Prácticas recomendadas para optimizar el rendimiento de S3 Express One Zone
Al crear aplicaciones que cargan y recuperan objetos de Amazon S3 Express One Zone, siga las directrices de nuestras prácticas recomendadas para optimizar el rendimiento. Para usar la clase de almacenamiento S3 Express One Zone, debe crear un bucket de directorio de S3. La clase de almacenamiento S3 Express One Zone no se admite para su uso con los buckets de uso general de S3.
Para ver las directrices de rendimiento para el resto de clases de almacenamiento de Amazon S3 y los buckets de uso general de S3, consulte Prácticas recomendadas para patrones de diseño: optimizar el rendimiento de Amazon S3.
Para obtener un rendimiento y una escalabilidad óptimos con la clase de almacenamiento S3 Express One Zone y los buckets de directorio en cargas de trabajo a gran escala, es importante comprender cómo funcionan los buckets de directorio de forma diferente a los buckets de uso general. A continuación, le ofrecemos las prácticas recomendadas para alinear las aplicaciones con la forma en que funcionan los buckets de directorio.
Cómo funcionan los buckets de directorio
La clase de almacenamiento Amazon S3 Express One Zone puede admitir cargas de trabajo con hasta 2 000 000 de transacciones GET y hasta 200 000 transacciones PUT por segundo (TPS) por bucket de directorio. Con S3 Express One Zone, los datos se almacenan en buckets de directorio de S3 en zonas de disponibilidad. Los objetos en los buckets de directorio son accesibles en un espacio de nombres jerárquico, similar a un sistema de archivos y a diferencia de los buckets de uso general de S3 que tienen un espacio de nombres plano. A diferencia de los buckets de uso general, los buckets de directorio organizan las claves jerárquicamente en directorios en lugar de prefijos. Un prefijo es una cadena de caracteres al principio del nombre de la clave de objeto. Puede utilizar prefijos para organizar los datos y administrar una arquitectura plana de almacenamiento de objetos en buckets de uso general. Para obtener más información, consulte Organizar objetos con prefijos.
En los buckets de directorio, los objetos se organizan en un espacio de nombres jerárquico mediante la barra diagonal (/) como único delimitador admitido. Cuando carga un objeto con una clave como dir1/dir2/file1.txt, Amazon S3 crea y administra automáticamente los directorios dir1/ y dir2/. Los directorios se crean durante las operaciones PutObject o CreateMultiPartUpload y se eliminan automáticamente cuando quedan vacíos tras las operaciones DeleteObject o AbortMultiPartUpload. No existe un límite máximo en el número de objetos y subdirectorios de un directorio.
Los directorios que se crean cuando se cargan objetos en los buckets de directorio pueden escalarse instantáneamente para reducir la posibilidad de errores HTTP 503 (Slow Down). Este escalado automático permite a sus aplicaciones paralelizar las solicitudes de lectura y escritura dentro de los directorios y entre ellos, según sea necesario. Para S3 Express One Zone, los directorios individuales están diseñados para admitir la tasa máxima de solicitudes de un bucket de directorio. No es necesario aleatorizar los prefijos de clave para lograr un rendimiento óptimo, ya que el sistema distribuye automáticamente los objetos para lograr una distribución uniforme de la carga, pero, como resultado, las claves no se almacenan lexicográficamente en los buckets de directorio. Esto contrasta con los buckets de uso general de S3, en los que las claves que están lexicográficamente más cerca tienen más probabilidades de estar ubicadas en el mismo servidor.
Para obtener más información sobre ejemplos de operaciones de bucket de directorio e interacciones de directorio, consulte Ejemplos de funcionamiento del bucket de directorio y de interacciones con el directorio.
Prácticas recomendadas
Siga las prácticas recomendadas para optimizar el rendimiento del bucket de directorio y contribuir a que las cargas de trabajo escalen con el tiempo.
Uso de directorios que contengan muchas entradas (objetos o subdirectorios)
Los buckets de directorio ofrecen un alto rendimiento de forma predeterminada para todas las cargas de trabajo. Para obtener una optimización aún mayor del rendimiento con determinadas operaciones, consolidar más entradas (que sean objetos o subdirectorios) en directorios dará lugar a una menor latencia y a una mayor tasa de solicitudes:
Las operaciones de API de mutación, como
PutObject,DeleteObject,CreateMultiPartUploadyAbortMultiPartUpload, alcanzan un rendimiento óptimo cuando se implementan con menos directorios, más densos, que contengan miles de entradas, en lugar de hacerlo con un gran número de directorios más pequeños.Las operaciones
ListObjectsV2tienen mejor rendimiento cuando hay que recorrer menos directorios para rellenar una página de resultados.
No usar entropía en los prefijos
En las operaciones de Amazon S3, la entropía se refiere a la asignación al azar de la denominación de los prefijos que ayuda a distribuir las cargas de trabajo de manera uniforme entre las particiones de almacenamiento. No obstante, dado que los buckets de directorio administran internamente la distribución de la carga, no se recomienda utilizar entropía en los prefijos para obtener el mejor rendimiento. Esto se debe a que, en el caso de los buckets de directorio, la entropía puede hacer que las solicitudes sean más lentas al no reutilizar los directorios que ya se han creado.
Un patrón clave como $HASH/directory/object podría acabar creando muchos directorios intermedios. En el siguiente ejemplo, todos los valores de job-1 son directorios diferentes ya que los elementos principales son diferentes. Los directorios serán dispersos y las solicitudes de mutación y enumeración serán más lentas. En este ejemplo hay 12 directorios intermedios que tienen todos una única entrada.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
En cambio, para mejorar el rendimiento, podemos eliminar el componente $HASH y permitir que job-1 se convierta en un único directorio, lo que mejora la densidad de un directorio. En el siguiente ejemplo, el directorio intermedio único que tiene seis entradas puede dar lugar a un mejor rendimiento, en comparación con el ejemplo anterior.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
Esta ventaja de rendimiento se produce porque, cuando se crea inicialmente una clave de objeto y el nombre de clave incluye un directorio, el directorio se crea automáticamente para el objeto. Las cargas de objetos posteriores a ese mismo directorio no requieren que se cree el directorio, lo que reduce la latencia de las cargas de objetos a los directorios existentes.
Utilice un separador distinto del delimitador / para separar partes de la clave si no necesita la capacidad de agrupar lógicamente objetos durante las llamadas a ListObjectsV2
Dado que el delimitador / recibe un tratamiento especial para los buckets de directorio, se debe utilizar con intención. Aunque los buckets de directorio no ordenan los objetos lexicográficamente, los objetos dentro de un directorio se siguen agrupando en las salidas de ListObjectsV2. Si no necesita esta funcionalidad, puede reemplazar / por otro carácter como separador a fin de no provocar la creación de directorios intermedios.
Por ejemplo, suponga que las siguientes claves están en un patrón de prefijo YYYY/MM/DD/HH/
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
Si no tiene la necesidad de agrupar objetos por hora o día en los resultados de ListObjectsV2, pero necesita agrupar objetos por mes, el siguiente patrón de claves de YYYY/MM/DD-HH- conducirá a un número significativamente menor de directorios y a un mejor rendimiento de la operación ListObjectsV2.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
Uso de operaciones de listas delimitadas siempre que sea posible
Una solicitud ListObjectsV2 sin delimiter realiza un recorrido recursivo en profundidad de todos los directorios. Una solicitud ListObjectsV2 con delimiter recupera solo las entradas del directorio especificado por el parámetro prefix, lo que reduce la latencia de la solicitud y aumenta las claves agregadas por segundo. Para los buckets de directorio, utilice operaciones de listas delimitadas siempre que sea posible. Las listas delimitadas hacen que los directorios se visiten menos veces, lo que se traduce en un mayor número de claves por segundo y una menor latencia de las solicitudes.
Por ejemplo, para los siguientes directorios y objetos del bucket de directorio:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
Para mejorar el rendimiento de ListObjectsV2, utilice una lista delimitada para enumerar los subdirectorios y objetos, si la lógica de la aplicación lo permite. Por ejemplo, puede ejecutar el siguiente comando para la operación de lista delimitada,
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
El resultado es la lista de subdirectorios.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
Para enumerar cada subdirectorio con mejor rendimiento, puede ejecutar un comando como el siguiente ejemplo:
Comando:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
Salida:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
Coubique el almacenamiento S3 Express One Zone con sus recursos informáticos de
Con S3 Express One Zone, cada bucket de directorio se ubica en una única zona de disponibilidad que seleccione al crear el bucket. Para empezar, puede crear un nuevo bucket de directorio en una zona de disponibilidad local para sus cargas de trabajo o recursos informáticos. A continuación, puede iniciar de inmediato lecturas y escrituras de muy baja latencia. Los buckets de directorio son un tipo de buckets de S3 en los que puede elegir la zona de disponibilidad en una Región de AWS para reducir la latencia entre computación y almacenamiento.
Si accede a los buckets de directorio de todas las zonas de disponibilidad, es posible que experimente un aumento de la latencia. Para optimizar el rendimiento, le recomendamos que acceda a un bucket de directorio desde instancias de Amazon Elastic Container Service, Amazon Elastic Kubernetes Service y Amazon Elastic Compute Cloud que estén ubicadas en la misma zona de disponibilidad siempre que sea posible.
Uso de conexiones simultáneas para lograr un alto rendimiento con objetos de más de 1 MB
Puede lograr el mejor rendimiento emitiendo varias solicitudes simultáneas a los buckets de directorio para distribuir las solicitudes en conexiones independientes y maximizar así el ancho de banda accesible. Al igual que los buckets de uso general, S3 Express One Zone no tiene límites en cuanto al número de conexiones que se realizan en el bucket de directorio. Los directorios individuales pueden escalar el rendimiento de forma horizontal y automática cuando se realizan grandes cantidades de escrituras simultáneas en el mismo directorio.
Las conexiones TCP individuales a los buckets de directorio tienen un límite superior fijo para el número de bytes que se pueden cargar o descargar por segundo. Cuando los objetos aumentan de tamaño, los tiempos de solicitud pasan a estar dominados por el streaming de bytes en lugar del procesamiento de transacciones. Si utiliza varias conexiones para paralelizar la carga o descarga de objetos de mayor tamaño, podrá reducir la latencia de extremo a extremo. Si utiliza el SDK de Java 2.x, debería considerar la posibilidad de utilizar el Administrador de transferencias de S3, que aprovechará las mejoras de rendimiento, como las operaciones de la API de carga multiparte y las recuperaciones por intervalo de bytes para acceder a los datos en paralelo.
Uso de puntos de conexión de VPC de puerta de enlace
Los puntos de conexión de puerta de enlace proporcionan una conexión directa desde la VPC a los buckets de directorio, sin necesidad de una puerta de enlace de Internet ni un dispositivo NAT para la VPC. Para reducir el tiempo que los paquetes pasan en la red, debe configurar la VPC con un punto de conexión de VPC de puerta de enlace para los buckets de directorio. Para obtener más información, consulte Redes para buckets de directorio.
Uso de la autenticación de sesión y reutilización de los tokens de sesión mientras sean válidos
Los buckets de directorio proporcionan un mecanismo de autenticación de token de sesión para reducir la latencia en las operaciones de API sensibles al rendimiento. Puede realizar una única llamada a CreateSession para obtener un token de sesión que será válido para todas las solicitudes en los 5 minutos siguientes. Para obtener la menor latencia en las llamadas a la API, asegúrese de adquirir un token de sesión y reutilizarlo durante toda la vida útil antes de actualizarlo.
