Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen Sie ein Modell in Amazon SageMaker AI mit ModelBuilder
Die Vorbereitung Ihres Modells für die Bereitstellung auf einem SageMaker KI-Endpunkt erfordert mehrere Schritte, darunter die Auswahl eines Modell-Images, die Einrichtung der Endpunktkonfiguration, die Codierung Ihrer Serialisierungs- und Deserialisierungsfunktionen für die Übertragung von Daten zu und von Server und Client, die Identifizierung von Modellabhängigkeiten und deren Upload auf Amazon S3. ModelBuilderkann die Komplexität der Ersteinrichtung und Bereitstellung reduzieren, sodass Sie in einem einzigen Schritt ein einsatzfähiges Modell erstellen können.
ModelBuilder führt die folgenden Aufgaben für Sie aus:
Konvertiert Modelle für maschinelles Lernen, die mit verschiedenen Frameworks wie XGBoost trainiert wurden, oder PyTorch in einem Schritt in einsatzfähige Modelle.
Führt eine automatische Containerauswahl auf der Grundlage des Modell-Frameworks durch, sodass Sie Ihren Container nicht manuell angeben müssen. Sie können trotzdem Ihren eigenen Container verwenden, indem Sie Ihren eigenen URI an
ModelBuilderübergeben.Verwaltet die Serialisierung von Daten auf Clientseite, bevor sie zur Inferenz und Deserialisierung der vom Server zurückgegebenen Ergebnisse an den Server gesendet werden. Die Daten werden ohne manuelle Verarbeitung korrekt formatiert.
Ermöglicht die automatische Erfassung von Abhängigkeiten und verpackt das Modell entsprechend den Erwartungen des Modellservers. Die automatische Erfassung von Abhängigkeiten durch
ModelBuilderist ein Best-Effort-Ansatz, um Abhängigkeiten dynamisch zu laden. (Wir empfehlen, die automatische Erfassung lokal zu testen und die Abhängigkeiten an Ihre Bedürfnisse anzupassen.)Führt für Anwendungsfälle mit großen Sprachmodellen (LLM) optional eine lokale Parameteroptimierung der Servereigenschaften durch, die für eine bessere Leistung beim Hosten auf einem KI-Endpunkt bereitgestellt werden können. SageMaker
Unterstützt die meisten gängigen Modellserver und Container wie Triton TorchServe, DjlServing und TGI Container.
Erstellen Sie Ihr Modell mit ModelBuilder
ModelBuilderist eine Python-Klasse, die ein Framework-Modell wie XGBoost oder oder PyTorch eine benutzerdefinierte Inferenzspezifikation verwendet und es in ein bereitstellbares Modell konvertiert. ModelBuilderstellt eine Build-Funktion bereit, die die Artefakte für die Bereitstellung generiert. Das generierte Modellartefakt ist spezifisch für den Modellserver, den Sie auch als eine der Eingaben angeben können. Weitere Informationen zur ModelBuilder Klasse finden Sie unter ModelBuilder
Das folgende Diagramm veranschaulicht den gesamten Workflow bei der Modellerstellung unter Verwendung von ModelBuilder. ModelBuilder akzeptiert eine Modell oder eine Inferenzspezifikation zusammen mit Ihrem Schema, um ein bereitstellbares Modell zu erstellen, das Sie vor der Bereitstellung lokal testen können.
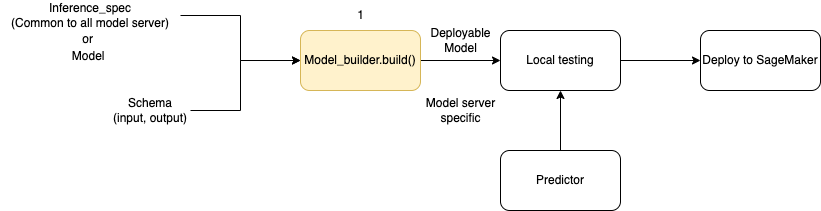
ModelBuilder kann jede Anpassung vornehmen, die Sie anwenden möchten. Um ein Framework-Modell bereitzustellen, erwartet der Model Builder jedoch mindestens ein Modell, eine Beispieleingabe und -ausgabe sowie die Rolle. Im folgenden Codebeispiel wird ModelBuilder mit einem Framework-Modell und einer Instance von SchemaBuilder mit minimalen Argumenten aufgerufen (um die entsprechenden Funktionen für die Serialisierung und Deserialisierung der Endpunkteingabe und -ausgabe abzuleiten). Es ist kein Container angegeben und es werden keine Paketabhängigkeiten übergeben — SageMaker KI leitet diese Ressourcen automatisch ab, wenn Sie Ihr Modell erstellen.
