Cómo añadir una política de escalado automático a un clúster de base de datos de Amazon Aurora
Puede agregar una política de escalado utilizando la Consola de administración de AWS, AWS CLI o la API de Auto Scaling de aplicaciones.
nota
Para ver un ejemplo que agrega una política de escalado mediante CloudFormation, consulte Declaración de una política de escalado para un clúster de base de datos de Aurora en la Guía del usuario de AWS CloudFormation.
Puede agregar una política de escalado a un clúster de base de datos de Aurora mediante la Consola de administración de AWS.
Para añadir una política de Auto Scaling a un clúster de base de datos Aurora
Inicie sesión en la Consola de administración de AWS y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En el panel de navegación, seleccione Databases (Bases de datos).
-
Seleccione el clúster de base de datos Aurora para el que desea añadir una política.
-
Seleccione la pestaña Logs & events (Registros y eventos).
-
En la sección Auto scaling policies (Políticas de Auto Scaling), elija Add (Añadir).
Aparecerá el cuadro de diálogo Add Auto Scaling policy (Añadir política de Auto Scaling).
-
En Policy name (Nombre de la política), escriba un nombre para la política.
-
Para la métrica de destino, elija una de las siguientes opciones:
-
Average CPU utilization of Aurora Replicas (Utilización media de CPU de réplicas de Aurora) para crear una política basada en el uso medio de la CPU.
-
Average connections of Aurora Replicas (Promedio de conexiones de réplicas de Aurora) para crear una política basada en el número medio de conexiones a réplicas de Aurora.
-
-
Para el valor de destino, escriba una de las siguientes opciones:
-
Si eligió Average CPU utilization of Aurora Replicas (Utilización media de CPU de réplicas de Aurora) en el paso anterior, escriba el porcentaje de utilización de CPU que desea mantener en las réplicas de Aurora.
-
Si eligió Average connections of Aurora Replicas (Promedio de conexiones de réplicas de Aurora) en el paso anterior, escriba el número de conexiones que desea mantener.
Las réplicas de Aurora se añaden o quitan para mantener la métrica en un valor próximo al especificado.
-
-
(Opcional) Expanda Additional Configuration (Configuración adicional) para crear un periodo de recuperación de escalado vertical u horizontal.
-
Para Minimum capacity (Capacidad mínima), escriba el número mínimo de réplicas de Aurora que debe mantener la política de Auto Scaling de Aurora.
-
Para Maximum capacity (Capacidad máxima), escriba el número máximo de réplicas de Aurora que debe mantener la política de Auto Scaling de Aurora.
-
Elija Add policy (Agregar política).
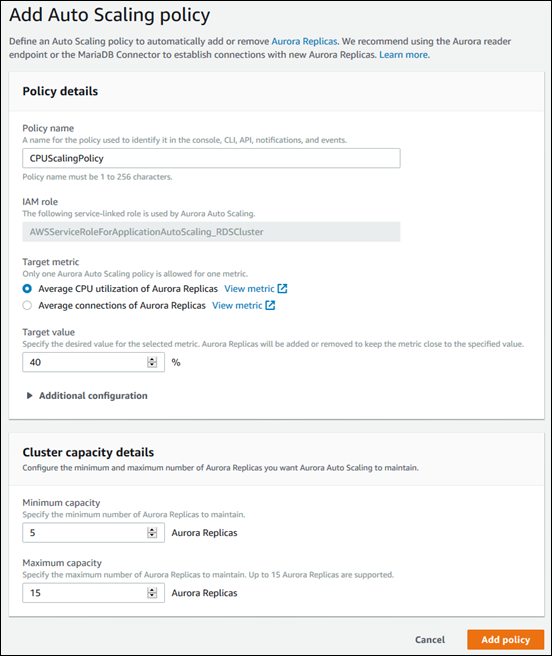
El siguiente cuadro de diálogo crea una política de Auto Scaling basada en un uso medio de la CPU del 40 por ciento. En la política se especifica un mínimo de 5 réplicas de Aurora y un máximo de 15 réplicas de Aurora.
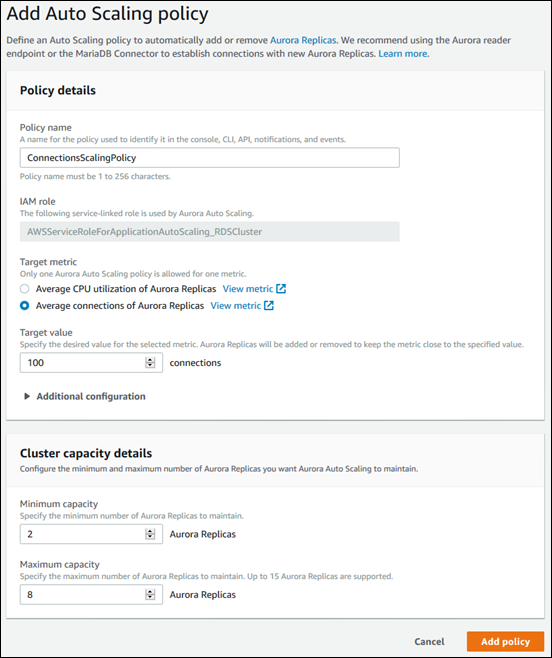
En el siguiente cuadro de diálogo se crea una política de Auto Scaling basada en un número medio de conexiones de 100. En la política se especifica un mínimo de dos réplicas de Aurora y un máximo de ocho réplicas de Aurora.
Puede aplicar una política de escalado en función de una métrica predefinida o una personalizada. Para ello, puede usar AWS CLI o la API de Auto Scaling de aplicaciones. El primer paso consiste en registrar su clúster de base de datos Aurora con Auto Scaling de aplicaciones.
Registro de un clúster de base de datos Aurora
Antes de que pueda usar Auto Scaling de Aurora con un clúster de base de datos Aurora, puede registrar su clúster de base de datos Aurora con Auto Scaling de aplicaciones. Esto se hace para definir la dimensión y los límites de escalado que se van a aplicar a ese clúster. La aplicación Auto Scaling escala dinámicamente el clúster de base de datos de Aurora a lo largo de la rds:cluster:ReadReplicaCount dimensión escalable, que representa el número de réplicas de Aurora.
Para registrar su clúster de base de datos Aurora, puede usar la AWS CLI o la API de Auto Scaling de aplicaciones.
AWS CLI
Para registrar un clúster de base de datos de Aurora, utilice el comando register-scalable-target de AWS CLI con los siguientes parámetros:
-
--service-namespace– ajuste este valor enrds. -
--resource-id: identificador de recurso para el clúster de base de datos Aurora. Para este parámetro, el tipo de recurso esclustery el identificador único es el nombre del clúster de base de datos Aurora, por ejemplocluster:myscalablecluster. -
--scalable-dimension– ajuste este valor enrds:cluster:ReadReplicaCount. -
--min-capacity: el número mínimo de instancias de base de datos de lector que Auto Scaling de aplicaciones va a administrar. Para obtener información sobre la relación entre--min-capacity,--max-capacity, y el número de instancias de bases de datos del clúster, consulte Capacidad mínima y máxima. -
--max-capacity: el número máximo de instancias de base de datos de lector que Auto Scaling de aplicaciones va a administrar. Para obtener información sobre la relación entre--min-capacity,--max-capacity, y el número de instancias de bases de datos del clúster, consulte Capacidad mínima y máxima.
ejemplo
En el siguiente ejemplo, registra un clúster de base de datos Aurora denominado myscalablecluster. El registro indica que el clúster de base de datos debe escalarse dinámicamente para tener de una a ocho réplicas de Aurora.
Para Linux, macOS o Unix:
aws application-autoscaling register-scalable-target \ --service-namespace rds \ --resource-id cluster:myscalablecluster\ --scalable-dimension rds:cluster:ReadReplicaCount \ --min-capacity1\ --max-capacity8\
Para Windows:
aws application-autoscaling register-scalable-target ^ --service-namespace rds ^ --resource-id cluster:myscalablecluster^ --scalable-dimension rds:cluster:ReadReplicaCount ^ --min-capacity1^ --max-capacity8^
API Application Auto Scaling
Para registrar un clúster de base de datos de Aurora con Auto Scaling de aplicaciones, use la operación RegisterScalableTarget de la API de Auto Scaling de aplicaciones con los siguientes parámetros:
-
ServiceNamespace– ajuste este valor enrds. -
ResourceID: identificador de recurso para el clúster de base de datos Aurora. Para este parámetro, el tipo de recurso esclustery el identificador único es el nombre del clúster de base de datos Aurora, por ejemplocluster:myscalablecluster. -
ScalableDimension– ajuste este valor enrds:cluster:ReadReplicaCount. -
MinCapacity: el número mínimo de instancias de base de datos de lector que Auto Scaling de aplicaciones va a administrar. Para obtener información sobre la relación entreMinCapacity,MaxCapacity, y el número de instancias de bases de datos del clúster, consulte Capacidad mínima y máxima. -
MaxCapacity: el número máximo de instancias de base de datos de lector que Auto Scaling de aplicaciones va a administrar. Para obtener información sobre la relación entreMinCapacity,MaxCapacity, y el número de instancias de bases de datos del clúster, consulte Capacidad mínima y máxima.
ejemplo
En el siguiente ejemplo, registra un clúster de base de datos Aurora denominado myscalablecluster con la API de Auto Scaling de aplicaciones. Este registro indica que el clúster de base de datos debe escalarse dinámicamente para tener de una a ocho réplicas de Aurora.
POST / HTTP/1.1 Host: autoscaling.us-east-2.amazonaws.com Accept-Encoding: identity Content-Length: 219 X-Amz-Target: AnyScaleFrontendService.RegisterScalableTarget X-Amz-Date: 20160506T182145Z User-Agent: aws-cli/1.10.23 Python/2.7.11 Darwin/15.4.0 botocore/1.4.8 Content-Type: application/x-amz-json-1.1 Authorization: AUTHPARAMS { "ServiceNamespace": "rds", "ResourceId": "cluster:myscalablecluster", "ScalableDimension": "rds:cluster:ReadReplicaCount", "MinCapacity":1, "MaxCapacity":8}
Definición de una política de escalado para un clúster de base de datos Aurora
Una configuración de la política de escalado de seguimiento de destino está representada por un bloque JSON en el que se definen las métricas y los valores de destino. Puede guardar una configuración de la política de escalado como bloque JSON en un archivo de texto. Puede utilizarr ese archivo de texto al invocar AWS CLI o la API de Auto Scaling de aplicaciones. Para obtener más información acerca de la sintaxis de configuración de la política, consulte TargetTrackingScalingPolicyConfiguration en la referencia de la API de Auto Scaling de aplicaciones.
Las siguientes opciones están disponibles para definir una configuración de la política de escalado de seguimiento de destino.
Temas
Uso de una métrica predefinida
Mediante las métricas predefinidas, puede definir rápidamente una política de escalado de seguimiento de destino para un clúster de base de datos Aurora que funciona bien tanto con el seguimiento de destino como con el escalado dinámico en Auto Scaling de Aurora.
Actualmente, Aurora admite las siguientes métricas predefinidas en Auto Scaling de Aurora:
-
RDSReaderAverageCPUUtilization: el valor medio de la métrica de
CPUUtilizationen CloudWatch en todas las réplicas de Aurora del clúster de base de datos Aurora. -
RDSReaderAverageDatabaseConnections: el valor medio de la métrica de
DatabaseConnectionsen CloudWatch en todas las réplicas de Aurora del clúster de base de datos Aurora.
Para obtener más información sobre las métricas de CPUUtilization y DatabaseConnections, consulte Métricas de Amazon CloudWatch para Amazon Aurora.
Para usar una métrica predefinida en su política de escalado, puede crear una configuración de seguimiento de destino para su política de escalado. Esta configuración debe incluir PredefinedMetricSpecification para la métrica predefinida y TargetValue para el valor de destino de esa métrica.
ejemplo
En el siguiente ejemplo se describe una configuración de la política típica para el escalado de seguimiento de destino de un clúster de base de datos Aurora. En esta configuración, la métrica predefinida RDSReaderAverageCPUUtilization se usa para ajustar el clúster de base de datos Aurora en función del uso medio de la CPU del 40 por ciento en todas las réplicas de Aurora.
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" } }
Uso de una métrica personalizada
Mediante las métricas personalizadas, puede definir una política de escalado de seguimiento de destino que cumpla sus requisitos personalizados. Puede definir una métrica personalizada en función de cualquier métrica de Aurora que cambie en proporción al escalado.
No todas las métricas de Aurora funcionan para el seguimiento de destino. La métrica debe ser una métrica de utilización válida y describir el nivel de actividad de una instancia. El valor de la métrica debe aumentar o reducirse en proporción al número de réplicas de Aurora del clúster de base de datos Aurora. Este aumento o reducción proporcionales son necesarios para usar los datos de las métricas a fin de ampliar o reducir proporcionalmente el número de réplicas de Aurora.
ejemplo
En el siguiente ejemplo se describe una configuración de seguimiento de destino para una política de escalado. En esta configuración, una métrica personalizada ajusta un clúster de base de datos Aurora en función de un uso medio de la CPU del 50 % en todas las réplicas de Aurora de un clúster de base de datos Aurora denominado my-db-cluster.
{ "TargetValue": 50, "CustomizedMetricSpecification": { "MetricName": "CPUUtilization", "Namespace": "AWS/RDS", "Dimensions": [ {"Name": "DBClusterIdentifier","Value": "my-db-cluster"}, {"Name": "Role","Value": "READER"} ], "Statistic": "Average", "Unit": "Percent" } }
Uso de periodos de recuperación
Puede especificar un valor, en segundos, a fin de que ScaleOutCooldown añada un periodo de recuperación para el escalado ascendente de su clúster de base de datos Aurora. De forma similar, puede añadir un valor, en segundos, a fin de que ScaleInCooldown añada un periodo de recuperación para el escalado descendente de su clúster de base de datos Aurora. Para obtener más información acerca de ScaleInCooldown y ScaleOutCooldown, consulte TargetTrackingScalingPolicyConfiguration en la referencia de la API de Auto Scaling de aplicaciones.
ejemplo
En el siguiente ejemplo se describe una configuración de seguimiento de destino para una política de escalado. En esta configuración, la métrica predefinida RDSReaderAverageCPUUtilization se usa para ajustar un clúster de base de datos de Aurora en función del uso promedio de la CPU del 40 por ciento en todas las réplicas de Aurora de ese clúster de base de datos de Aurora. La configuración proporciona un periodo de recuperación de escalado descendente de 10 minutos y un periodo de recuperación de escalado ascendente de 5 minutos.
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" }, "ScaleInCooldown": 600, "ScaleOutCooldown": 300 }
Desactivación de actividad de escalado descendente
Puede evitar que la configuración de la política de escalado de seguimiento de destino escale de forma descendente su clúster de base de datos Aurora deshabilitando la actividad de escalado descendente. La deshabilitación de la actividad de escalado descendente evita que la política de escalado elimine réplicas de Aurora, a la vez que permite a la política de escalado crearlas según sea necesario.
Puede especificar un valor booleano para que DisableScaleIn habilite o deshabilite la actividad de escalado descendente para su clúster de base de datos Aurora. Para obtener más información acerca de DisableScaleIn, consulte TargetTrackingScalingPolicyConfiguration en la referencia de la API de Auto Scaling de aplicaciones.
ejemplo
En el siguiente ejemplo se describe una configuración de seguimiento de destino para una política de escalado. En esta configuración, la métrica predefinida RDSReaderAverageCPUUtilization ajusta un clúster de base de datos Aurora en función del uso medio de la CPU del 40 % en todas las réplicas de Aurora de ese clúster de base de datos Aurora. La configuración deshabilita la actividad de escalado descendente para la política de escalado.
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" }, "DisableScaleIn": true }
Aplicación de una política de escalado a un clúster de base de datos Aurora
Tras registrar su clúster de base de datos Aurora con Auto Scaling de aplicaciones y definir una política de escalado, puede aplicar esta al clúster de base de datos Aurora registrado. Para aplicar una política de escalado a un clúster de base de datos Aurora, puede usar la AWS CLI o la API de Auto Scaling de aplicaciones.
Para aplicar una política de escalado a un clúster de base de datos de Aurora, use el comando put-scaling-policy de AWS CLI con los siguientes parámetros:
-
--policy-name: el nombre de la política de escalado. -
--policy-type– ajuste este valor enTargetTrackingScaling. -
--resource-id: identificador de recurso para el clúster de base de datos Aurora. Para este parámetro, el tipo de recurso esclustery el identificador único es el nombre del clúster de base de datos Aurora, por ejemplocluster:myscalablecluster. -
--service-namespace– ajuste este valor enrds. -
--scalable-dimension– ajuste este valor enrds:cluster:ReadReplicaCount. -
--target-tracking-scaling-policy-configuration: configuración de la política de escalado de seguimiento de destino que se usará para el clúster de base de datos Aurora.
ejemplo
En el siguiente ejemplo, aplica una política de escalado de seguimiento de destino denominada myscalablepolicy a un clúster de base de datos Aurora llamado myscalablecluster con Auto Scaling de aplicaciones. Para ello, puede usar una configuración de la política guardada en un archivo denominado config.json.
Para Linux, macOS o Unix:
aws application-autoscaling put-scaling-policy \ --policy-namemyscalablepolicy\ --policy-type TargetTrackingScaling \ --resource-id cluster:myscalablecluster\ --service-namespace rds \ --scalable-dimension rds:cluster:ReadReplicaCount \ --target-tracking-scaling-policy-configurationfile://config.json
Para Windows:
aws application-autoscaling put-scaling-policy ^ --policy-namemyscalablepolicy^ --policy-type TargetTrackingScaling ^ --resource-id cluster:myscalablecluster^ --service-namespace rds ^ --scalable-dimension rds:cluster:ReadReplicaCount ^ --target-tracking-scaling-policy-configurationfile://config.json
Para aplicar una política de escalado a un clúster de base de datos de Aurora con la API de Auto Scaling de aplicaciones, utilice la operación PutScalingPolicy de la API de Auto Scaling de aplicaciones con los siguientes parámetros:
-
PolicyName: el nombre de la política de escalado. -
ServiceNamespace– ajuste este valor enrds. -
ResourceID: identificador de recurso para el clúster de base de datos Aurora. Para este parámetro, el tipo de recurso esclustery el identificador único es el nombre del clúster de base de datos Aurora, por ejemplocluster:myscalablecluster. -
ScalableDimension– ajuste este valor enrds:cluster:ReadReplicaCount. -
PolicyType– ajuste este valor enTargetTrackingScaling. -
TargetTrackingScalingPolicyConfiguration: configuración de la política de escalado de seguimiento de destino que se usará para el clúster de base de datos Aurora.
ejemplo
En el siguiente ejemplo, aplica una política de escalado de seguimiento de destino denominada myscalablepolicy a un clúster de base de datos Aurora llamado myscalablecluster con Auto Scaling de aplicaciones. Puede usar una configuración de la política en función de la métrica predefinida RDSReaderAverageCPUUtilization.
POST / HTTP/1.1 Host: autoscaling.us-east-2.amazonaws.com Accept-Encoding: identity Content-Length: 219 X-Amz-Target: AnyScaleFrontendService.PutScalingPolicy X-Amz-Date: 20160506T182145Z User-Agent: aws-cli/1.10.23 Python/2.7.11 Darwin/15.4.0 botocore/1.4.8 Content-Type: application/x-amz-json-1.1 Authorization: AUTHPARAMS { "PolicyName": "myscalablepolicy", "ServiceNamespace": "rds", "ResourceId": "cluster:myscalablecluster", "ScalableDimension": "rds:cluster:ReadReplicaCount", "PolicyType": "TargetTrackingScaling", "TargetTrackingScalingPolicyConfiguration": { "TargetValue":40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" } } }
