Ejemplo: utilice Application Signals para resolver un problema de estado operativo
El siguiente escenario brinda un ejemplo de cómo se puede utilizar Application Signals para monitorear sus servicios e identificar problemas de calidad del servicio. Desplácese para identificar las posibles causas subyacentes y tome medidas para resolver el problema. Este ejemplo se centra en una aplicación de clínica de mascotas compuesta por varios microservicios que llaman a Servicios de AWS, como DynamoDB.
Jane forma parte de un equipo de DevOps que supervisa el estado operativo de una aplicación de clínica de mascotas. El equipo de Jane se encarga de asegurar que la aplicación tenga una alta disponibilidad y capacidad de respuesta. Utilizan objetivos de nivel de servicio (SLO) para medir el rendimiento de las aplicaciones en relación con estos compromisos empresariales. Jane recibe una alerta sobre varios indicadores de nivel de servicio (SLI) incorrectos. Abre la consola de CloudWatch y se dirige a la página Servicios, donde observa varios servicios que no funcionan de forma correcta.
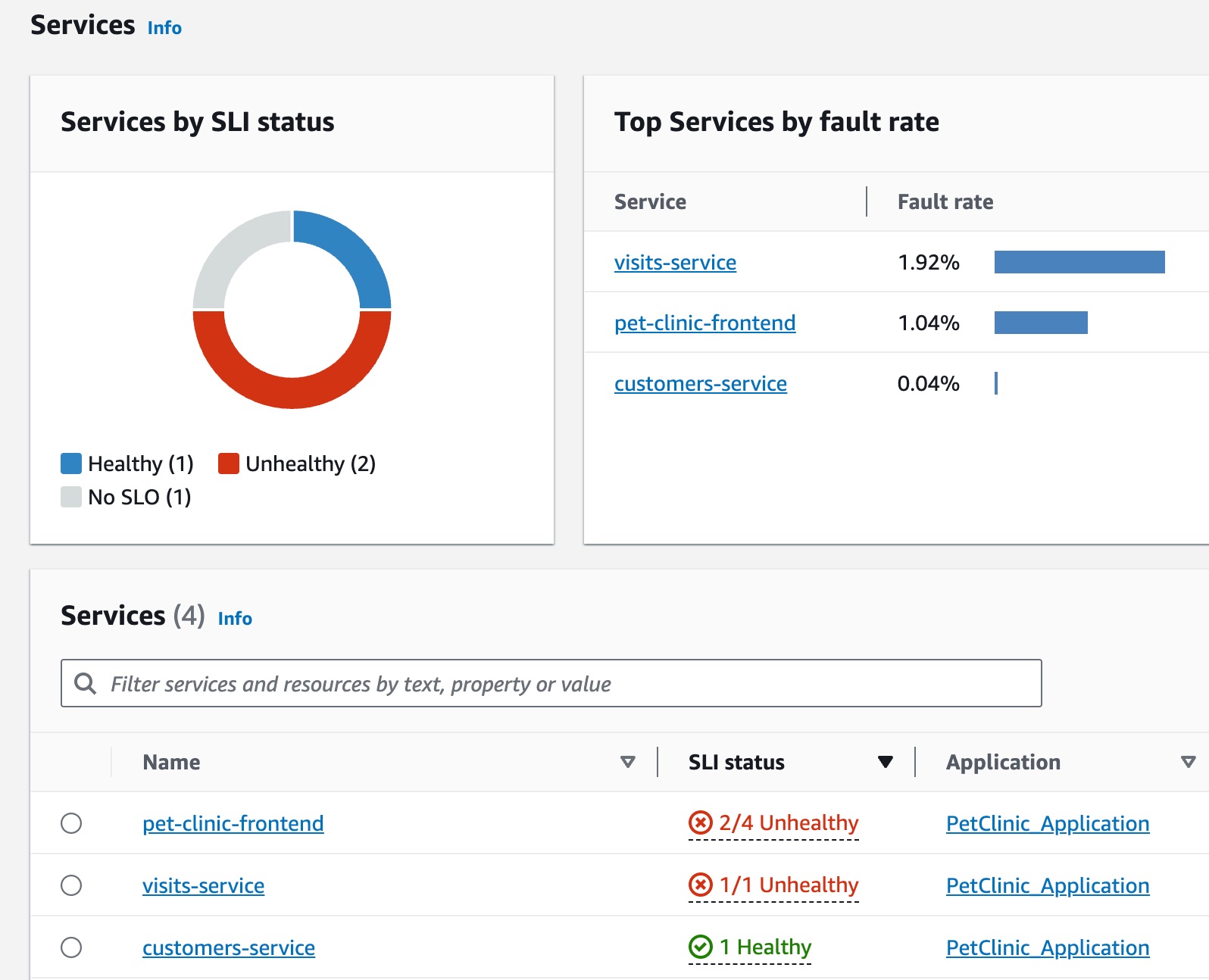
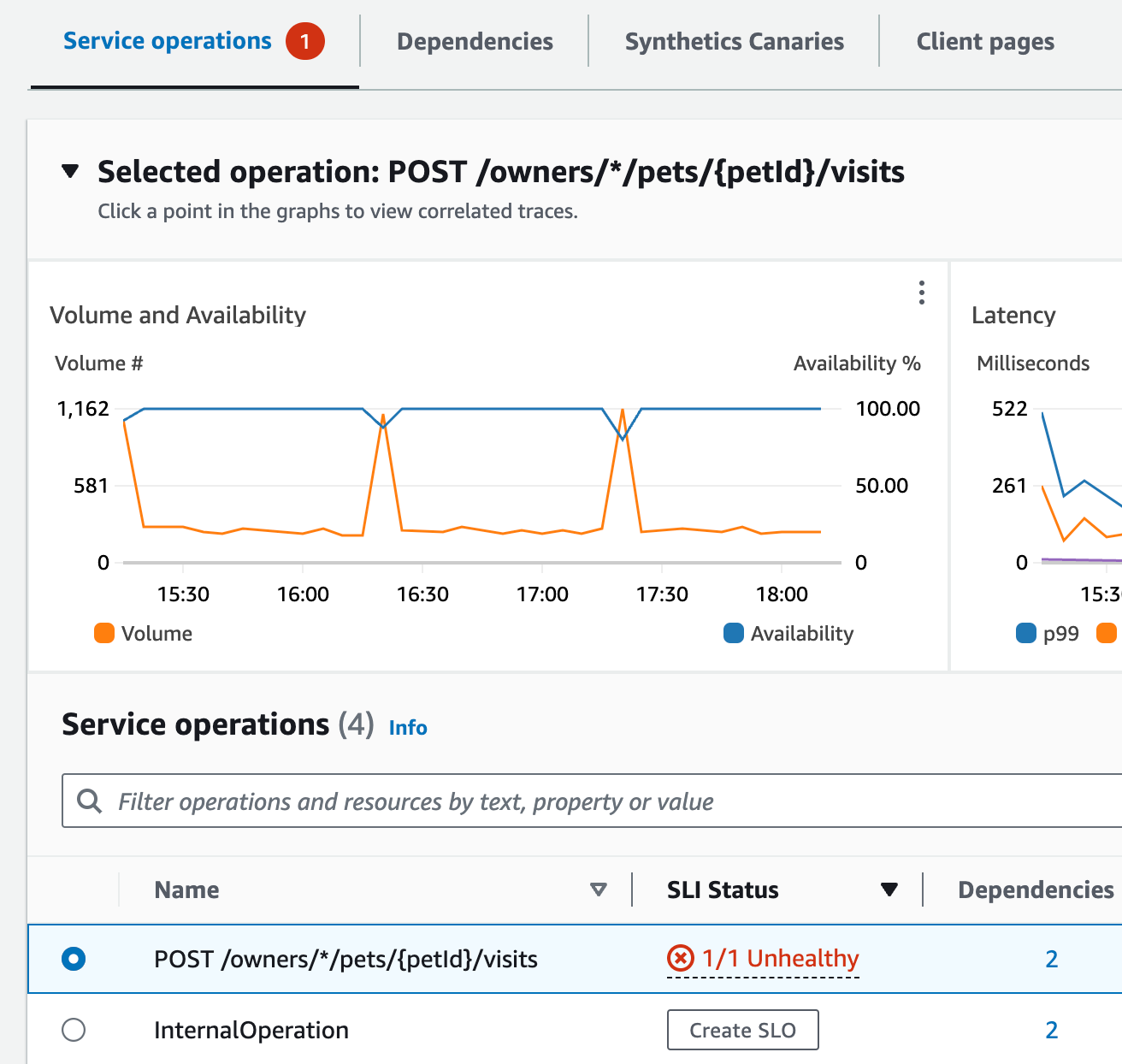
En la parte superior de la página, Jane ve que el visits-service es el servicio principal por tasa de fallos. Selecciona el enlace en el gráfico, que abre la página Detalles del servicio para ese servicio. Observa que hay una operación incorrecta en la tabla Operaciones del servicio. Selecciona esta operación y observa en el gráfico de Volumen y disponibilidad que hay picos periódicos en el volumen de llamadas que parecen relacionarse con caídas en la disponibilidad.
