Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwaltung von Datenquellen
Neben der automatisierten Wellenplanung ermöglicht das Wave Planning Manager (WPM) -Modul auch Viele-zu-Viele-Beziehungen beim Import. Mit dieser Funktion können Anwendungen auf vielen Servern bereitgestellt werden, und ein Server kann viele Anwendungen unterstützen.
Der Importvorgang ist anders und erfordert die Erstellung einer Datenquelle.
Datenquellen
Eine Datenquelle ist ein konfigurierter Eingabemechanismus im Wave Planning Module (WPM), der definiert, woher Ihre Migrationsdaten stammen und wie Ihre Eingabedatei bereits vorhandenen Ressourcen in CMF zugeordnet wird.
Um eine neue Datenquelle zu erstellen
-
Wählen Sie im Navigationsmenü Wave Planning > Datenquelle
-
Die Tabelle zeigt eine Liste der zuvor erstellten Datenquellen. Wählen Sie Hinzufügen
-
Füllen Sie die allgemeinen Einstellungen der Datenquelle aus und laden Sie die Eingabedatei mit den Daten hoch, die Sie importieren möchten
-
Sobald Sie Ihre Datei hochgeladen haben, erscheint der Bildschirm „Entitäten auswählen“. Wählen Sie im Drop-down-Menü die CMF-Entitäten aus, denen die Daten in der Datei zugeordnet sind. Wenn Sie eine Excel-Datei hochgeladen haben, können Sie mehrere Blätter verschiedenen CMF-Entitäten zuordnen. Das heißt, Blatt 1 könnte alle Ihre Server enthalten, Blatt 2 könnte alle Ihre Anwendungen enthalten usw.
-
-
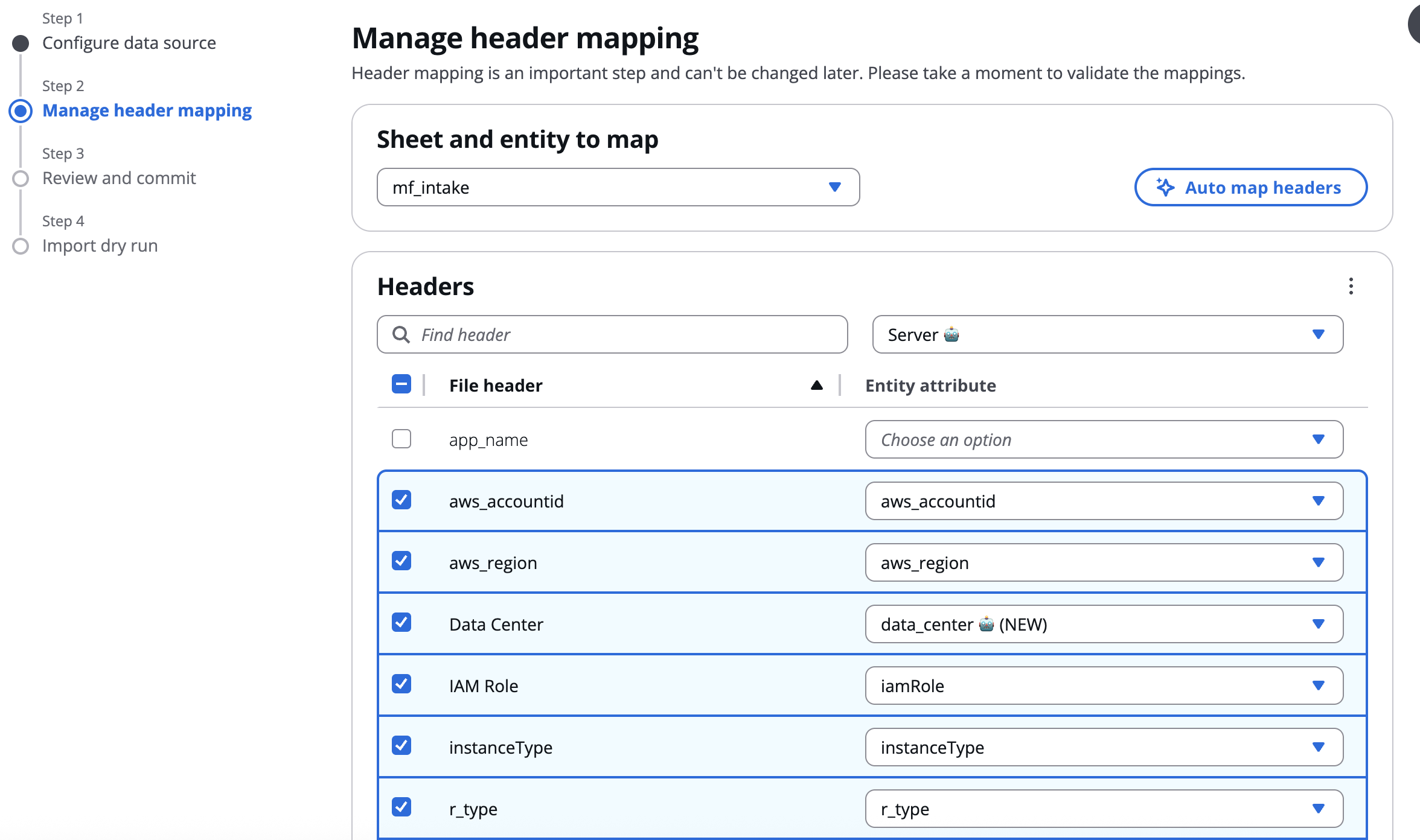