Si utiliza los SDK de AWS, estos se encargan de actualizar el token de sesión automáticamente para evitar interrupciones del servicio cuando caduca una sesión. Le recomendamos que utilice los AWS SDK para iniciar y administrar las solicitudes a la operación de la API CreateSession.
Para obtener más información acerca de CreateSession, consulte Autorización de operaciones de la API de puntos de conexión zonales con CreateSession.
Uso de un cliente basado en CRT
El tiempo de ejecución común (CRT) de AWS es un conjunto de bibliotecas modulares, de alto rendimiento y eficientes escritas en C y pensadas para actuar como base de los AWS SDK. El CRT proporciona un mayor rendimiento, una mejor administración de las conexiones y tiempos de inicio más rápidos. El CRT está disponible en todos los AWS SDK excepto en Go.
Para obtener más información sobre cómo configurar el CRT para el SDK que utilice, consulte Bibliotecas de tiempo de ejecución común (CRT) de AWS, Aceleración del rendimiento de Amazon S3 con el tiempo de ejecución común de AWS
Uso de la versión más reciente de los AWS SDK
Los SDK de AWS ofrecen compatibilidad integrada con muchas de las directrices recomendadas para optimizar el rendimiento de Amazon S3. Los SDK ofrecen una API más sencilla para aprovechar Amazon S3 desde dentro de una aplicación y se actualizan periódicamente para seguir las últimas prácticas recomendadas. Por ejemplo, los SDK reintentan automáticamente las solicitudes tras errores HTTP 503 y gestionan las respuestas de conexiones lentas.
Si utiliza el SDK de Java 2.x, debería considerar la posibilidad de utilizar el Administrador de transferencias de S3, que escala horizontalmente las conexiones de forma automática para obtener miles de solicitudes por segundo mediante solicitudes de intervalo de bytes cuando sea apropiado. Las solicitudes de rango de bytes pueden mejorar el rendimiento porque puede utilizar conexiones simultáneas a S3 para obtener diferentes intervalos de bytes dentro del mismo objeto. Esto le ayuda a lograr un rendimiento total mayor frente a una sola solicitud de todo el objeto. Por lo tanto, es importante usar la versión más reciente de los AWS SDK para obtener las características de optimización de rendimiento más recientes.
Soluciones de problemas de rendimiento
¿Establece solicitudes de reintentos para aplicaciones sensibles a la latencia?
S3 Express One Zone está diseñado específicamente para ofrecer niveles uniformes de alto rendimiento sin realizar ajustes adicionales. Sin embargo, establecer valores de tiempo de espera y reintentos agresivos puede ayudar aún más a lograr una latencia y un rendimiento uniformes. Los SDK de AWS cuentan con un tiempo de espera configurable y valores de reintento que puede ajustar a las tolerancias de su aplicación específica.
¿Utiliza bibliotecas de tiempo de ejecución común (CRT) de AWS y tipos de instancia de Amazon EC2 óptimos?
Las aplicaciones que realizan un gran número de operaciones de lectura y escritura probablemente necesitan más memoria o capacidad de computación que las aplicaciones que no. Al lanzar sus instancias de Amazon Elastic Compute Cloud (Amazon EC2) para su carga de trabajo de rendimiento exigente, seleccione los tipos de instancia que tengan la cantidad de estos recursos que necesita su aplicación. El almacenamiento de alto rendimiento S3 Express One Zone se empareja de forma ideal con tipos de instancias más grandes y más nuevos, con una mayor cantidad de memoria del sistema y CPU y GPU más potentes que pueden aprovechar el almacenamiento de mayor rendimiento. También recomendamos utilizar las versiones más recientes de los SDK de AWS habilitados para CRT, que pueden acelerar mejor las solicitudes de lectura y escritura en paralelo.
¿Utiliza los AWS SDK para la autenticación basada en sesiones?
Con Amazon S3, también es posible optimizar el rendimiento cuando se utilizan solicitudes de API de REST de HTTP siguiendo las mismas prácticas recomendadas que forman parte de los SDK de AWS. Sin embargo, con el mecanismo de autorización y autenticación basado en sesiones que utiliza S3 Express One Zone, le recomendamos fehacientemente que utilice los SDK de AWS para administrar CreateSession y su token de sesión administrada. Los SDK de AWS crean y actualizan automáticamente los tokens en su nombre mediante la operación de la API CreateSession. El uso de CreateSession ahorra la latencia de ida y vuelta por solicitud al AWS Identity and Access Management (IAM) para autorizar cada solicitud.
Ejemplos de funcionamiento del bucket de directorio y de interacciones con el directorio
A continuación, se muestran tres ejemplos sobre el funcionamiento de los buckets de directorio.
Ejemplo 1: cómo interactúan las solicitudes PutObject de S3 a un bucket de directorio con directorios
-
Cuando se ejecuta la operación
PUT(<bucket>, "documents/reports/quarterly.txt")en un bucket vacío, se crea el directoriodocuments/dentro de la raíz del bucket, se crea el directorioreports/dentro dedocuments/y se crea el objetoquarterly.txtdentro dereports/. Para esta operación, se han creado dos directorios además del objeto.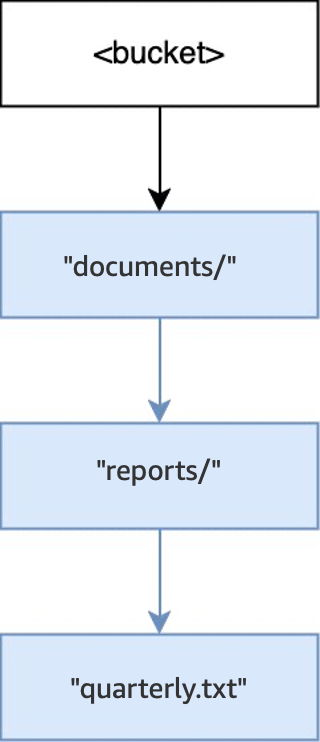
-
Después, cuando se ejecuta otra operación
PUT(<bucket>, "documents/logs/application.txt"), el directoriodocuments/ya existe, el directoriologs/dentro dedocuments/no existe y se crea, y el objetoapplication.txtdentro delogs/se crea. Para esta operación, solo se ha creado un directorio además del objeto.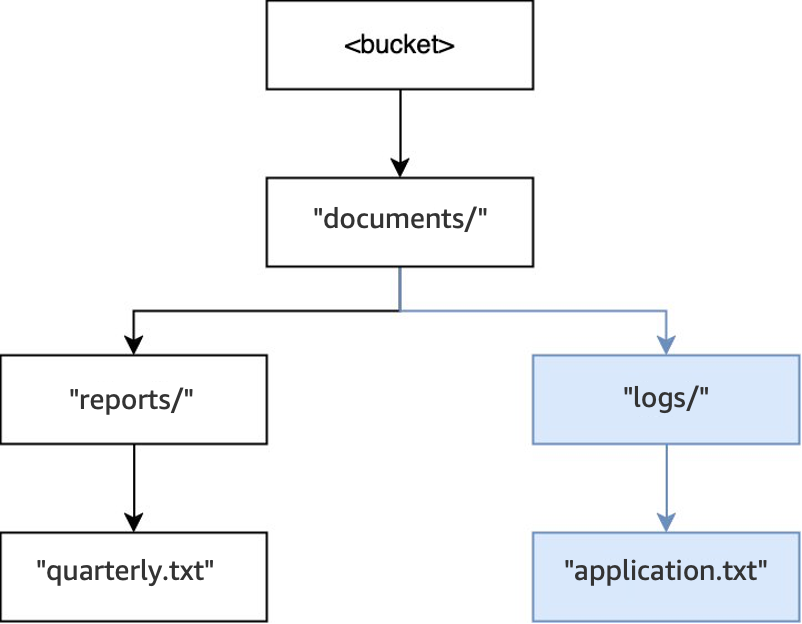
-
Por último, cuando se ejecuta una operación
PUT(<bucket>, "documents/readme.txt"), el directoriodocuments/dentro de la raíz ya existe y se crea el objetoreadme.txt. Para esta operación, no se crea ningún directorio.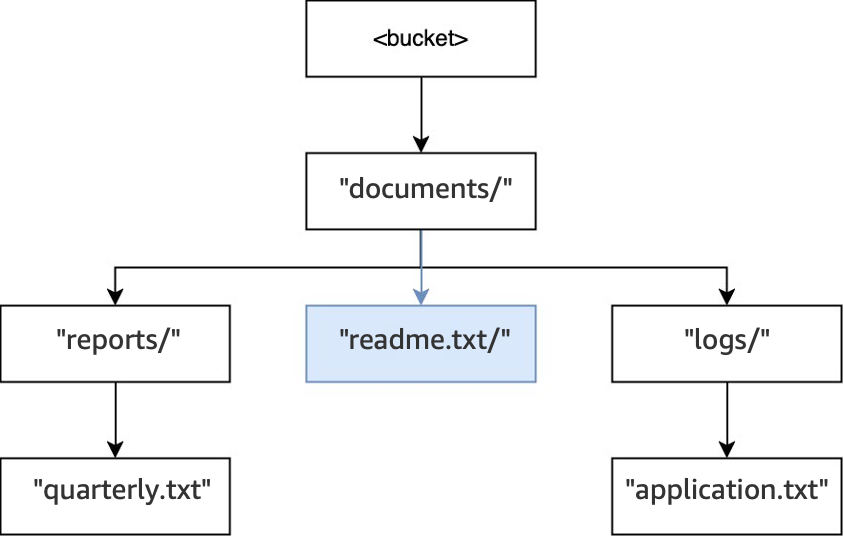
Ejemplo 2: cómo interactúan las solicitudes ListObjectsV2 de S3 a un bucket de directorio con directorios
Para las solicitudes ListObjectsV2 de S3 sin especificar un delimitador, se recorre un bucket en orden de profundidad. Los resultados se devuelven en un orden coherente. No obstante, aunque este orden sigue siendo el mismo entre solicitudes, el orden no es lexicográfico. Para el bucket y los directorios creados en el ejemplo anterior:
-
Cuando se ejecuta
LIST(<bucket>), se introduce el directoriodocuments/y comienza el recorrido. -
Se introduce el subdirectorio
logs/y comienza el recorrido. -
El objeto
application.txtse encuentra dentro delogs/. -
No existen más entradas dentro de
logs/. La operación de lista sale delogs/y vuelve a entrar endocuments/. -
Se sigue recorriendo el directorio
documents/y se encuentra el objetoreadme.txt. -
Se sigue recorriendo el directorio
documents/, se entra en el subdirectorioreports/y comienza el recorrido. -
El objeto
quarterly.txtse encuentra dentro dereports/. -
No existen más entradas dentro de
reports/. La lista sale dereports/y vuelve a entrar endocuments/. -
No existen más entradas en
documents/y la lista regresa.
En este ejemplo, logs/ se ordena antes que readme.txt y readme.txt se ordena antes que reports/.
