Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Prácticas recomendadas para lograr la eficiencia y optimización del rendimiento en Amazon MQ para RabbitMQ
Puede optimizar el rendimiento de su agente Amazon MQ para RabbitMQ maximizando el rendimiento, minimizando la latencia y garantizando un uso eficiente de los recursos. Siga las siguientes prácticas recomendadas para optimizar el rendimiento de su aplicación.
Paso 1: Mantenga el tamaño de los mensajes por debajo de 1 MB
Recomendamos mantener los mensajes en un tamaño inferior a 1 megabyte (MB) para obtener un rendimiento y una fiabilidad óptimos.
De forma predeterminada, RabbitMQ 3.13 admite mensajes de hasta 128 MB, pero los mensajes de gran tamaño pueden activar alarmas de memoria impredecibles que bloquean la publicación y pueden generar una gran presión de memoria al replicar los mensajes en los nodos. Los mensajes sobredimensionados también pueden afectar a los procesos de reinicio y recuperación de los agentes, lo que aumenta los riesgos para la continuidad del servicio y puede provocar una degradación del rendimiento.
Almacene y recupere cargas útiles de gran tamaño mediante el patrón de verificación de notificaciones
Para gestionar mensajes de gran tamaño, puede implementar el patrón de verificación de notificaciones almacenando la carga útil del mensaje en un almacenamiento externo y enviando únicamente el identificador de referencia de la carga útil a través de RabbitMQ. El consumidor utiliza el identificador de referencia de la carga útil para recuperar y procesar el mensaje de gran tamaño.
En el siguiente diagrama se muestra cómo utilizar Amazon MQ para RabbitMQ y Amazon S3 para implementar el patrón de verificación de notificaciones.
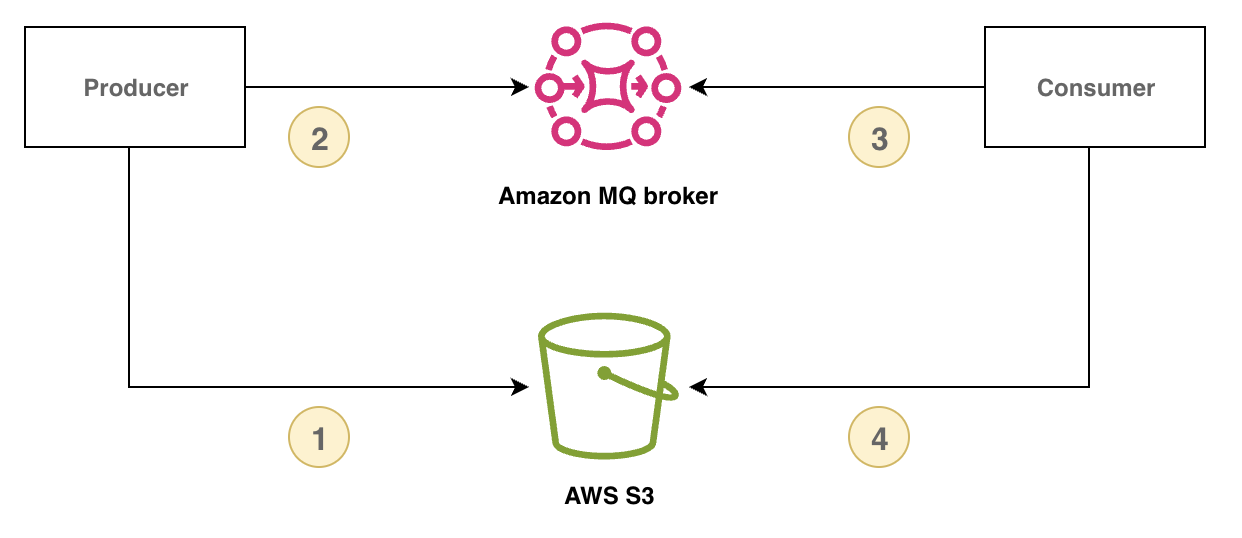
En el siguiente ejemplo, se muestra este patrón con Amazon MQ, el AWS SDK para Java 2.x y Amazon S3:
-
En primer lugar, defina una clase de mensaje que contenga el identificador de referencia de Amazon S3.
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
Cree un método de publicación que almacene la carga útil en Amazon S3 y envíe un mensaje de referencia a través de RabbitMQ.
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
Implemente un método de consumo que recupere la carga útil de Amazon S3, la procese y elimine el objeto de Amazon S3.
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
Paso 2: Uso basic.consume y consumo de larga duración
Usar basic.consume con un consumidor de larga duración es más eficiente que sondear los mensajes individuales utilizando basic.get. Para obtener más información, consulte Sondeo de mensajes individuales
Paso 3: Configurar la captura previa
Puede utilizar el valor de captura previa de RabbitMQ para optimizar la forma en que los consumidores consumen los mensajes. RabbitMQ implementa el mecanismo de captura previa de canales que proporciona AMQP 0-9-1 mediante la aplicación del recuento de captura previa a los consumidores en lugar de a los canales. El valor de captura previa se utiliza para especificar cuántos mensajes se envían al consumidor en un momento dado. De forma predeterminada, RabbitMQ establece un tamaño de búfer ilimitado para las aplicaciones cliente.
Hay varios factores a tener en cuenta al establecer un recuento de captura previa para los consumidores de RabbitMQ. Primero, considere el entorno y la configuración de los consumidores. Debido a que los consumidores necesitan mantener todos los mensajes en la memoria mientras se procesan, un alto valor de captura previa puede tener un impacto negativo en el rendimiento de los consumidores y, en algunos casos, puede provocar el bloqueo de todos los consumidores juntos. Del mismo modo, el propio agente de RabbitMQ guarda todos los mensajes que envía en la memoria caché hasta que recibe el acuse de recibo del consumidor. Un alto valor de captura previa puede hacer que el servidor de RabbitMQ se quede sin memoria rápidamente si el reconocimiento automático no está configurado para los consumidores y si los consumidores tardan un tiempo relativamente largo en procesar mensajes.
Teniendo en cuenta las consideraciones anteriores, recomendamos establecer siempre un valor de captura previa para evitar situaciones en las que un agente de RabbitMQ o sus consumidores se queden sin memoria debido a un gran número de mensajes sin procesar o sin reconocer. Si necesita optimizar sus agentes para que procesen grandes volúmenes de mensajes, puede probarlos junto con los consumidores utilizando un intervalo de recuentos de captura previa para determinar el valor en el que la sobrecarga de red se vuelve en gran medida insignificante en comparación con el tiempo que tarda un consumidor en procesar mensajes.
nota
Si las aplicaciones cliente se han configurado para confirmar automáticamente la entrega de mensajes a los consumidores, no servirá de nada establecer un valor de captura previa.
Todos los mensajes que capturados previamente se eliminan de la cola.
En el siguiente ejemplo, se muestra cómo establecer un valor de captura previa de 10 para un solo consumidor utilizando la biblioteca de clientes Java de RabbitMQ.
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
nota
En la biblioteca de clientes Java de RabbitMQ, el valor predeterminado para el indicador global se establece en false, por lo que el ejemplo anterior se puede escribir simplemente como channel.basicQos(10).
Paso 4: Utilice Celery 5.5 o una versión posterior con las colas de cuórum
Python Celery
Para todas las versiones de Celery
-
Desactiva
task_create_missing_queuespara reducir la pérdida de colas. -
A continuación, desactiva
worker_enable_remote_controlpara detener la creación dinámica de colascelery@...pidbox. Esto reducirá la pérdida de colas en el agente.worker_enable_remote_control = false -
Para reducir aún más la actividad de mensajes no críticos, desactive Celery y worker-send-task-events
deje de incluirlos -Eni--task-eventsmarcarlos al iniciar la aplicación Celery. -
Inicie la aplicación Celery con los siguientes parámetros:
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
Para las versiones 5.5 y superiores de Celery
-
Actualice Celery a la versión 5.5
, la versión mínima que admite las colas de cuórum, o a una versión posterior. Para ver qué versión de Celery está usando, utilice celery --version. Para obtener más información sobre los cuórums, consulte Colas de cuórum para RabbitMQ en Amazon MQ. -
Después de actualizar a Celery 5.5 o una versión posterior, configure
task_default_queue_typeen modo “cuórum”. -
A continuación, también debe activar la opción Publicar confirmaciones en Broker Transport Options
: broker_transport_options = {"confirm_publish": True}