Der nächste Schritt beinhaltet die Zuordnung von Headern aus Ihrer Eingabedatei zu Schemaattributen für jede Entität, die Sie im vorherigen Schritt ausgewählt haben. Wählen Sie zunächst das Blatt aus, das Sie zuordnen möchten, und die Entität, der Sie zuordnen möchten. Anschließend können Sie jeden Header in Ihrer Quelldatei einem Schemaattribut zuordnen, indem Sie aus den Drop-down-Optionen eine Auswahl treffen
-
Weitere Informationen zur Funktionsweise der Header-Mapping finden Sie unter Header-Zuordnung
-
-
Der nächste Schritt ist der Überprüfungsbildschirm. Hier können Sie alle Eingabe-Header überprüfen und überprüfen, wie sie den einzelnen Entitäten in CMF zugeordnet sind. Darüber hinaus können Sie auch alle Schemaattribute sehen, die automatisch zusammen mit dieser Datenquelle erstellt werden. Hinweis: Sobald Sie diesen Schritt abgeschlossen haben, werden die Datenquellen- und Schemaattribute in CMF erstellt
-
Der letzte Bildschirm bietet die Möglichkeit, einen Testlauf für den Datenimport durchzuführen, um zu testen und zu überprüfen, was passiert, wenn Ihre neu erstellte Datenquelle während eines tatsächlichen Datenimports verwendet wird. Während dieses Schritts werden keine tatsächlichen Daten in CMF importiert. Sie können sehen, welche Entitäten erstellt worden wären, zusammen mit der Überprüfung, auf die errors/warnings CMF gestoßen wäre, wenn es sich um einen ordnungsgemäßen Datenimport gehandelt hätte. Sie können entweder zu den vorherigen Schritten im Assistenten zurückkehren, um weitere Aktualisierungen an der Datenquelle vorzunehmen, falls Fehler auftreten, oder Sie können den Assistenten speichern und schließen. Ihre Datenquelle steht nun anderen Benutzern zur Verfügung, um sie für tatsächliche Datenimportaufträge zu verwenden.
-
Wenn Sie bei der Überprüfung von Attributen, die die Eingabeanforderungen nicht erfüllen, auf Validierungsfehler stoßen, können Sie das Attribut in Ihrer Eingabedatei aktualisieren, um die Überprüfung und den erneuten Import zu bestehen. Falls dies nicht möglich ist, können Sie alternativ die Attributeinschränkungen in CMF aktualisieren (Administration > Attribute > {Schemaname} > {Attributname} > Bearbeiten > Eingabevalidierung). Beachten Sie, dass andere Funktionen in CMF beeinträchtigt werden können, wenn Sie dies für bereits vorhandene Attribute tun.
-
Header-Zuordnung
Eines der Hauptmerkmale von Datenquellen ist das Header-Mapping. Durch das Header-Mapping können Sie Ihre eigene Datei mit Ihren eigenen Header-Namen verwenden und diese dynamisch verwandten CMF-Entitätsschemaattributen zuordnen. Im Folgenden finden Sie eine Übersicht über einige der Funktionen, auf die Sie beim Header-Mapping stoßen können.
Automatische Zuordnung von Headern
Anmerkung
Diese Funktion erfordert Generative KI. Weitere Informationen darüber, ob sie aktiviert ist, finden Sie im Abschnitt Voraussetzungen des Bereitstellungsleitfadens.
Wenn Sie ein neues Blatt aus Ihrer Eingabedatei für den Import auswählen, wird die Schaltfläche Kopfzeilen automatisch zuordnen angezeigt.
WPM nutzt Generative KI, um zu versuchen, Ihre Eingabedatei-Header automatisch Entitätsschemaattributen zuzuordnen. Wenn es keine Übereinstimmung findet, empfiehlt es möglicherweise auch einen neuen Namen für das Schemaattribut, der zusammen mit der Datenquelle automatisch in der Entität erstellt werden kann. Wenn es eine Empfehlung gibt, wird am Ende 🤖 (NEW) angehängt
Warnung
Bitte beachten Sie, dass die generativen KI-Funktionen des Header-Mappings möglicherweise nicht immer zu 100% genau sind. Die Ergebnisse sollten von den Benutzern überprüft und validiert werden.
Schemaattribute automatisch erstellen
Verfügbare Entitätsattribute werden in der Drop-down-Liste aufgeführt, wenn die einzelnen Eingabe-Header zugeordnet werden. Wenn keine exakte Zuordnung gefunden wird, ist eine der Optionen der Header-Name, an dessen Ende (NEW) angehängt wird. Diese Option ist verfügbar, wenn Sie ein benutzerdefiniertes Attribut haben, das derzeit nicht in der CMF-Entität enthalten ist, die Sie zuordnen. Wenn Sie diese Option auswählen, wird das Attribut automatisch gleichzeitig mit der Datenquelle in der verknüpften Entität erstellt.
Datenimport
Sobald eine Datenquelle erstellt wurde, können Ressourcen in CMF importiert werden.
Um Daten zu importieren
-
Wählen Sie im Menü Wave Planning > Import aus.
-
Die Tabelle zeigt eine Liste von Datenimportaufträgen. Wählen Sie Hinzufügen aus.
-
Wählen Sie Ihre Datenquelle aus der Liste der Datenquellen aus. Wählen Sie Weiter aus.
-
Wählen Sie Datei auswählen.
-
Suchen Sie die lokale XLSX- oder CSV-Datei, die Ihre Ressourcen enthält. Diese Datei muss dieselben Spaltenüberschriften wie in der Datenquelle definiert haben. Wenn es sich um eine XLSX-Datei handelt, muss sie auch dieselben Blattnamen haben. Wählen Sie Weiter aus.
-
Wählen Sie die Registerkarte Validierungsprobleme, um alle Validierungswarnungen oder Fehler zu überprüfen. Wenn Aktualisierungen an Ihrer Importdatei erforderlich sind, wählen Sie Abbrechen.
-
Wählen Sie die Registerkarte Validierte Entitäten, um die Ressourcen zu überprüfen, die erstellt und aktualisiert werden. Wenn Aktualisierungen an Ihrer Importdatei erforderlich sind, wählen Sie Abbrechen. Klicken Sie andernfalls auf Next (Weiter).
-
Sehen Sie sich eine Zusammenfassung des Jobs an. Wenn Sie bereit sind, wählen Sie Daten importieren.
Sie werden zur Datenimportseite weitergeleitet. Es wird ein neuer Job mit dem Status Ausstehend erstellt.
Status des Datenimport-Jobs
Um eine große Anzahl von Ressourcen bei einem Datenimport zu unterstützen, handelt es sich um einen asynchronen Prozess. Der Status des Jobs kann auf der Seite Wave Planning > Import überwacht werden. In der folgenden Tabelle werden die Status eines Jobs detailliert beschrieben.
| Status | Definition |
|---|---|
|
Ausstehend |
Es wurde eine Job-Anfrage gestellt, aber der Server hat noch keine Ressourcen für die Verarbeitung zugewiesen. |
|
Verarbeitung |
Der Server verarbeitet derzeit den Import. |
|
Completed |
Der Server hat den Import abgeschlossen. Ressourcen wurden erfolgreich importiert. |
|
Fehlgeschlagen |
Der Server hat den Import abgeschlossen. Mindestens eine Ressource wurde nicht erfolgreich importiert. |
Um den Status eines Importauftrags zu überwachen
-
Wählen Sie im Menü Wave Planning > Import aus.
-
Suchen Sie in der Liste der Datenimportaufträge den Job, den Sie überwachen möchten. Sehen Sie sich die Spalte Status an. Warten Sie, bis der Status Abgeschlossen oder Fehlgeschlagen anzeigt.
-
Wählen Sie den zu überwachenden Importauftrag aus, indem Sie die Upload-ID auswählen.
-
Unter der Annahme, dass der Job den Status Abgeschlossen hatte, werden zwei Registerkarten angezeigt: Zusammenfassung und Verarbeitete Elemente. Wenn sich Ihr Job im Status Fehlgeschlagen befindet, finden Sie im folgenden Leitfaden Informationen zur Behebung eines fehlgeschlagenen Imports.
-
Wählen Sie die Registerkarte Zusammenfassung, um eine Übersicht über den Job zu erhalten.
-
Wählen Sie die Registerkarte Verarbeitete Elemente, um eine Liste aller Ressourcen anzuzeigen, die erfolgreich erstellt oder aktualisiert wurden.

Um einen fehlgeschlagenen Import zu beheben
-
Wählen Sie im Menü Wave Planning > Import aus.
-
Suchen Sie in der Liste der Datenimportaufträge den Auftrag „Fehlgeschlagen“. Wählen Sie die Upload-ID aus.
-
Wählen Sie den Tab Zusammenfassung, um eine Übersicht über den Job zu erhalten.
-
Wählen Sie die Registerkarte Verarbeitete Elemente, um eine Liste aller Ressourcen anzuzeigen, die erfolgreich erstellt oder aktualisiert wurden.
-
Wählen Sie die Registerkarte „Fehler beim Import von Elementen“, um eine Liste aller Ressourcen anzuzeigen, die nicht erfolgreich erstellt oder aktualisiert wurden. In der Tabelle wird der Fehler für jede Entität detailliert beschrieben.

Erforderliche Attribute im Vergleich zu optionalen Attributen
Wir haben die Anforderung für bestimmte Serverfelder wie Subnetz-IDs, AWS-Region und AWS-Konto-ID während des WPM-Imports entfernt, da diese Informationen während der ersten Wave-Planungsphase möglicherweise nicht verfügbar sind. Diese Felder sind jedoch für die Ausführung und Migration von Pipelines unerlässlich. Benutzer müssen sicherstellen, dass diese erforderlichen Attribute hinzugefügt und ordnungsgemäß konfiguriert wurden, bevor:
-
Ausführen einer beliebigen CMF-Pipeline
-
Durchführung der eigentlichen Migrationsaktivitäten
