Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Leitfaden zur Integration
Die gesamte Lösung ist so konzipiert, dass sie leicht erweiterbar ist. Die Orchestrierungsebene dieser Lösung basiert auf. LangChain
Erweiterung wird unterstützt LLMs
Um einen weiteren Modellanbieter hinzuzufügen, z. B. einen benutzerdefinierten LLM-Anbieter, müssen Sie die folgenden drei Komponenten der Lösung aktualisieren:
-
Erstellen Sie einen neuen
TextUseCaseCDK-Stack, der die mit Ihrem benutzerdefinierten LLM-Anbieter konfigurierte Chat-Anwendung bereitstellt:-
Klonen Sie das GitHub Repository
dieser Lösung und richten Sie Ihre Build-Umgebung ein, indem Sie den Anweisungen in der Datei README.md folgen. -
Kopieren Sie die
source/infrastructure/lib/bedrock-chat-stack.tsDatei (oder erstellen Sie eine neue), fügen Sie sie in dasselbe Verzeichnis ein und benennen Sie sie um.custom-chat-stack.ts -
Benennen Sie die Klasse in der Datei in eine geeignete um, z.
CustomLLMChatB. -
Sie können diesem Stack ein Secrets Manager Manager-Geheimnis hinzufügen, in dem Ihre Anmeldeinformationen für Ihr benutzerdefiniertes LLM gespeichert werden. Sie können diese Anmeldeinformationen während des Modellaufrufs in der Chat-Lambda-Schicht abrufen, die im nächsten Absatz beschrieben wird.
-
-
Erstellen Sie eine Lambda-Schicht, die die Python-Bibliothek des hinzuzufügenden Modellanbieters enthält, und hängen Sie sie an. Für eine Chat-Anwendung für Amazon Bedrock-Anwendungsfälle enthält die
langchain-awsPython-Bibliothek die benutzerdefinierten Konnektoren zusätzlich zum LangChain Paket, um eine Verbindung zu den AWS-Modellanbietern (Amazon Bedrock und SageMaker KI), Wissensdatenbanken (Amazon Kendra und Amazon Bedrock Knowledge Bases) und Speichertypen (wie DynamoDB) herzustellen. In ähnlicher Weise haben andere Modellanbieter ihre eigenen Konnektoren. Diese Ebene hilft Ihnen, die Python-Bibliothek dieses Modellanbieters anzuhängen, sodass Sie diese Konnektoren in der Chat-Lambda-Schicht verwenden können, die das LLM aufruft (Schritt 3). In dieser Lösung wird ein benutzerdefinierter Asset-Bundler verwendet, um Lambda-Schichten zu erstellen, die mithilfe von CDK-Aspekten angehängt werden. So erstellen Sie eine neue Ebene für die Bibliothek des Anbieters benutzerdefinierter Modelle:-
Navigieren Sie zu der
LambdaAspectsKlasse in dersource/infrastructure/lib/utils/lambda-aspects.tsDatei. -
Folgen Sie den Anweisungen zur Erweiterung der Funktionalität der Lambda-Aspects-Klasse in der Datei (z. B. zum Hinzufügen der
getOrCreateLangchainLayerMethode). Um diese neue Methode zu verwenden (zum BeispielgetOrCreateCustomLLMLayer), aktualisieren Sie auch dieLLM_LIBRARY_LAYER_TYPESAufzählung in dersource/infrastructure/lib/utils/constants.tsDatei.
-
-
Erweitern Sie die
chatLambda-Funktion, um einen Builder, einen Client und einen Handler für den neuen Anbieter zu implementieren.Die
source/lambda/chatenthält die LangChain Verbindungen für verschiedene LLMs sowie die unterstützenden Klassen, um diese LLMs zu erstellen. Diese unterstützenden Klassen folgen den Entwurfsmustern von Builder und Object Oriented, um das LLM zu erstellen.Jeder Handler (z. B.
bedrock_handler.py) erstellt zuerst einen Client, überprüft die Umgebung auf erforderliche Umgebungsvariablen und ruft dann eineget_modelMethode auf, um die LangChain LLM-Klasse abzurufen. Die Methode generate wird dann aufgerufen, um das LLM aufzurufen und seine Antwort abzurufen. LangChain unterstützt derzeit Streaming-Funktionen für Amazon Bedrock, aber nicht SageMaker KI. Je nach Streaming- oder Nicht-Streaming-Funktionalität wird der entsprechende WebSocket Handler (WebsocketStreamingCallbackHandleroderWebsocketHandler) aufgerufen, um die Antwort mithilfe der Methode an die WebSocket Verbindung zurückzuschicken.post_to_connectionDer
clients/builderOrdner enthält die Klassen, die beim Erstellen eines LLM Builders mithilfe des Builder-Musters helfen. Zunächstuse_case_configwird a aus einem DynamoDB-Konfigurationsspeicher abgerufen, in dem die Details darüber gespeichert werden, welche Art von Wissensdatenbank, Konversationsspeicher und Modell erstellt werden sollen. Es enthält auch relevante Modelldetails wie Modellparameter und Eingabeaufforderungen. Der Builder hilft Ihnen dann dabei, die Schritte zum Erstellen einer Wissensdatenbank, zum Erstellen eines Konversationsspeichers zur Aufrechterhaltung des Konversationskontextes für LLM, zum Einstellen der entsprechenden LangChain Callbacks für Streaming- und Nicht-Streaming-Fälle und zum Erstellen eines LLM-Modells auf der Grundlage der bereitgestellten Modellkonfigurationen zu befolgen. Die DynamoDB-Konfiguration wird zum Zeitpunkt der Anwendungsfallerstellung gespeichert, wenn Sie einen Anwendungsfall über das Deployment-Dashboard bereitstellen (oder wenn er von den Benutzern in eigenständigen Anwendungsfall-Stack-Bereitstellungen ohne das Deployment-Dashboard bereitgestellt wird).Der
clients/factoriesUnterordner hilft bei der Festlegung des geeigneten Konversationsspeichers und der Wissensdatenbankklasse auf der Grundlage der LLM-Konfiguration. Dies ermöglicht eine einfache Erweiterung auf alle anderen Wissensdatenbanken oder Speichertypen, die Ihre Implementierung unterstützen soll.Der
sharedUnterordner enthält spezifische Implementierungen von Knowledge Base und Conversation Memory, die vom Builder innerhalb der Factories instanziiert werden. Es enthält auch Amazon Kendra- und Amazon Bedrock Knowledge Base-Retriever, die innerhalb aufgerufen werden, LangChain um Dokumente für die RAG-Anwendungsfälle abzurufen, sowie Callbacks, die vom LLM-Modell verwendet werden. LangChainDie LangChain Implementierungen verwenden LangChain Expression Language (LCEL), um Konversationsketten gemeinsam zu erstellen.
RunnableWithMessageHistoryclass wird verwendet, um den Konversationsverlauf mit benutzerdefinierten LCEL-Ketten zu verwalten, sodass Funktionen wie das Zurücksenden von Quelldokumenten und die Verwendung der an die Wissensdatenbank gesendeten umformulierten (oder unmissverständlichen) Frage auch an das LLM gesendet werden können.Um Ihre eigene Implementierung eines benutzerdefinierten Anbieters zu erstellen, können Sie:
-
Kopieren Sie die
bedrock_handler.pyDatei und erstellen Sie Ihren benutzerdefinierten Handler (z. B.custom_handler.py), der Ihren benutzerdefinierten Client erstellt (z. B.CustomProviderClient) (wie im folgenden Schritt angegeben). -
Kopieren Sie
bedrock_client.pyin den Client-Ordner. Benennen Sie es um incustom_provider_client.py(oder Ihren spezifischen Modellanbieternamen, z. B.CustomProvider). Benennen Sie die darin enthaltene Klasse entsprechend, z. B.CustomProviderClientwelche erbtLLMChatClient.Sie können die von bereitgestellten Methoden verwenden
LLMChatClientoder Ihre eigenen Implementierungen schreiben, um diese zu überschreiben.Die
get_modelMethode erstellt eineCustomProviderBuilder(siehe den folgenden Schritt) und ruft dieconstruct_chat_modelMethode auf, die das Chat-Modell mithilfe von Builder-Schritten erstellt. Diese Methode fungiert im Builder-Muster als Director. -
Kopieren Sie es
clients/builders/bedrock_builder.pyund benennen Sie es umcustom_provider_builder.pyund die darin enthaltene Klasse in die KlasseCustomProviderBuilder, die erbt LLMBuilder (llm_builder.py). Sie können die von bereitgestellten Methoden verwenden LLMBuilder oder Ihre eigenen Implementierungen schreiben, um diese zu überschreiben. Die Builder-Schritte werden nacheinander innerhalb derconstruct_chat_modelMethode des Clients aufgerufen, z. B.set_model_defaultsset_knowledge_base, undset_conversation_memory.Die
set_llm_modelMethode würde das eigentliche LLM-Modell unter Verwendung aller Werte erstellen, die mit den zuvor aufgerufenen Methoden festgelegt wurden. Insbesondere können Sie ein RAG (CustomProviderRetrievalLLM) oder ein LLM ohne RAG (CustomProviderLLM) erstellen, das auf dem basiert, was aus derrag_enabled variableLLM-Konfiguration in DynamoDB abgerufen wurde.Diese Konfiguration wird in der Methode in der Klasse abgerufen.
retrieve_use_case_configLLMChatClient -
Implementieren Sie Ihre
CustomProviderLLModerCustomProviderRetrievalLLM-Implementierung imllm_modelsUnterordner, je nachdem, ob Sie einen RAG-Anwendungsfall oder einen anderen Anwendungsfall benötigen. Die meisten Funktionen zur Implementierung dieser Modelle werden in ihren jeweiligenRetrievalLLMKlassen fürBaseLangChainModelAnwendungsfälle bereitgestellt, die nicht von RAG und RAG stammen.Sie können die
llm_models/bedrock.pyDatei kopieren und die erforderlichen Änderungen vornehmen, um das LangChain Modell aufzurufen, das sich auf Ihren benutzerdefinierten Anbieter bezieht. Amazon Bedrock verwendet beispielsweise eineChatBedrockKlasse, um ein Chat-Modell mithilfe von LangChain zu erstellen.Die Generate-Methode generiert die LLM-Antwort mithilfe der LangChain LCEL-Ketten.
Sie können die
get_clean_model_paramsMethode auch verwenden, um die Modellparameter gemäß LangChain Ihren Modellanforderungen zu bereinigen.
-
Erweiterung der unterstützten Tools von Strands
Mit der Lösung können Sie MCP-Server, KI-Agenten und Multi-Agent-Workflows erstellen und bereitstellen. Im Rahmen von Agent Builder können Sie MCP-Server anhängen, um Ihren Agenten zusätzliche Funktionen zu bieten. Zusätzlich zu den MCP-Servern können Sie die integrierten Tools von Strands
Die Lösung ist standardmäßig mit den folgenden Strons-Tools vorkonfiguriert:
-
Aktuelle Uhrzeit (standardmäßig aktiviert)
-
Taschenrechner (standardmäßig aktiviert)
-
Umgebung
Auswahl des MCP-Servers und der Tools im Agent Builder-Assistenten mit integrierten Strands Tools

Um Ihre Agenten um zusätzliche Strons-Tools zu erweitern, folgen Sie dem in diesem Abschnitt beschriebenen vierstufigen Prozess.
Schritt 1: Finden Sie das Strans-Tool
Durchsuchen Sie die verfügbaren Strands Tools
Schritt 2: Aktualisieren Sie den SSM-Parameter
Um ein Tool in der Agent Builder-Bereitstellungsoberfläche verfügbar zu machen, aktualisieren Sie den AWS Systems Manager Parameter Store, der definiert, welche Strons-Tools unterstützt werden.
-
Navigieren Sie in Ihrem AWS-Konto zum AWS Systems Manager Parameter Store.
-
Suchen Sie den Parameter:
/gaab/<stack-name>/strands-tools -
Fügen Sie Ihre Werkzeugkonfiguration mithilfe der folgenden JSON-Struktur am Ende der vorhandenen Liste hinzu:
{ "name": "Bedrock KB Retrieve", "description": "Retrieve information from Bedrock Knowledge Base", "value": "retrieve", "category": "AI", "isDefault": false }Feld Description name
Anzeigename, der in der Agent Builder-Benutzeroberfläche angezeigt wird
description
Kurze Beschreibung der Funktionen des Tools
value
Der genaue Werkzeugname, wie er im Strands Tool-Paket definiert ist
category
Organisatorische Kategorie für die Gruppierung von Tools in der Benutzeroberfläche
ist Standard
Ob das Tool standardmäßig für neue Agenten aktiviert werden soll
Schritt 3: Umgebungsvariablen konfigurieren
Viele Strands-Tools benötigen Umgebungsvariablen für die Konfiguration. Sie können diese Variablen auf zwei Arten setzen:
Option 1: Direkte Konfiguration zur AgentCore Laufzeit
Aktualisieren Sie den bereitgestellten Agenten direkt auf Amazon Bedrock AgentCore Runtime mit den erforderlichen Umgebungsvariablen.
Option 2: Modellparameter im Bereitstellungsassistenten
Fügen Sie während des Schritts zur Modellauswahl im Agent Builder-Assistenten Umgebungsvariablen hinzu. Verwenden Sie dazu den Abschnitt Modellparameter. Umgebungsvariablen, die der Namenskonvention ENV_<ALL_CAPS_TOOL_NAME>_<env_variable_name> folgen, werden zur Laufzeit automatisch in die Ausführungsumgebung des Agenten geladen als<env_variable_name>.
Beispiel:
-
ENV_RETRIEVE_KNOWLEDGE_BASE_IDwirdKNOWLEDGE_BASE_ID -
ENV_RETRIEVE_MIN_SCOREwirdMIN_SCORE
Abschnitt mit erweiterten Modellparametern, der die ENV_RETRIEVE_KNOWLEDGE_BASE_ID-Konfiguration zeigt

Informationen zu den erforderlichen Umgebungsvariablen finden Sie in der Dokumentation oder im Quellcode des jeweiligen Tools. Für das Tool zum Abrufen finden Sie die Konfigurationsoptionen im Quellcode
Schritt 4: Fügen Sie IAM-Berechtigungen hinzu
Fügen Sie Ihrer AgentCore Runtime-Ausführungsrolle manuell alle erforderlichen IAM-Berechtigungen hinzu, damit der Agent das Tool verwenden kann.
Um beispielsweise das Abruftool mit Amazon Bedrock Knowledge Bases zu verwenden:
-
Navigieren Sie in Ihrem AWS-Konto zur IAM-Konsole.
-
Suchen Sie die AgentCore Runtime-Ausführungsrolle für Ihren Agenten.
-
Fügen Sie die folgende Berechtigung hinzu:
{ "Effect": "Allow", "Action": "bedrock:Retrieve", "Resource": "arn:aws:bedrock:region:account-id:knowledge-base/knowledge-base-id" }
Die IAM-Konsole zeigt die StrandsRetrieveTool KBAccess Richtlinie an, die der AgentCore Runtime-Ausführungsrolle zugeordnet ist

Welche spezifischen Berechtigungen erforderlich sind, hängt vom jeweiligen Tool ab. Schlagen Sie in der Dokumentation des Tools und in der AWS-Servicedokumentation nach, um die entsprechenden IAM-Berechtigungen zu ermitteln.
Schritt 5: Testen Sie den Agenten
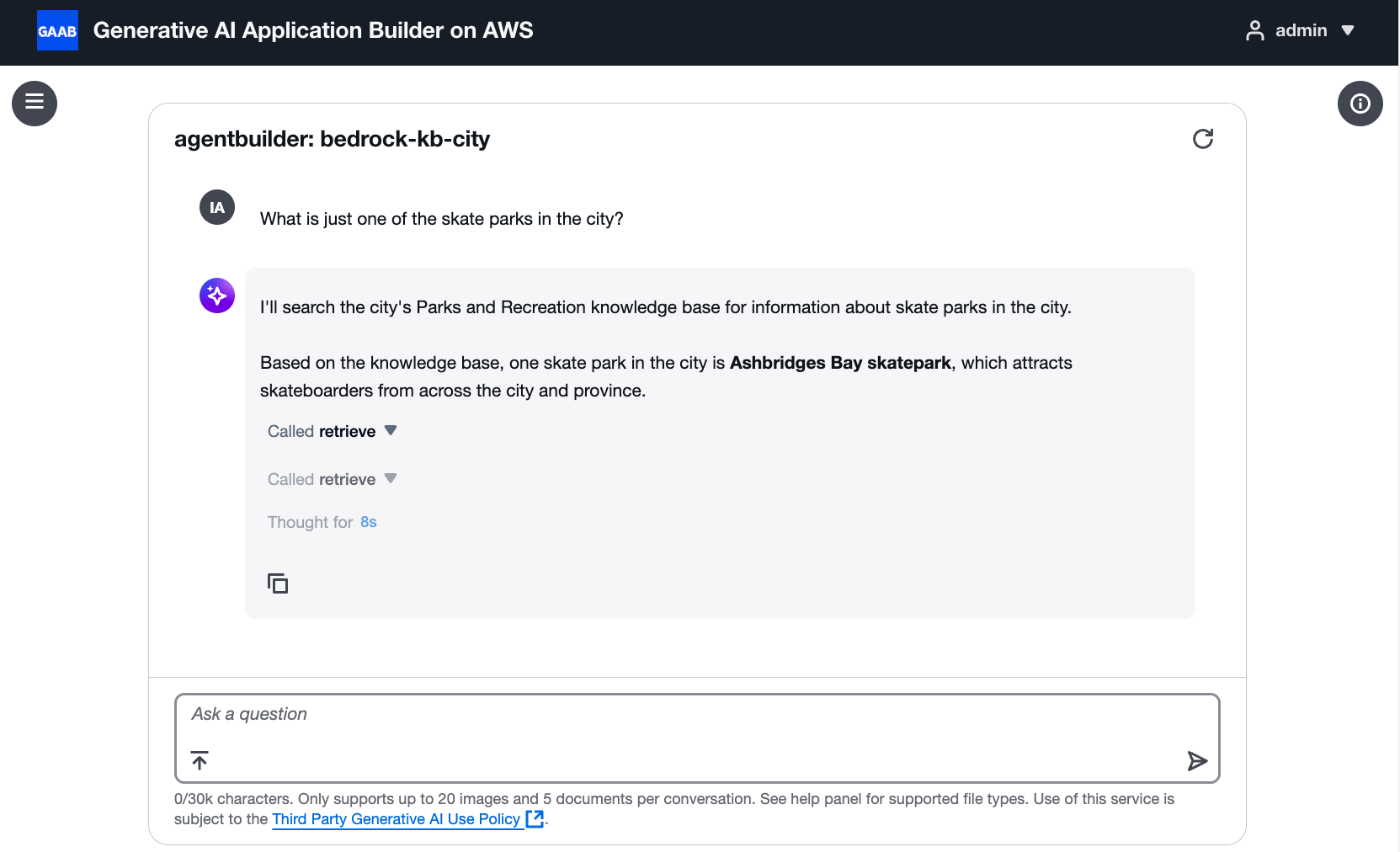
Nachdem Sie die Konfigurationsschritte abgeschlossen haben, testen Sie Ihren Agenten, um sicherzustellen, dass das Tool ordnungsgemäß funktioniert. Sie sollten die Tool-Aufrufe in den Ausführungsprotokollen und Antworten des Agenten sehen.
Der Agent verwendet erfolgreich das Retrieve-Tool, um eine Frage zu Skateparks zu beantworten
Anmerkung
Eine vollständige Liste der verfügbaren Strands-Tools und ihrer Funktionen finden Sie in der Dokumentation zu den Strands Community Tools
Erweiterung der unterstützten Wissensdatenbanken und Typen von Konversationsspeichern
Um Ihre Implementierungen von Conversation Memory oder Knowledge Base hinzuzufügen, fügen Sie die erforderlichen Implementierungen im shared Ordner hinzu und bearbeiten Sie dann die Factories und die entsprechenden Aufzählungen, um eine Instanz dieser Klassen zu erstellen.
Wenn Sie die LLM-Konfiguration angeben, die im Parameterspeicher gespeichert ist, werden der entsprechende Konversationsspeicher und die entsprechende Wissensdatenbank für Ihr LLM erstellt. Wenn zum Beispiel für DynamoDB angegeben ConversationMemoryType ist, wird eine Instanz von DynamoDBChatMessageHistory (available insideshared_components/memory/ddb_enhanced_message_history.py) erstellt. Wenn Amazon Kendra angegeben KnowledgeBaseType ist, wird eine Instanz von KendraKnowledgeBase (innerhalb verfügbarshared_components/knowledge/kendra_knowledge_base.py) erstellt.
Erstellung und Bereitstellung der Codeänderungen
Erstellen Sie das Programm mit dem npm run build Befehl. Sobald alle Fehler behoben sind, führen Sie den Befehl aus, cdk synth um die Vorlagendateien und alle Lambda-Assets zu generieren.
-
Sie können das
–0—/stage-assets.shSkript verwenden, um alle generierten Assets manuell im Staging-Bucket in Ihrem Konto bereitzustellen. -
Verwenden Sie den folgenden Befehl, um die Plattform bereitzustellen oder zu aktualisieren:
cdk deploy DeploymentPlatformStack --parameters AdminUserEmail='admin-email@amazon.com'Alle zusätzlichen CloudFormation AWS-Parameter sollten ebenfalls zusammen mit dem AdminUserEmailParameter angegeben werden.
