Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Cluster-Reparaturen bei GPU-Fehlern
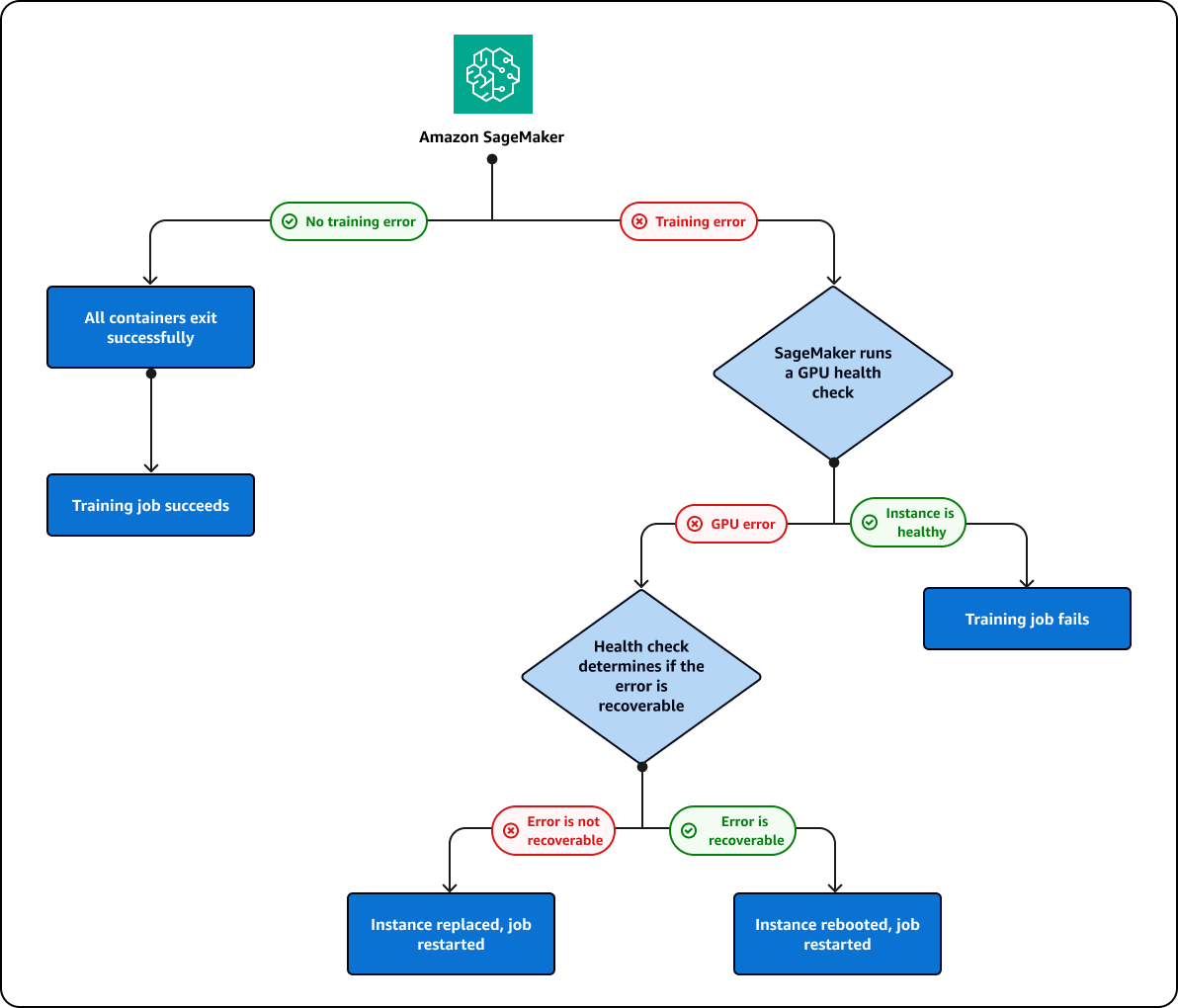
Wenn Sie einen Trainingsjob ausführen, der auf einer GPU fehlschlägt, führt SageMaker AI eine GPU-Zustandsprüfung durch, um festzustellen, ob der Fehler mit einem GPU-Problem zusammenhängt. SageMaker KI ergreift auf der Grundlage der Ergebnisse der Gesundheitsprüfung die folgenden Maßnahmen:
Wenn der Fehler behebbar ist und durch einen Neustart der Instanz oder das Zurücksetzen der GPU behoben werden kann, SageMaker wird AI die Instanz neu starten.
Wenn der Fehler nicht behebbar ist und durch eine GPU verursacht wird, die ersetzt werden muss, ersetzt AI die Instanz. SageMaker
Die Instanz wird im Rahmen eines SageMaker AI-Cluster-Reparaturprozesses entweder ersetzt oder neu gestartet. Während dieses Vorgangs wird die folgende Nachricht in Ihrem Trainingsjobstatus angezeigt:
Repairing training cluster due to hardware failure
SageMaker KI wird bis zu zweimal versuchen, den Cluster zu 10 reparieren. Wenn die Clusterreparatur erfolgreich ist, startet SageMaker KI den Trainingsjob automatisch vom vorherigen Checkpoint aus neu. Wenn die Cluster-Reparatur fehlschlägt, schlägt auch der Trainingsjob fehl. Der Clusterreparaturprozess wird Ihnen nicht in Rechnung gestellt. Clusterreparaturen werden erst eingeleitet, wenn Ihr Trainingsjob fehlschlägt. Wenn bei einem Warmpool-Cluster ein GPU-Problem festgestellt wird, wechselt der Cluster in den Reparaturmodus, um die fehlerhafte Instance entweder neu zu starten oder zu ersetzen. Nach der Reparatur kann der Cluster weiterhin als Warmpool-Cluster verwendet werden.
Der zuvor beschriebene Reparaturprozess für Cluster und Instances ist im folgenden Diagramm dargestellt: