Integraciones sin ETL de Aurora
Una integración sin ETL de Aurora con Amazon Redshift y Amazon SageMaker AI permite realizar análisis y machine learning (ML) casi en tiempo real mediante datos de Aurora. Es una solución totalmente administrada que permite que los datos transaccionales estén disponibles en el destino de análisis después de escribirlos en un clúster de base de datos de Aurora. La extracción, transformación y carga (ETL) es un proceso en el que se combinan datos de numerosos orígenes en un gran almacenamiento de datos central.
La integración sin ETL hace que los datos de clúster de base de datos de Aurora estén disponibles en Amazon Redshift o un Amazon SageMaker AI Lakehouse prácticamente en tiempo real. Una vez que los datos están en el almacén de datos de destino o lago de datos, puede alimentar cargas de trabajo de análisis, ML e IA con las capacidades integradas, como el machine learning, las vistas materializadas, el uso compartido de datos, el acceso federado a varios almacenamientos de datos y lagos de datos, y las integraciones con Amazon SageMaker AI, Quick y otros Servicios de AWS.
Para crear una integración sin ETL, especifique un clúster de base de datos de Aurora como origen y un almacén de datos o almacén de lago compatible como destino. La integración replica los datos de la base de datos de origen en el almacén de datos de destino o almacén de lago.
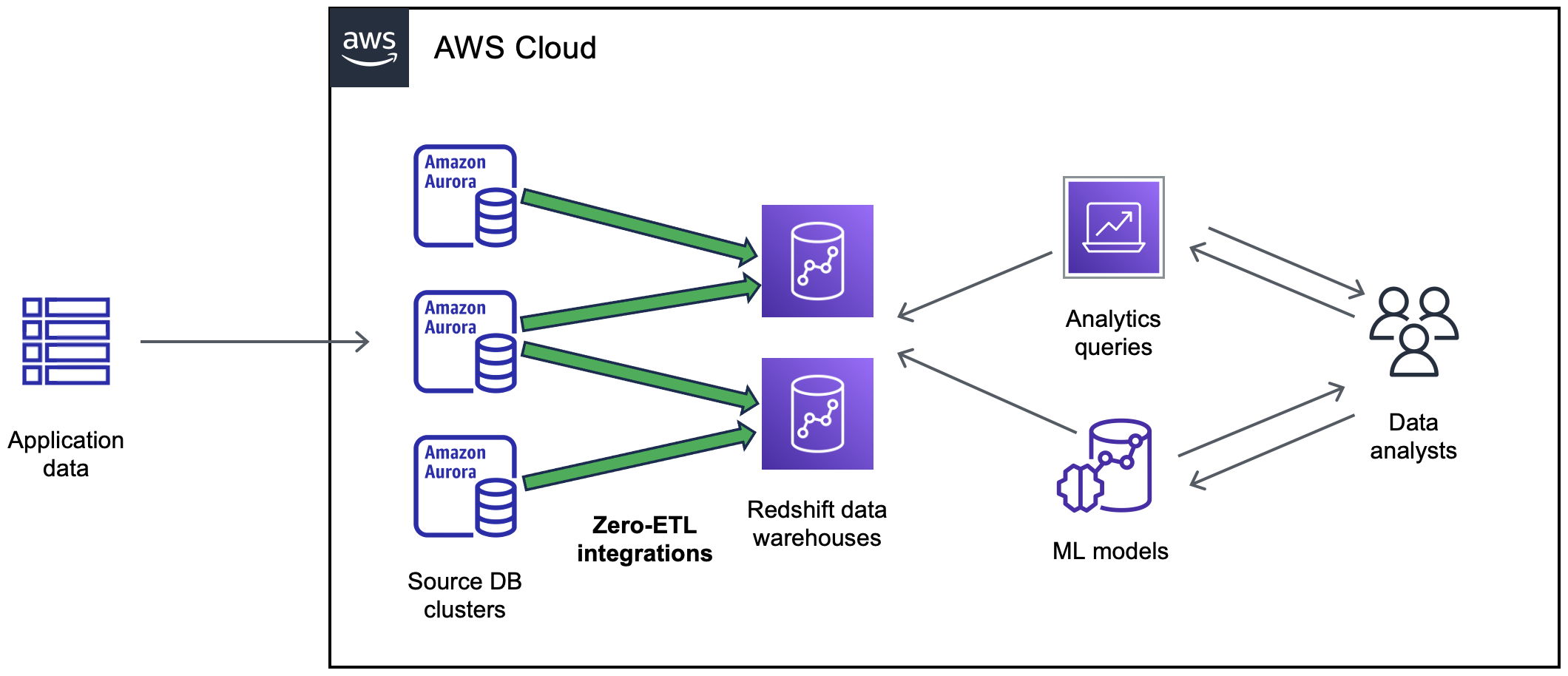
El siguiente diagrama ilustra esta funcionalidad para una integración sin ETL con Amazon Redshift:
En el siguiente diagrama se ilustra esta funcionalidad para la integración sin ETL con un Amazon SageMaker AI Lakehouse:
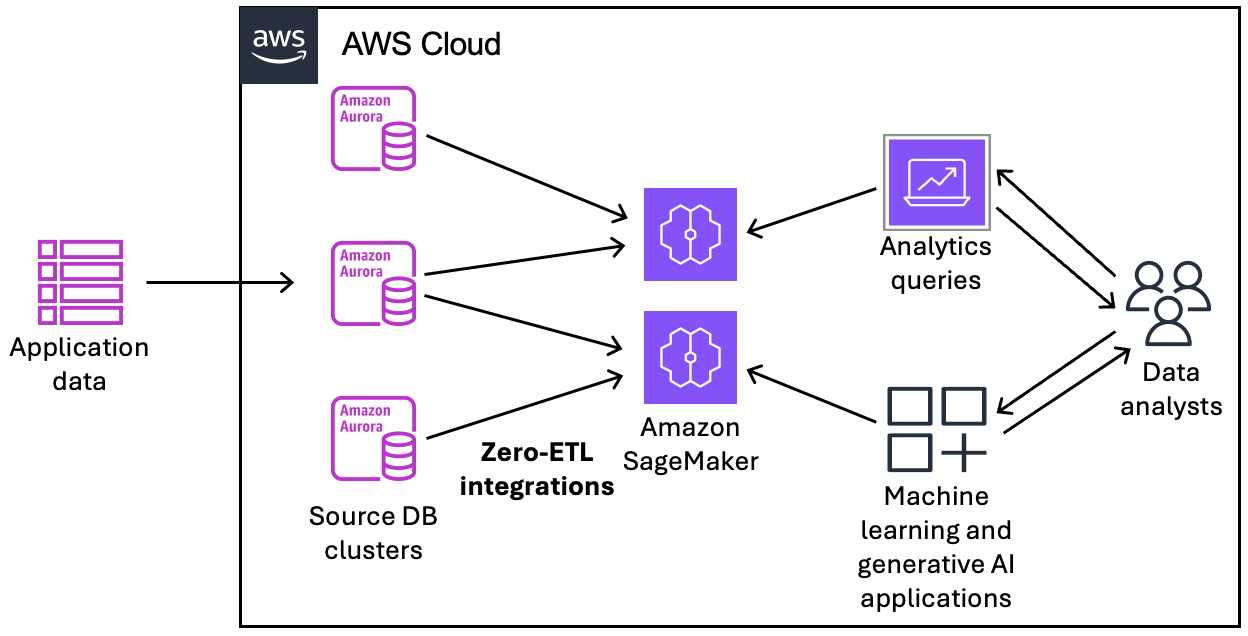
La integración supervisa el estado de la canalización de datos y se recupera de los problemas cuando es posible. Puede crear integraciones a partir de varios clústeres de base de datos de Aurora en un único almacén de datos o almacén de lago de destino, lo que le permite obtener información en varias aplicaciones.
Para obtener información sobre los precios de las integraciones sin ETL, consulte Precios de Amazon Aurora
Temas
Creación de integraciones sin ETL de Aurora con Amazon Redshift
Creación de integraciones sin ETL de Aurora con un Amazon SageMaker Lakehouse
Agregación de datos a un clúster de base de datos de Aurora de origen y realización de consultas
Visualización y supervisión de las integraciones sin ETL de Aurora
Ventajas
Las integraciones sin ETL de Aurora tienen los siguientes beneficios:
-
Le ayudan a obtener información holística a partir de numerosos orígenes de datos.
-
Eliminan la necesidad de crear y mantener canalizaciones de datos complejas que realicen operaciones de extracción, transformación y carga (ETL). Las integraciones sin ETL eliminan los inconvenientes derivados de la creación y administración de canalizaciones, ya que las aprovisionan y administran por usted.
-
Reducen la carga operativa y los costos para que pueda centrarse en mejorar sus aplicaciones.
-
Le permite aprovechar las capacidades de análisis y ML de destino para obtener información a partir de datos transaccionales y de otro tipo, a fin de responder de manera eficaz a eventos críticos y urgentes.
Conceptos clave
Cuando empiece a utilizar las integraciones sin ETL, tenga en cuenta los siguientes conceptos:
- Integración
-
Una canalización de datos totalmente administrada que replica automáticamente los datos y esquemas transaccionales de un clúster de base de datos de Aurora a un almacén de datos o catálogo.
- Clúster de base de datos de origen
-
El clúster de base de datos de Aurora desde donde se replican los datos. Puede especificar un clúster de base de datos que utilice instancias de base de datos aprovisionadas o instancias de base de datos de Aurora serverless como origen.
- Target
-
El almacén de datos o almacén de lago en el que se replican los datos. Hay dos tipos de almacenamientos de datos: un almacenamiento de datos de clústeres aprovisionados y un almacenamiento de datos sin servidor. Un almacenamiento de datos de clústeres aprovisionados es una colección de recursos de computación denominados nodos que están organizados en un grupo llamado clúster. Un almacenamiento de datos sin servidor se compone de un grupo de trabajo que almacena los recursos de computación y un espacio de nombres que aloja los objetos y usuarios de la base de datos. Ambos almacenes de datos ejecutan un motor de análisis y contienen una o más bases de datos.
Un almacén de lago de destino consta de catálogos, bases de datos, tablas y vistas. Para obtener más información sobre la arquitectura del almacén de lago, consulte SageMaker Lakehouse components en la Guía del usuario de Amazon SageMaker AI Unified Studio.
Múltiples clústeres de base de datos de origen pueden escribir en el mismo destino.
Para obtener más información, consulte Arquitectura del sistema de almacenamiento de datos en la Guía del desarrollador de Amazon Redshift.
Limitaciones
Las siguientes limitaciones se aplican a las integración sin ETL de Aurora.
Temas
Limitaciones generales
-
El clúster de base de datos de origen debe estar en la misma región que el destino.
-
No puede cambiar el nombre de un clúster de base de datos ni ninguna de sus instancias si ya tiene integraciones.
-
No se pueden crear varias integraciones entre las mismas bases de datos de origen y de destino.
-
No puede eliminar un clúster de base de datos que ya tenga integraciones. Primero debes eliminar todas las integraciones asociadas.
-
Si detiene el clúster de base de datos de origen, es posible que las últimas transacciones no se repliquen en el destino hasta que reanude el clúster.
-
Si el clúster es el origen de una implementación azul/verde, los entornos azul y verde no pueden tener integraciones sin ETL existentes durante la transición. Primero debe eliminar la integración, realizar la transición y, a continuación, volver a crear la integración.
-
Un clúster de base de datos debe contener al menos una instancia de base de datos para ser el origen de una integración.
-
No puede crear una integración para un clúster de base de datos de origen que sea un clon entre cuentas, como los que se comparten mediante AWS Resource Access Manager (AWS RAM).
-
Si el clúster de origen es el clúster de base de datos primario de una base de datos global de Aurora y se cambia por error a uno de sus clústeres secundarios, la integración queda inactiva. Debe eliminar y volver a crear la integración.
-
No puede crear una integración para una base de datos de origen en la que se esté creando otra integración de forma activa.
-
Cuando se crea una integración por primera vez, o cuando se vuelve a sincronizar una tabla, la transferencia de datos del origen al destino puede tardar entre 20 y 25 minutos o más, en función del tamaño de la base de datos de origen. Este retardo puede provocar un aumento del retardo en la réplica.
-
Algunos tipos de datos no son compatibles. Para obtener más información, consulte Diferencias de tipos de datos entre las bases de datos Aurora y Amazon Redshift.
-
Las tablas del sistema, las tablas temporales y las vistas no se replican en almacenes de destino.
-
Al ejecutar comandos DDL (por ejemplo,
ALTER TABLE) en una tabla de origen, se puede desencadenar una resincronización de la tabla, lo que hace que la tabla no esté disponible para realizar consultas mientras se resincroniza. Para obtener más información, consulte Una o más de mis tablas de Amazon Redshift requieren una resincronización.
Limitaciones de Aurora MySQL
-
El clúster de base de datos de origen debe ejecutar una versión compatible de Aurora MySQL. Para obtener una lista de las versiones compatibles, consulte Regiones y motores de base de datos de Aurora admitidos para integraciones sin ETL.
-
Las integraciones sin ETL se basan en el registro binario de MySQL (binlog) para capturar los cambios en los datos en curso. No utilice el filtrado de datos basado en binlog, ya que puede provocar incoherencias entre los datos de las bases de datos de origen y de destino.
-
Las integraciones sin ETL solo son compatibles con bases de datos configuradas para usar el motor de almacenamiento de InnoDB.
-
No se admiten referencias de clave externas con actualizaciones de tablas predefinidas. En concreto, las reglas
ON DELETEyON UPDATEno son compatibles con las accionesCASCADE,SET NULLySET DEFAULT. Si se intenta crear o actualizar una tabla con este tipo de referencias a otra tabla, se producirá un error en la tabla. -
Las transacciones XA
realizadas en el clúster de base de datos de origen hacen que la integración entre en un estado de Syncing.
Limitaciones de Aurora PostgreSQL
-
El clúster de base de datos de origen debe ejecutar una versión compatible de Aurora PostgreSQL. Para obtener una lista de las versiones compatibles, consulte Regiones y motores de base de datos de Aurora admitidos para integraciones sin ETL.
-
Si selecciona un clúster de base de datos de origen de Aurora PostgreSQL, debe especificar al menos un patrón de filtro de datos. Como mínimo, el patrón debe incluir una única base de datos (
database-name.*.* -
Todas las bases de datos creadas en el clúster de base de datos de Aurora PostgreSQL de origen deben utilizar la codificación UTF-8.
-
Al utilizar la partición declarativa, las particiones de la tabla se replicarán en Amazon Redshift. Sin embargo, la tabla particionada en sí no se replica en Amazon Redshift.
-
No se admiten las transacciones bifásicas
. -
Si elimina todas las instancias de base de datos de un clúster de base de datos que es el origen de una integración y, a continuación, vuelve a agregar una instancia de base de datos, la replicación se interrumpe entre los clústeres de origen y de destino.
-
El clúster de base de datos de origen no puede utilizar la base de datos ilimitada de Aurora.
-
Las claves principales son obligatorias en todas las tablas presentes en el filtro de datos. Todas las tablas que no tengan una clave principal pasarán al estado erróneo.
Limitaciones de Amazon Redshift
Para obtener una lista de limitaciones de Amazon Redshift relacionadas con las integraciones sin ETL, consulte Consideraciones al utilizar las integraciones sin ETL con Amazon Redshift de la Guía de administración de Amazon Redshift.
Amazon SageMaker AILimitaciones de Lakehouse
La siguiente es una limitación para las integraciones sin ETL de Amazon SageMaker AI Lakehouse.
-
Los nombres de catálogo están limitados a 19 caracteres de longitud.
Cuotas
La cuenta tiene las siguientes cuotas relacionadas con las integraciones sin ETL de Aurora. Cada una de las cuotas se aplica a una sola región, a no ser que se especifique otra cosa.
| Nombre | Predeterminado | Descripción |
|---|---|---|
| Integraciones | 100 | El número total de integraciones dentro de una Cuenta de AWS. |
| Integraciones por destino | 50 | El número de integraciones que envían datos a un único almacén de datos o almacén de lago de destino. |
| Integraciones por clúster de origen | 5 | La cantidad de integraciones que envían datos desde un solo clúster de base de datos de origen. |
Además, el almacén de destino establece algunos límites en la cantidad de tablas permitidas en cada instancia de base de datos o nodo de clúster. Para obtener más información sobre cuotas y límites de Amazon Redshift, consulte Cuotas y límites de Amazon Redshift en la Guía de administración de Amazon Redshift.
Regiones admitidas
Las integraciones sin ETL de Aurora están disponibles en un subconjunto de Regiones de AWS. Para obtener una lista de las regiones admitidas, consulte Regiones y motores de base de datos de Aurora admitidos para integraciones sin ETL.
