Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konzepte der Modellparallelität
Modellparallelität ist eine verteilte Trainingsmethode, bei der das Deep-Learning-Modell (DL) auf mehrere GPUs und Instances aufgeteilt wird. Die SageMaker Model Parallel Library v2 (SMP v2) ist mit den nativen PyTorch APIs und Funktionen kompatibel. Auf diese Weise können Sie Ihr FSDP-Trainingsskript ( PyTorch Fully Sharded Data Parallel) bequem an die SageMaker Trainingsplattform anpassen und die Leistungsverbesserung nutzen, die SMP v2 bietet. Diese Einführungsseite bietet einen allgemeinen Überblick über die Modellparallelität und beschreibt, wie sie helfen kann, Probleme zu lösen, die beim Training von Deep-Learning-Modellen (DL), die in der Regel sehr groß sind, auftreten. Es enthält auch Beispiele dafür, was die SageMaker Modellparallel-Bibliothek bietet, um Modellparallelstrategien und Speicherverbrauch zu verwalten.
Was ist Modellparallelität?
Eine Erhöhung der Größe von Deep-Learning-Modellen (Ebenen und Parameter) führt zu einer besseren Genauigkeit bei komplexen Aufgaben wie Computer Vision und Verarbeitung natürlicher Sprache. Die maximale Modellgröße, die Sie in den Speicher einer einzelnen GPU passen können, ist jedoch begrenzt. Beim Training von DL-Modellen können GPU-Speicherbeschränkungen auf folgende Weise zu Engpässen führen:
-
Sie begrenzen die Größe des Modells, das Sie trainieren können, da der Speicherbedarf eines Modells proportional zur Anzahl der Parameter skaliert.
-
Sie begrenzen die Batchgröße pro GPU während des Trainings und verringern so die GPU-Auslastung und die Trainingseffizienz.
Um die Einschränkungen zu überwinden, die mit dem Training eines Modells auf einer einzelnen GPU verbunden sind, bietet SageMaker KI die Modellparallelbibliothek, mit der DL-Modelle effizient auf mehreren Rechenknoten verteilt und trainiert werden können. Darüber hinaus können Sie mit der Bibliothek ein optimiertes verteiltes Training mithilfe von EFA-supported Geräten erreichen, die die Leistung der Kommunikation zwischen den Knoten mit geringer Latenz, hohem Durchsatz und Betriebssystem-Bypass verbessern.
Schätzen Sie den Speicherbedarf ab, bevor Sie die Modellparallelität verwenden
Bevor Sie die SageMaker Modellparallelbibliothek verwenden, sollten Sie Folgendes berücksichtigen, um sich ein Bild von den Speicheranforderungen beim Training großer DL-Modelle zu machen.
Für einen Trainingsjob, der eine automatische gemischte Präzision wie float16 (FP16) oder bfloat16 (BF16) und Adam-Optimierer verwendet, beträgt der erforderliche GPU-Speicher pro Parameter etwa 20 Byte, den wir wie folgt aufschlüsseln können:
-
Ein FP16- oder BF16-Parameter ~ 2 Byte
-
Ein FP16- oder BF16-Gradient ~ 2 Byte
-
Ein FP32-Optimierer-Status ~ 8 Byte, der auf den Adam-Optimierern basiert
-
Eine FP32-Kopie des Parameters ~ 4 Byte (wird für den
optimizer apply(OA-) Vorgang benötigt) -
Eine FP32-Kopie des Gradienten ~ 4 Byte (wird für den OA-Vorgang benötigt)
Selbst für ein relativ kleines DL-Modell mit 10 Milliarden Parametern kann es mindestens 200 GB Arbeitsspeicher benötigen, was viel größer ist als der typische GPU-Speicher (z. B. NVIDIA A100 mit 40GB/80GB Speicher), der auf einer einzelnen GPU verfügbar ist. Zusätzlich zu den Speicheranforderungen für Modell- und Optimiererstatus kommen weitere Speicherverbraucher hinzu, wie z. B. Aktivierungen, die im Vorwärtsdurchlauf generiert werden. Der benötigte Speicher kann deutlich mehr als 200 GB betragen.
Für verteilte Trainings empfehlen wir die Verwendung von Amazon-EC2-P4- und P5-Instances mit NVIDIA A100- bzw. H100 Tensor Core-GPUs. Weitere Informationen zu Spezifikationen wie CPU-Kernen, RAM, angeschlossenem Speichervolumen und Netzwerkbandbreite finden Sie im Abschnitt Beschleunigtes Rechnen auf der Seite Amazon-EC2-Instance-Typen
Selbst mit beschleunigten Recheninstanzen können Modelle mit etwa 10 Milliarden Parametern wie Megatron-LM T5 und noch größere Modelle mit Hunderten von Milliarden von Parametern nicht in jedes GPU-Gerät passen. GPT-3
Wie die Bibliothek Modellparallelität und Speicherspartechniken einsetzt
Die Bibliothek besteht aus verschiedenen Arten von Modellparallelitäts-Features und Features zur Speichereinsparung, z. B. Optimierungszustand-Sharding, Aktivierungsprüfpunkte und Aktivierungs-Offloading. All diese Techniken können kombiniert werden, um große Modelle, die aus Hunderten von Milliarden von Parametern bestehen, effizient zu trainieren.
Themen
Parallelität fragmentierter Daten
Sharded-Datenparallelität ist eine speichersparende verteilte Trainingstechnik, die den Status eines Modells (Modellparameter, Gradienten und Optimiererzustände) auf GPUs innerhalb einer datenparallelen Gruppe aufteilt.
Sie können die Parallelität fragmentierter Daten als eigenständige Strategie auf Ihr Modell anwenden. Wenn Sie außerdem die leistungsstärksten GPU-Instanzen verwenden, die mit NVIDIA A100 Tensor Core-GPUs ausgestattet sind, können Sie die Vorteile der verbesserten Trainingsgeschwindigkeit nutzen, ml.p4d.24xlarge die durch den ml.p4de.24xlarge Betrieb der Datenparallelismus-Bibliothek (SMDDP) geboten wird. AllGather SageMaker
Weitere Informationen zur Sharded-Datenparallelität und zu deren Einrichtung oder Verwendung einer Kombination aus Sharded-Datenparallelität und anderen Techniken wie Tensorparallelismus und Training mit gemischter Präzision finden Sie unter Parallelität hybrider fragmentierter Daten.
Expertenparallelität
SMP v2 ist in NVIDIA Megatron
Ein MoE-Modell ist eine Art Transformer-Modell, das aus mehreren Experten besteht, von denen jeder aus einem neuronalen Netzwerk besteht, in der Regel einem Feed-Forward-Netzwerk (FFN). Ein Gate-Netzwerk, das als Router bezeichnet wird, bestimmt, welche Token an welchen Experten gesendet werden. Diese Experten sind auf die Verarbeitung bestimmter Aspekte der Eingabedaten spezialisiert, sodass das Modell schneller trainiert werden kann, die Datenverarbeitungskosten reduziert werden und gleichzeitig dieselbe Leistungsqualität wie bei dem Modell mit hoher Dichte erreicht wird. Und Expertenparallelismus ist eine Parallelitätstechnik, bei der Experten eines MoE-Modells auf verschiedene GPU-Geräte aufgeteilt werden.
Informationen zum Trainieren von MoE-Modellen mit SMP v2 finden Sie unter Expertenparallelität.
Tensor-Parallelität
Die Tensorparallelität teilt einzelne Schichten oder nn.Modules auf verschiedene Geräte auf, die parallel ausgeführt werden. Die folgende Abbildung zeigt das einfachste Beispiel dafür, wie die SMP-Bibliothek ein Modell in vier Schichten aufteilt, um eine bidirektionale Tensorparallelität zu erreichen ("tensor_parallel_degree": 2). In der folgenden Abbildung lauten die Notationen für Modellparallelgruppe, Tensorparallelgruppe und Datenparallelgruppe jeweils MP_GROUP, TP_GROUP und DP_GROUP. Die Schichten jedes Modellreplikats werden halbiert und auf zwei GPUs verteilt. Die Bibliothek verwaltet die Kommunikation zwischen den über Tensor verteilten Modellreplikaten.
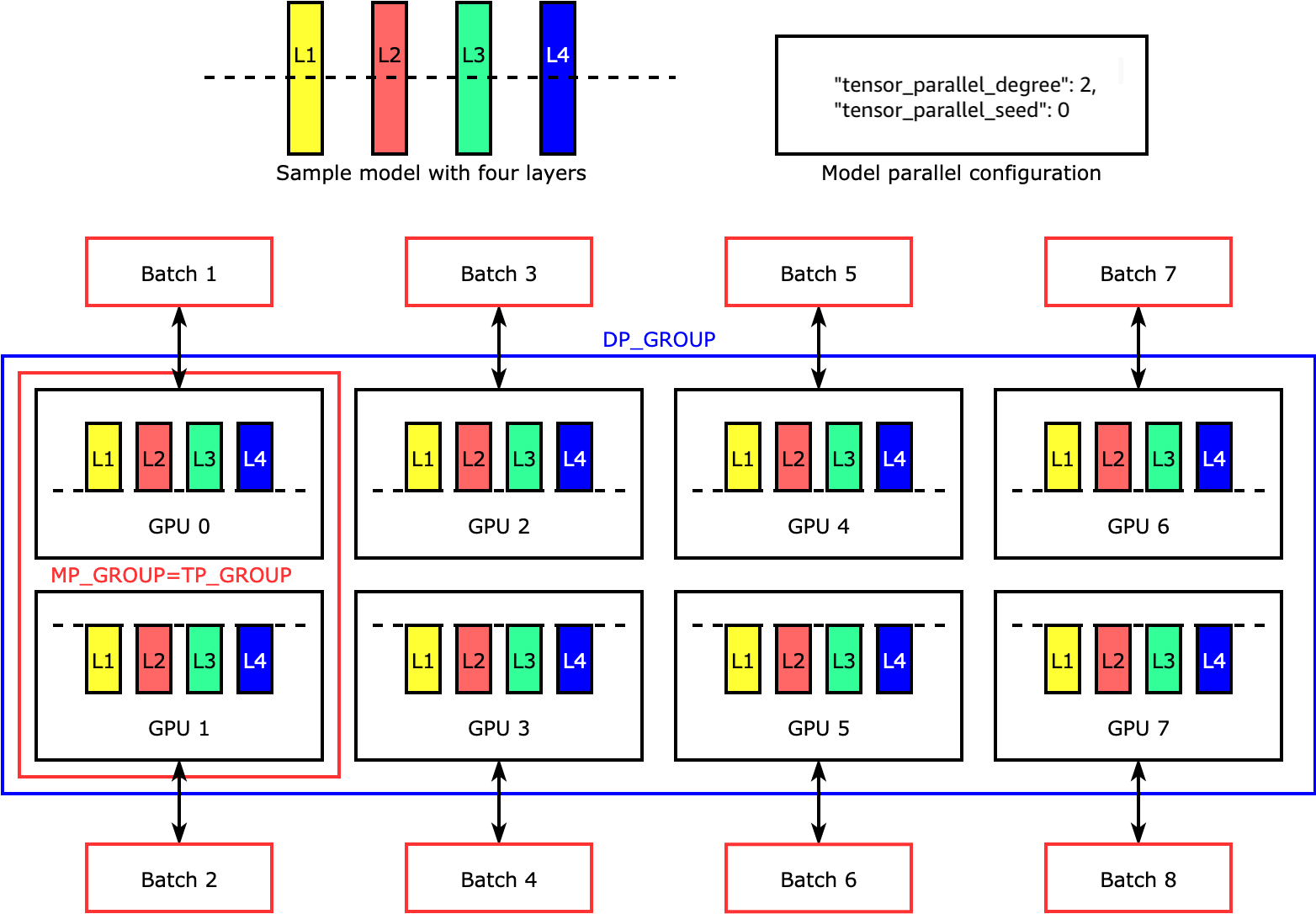
Weitere Informationen zur Tensorparallelität und anderen speichersparenden Funktionen sowie zum Einstellen einer PyTorch Kombination der Kernfunktionen finden Sie unter. Tensor-Parallelität
Aktivierungs-Checkpointing und -auslagerung
Um GPU-Speicher zu sparen, unterstützt die Bibliothek Aktivierungsprüfpunkte, um zu verhindern, dass interne Aktivierungen für benutzerdefinierte Module während des Forward-Durchlaufs im GPU-Speicher gespeichert werden. Die Bibliothek berechnet diese Aktivierungen während des Rückwärtsdurchlaufs neu. Darüber hinaus verlagert sie bei der Aktivierungsauslagerung die gespeicherten Aktivierungen auf den CPU-Speicher und lädt sie während des Rücklaufs zurück auf die GPU, um den Speicherbedarf für die Aktivierung weiter zu reduzieren. Weitere Informationen zur Verwendung dieser Features finden Sie unter Checkpointing bei der Aktivierung und Aktivierung, Entladung.
Auswahl der richtigen Techniken für Ihr Modell
Weitere Informationen zur Auswahl der richtigen Techniken und Konfigurationen finden Sie unter SageMaker Bewährte Methoden für verteilte Modellparallelität.