Para analizar más de cerca las caídas en la disponibilidad del servicio, Jane selecciona uno de los puntos de datos de disponibilidad del gráfico. Se abre un panel que muestra los seguimientos de X-Ray que se correlacionan con el punto de datos seleccionado. Observa que hay varios seguimientos que contienen errores.
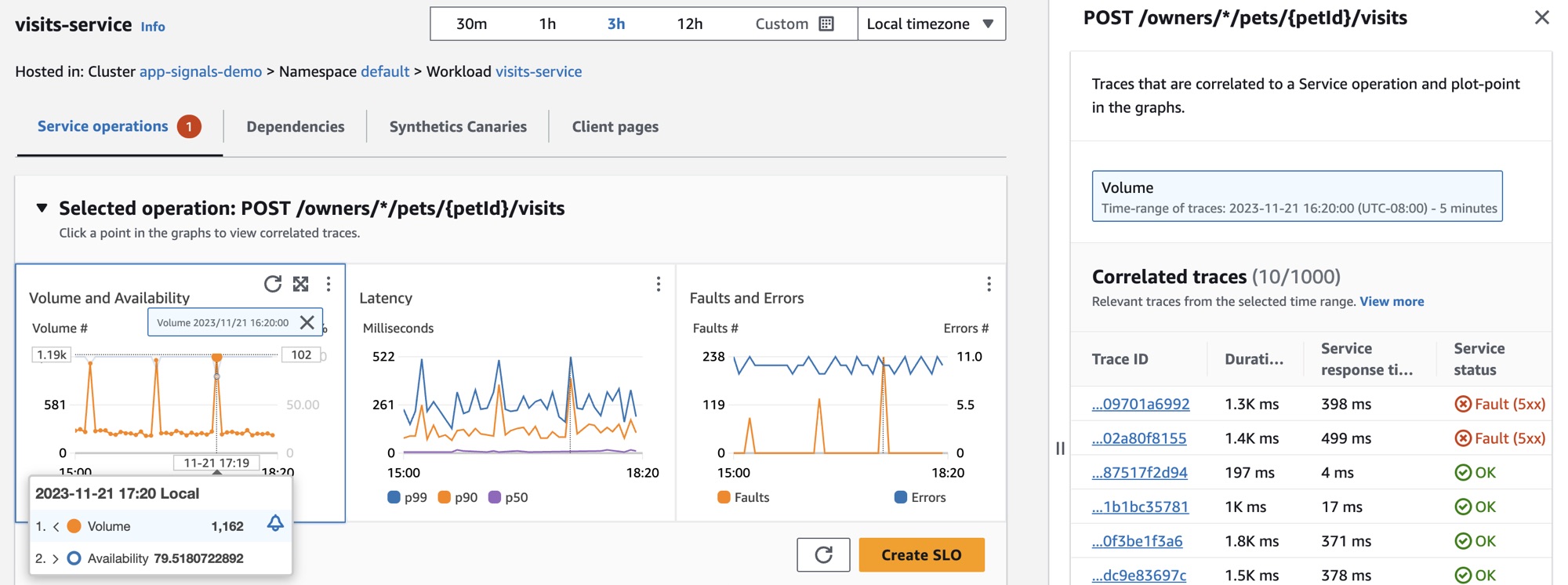
Jane selecciona uno de los seguimientos correlacionados con un estado de error, lo que abre la página de detalles de Seguimiento de X-Ray del seguimiento seleccionado. Jane se desplaza hacia la sección Escala de tiempo de los segmentos y sigue la ruta de llamada hasta que observa que las llamadas a una tabla de DynamoDB presentan errores. Selecciona el segmento de DynamoDB y navega hasta la pestaña Excepciones del panel de la derecha.

Jane observa que un recurso de DynamoDB está mal configurado, lo que provoca errores durante los picos de solicitudes de los clientes. El nivel de rendimiento aprovisionado de la tabla de DynamoDB se supera de forma periódica, lo que provoca problemas de disponibilidad del servicio y SLI incorrectos. Según esta información, su equipo puede configurar un nivel superior de rendimiento aprovisionado y asegurar una alta disponibilidad de la aplicación.
