Adición de un grupo de particiones de base de datos a un clúster de base de datos de Base de datos ilimitada de Aurora PostgreSQL existente
Puede crear un grupo de particiones de base de datos en un clúster de base de datos existente, por ejemplo, si está restaurando un clúster de base de datos o si ha eliminado el grupo de particiones de base de datos.
Para obtener más información sobre los requisitos del clúster de base de datos principal y del grupo de particiones de base de datos, consulte Requisitos y consideraciones sobre Base de datos ilimitada de Aurora PostgreSQL.
nota
Solo puede tener un grupo de particiones de base de datos por clúster.
El clúster de base de datos de Base de datos ilimitada debe tener el estado available para poder crear un grupo de particiones de base de datos.
Puede usar la Consola de administración de AWS para añadir un grupo de particiones de base de datos a un clúster de base de datos existente.
Adición de un grupo de particiones de base de datos
Inicie sesión en la Consola de administración de AWS y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Acceda a la página Databases (Bases de datos).
-
Seleccione el clúster de base de datos de Base de datos ilimitada al que desea agregar un grupo de particiones de base de datos.
-
En Acciones, elija Agregar un grupo de particiones de base de datos.
-
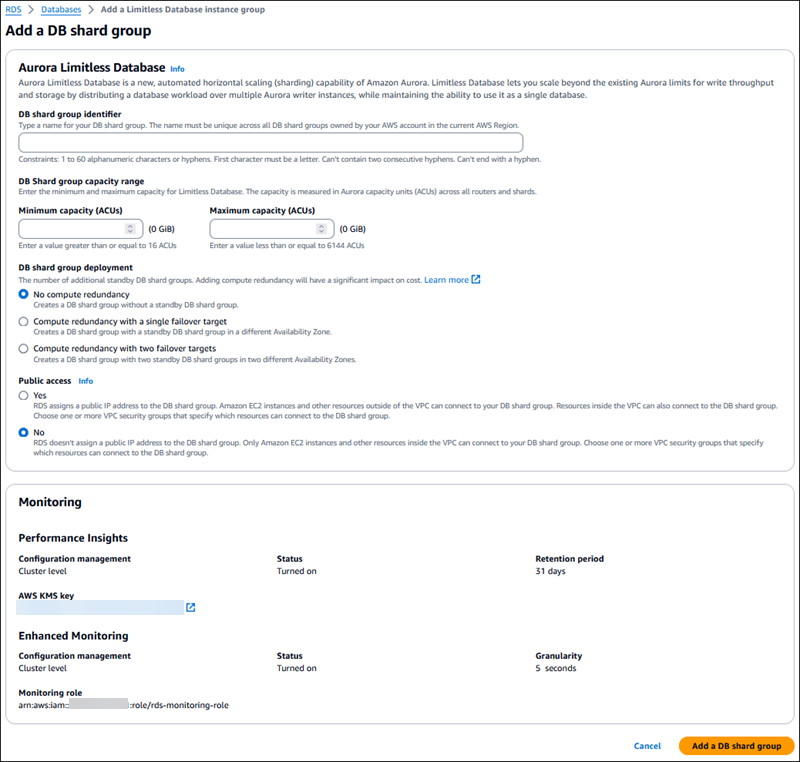
Introduzca un Identificador de grupo de particiones de base de datos.
importante
Tras crear el grupo de particiones de base de datos, ya no podrá cambiar el identificador del clúster de base de datos ni el identificador del grupo de particiones de base de datos.
-
Introduzca la Capacidad mínima (ACU). Utilice un valor de al menos 16 ACU.
-
Introduzca la Capacidad máxima (ACU). Utilice un valor entre 16 y 6144 ACU.
Para obtener más información, consulte Correlación de la capacidad máxima del grupo de particiones de base de datos con la cantidad de enrutadores y particiones creada.
-
Para Implementación del grupo de partición de base de datos, elija si desea crear esperas para el grupo de particiones de base de datos:
-
Sin redundancia de computación: crea un grupo de particiones de base de datos sin esperas para cada partición. Este es el valor predeterminado.
-
Redundancia de computación con un solo destino de conmutación por error: crea un grupo de particiones de base de datos con una espera de computación en una zona de disponibilidad (AZ) diferente.
-
Redundancia de computación con dos destinos de conmutación por error: crea un grupo de particiones de base de datos con dos esperas de computación en dos zonas de disponibilidad diferentes.
-
-
Elija si desea que el grupo de particiones de base de datos sea de acceso público.
nota
No puede modificar esta configuración después de crear el grupo de particiones de base de datos.
-
Elija Agregar un grupo de particiones de base de datos.
Utilice el comando create-db-shard-group de la AWS CLI para crear un grupo de particiones de base de datos.
Se requieren los siguientes parámetros:
-
--db-cluster-identifier: es el clúster de base de datos al que pertenece el grupo de particiones de base de datos. -
--db-shard-group-identifier: es el nombre del grupo de particiones de base de datos.El identificador del grupo de particiones de base de datos tiene las siguientes restricciones:
-
Debe ser único en la Cuenta de AWS y en la Región de AWS donde se ha creado.
-
Debe contener entre 1 y 63 letras, números o guiones.
-
El primer carácter debe ser una letra.
-
No puede terminar con un guion ni contener dos guiones consecutivos.
importante
Tras crear el grupo de particiones de base de datos, ya no podrá cambiar el identificador del clúster de base de datos ni el identificador del grupo de particiones de base de datos.
-
-
--max-acu: es la capacidad máxima del grupo de particiones de base de datos. Utilice un valor entre 16 y 6144 ACU.
Los siguientes parámetros son opcionales:
-
--compute-redundancy: indica si se deben crear esperas para el grupo de particiones de base de datos. Este parámetro puede tener uno de los siguientes valores:-
0: crea un grupo de particiones de base de datos sin esperas para cada partición. Este es el valor predeterminado. -
1: crea un grupo de particiones de base de datos con una espera de computación en una zona de disponibilidad (AZ) diferente. -
2: crea un grupo de particiones de base de datos con dos esperas de computación en dos AZ diferentes.
nota
Si establece la redundancia de computación en un valor distinto de cero, el número total de nodos se duplicará o triplicará. Esto generará un costo adicional.
-
-
--min-acu: es la capacidad mínima de su grupo de particiones de base de datos. Debe tener al menos 16 ACU, que es el valor predeterminado. -
--publicly-accessible|--no-publicly-accessible: indica si se deben asignar direcciones IP de acceso público al grupo de particiones de base de datos. El acceso al grupo de particiones de base de datos está controlado por los grupos de seguridad que utiliza el clúster.El valor predeterminado es
--no-publicly-accessible.nota
No puede modificar esta configuración después de crear el grupo de particiones de base de datos.
En el siguiente ejemplo, se crea un grupo de particiones de base de datos en un clúster de base de datos de Aurora PostgreSQL.
aws rds create-db-shard-group \ --db-cluster-identifiermy-db-cluster\ --db-shard-group-identifiermy-new-shard-group\ --max-acu1000
La salida es similar al siguiente ejemplo.
{ "Status": "CREATING", "Endpoint": "my-db-cluster.limitless-ckifpdyyyxxx.us-east-1.rds.amazonaws.com", "PubliclyAccessible": false, "DBClusterIdentifier": "my-db-cluster", "MaxACU": 1000.0, "DBShardGroupIdentifier": "my-new-shard-group", "DBShardGroupResourceId": "shardgroup-8986d309a93c4da1b1455add17abcdef", "ComputeRedundancy": 0 }
