convierte la petición del usuario en una consulta de búsqueda. Puede diseñar las plantillas de petición con las siguientes herramientas:
-
Marcadores de posición rápidos: Pre-defined variables de las bases de conocimiento de Amazon Bedrock que se rellenan dinámicamente en tiempo de ejecución durante una consulta a la base de conocimientos. En la petición del sistema, puede ver estos marcadores de posición rodeados por el símbolo
$. En la siguiente lista se describen los marcadores de posición que puede utilizar:nota
El marcador de posición
$output_format_instructions$es un campo obligatorio para que las citas se muestren en la respuesta.Variable Plantilla de petición Se sustituye por Modelo ¿Obligatorio? $query$ Orquestación, generación Es la consulta del usuario enviada a la base de conocimientos. Anthropic Claude Instant, Anthropic Claude v2.x Sí Anthropic Claude 3 Sonnet No (incluido automáticamente en la entrada del modelo) $search_results$ Generación Los resultados recuperados para la consulta del usuario. Todos Sí $output_format_instructions$ Orquestación Instrucciones subyacentes para formatear la generación de respuestas y las citas. Depende del modelo. Si define sus propias instrucciones de formato, le sugerimos que elimine este marcador de posición. Sin este marcador de posición, la respuesta no contendrá citas. Todos Sí $current_time$ Orquestación, generación Hora actual Todos No -
Etiquetas XML: los modelos Anthropic admiten el uso de etiquetas XML para estructurar y delinear las peticiones. Utilice nombres de etiquetas descriptivos para obtener resultados óptimos. Por ejemplo, en la petición predeterminada del sistema, verá la etiqueta
<database>utilizada para delinear una base de datos de preguntas anteriores. Para obtener más información, consulte Usa etiquetas XMLen la Guía del usuario de Anthropic .
Para ver las directrices generales de ingeniería de peticiones, consulte Conceptos de ingeniería de peticiones.
nota
Cuando no proporciona una plantilla de mensaje personalizada, Amazon Bedrock utiliza un mensaje del sistema predeterminado que incluye contenido de ejemplo genérico (como ejemplos de preguntas y respuestas sobre temas no relacionados) para guiar el formato de respuesta del modelo. Este mensaje predeterminado está visible en los registros de invocación del modelo. El contenido de ejemplo del mensaje predeterminado no proviene de los datos de otros clientes, sino de una plantilla estática proporcionada por Amazon Bedrock. Puede anular el mensaje predeterminado especificando el suyo propio. textPromptTemplate
Elija la pestaña del método que prefiera y siga estos pasos:
