Visualización de la actividad detallada del servicio y el estado operativo en la página de detalles del servicio
Al instrumentar la aplicación, Amazon CloudWatch Application Signals asigna todos los servicios que descubre la aplicación. Utilice la página de detalles del servicio para ver una descripción general de sus servicios, las operaciones, dependencias, canarios y solicitudes de los clientes para un solo servicio. Para ver la página de detalles del servicio, haga lo siguiente:
-
Elija Servicios en la sección Application Signals del panel de navegación izquierdo.
-
Elija el nombre de cualquier servicio desde Servicios, Servicios principales o de las tablas de dependencias.
Bajo schedule-visits, verá la etiqueta de cuenta y el ID bajo el nombre del servicio.
La página de detalles del servicio se organiza en las siguientes pestañas:
-
Descripción general: utilice esta pestaña para ver una descripción general de un solo servicio, incluida la cantidad de operaciones, las dependencias, los datos sintéticos y las páginas de clientes. La pestaña muestra las métricas clave de todo el servicio, las principales operaciones y las dependencias. Estas métricas incluyen datos de series temporales sobre la latencia, las fallas y los errores en todas las operaciones de servicio para ese servicio.
-
Operaciones de servicio: use esta pestaña para ver una lista de las operaciones a las que llama su servicio y gráficos interactivos con las métricas clave que miden el estado de cada operación. Puede seleccionar un punto de datos en un gráfico para obtener información sobre los seguimientos, los registros o las métricas asociadas a ese punto de datos.
-
Dependencias: use esta pestaña para ver una lista de las dependencias a las que llama su servicio y una lista de métricas de esas dependencias.
-
Canarios de Synthetics: use esta pestaña para ver una lista de canarios de Synthetics que simulan las llamadas de los usuarios a su servicio y las métricas de rendimiento clave para ver cómo funcionan esos canarios.
-
Páginas de clientes: use esta pestaña para ver una lista de las páginas de clientes que llaman a su servicio y las métricas que miden la calidad de las interacciones de los clientes con su aplicación.
-
Métricas relacionadas: utilice esta pestaña para correlacionar las métricas relacionadas, como las métricas estándar, las métricas de tiempo de ejecución y las métricas personalizadas de un servicio, sus operaciones o sus dependencias.
Visualización de la descripción general de su servicio
Utilice la página de descripción general del servicio para ver un resumen detallado de las métricas de todas las operaciones de servicio en una única ubicación. Compruebe el rendimiento de todas las operaciones, dependencias, páginas de clientes y canarios de Synthetics que interactúan con su aplicación. Utilice esta información como ayuda para determinar dónde concentrar los esfuerzos para identificar problemas, solucionar errores y encontrar oportunidades de optimización.
Elija cualquier enlace en Detalles del servicio para ver la información relacionada con un servicio específico. Por ejemplo, en el caso de los servicios alojados en Amazon EKS, la página de detalles del servicio muestra información sobre el clúster, el espacio de nombres y la carga de trabajo. Para los servicios alojados en Amazon ECS o Amazon EC2, la página de detalles del servicio muestra el valor del entorno.
En Servicios, la pestaña Descripción general muestra un resumen de lo siguiente:
-
Operaciones: utilice esta pestaña para ver el estado de las operaciones de servicio. El estado está determinado por los indicadores de nivel de servicio (SLI), que se definen como parte de un objetivo de nivel de servicio (SLO).
-
Dependencias: utilice esta pestaña para ver las principales dependencias de los servicios a los que llama su aplicación, ordenadas por tasa de fallos, y para ver el estado de las dependencias de sus servicios. El estado está determinado por los indicadores de nivel de servicio (SLI), que se definen como parte de un objetivo de nivel de servicio (SLO).
-
Canarios de Synthetics: utilice esta pestaña para ver el resultado de las llamadas simuladas a puntos de conexión o API asociadas a su servicio y el número de canarios fallidos.
-
Páginas de clientes: utilice esta pestaña para ver las páginas principales a las que llaman los clientes que tienen errores asíncronos de JavaScript y XML (AJAX).
La siguiente ilustración muestra una descripción general de los servicios:

La pestaña Descripción general también muestra un gráfico de las dependencias con la latencia más alta en todos los servicios. Utilice las métricas de latencia p99, p90 y p50 para evaluar rápidamente qué dependencias contribuyen a la latencia total del servicio, de la siguiente manera:

Por ejemplo, el gráfico anterior muestra que el 99 % de las solicitudes realizadas a la dependencia customer-service se completaron en aproximadamente 4950 milisegundos. Las demás dependencias tardaron menos tiempo.
Los gráficos que muestran las cuatro operaciones de servicio principales por latencia muestran el volumen de solicitudes, la disponibilidad, la tasa de fallos y la tasa de errores de esos servicios, como se muestra en la siguiente imagen:
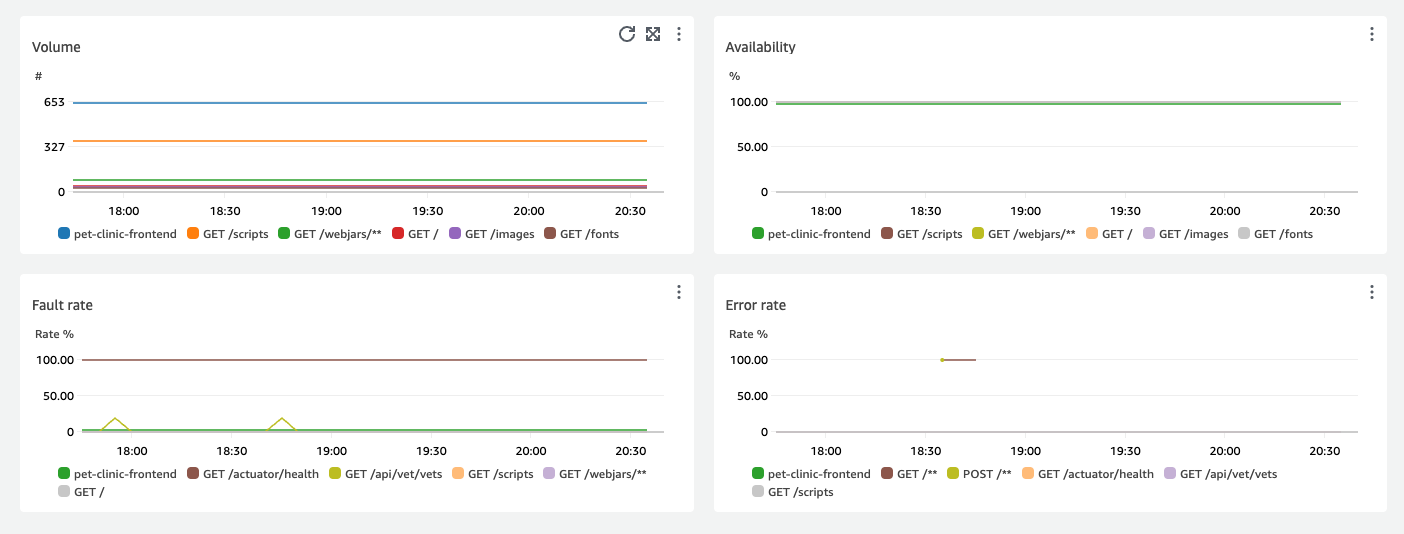
La sección Detalles del servicio muestra los detalles del servicio, como el ID de la cuenta y la Etiqueta de la cuenta.
Visualización de las operaciones de servicio
Al instrumentar la aplicación, Application Signals descubre todas las operaciones de servicio a las que llama la aplicación. Utilice la pestaña Operaciones del servicio para ver una tabla que contiene las operaciones del servicio y un conjunto de métricas que miden el rendimiento de una operación seleccionada. Estas métricas incluyen el estado del indicador de nivel de servicio (SLI), el número de dependencias, la latencia, el volumen, los fallos, los errores y la disponibilidad, como se muestra en la siguiente imagen:
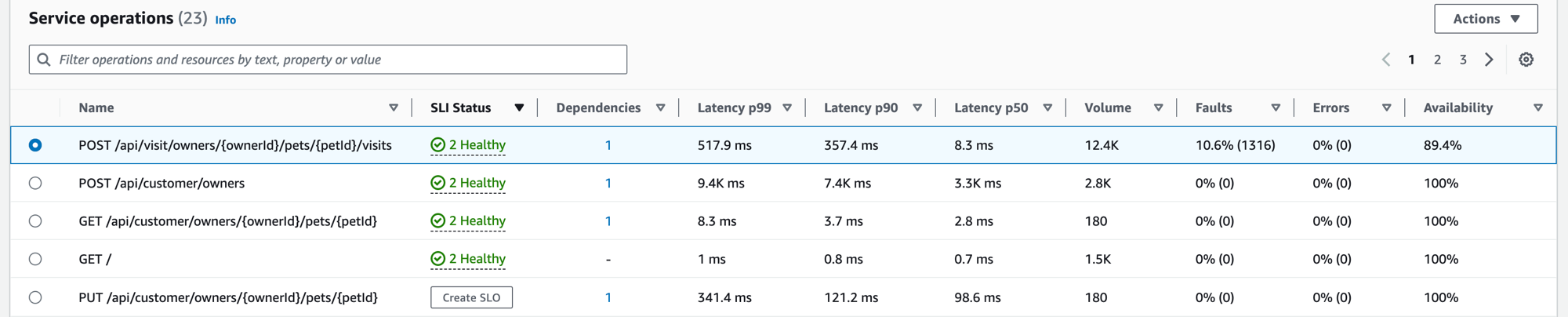
Filtre la tabla para que le resulte más fácil encontrar una operación de servicio al seleccionar una o más propiedades del cuadro de texto del filtro. Al elegir cada propiedad, se lo guiará por los criterios de filtro y verá el filtro completo debajo del cuadro de texto del filtro. Elija Borrar filtros en cualquier momento para eliminar el filtro de la tabla.
Elija el estado del SLI para una operación para mostrar una ventana emergente que contiene un vínculo a cualquier SLI en mal estado y un vínculo para ver todos los SLO de la operación, como se muestra en la siguiente tabla:
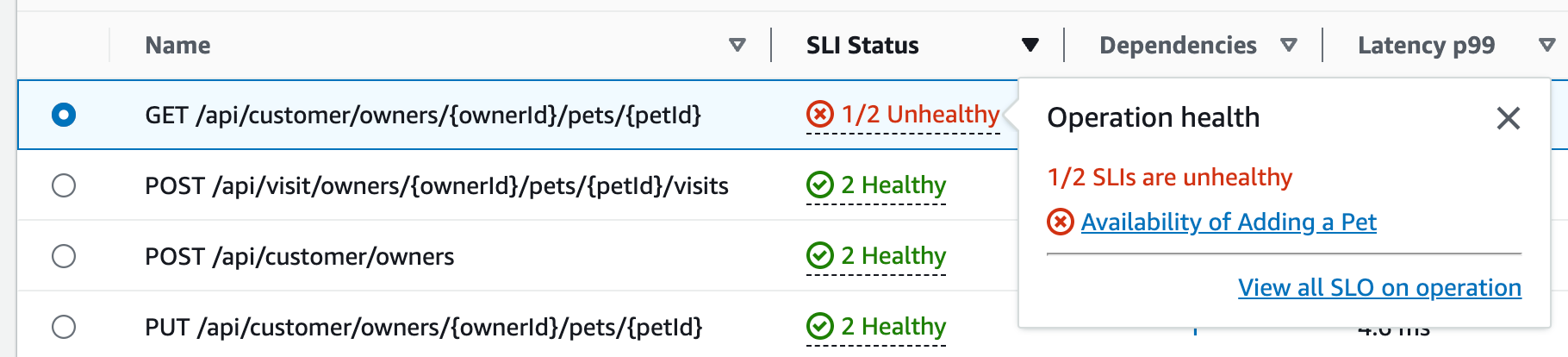
La tabla de operaciones del servicio muestra el estado del SLI, el número de SLI en buen estado o en mal estado y el número total de SLO para cada operación.
Utilice los SLI para supervisar la latencia, la disponibilidad y otras métricas operativas que miden el estado operativo de un servicio. Utilice un SLO para comprobar el rendimiento y el estado de sus servicios y operaciones.
Para crear un SLO, realice el siguiente procedimiento:
-
Si una operación no tiene ningún SLO, elija el botón Crear SLO en la columna Estado del SLI.
-
Si una operación ya tiene un SLO, haga lo siguiente:
-
Seleccione el botón de opción situado junto al nombre de la operación.
-
Seleccione Crear SLO en la flecha desplegable Acciones situada en la parte superior derecha de la tabla.
-
Para obtener más información, consulte Objetivos de nivel de servicio (SLO).
La columna Dependencias muestra el número de dependencias a las que llama esta operación. Elija este número para abrir la pestaña Dependencias filtrada según la operación seleccionada.
Visualización de métricas de operaciones de servicio, seguimientos correlacionados y registros de aplicaciones
Application Signals correlaciona las métricas de operación de servicio con los seguimientos de AWS X-Ray, CloudWatch Container Insights y los registros de las aplicaciones. Utilice estas métricas para solucionar problemas de estado operativo. Para ver las métricas como información gráfica, haga lo siguiente:
-
Elija una opción de servicio en la tabla Operaciones de servicio para ver un conjunto de gráficos para la operación seleccionada encima de la tabla con métricas de volumen y disponibilidad, latencia y fallas y errores.
-
Coloque el cursor sobre un punto en un gráfico para ver más información.
-
Seleccione un punto para abrir un panel de diagnóstico que muestra seguimientos, métricas y registros de aplicaciones correlacionados para el punto seleccionado en el gráfico.
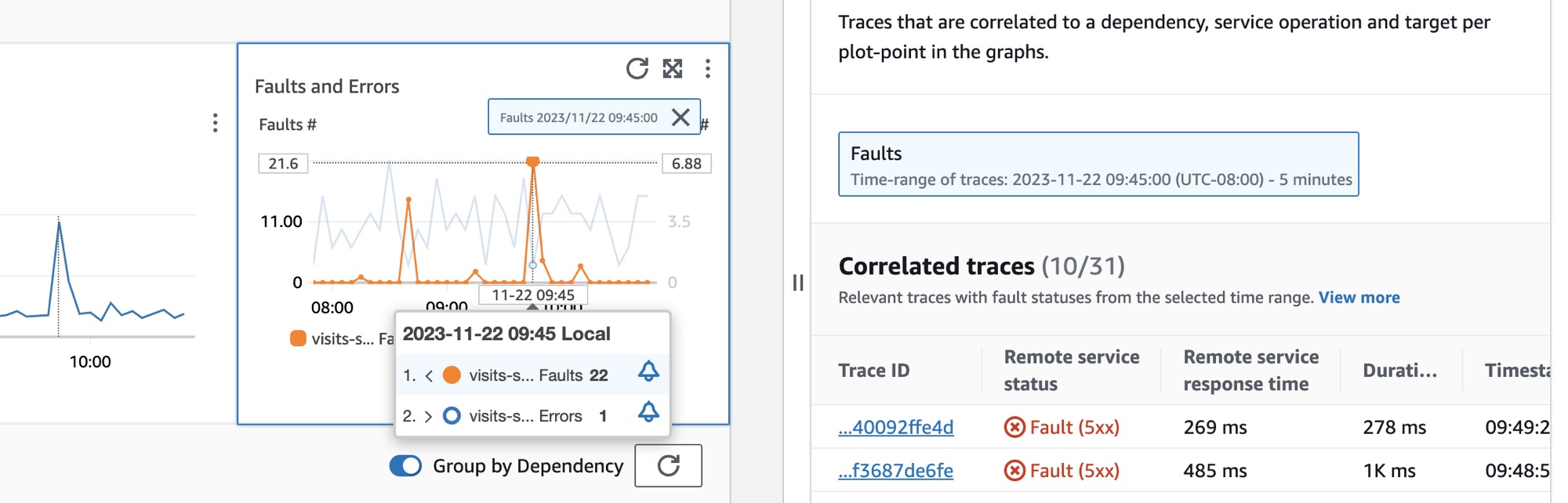
La siguiente imagen muestra la información sobre herramientas que aparece después de pasar el ratón sobre un punto del gráfico y el panel de diagnóstico que aparece al hacer clic en un punto. La información sobre herramientas contiene información sobre el punto de datos asociado en el gráfico de fallas y errores. El panel contiene los seguimientos correlacionados, los colaboradores principales y los registros de aplicaciones asociados al punto seleccionado.
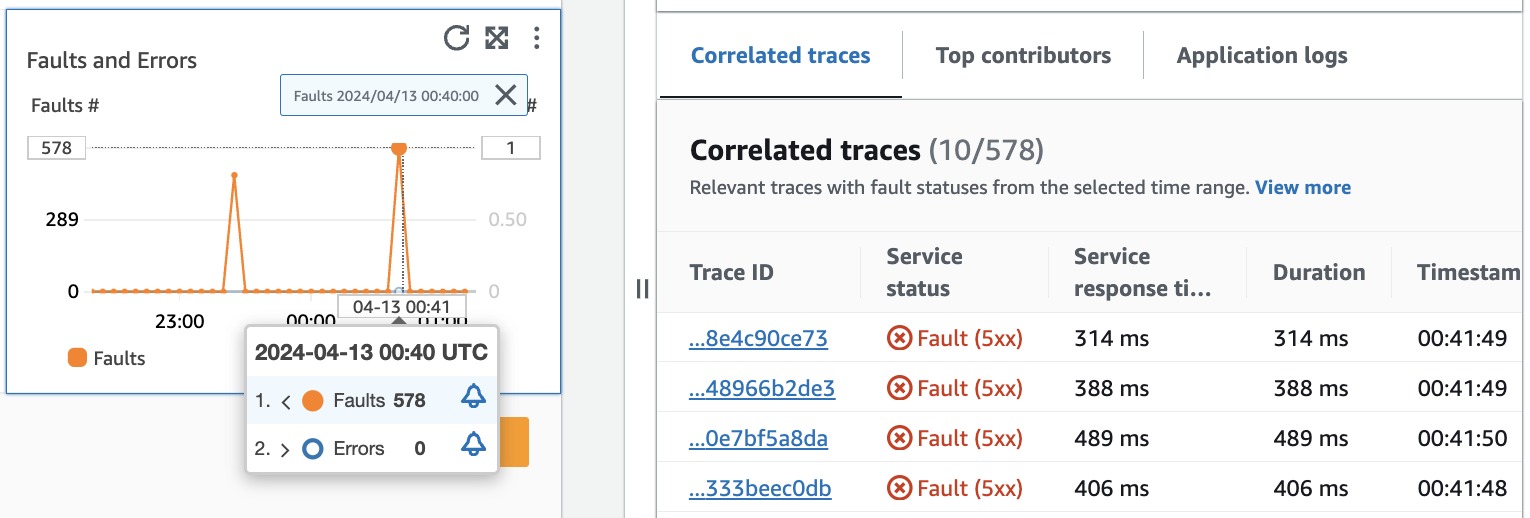
Seguimientos correlacionados
Observe los seguimientos relacionados para comprender un problema subyacente con un seguimiento. Puede comprobar si los seguimientos correlacionados o cualquier nodo de servicio asociado a ellos se comportan de forma similar. Para examinar los seguimientos correlacionados, elija un ID de seguimiento de la tabla Seguimientos correlacionados para abrir la página Detalles del seguimiento de X-Ray para el seguimiento elegido. La página de detalles del seguimiento contiene un mapa de nodos de servicio asociados con el seguimiento seleccionado y una línea de tiempo de los segmentos del seguimiento.
Colaboradores principales
Consulte los principales colaboradores para encontrar las principales fuentes de entrada a una métrica. Agrupe a los colaboradores por diferentes componentes para buscar similitudes dentro del grupo y comprender en qué se diferencia el comportamiento de seguimiento entre ellos.
En la pestaña Colaboradores principales se muestran las métricas de Volumen de llamadas, Disponibilidad, Latencia promedio, Errores y Fallas de cada grupo. La siguiente imagen de ejemplo muestra los principales colaboradores a un conjunto de métricas para una aplicación implementada en una plataforma Amazon EKS:
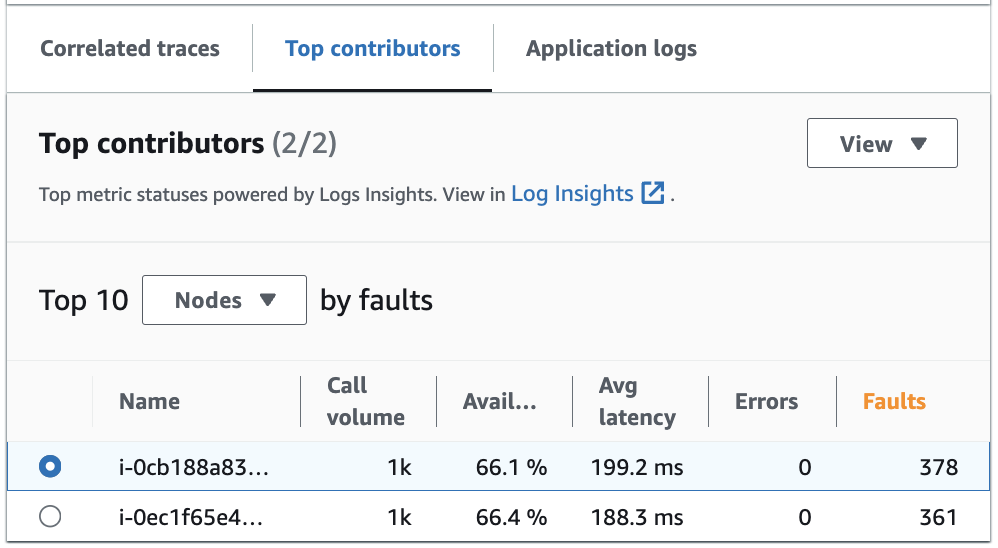
Los principales colaboradores contienen las siguientes métricas:
-
Volumen de llamadas: utilice el volumen de llamadas para conocer el número de solicitudes por intervalo de tiempo de un grupo.
-
Disponibilidad: utilice la disponibilidad para ver el porcentaje de tiempo que no se detectó ningún error en un grupo.
-
Latencia media: utilice la latencia para comprobar el tiempo medio durante el que se enviaron las solicitudes de un grupo durante un intervalo de tiempo que depende de cuánto tiempo hace que se hicieron las solicitudes que está investigando. Las solicitudes que se realizaron menos de 15 días antes se evalúan en intervalos de 1 minuto. Las solicitudes que se realizaron entre 15 y 30 días antes, inclusive, se evalúan en intervalos de 5 minutos. Por ejemplo, si está investigando las solicitudes que provocaron un error hace 15 días, la métrica del volumen de llamadas es igual al número de solicitudes por intervalo de 5 minutos.
-
Errores: el número de errores por grupo medidos durante un intervalo de tiempo.
-
Fallos: el número de fallos por grupo durante un intervalo de tiempo.
Colaboradores principales que utilizan Amazon EKS o Kubernetes
Utilice información acerca de los colaboradores principales para aplicaciones implementadas en Amazon EKS o Kubernetes para ver las métricas de estado operativo agrupadas por Nodo, Pod y PodTemplateHash. Se aplican las siguientes definiciones:
-
Un pod es un grupo de uno o más contenedores de Docker que comparten almacenamiento y recursos. Un pod es la unidad más pequeña que se puede implementar en una plataforma de Kubernetes. Agrupe por pods para comprobar si los errores están relacionados con limitaciones específicas del pod.
-
Un nodo es un servidor que ejecuta pods. Agrupe por nodos para comprobar si los errores están relacionados con limitaciones específicas del nodo.
-
El hash de una plantilla de pod se utiliza para buscar una versión concreta de una implementación. Agrupe por hash de plantilla de pod para comprobar si los errores están relacionados con una implementación en particular.
Principales colaboradores que utilizan Amazon EC2
Utilice la información sobre los principales colaboradores para aplicaciones implementadas en Amazon EKS para ver las métricas de estado operativo agrupadas por ID de instancia y grupo de escalado automático. Se aplican las siguientes definiciones:
-
Un ID de instancia es un identificador único de la instancia de Amazon EC2 que ejecuta su servicio. Agrupe por ID de instancia para comprobar si los errores están relacionados con una instancia de Amazon EC2 específica.
-
Un grupo de escalado automático es un conjunto de instancias de Amazon EC2 que le permiten escalar o reducir verticalmente los recursos que necesita para atender las solicitudes de sus aplicaciones. Agrupe por grupo de escalado automático si quiere comprobar si el alcance de los errores se limita a las instancias del grupo.
Principales colaboradores que utilizan una plataforma personalizada
Utilice la información sobre los principales colaboradores para aplicaciones implementadas con instrumentación personalizada para ver las métricas del estado operativo agrupadas por nombre de host. Se aplican las siguientes definiciones:
-
Un nombre de host identifica un dispositivo, como un punto de conexión o una instancia de Amazon EC2, que está conectado a una red. Agrupe por nombre de host para comprobar si los errores están relacionados con un dispositivo físico o virtual específico.
Visualización de los principales colaboradores en Log Insights y Container Insights
Vea y modifique la consulta automática que generó las métricas para sus principales colaboradores en Información de registros. Vea las métricas de rendimiento de la infraestructura por grupos específicos, como pods o nodos, en Información de contenedores. Puede ordenar los clústeres, los nodos o las cargas de trabajo por consumo de recursos e identificar rápidamente las anomalías o mitigar los riesgos de forma proactiva antes de que la experiencia del usuario final se vea afectada. A continuación, se muestra una imagen que muestra cómo seleccionar estas opciones:
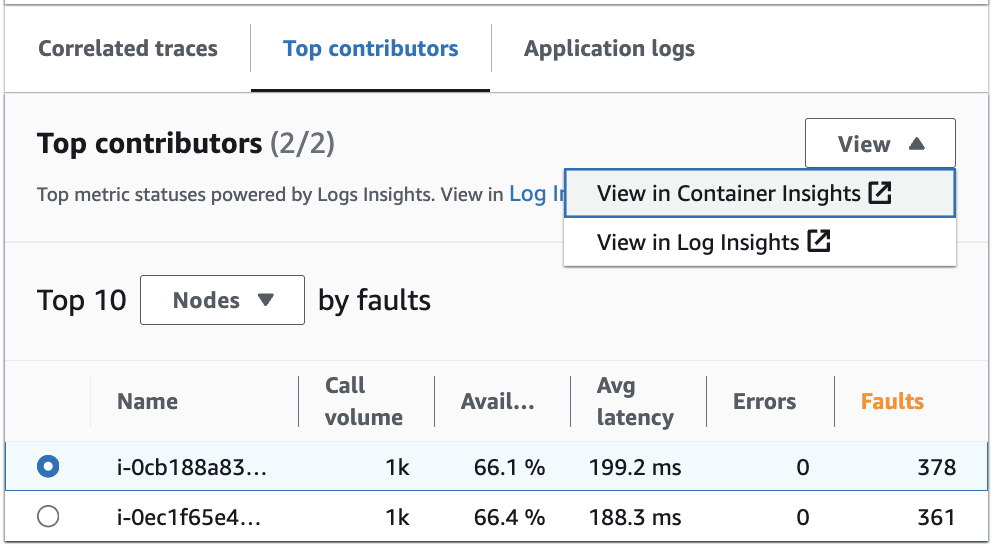
En Información de contenedores, puede ver las métricas de su contenedor de Amazon EKS o Amazon ECS que son específicas de la agrupación de sus principales colaboradores. Por ejemplo, si ha agrupado un contenedor de EKS por grupo para generar los principales colaboradores, la información sobre el contenedor mostrará las métricas y estadísticas filtradas para su pod.
En Información de registros, puede modificar la consulta que generó las métricas en Colaboradores principales siguiendo estos pasos:
-
Seleccione Ver en Información de registros. La página Información de registros que se abre contiene una consulta que se genera automáticamente y contiene la siguiente información:
-
El nombre del grupo de clústeres de registros.
-
La operación que estaba investigando con CloudWatch.
-
El agregado de la métrica de estado operativo con la que interactuó en el gráfico.
Los resultados del registro se filtran automáticamente para mostrar los datos de los últimos cinco minutos antes de seleccionar el punto de datos en el gráfico de servicio.
-
-
Para editar la consulta, sustituya el texto generado por sus cambios. También puede usar el Generador de consultas como ayuda para generar una consulta nueva o actualizar la consulta existente.
Registros de aplicaciones
Utilice la consulta de la pestaña Registros de aplicaciones para generar información registrada para su grupo de registros y servicio actuales e inserte una marca de tiempo. Un grupo de registro es un grupo de flujos de registro que puede definir al configurar la aplicación.
Utilice un grupo de registros para organizar los registros con características similares, incluidas las siguientes:
-
Capture los registros de una organización, fuente o función específicas.
-
Capture los registros a los que accede un usuario en particular.
-
Capture registros para un periodo de tiempo específico.
Utilice estos flujos de registro para realizar un seguimiento de grupos o períodos de tiempo específicos. También puede configurar reglas de supervisión, alarmas y notificaciones para estos grupos de registros. Para obtener información general acerca de los grupos de registros, consulte Working with log groups and log streams.
La consulta de registros de la aplicación devuelve los registros, los patrones de texto recurrentes y las visualizaciones gráficas de sus grupos de registros.
Para ejecutar la consulta, seleccione Ejecutar consulta en Información de registros para ejecutar la consulta generada automáticamente o modificarla. Para editar la consulta, sustituya el texto generado automáticamente por sus cambios. También puede usar el Generador de consultas como ayuda para generar una consulta nueva o actualizar la consulta existente.
La siguiente imagen muestra la consulta de ejemplo que se genera automáticamente en función del punto seleccionado en el gráfico de operaciones del servicio:
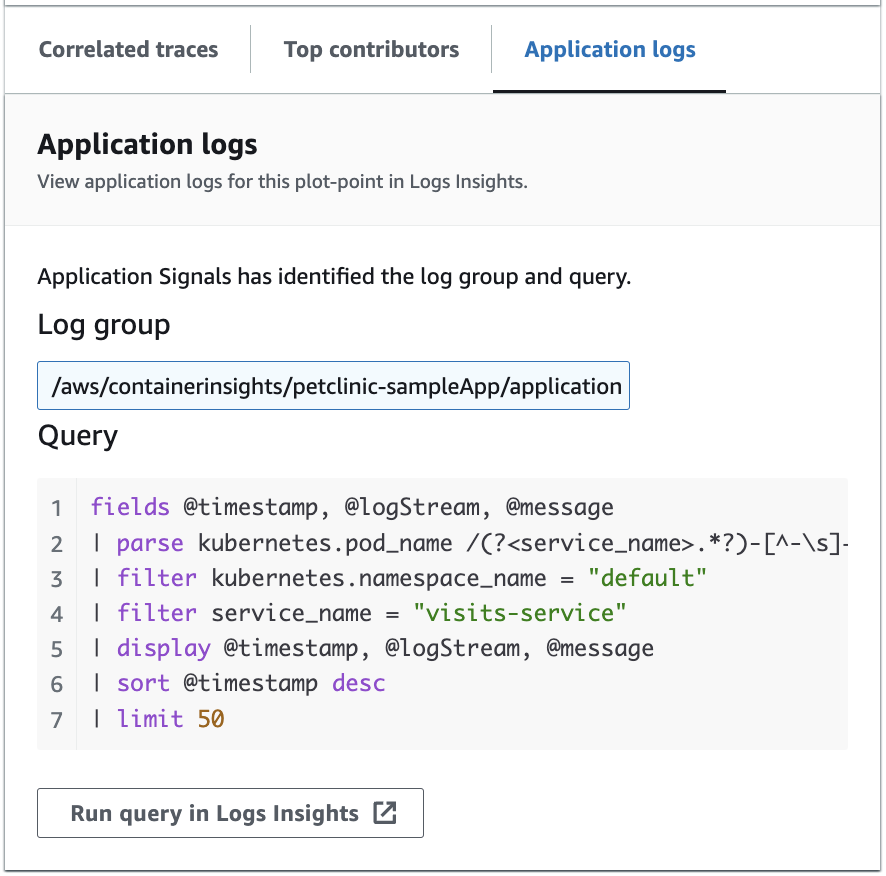
En la imagen anterior, CloudWatch detectó automáticamente el grupo de registro asociado al punto seleccionado y lo incluyó en una consulta generada.
Visualización de las dependencias de servicio
Elija la pestaña Dependencias para ver la tabla de Dependencias y un conjunto de métricas para las dependencias de todas las operaciones del servicio o de una sola operación. La tabla contiene una lista de las dependencias detectadas por Application Signals, incluidas las métricas del estado del SLI, latencia, volumen de llamadas, tasa de fallos, tasa de errores y disponibilidad.
En la parte superior de la página, elija una operación de la lista desplegable para ver sus dependencias o elija Todo para ver las dependencias de todas las operaciones.
Filtre la tabla para que le resulte más fácil encontrar lo que busca, al seleccionar una o más propiedades del cuadro de texto del filtro. Al elegir cada propiedad, se lo guiará por los criterios de filtro y verá el filtro completo debajo del cuadro de texto del filtro. Elija Borrar filtros en cualquier momento para eliminar el filtro de la tabla. Seleccione Agrupar por dependencia en la parte superior derecha de la tabla para agrupar las dependencias por nombre de servicio y operación. Cuando la agrupación esté activada, expanda o contraiga un grupo de dependencias con el icono + situado junto al nombre de la dependencia.
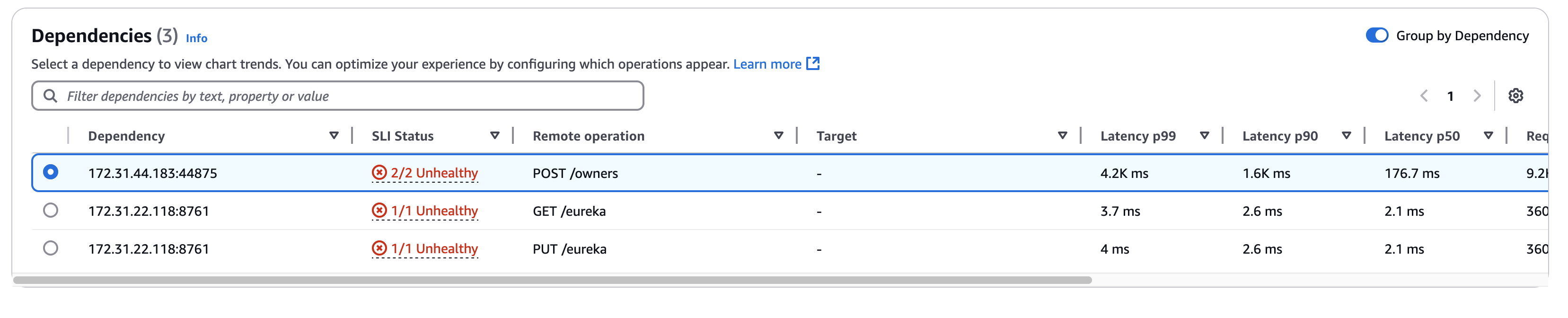
La columna Dependencia muestra el nombre del servicio de dependencia, mientras que la columna Operación remota muestra el nombre de la operación del servicio. En la columna Estado del SLI se muestra el número de SLI en buen estado o en mal estado junto con el número total de SLI para cada dependencia. Al llamar a los servicios de AWS, la columna Destino muestra el recurso de AWS, como una tabla de DynamoDB o una cola de Amazon SNS.
Para seleccionar una dependencia, seleccione la opción situada junto a una dependencia en la tabla de Dependencias. Esto muestra un conjunto de gráficos que muestran métricas detalladas de volumen de llamadas, disponibilidad, fallas y errores. Coloque el cursor sobre un punto en un gráfico para ver una ventana emergente con más información. Seleccione un punto de un gráfico para abrir un panel de diagnóstico que muestre los seguimientos correlacionados del punto seleccionado en el gráfico. Elija un ID de seguimiento de la tabla Seguimientos correlacionados para abrir la página Detalles del seguimiento de X-Ray para el seguimiento elegido.
Visualización de los valores controlados de Synthetics
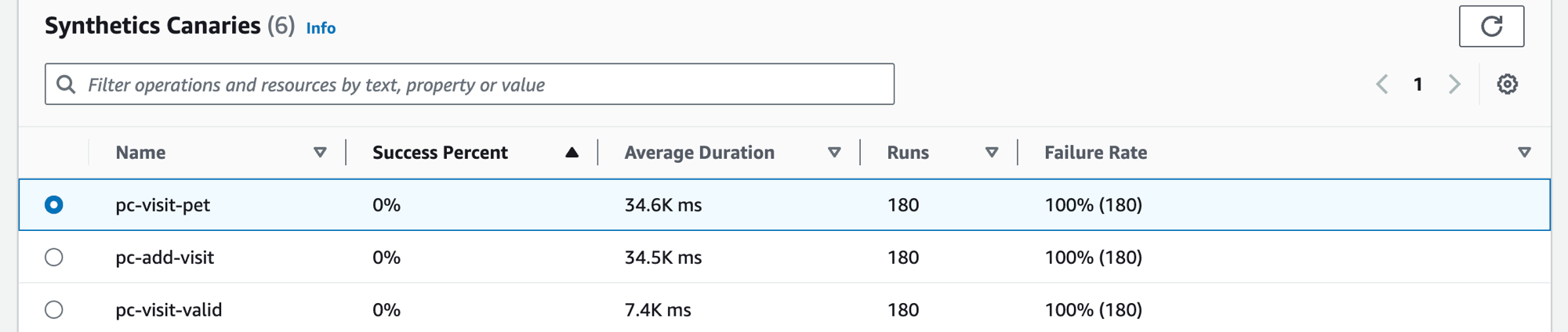
Seleccione la pestaña Valores controlados de Synthetics para ver la tabla Valores controlados de Synthetics y un conjunto de métricas para cada valor controlado de la tabla. La tabla incluye métricas del porcentaje de éxito, la duración promedio, las ejecuciones y la tasa de fallos. Solo se muestran los valores controlados que están habilitados para el seguimiento de AWS X-Ray.
Utilice el cuadro de texto del filtro de la tabla de canarios de Synthetics para encontrar el canario que le interese. Cada filtro que crea aparece debajo del cuadro de texto del filtro. Elija Borrar filtros en cualquier momento para eliminar el filtro de la tabla.
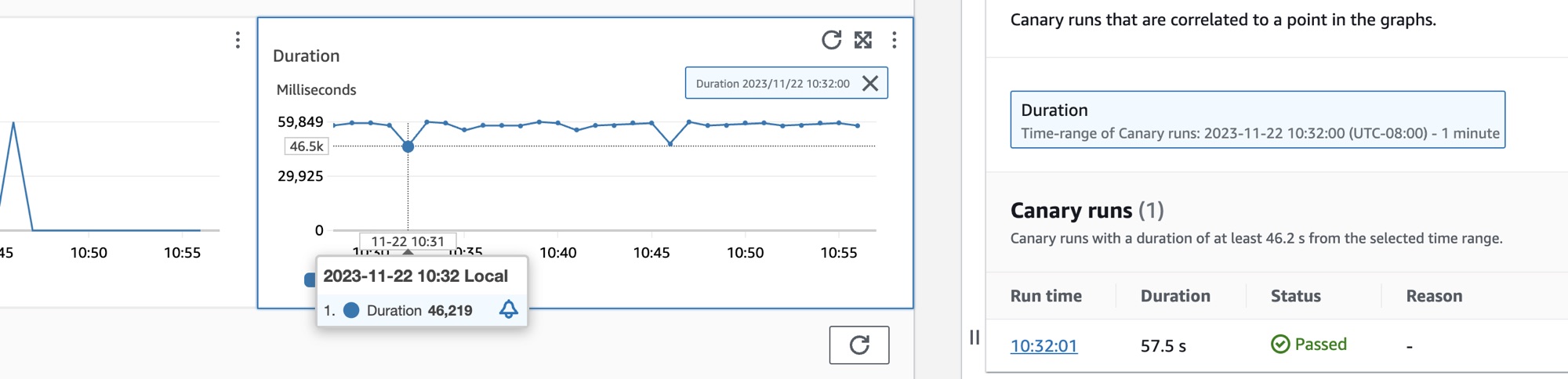
Seleccione el botón de radio situado junto al nombre del canario para ver un conjunto de pestañas que contienen métricas detalladas con gráficos, como el porcentaje de éxito, los errores y la duración. Coloque el cursor sobre un punto en un gráfico para ver una ventana emergente con más información. Seleccione un punto de un gráfico para abrir un panel de diagnóstico que muestre las ejecuciones de canario que se correlacionan con el punto seleccionado. Seleccione una ejecución de canario y elija el tiempo de ejecución para ver los artefactos de la ejecución de canario que seleccionó, incluidos los registros, los archivos HTTP (HAR), las capturas de pantalla y los pasos sugeridos para ayudarlo a solucionar problemas. Seleccione Más información para abrir la página Canarios de CloudWatch Synthetics junto a Ejecuciones de canarios.
Visualización de las páginas de sus clientes
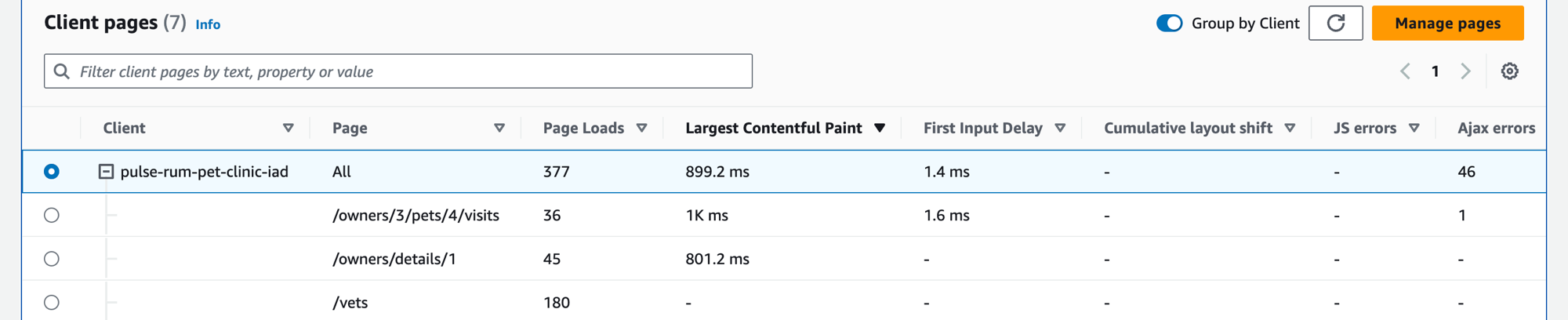
Seleccione la pestaña Páginas de clientes para ver una lista de las páginas web de clientes que llaman a su servicio. Utilice el conjunto de métricas de la página de cliente seleccionada para medir la calidad de la experiencia de su cliente al interactuar con un servicio o una aplicación. Estas métricas incluyen las cargas de página, las métricas esenciales de la web y los errores.
Para mostrar las páginas de sus clientes en la tabla, debe configurar su cliente web de CloudWatch RUM para el seguimiento de X-Ray y activar las métricas de Application Signals para las páginas de los clientes. Elija Administrar páginas para seleccionar qué páginas están habilitadas para las métricas de Application Signals.
Utilice el cuadro de texto del filtro para buscar la página del cliente o el monitor de aplicaciones que le interese debajo del cuadro de texto del filtro. Elija Borrar filtros para eliminar el filtro de la tabla. Seleccione Agrupar por cliente para agrupar las páginas de los clientes por cliente. Cuando estén agrupadas, seleccione el icono + situado junto al nombre del cliente para expandir la fila y ver todas las páginas de ese cliente.
Para seleccionar una página de cliente, seleccione la opción situada junto a una página del cliente en la tabla Páginas de clientes. Verá un conjunto de gráficos que muestran métricas detalladas. Coloque el cursor sobre un punto en un gráfico para ver una ventana emergente con más información. Seleccione un punto de un gráfico para abrir un panel de diagnóstico que muestre los eventos de navegación de rendimiento correlacionados del punto seleccionado en el gráfico. Elija un ID de evento de la lista de eventos de navegación para abrir la vista de la página de CloudWatch RUM para el evento elegido.
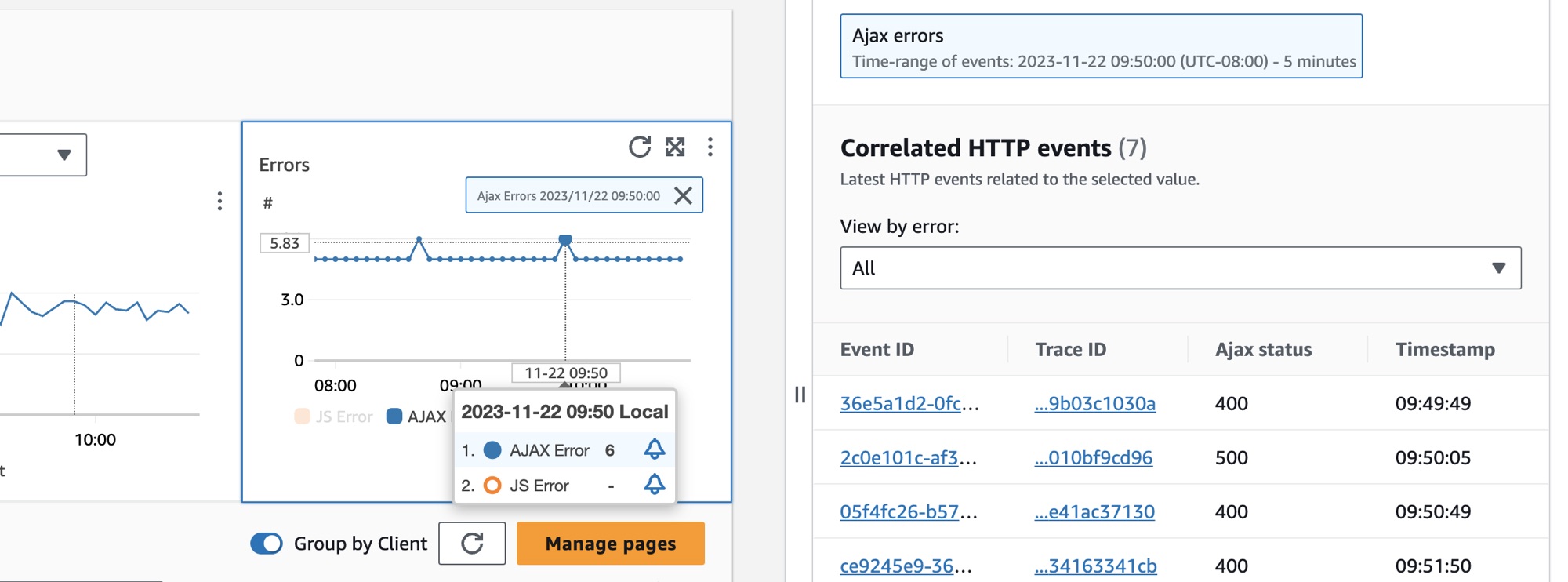
nota
Para ver los errores AJAX en las páginas de sus clientes, utilice la versión 1.15 de cliente web de CloudWatch RUM o posterior.
Se pueden mostrar hasta 100 operaciones, canarios y páginas de clientes, y hasta 250 dependencias por servicio.
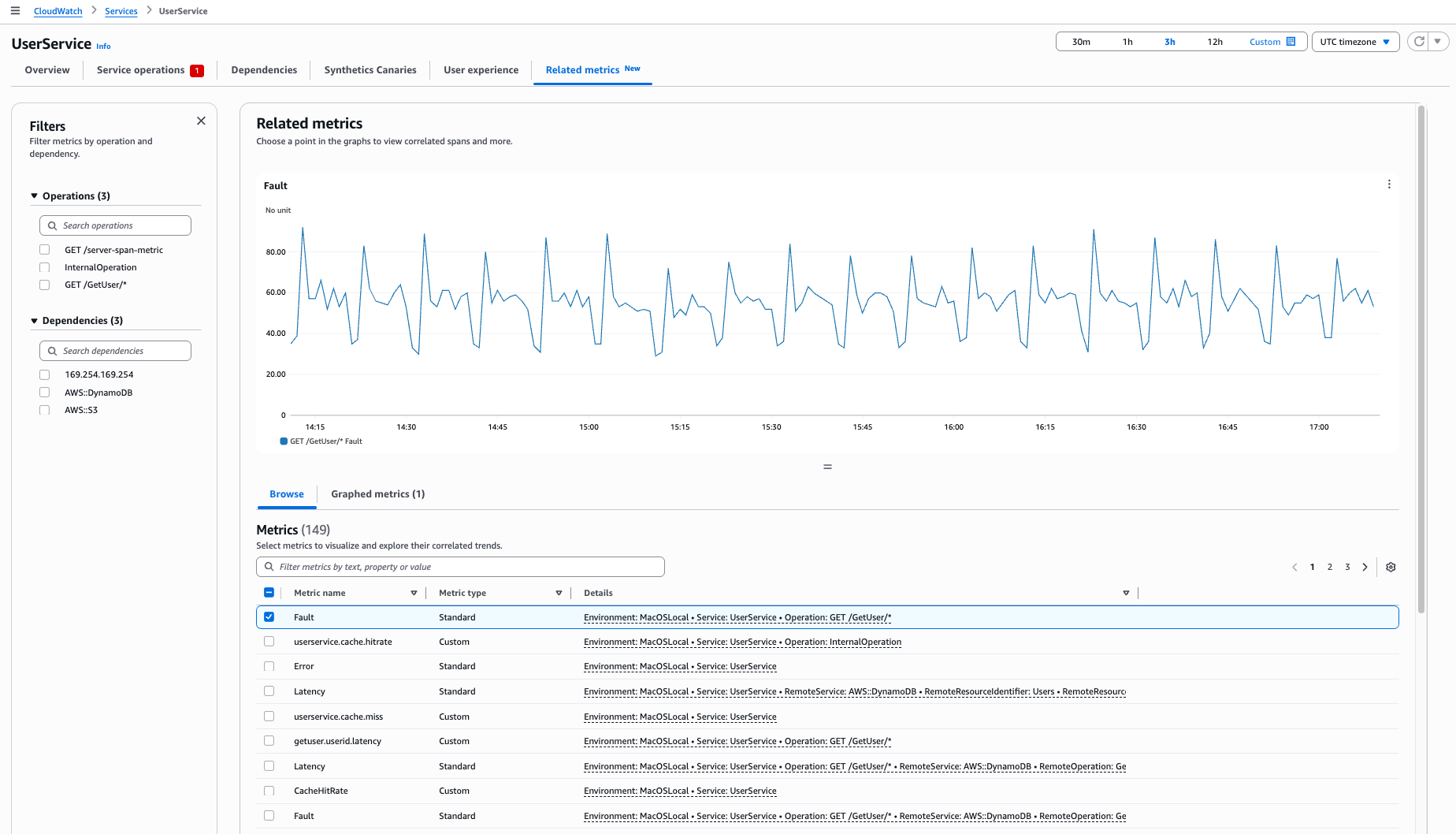
Visualización de métricas relacionadas
Use la pestaña Métricas relacionadas para ver varias métricas, identificar los patrones de correlación y determinar las causas raíz de los problemas.
La tabla de métricas muestra tres tipos de métricas:
Métricas estándar: Application Signals recopila métricas de aplicaciones estándar a partir de los servicios que detecta. Para obtener más información, consulte Recopilación de métricas de aplicaciones estándar.
Métricas de tiempo de ejecución: Application Signals utiliza el SDK de AWS Distro para OpenTelemetry para recopilar automáticamente métricas compatibles con OpenTelemetry de las aplicaciones en Java y Python. Para obtener más información, consulte Métricas de tiempo de ejecución.
Métricas personalizadas: Application Signals le permite generar métricas personalizadas a partir de su aplicación. Para obtener más información, consulte Métricas personalizadas con Application Signals
Puede acceder a la pestaña Métricas relacionadas desde las pestañas Descripción general del servicio, Operaciones de servicio, Dependencias, Canarios de Synthetics o RUM.
-
El panel de navegación izquierdo comienza con todas las operaciones y dependencias sin seleccionar.
-
El gráfico muestra inicialmente la métrica de errores de la operación con la tasa de errores más alta.
Antes de comenzar el análisis de correlación, asegúrese de que los puntos de datos se puedan ver en Operaciones de servicio o Dependencias. Para analizar las correlaciones, haga lo siguiente:
Abra la página Operaciones de servicio o Dependencias.
Seleccione un punto de datos en cualquier gráfico.
En el panel derecho, elija Correlacionar con otras métricas.
En la pestaña Métricas relacionadas que se abre, verá lo siguiente:
La operación o dependencia seleccionada en el menú de navegación de la izquierda
La métrica seleccionada que se muestra en un gráfico en la tabla Examinar las métricas
Intervalos correlacionados al seleccionar un punto de datos
Para incluir varias métricas en un gráfico, seleccione una o más métricas en la vista Explorar de la pestaña Métricas relacionadas. Elija Métricas diagramadas para ver todas las métricas incluidas en gráficos.
Para filtrar las métricas, utilice los filtros del panel izquierdo para centrarse en operaciones o dependencias específicas y utilice la barra de filtros del encabezado de la tabla para buscar por nombre, tipo u otros atributos. Estas opciones de filtrado le ayudan a detectar patrones y solucionar problemas de forma más eficaz.
Para analizar las métricas relacionadas en detalle, seleccione un punto de datos en la pestaña Métricas relacionadas. A continuación, puede ver lo siguiente:
Colaboradores principales: analiza métricas mediante la ejecución de consultas de Información de registros de CloudWatch. Estas consultas procesan los registros del formato de métricas mejorado (EMF) que contienen atributos clave para un análisis detallado de los siguientes aspectos:
Mediciones de latencia
Incidencias de errores
Métricas de disponibilidad de servicio
Las métricas siguientes no admiten colaboradores principales:
Métricas de OTEL
Métricas de intervalos en el servidor
Puede ver los colaboradores principales de Métricas de RED y Métricas de intervalos en el cliente.
Intervalos correlacionados: la sección Intervalos correlacionados funciona de forma coherente con la pestaña Operaciones de servicio. Para ayudarle a identificar los seguimientos y métricas relacionadas, el mecanismo de correlación funciona de la siguiente manera:
Compara los nombres de las métricas con los atributos de intervalo.
Identifica los patrones coincidentes durante el periodo de tiempo seleccionado.
Muestra información de seguimiento relevante.
Para analizar de forma eficaz las métricas y los intervalos a la vez, debe comprender cómo se correlacionan los distintos tipos de métricas. Estas son las limitaciones clave:
Las métricas de OTEL no se correlacionan con los intervalos porque utilizan sistemas de nomenclatura independientes.
Para correlacionar las métricas de intervalo en el servidor o en el cliente con los intervalos:
Incluya un campo de dimensión del servicio en su configuración.
Sin esta dimensión de servicio, no puede correlacionar estas métricas con los intervalos.
Registrar aplicaciones: para obtener información sobre cómo registrar una aplicación, consulte Registros de aplicaciones.
