Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Convertir los procesos de ETL a in AWS Glue AWS Schema Conversion Tool
A continuación, encontrará un resumen del proceso para convertir los scripts de ETL en AWS SCT. AWS Glue En este ejemplo vamos a convertir una base de datos Oracle a Amazon Redshift, junto con los procesos de ETL utilizados con las bases de datos de origen y almacenamientos de datos.
Temas
El siguiente diagrama de arquitectura muestra un ejemplo de proyecto de migración de bases de datos que incluye la conversión de scripts de ETL a AWS Glue.
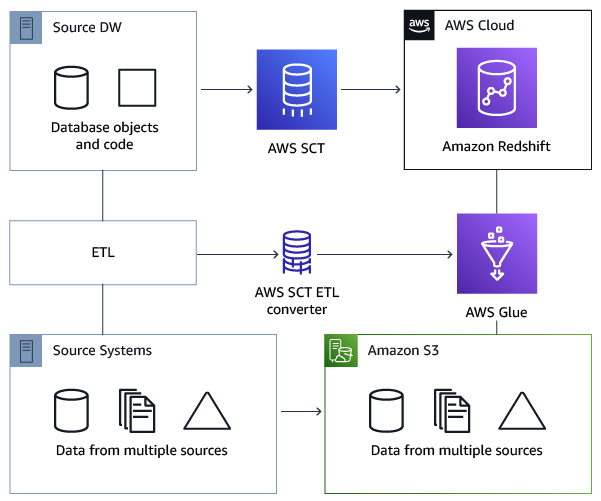
Requisitos previos
Antes de comenzar, haga lo siguiente:
-
Migre las bases de datos de origen que desee migrar a AWS.
-
Migre los almacenes de datos de destino a AWS.
-
Recopile una lista de todo el código involucrado en su proceso de ETL.
-
Recopile una lista de toda la información de conexión necesaria para cada base de datos.
Además, AWS Glue necesita permisos para acceder a otros AWS recursos en su nombre. Los permisos se proporcionan mediante AWS Identity and Access Management (IAM). Asegúrese de haber creado una política de IAM para. AWS GluePara obtener más información, consulte Crear una política de IAM para el servicio AWS Glueservice en la Guía para desarrolladores.AWS Glue
Comprensión del catálogo de datos AWS Glue
Como parte del proceso de conversión, AWS Glue carga información sobre las bases de datos de origen y destino. Además, organiza esta información en categorías, en una estructura que se denomina árbol. La estructura incluye lo siguiente:
-
Conexiones: parámetros de conexión
-
Rastreadores: una lista de rastreadores, un rastreador para cada esquema
-
Bases de datos: contenedores que contienen tablas
-
Tablas: definiciones de metadatos que representan los datos de las tablas
-
Trabajos de ETL: lógica empresarial que realiza el trabajo de ETL
-
Activadores: lógica que controla cuándo se ejecuta un trabajo de ETL AWS Glue (ya sea a petición, según lo programado o activado por eventos del trabajo)
AWS Glue Data Catalog es un índice para las métricas de tiempo de ejecución, esquema y ubicación de sus datos. Cuando trabaja con AWS Glue y AWS SCT, el catálogo de AWS Glue datos contiene referencias a los datos que se utilizan como fuentes y destinos de sus trabajos de ETL AWS Glue. Para crear su almacenamiento de datos, catalogue estos datos.
Puede usar la información del Catálogo de datos para crear y monitorizar sus trabajos de ETL. Normalmente, deberá ejecutar un rastreador para realizar un inventario de los datos incluidos en sus almacenes de datos, pero existen otras formas de añadir tablas de metadatos en el Catálogo de datos.
Al definir una tabla en su Data Catalog, puede añadirla a una base de datos. Se utiliza una base de datos para organizar las tablas AWS Glue.
Limitaciones a la hora de convertir utilizando AWS SCT AWS Glue
Las siguientes limitaciones se aplican al convertir utilizando AWS SCT con AWS Glue.
| Resource | Límite predeterminado |
| Número de bases de datos para cada cuenta | 10 000 |
| Número de tablas para cada base de datos | 100 000 |
| Número de particiones para cada tabla | 1 000 000 |
| Número de versiones de tabla para cada tabla | 100 000 |
| Número de tablas para cada cuenta | 1 000 000 |
| Número de particiones para cada cuenta | 10 000 000 |
| Número de versiones de tabla para cada cuenta | 1 000 000 |
| Número de conexiones para cada cuenta | 1 000 |
| Número de rastreadores para cada cuenta | 25 |
| Número de trabajos para cada cuenta | 25 |
| Número de disparadores para cada cuenta | 25 |
| Número de ejecuciones de trabajo simultáneas para cada cuenta | 30 |
| Número de ejecuciones de trabajo simultáneas para cada trabajo | 3 |
| Número de trabajos para cada disparador | 10 |
| Número de puntos de enlace de desarrollo para cada cuenta | 5 |
| Número máximo de unidades de procesamiento de datos (DPUs) utilizadas por un terminal de desarrollo a la vez | 5 |
| Cantidad máxima DPUs utilizada por un rol a la vez | 100 |
| Longitud del nombre de la base de datos |
Sin límite Para que sea compatible con otros almacenes de metadatos, como Apache Hive, el nombre se incorpora en minúsculas. Si tiene previsto obtener acceso a la base de datos desde Amazon Athena, proporcione un nombre únicamente con caracteres alfanuméricos y guiones bajos. |
| Longitud del nombre de la conexión | Sin límite |
| Longitud del nombre del rastreador | Sin límite |
Paso 1: Crear un nuevo proyecto de
Para crear un proyecto nuevo, siga estos pasos generales:
-
Crea un nuevo proyecto en AWS SCT. Para obtener más información, consulte Iniciar y gestionar proyectos en AWS SCT.
-
Agregue sus bases de datos de origen y destino al proyecto. Para obtener más información, consulte Añadir servidores al proyecto en AWS SCT.
Asegúrese de haber elegido Usar AWS Glue en la configuración de conexión a la base de datos de destino. Para ello, seleccione la pestaña AWS Glue. En Copiar desde AWS perfil, elija el perfil que desee usar. El perfil debe rellenar automáticamente la clave de AWS acceso, la clave secreta y la carpeta de bucket de Amazon S3. Si no lo hace, indique dicha información. Tras seleccionar Aceptar, AWS Glue analiza los objetos y carga los metadatos en el catálogo AWS Glue de datos.
Según la configuración de seguridad, es posible que aparezca un mensaje de advertencia que indique que su cuenta no tiene privilegios suficientes para algunos de los esquemas del servidor. Si tiene acceso a los esquemas que está utilizando, puede ignorar este mensaje.
-
Para finalizar la preparación de la importación de su ETL, establezca conexiones con sus bases de datos de origen y de destino. Para ello, elija la base de datos en el árbol de metadatos de origen o destino y, a continuación, seleccione Conectar al servidor.
AWS Glue crea una base de datos en el servidor de base de datos de origen y otra en el servidor de base de datos de destino para facilitar la conversión a ETL. La base de datos del servidor de destino contiene el catálogo AWS Glue de datos. Para encontrar objetos específicos, utilice el botón de búsqueda en los paneles de origen o destino.
Para ver cómo se convierte un objeto específico, busque un elemento que desee convertir y seleccione Convertir esquema desde el menú contextual (clic secundario). AWS SCT transforma este objeto seleccionado en un script.
Puede revisar el script convertido desde la carpeta Scripts del panel derecho. Actualmente, el script es un objeto virtual, que solo está disponible como parte de su AWS SCT proyecto.
Para crear un AWS Glue trabajo con el script convertido, cárguelo en Amazon S3. Para cargar el script a Amazon S3, selecciónelo y, a continuación, elija Guardar en S3 en el menú contextual (clic secundario).
Paso 2: Cree un AWS Glue trabajo
Tras guardar el script en Amazon S3, puede seleccionarlo y, a continuación, elegir Configure AWS Glue Job para abrir el asistente y configurar el AWS Glue trabajo. El asistente facilita esta configuración:
-
La primera pestaña del asistente, Diseñar flujo de datos, le permite elegir una estrategia de ejecución y la lista de scripts que desea incluir en este trabajo. Puede elegir los parámetros de cada script. También puede reorganizar los scripts de manera que se ejecuten en el orden correcto.
-
En la segunda pestaña, puede asignar un nombre al trabajo y configurar directamente las opciones para AWS Glue. En esta pantalla puede configurar las siguientes opciones:
-
AWS Identity and Access Management Función (IAM)
-
Nombres de archivos de script y rutas de archivo
-
Cifre el script usando cifrado del lado del servidor con claves administradas por Amazon S3 (SSE-S3)
-
Directorio temporal
-
Ruta de la biblioteca Python generada
-
Ruta de la biblioteca Python del usuario
-
Ruta de los archivos .jar dependientes
-
Ruta de archivos a la que se hace referencia
-
Simultáneo DPUs para cada ejecución de trabajo
-
Simultaneidad máxima
-
Tiempo de espera del trabajo (en minutos)
-
Umbral de notificación de retraso (en minutos)
-
Número de reintentos
-
Configuración de seguridad
-
Cifrado en el servidor
-
-
En el tercer paso, o pestaña, elija la conexión configurada con el punto de enlace de destino.
Cuando termine de configurar el trabajo, aparecerá debajo de los trabajos de ETL en el catálogo de AWS Glue datos. Si elige el trabajo, se mostrará la configuración para que pueda revisarla o editarla. Para crear un nuevo trabajo en AWS Glue, elija Crear AWS Glue trabajo en el menú contextual (clic con el botón derecho) del trabajo. Al hacerlo se aplica la definición de esquema. Para actualizar la visualización, elija Actualizar desde la base de datos en el menú contextual (clic secundario).
En este punto, puede ver su trabajo en la AWS Glue consola. Para ello, inicie sesión en Consola de administración de AWS y abra la AWS Glue consola en https://console.aws.amazon.com/glue/
Puede probar el nuevo trabajo para asegurarse de que funciona correctamente. Compruebe los datos de la tabla de origen y, a continuación, verifique que la tabla de destino esté vacía. Ejecute el trabajo y vuelva a realizar la comprobación. Puede ver los registros de errores desde la AWS Glue consola.