Ejemplo 3: cómo interactúan las solicitudes DeleteObject de S3 a un bucket de directorio con directorios
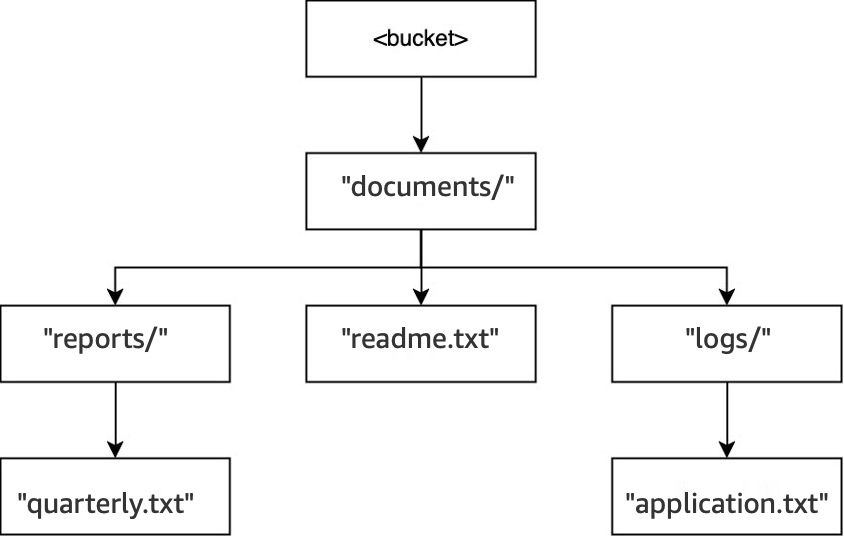
-
En ese mismo bucket, cuando se ejecuta la operación
DELETE(<bucket>, "documents/reports/quarterly.txt"), se elimina el objetoquarterly.txt, lo que deja vacío el directorioreports/y provoca que se elimine inmediatamente. El directoriodocuments/no está vacío porque tiene tanto el directoriologs/como el objetoreadme.txten el interior, por lo que no se elimina. Para esta operación, solo se han eliminado un objeto y un directorio.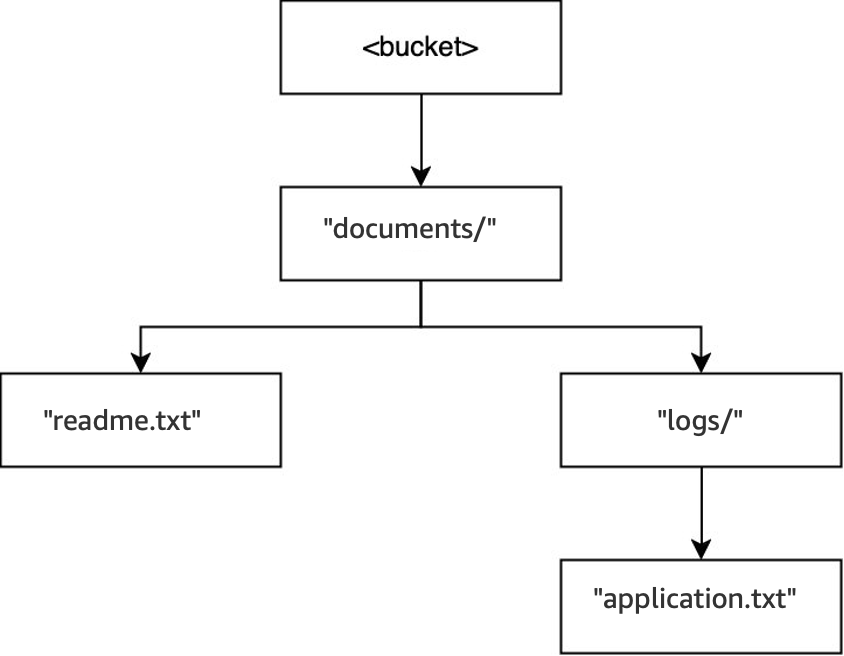
-
Cuando se ejecuta la operación
DELETE(<bucket>, "documents/readme.txt"), se elimina el objetoreadme.txt.documents/todavía no está vacío porque contiene el directoriologs/, por lo que no se elimina. Para esta operación, no se elimina ningún directorio y solo se elimina el objeto.
-
Por último, cuando se ejecuta la operación
DELETE(<bucket>, "documents/logs/application.txt"), se eliminaapplication.txt, lo que dejalogs/vacío y provoca que se elimine inmediatamente. A continuación,documents/se deja vacío y se provoca que también se elimine inmediatamente. Para esta operación, se eliminan dos directorios y un objeto. El bucket está ahora vacío.