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
Im folgenden Codebeispiel wird ModelBuilder mit einer Inferenzspezifikation (als InferenceSpec-Instance) statt mit einem Modell aufgerufen und bietet zusätzliche Anpassungen. In diesem Fall beinhaltet der Aufruf von Model Builder einen Pfad zum Speichern von Modellartefakten und aktiviert außerdem die automatische Erfassung aller verfügbaren Abhängigkeiten. Weitere Informationen zu InferenceSpec finden Sie unter Anpassen des Ladens von Modellen und der Bearbeitung von Anforderungen.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
Definieren von Serialisierungs- und Deserialisierungsmethoden
Beim Aufrufen eines SageMaker KI-Endpunkts werden die Daten über HTTP-Payloads mit unterschiedlichen MIME-Typen gesendet. Beispielsweise muss ein Bild, das zur Inferenz an den Endpunkt gesendet wird, auf Clientseite in Byte konvertiert und über eine HTTP-Nutzlast an den Endpunkt gesendet werden. Wenn der Endpunkt die Nutzlast empfängt, muss er die Byte-Zeichenfolge wieder auf den Datentyp deserialisieren, der vom Modell erwartet wird (auch als serverseitige Deserialisierung bezeichnet). Nachdem das Modell die Vorhersage abgeschlossen hat, müssen die Ergebnisse auch in Byte serialisiert werden, die über die HTTP-Nutzlast an den Benutzer oder den Client zurückgesendet werden können. Sobald der Client die Antwort-Bytedaten erhalten hat, muss er eine clientseitige Deserialisierung durchführen, um die Bytedaten wieder in das erwartete Datenformat wie beispielsweise JSON zu konvertieren. Sie müssen die Daten mindestens für Folgendes konvertieren:
Serialisierung der Inferenzanforderung (durchgeführt vom Client)
Deserialisierung der Inferenzanforderung (durchgeführt vom Server oder Algorithmus)
Aufrufen des Modells für die Nutzlast und Zurücksenden der Antwort-Nutzlast
Serialisierung der Inferenzantwort (durchgeführt vom Server oder Algorithmus)
Deserialisierung der Inferenzantwort (durchgeführt vom Client)
Das folgende Diagramm zeigt die Serialisierungs- und Deserialisierungsprozesse, die beim Aufrufen des Endpunkts ablaufen.
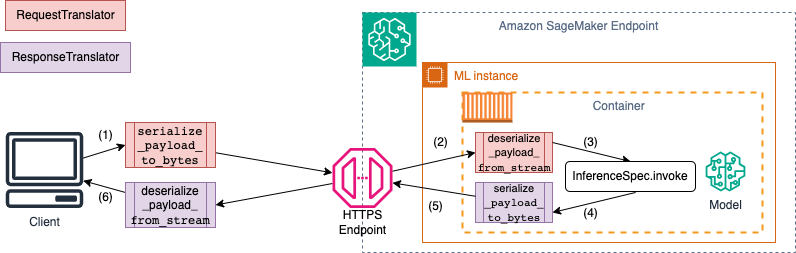
Wenn Sie eine Beispieleingabe und -ausgabe für SchemaBuilder bereitstellen, generiert der Schema Builder die entsprechenden Marshalling-Funktionen für die Serialisierung und Deserialisierung der Eingabe und Ausgabe. Sie können Ihre Serialisierungsfunktionen mit CustomPayloadTranslator weiter anpassen. In den meisten Fällen würde jedoch ein einfacher Serializer wie der folgende funktionieren:
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
Weitere Informationen dazu finden Sie unterSchemaBuilder. SchemaBuilder
Der folgende Codeausschnitt veranschaulicht ein Beispiel, in dem Sie sowohl die Serialisierungs- als auch die Deserialisierungsfunktionen auf Client- und Serverseite anpassen möchten. Sie können Ihre eigenen Anforderung- und Antwortübersetzer mit CustomPayloadTranslator definieren und diese Übersetzer an SchemaBuilder übergeben.
Durch die Zusammenführung von Ein- und Ausgaben mit den Übersetzern kann der Model Builder das Datenformat extrahieren, das das Modell erwartet. Nehmen wir beispielsweise an, dass es sich bei der Beispieleingabe um ein Rohbild handelt und Ihre benutzerdefinierten Übersetzer das Bild zuschneiden und das zugeschnittene Bild als Tensor an den Server senden. ModelBuilder benötigt sowohl die Roheingabe als auch jeglichen benutzerdefinierten Vorverarbeitungs- oder Nachbearbeitungscode, um eine Methode zur Konvertierung von Daten sowohl auf Client- als auch auf Serverseite abzuleiten.
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
Sie übergeben die Beispieleingabe und -ausgabe zusammen mit den zuvor definierten benutzerdefinierten Übersetzern, wenn Sie das SchemaBuilder-Objekt erstellen, wie im folgenden Beispiel gezeigt:
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Anschließend übergeben Sie die Beispieleingabe und -ausgabe zusammen mit den zuvor definierten benutzerdefinierten Übersetzern an das SchemaBuilder-Objekt.
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
In den folgenden Abschnitten wird detailliert erklärt, wie Sie Ihr Modell mit ModelBuilder erstellen und die unterstützenden Klassen verwenden, um das Erlebnis an Ihren Anwendungsfall anzupassen.
Themen
Anpassen des Ladens von Modellen und der Bearbeitung von Anforderungen
Die Bereitstellung Ihres eigenen Inferenzcodes über InferenceSpec bietet eine zusätzliche Anpassungsebene. Mit InferenceSpec können Sie anpassen, wie das Modell geladen wird und wie es eingehende Inferenzanforderungen verarbeitet, wobei Sie die standardmäßigen Mechanismen zum Laden und Bearbeiten von Inferenzen umgehen. Diese Flexibilität ist besonders vorteilhaft, wenn Sie mit nicht standardmäßigen Modellen oder benutzerdefinierten Inferenz-Pipelines arbeiten. Sie können die invoke-Methode anpassen, um zu steuern, wie das Modell eingehende Anforderungen vor- und nachverarbeitet. Die invoke-Methode stellt sicher, dass das Modell Inferenzanforderungen korrekt verarbeitet. Das folgende Beispiel wird verwendetInferenceSpec, um ein Modell mit der HuggingFace Pipeline zu generieren. Weitere Informationen zu InferenceSpec finden Sie in der InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
Das folgende Beispiel zeigt eine angepasste Variante eines vorherigen Beispiels. Ein Modell wird mit einer Inferenzspezifikation definiert, die Abhängigkeiten aufweist. In diesem Fall ist der Code in der Inferenzspezifikation vom lang-segment-Paket abhängig. Das Argument for dependencies enthält eine Anweisung, die den Builder anweist, lang-segment mit Git zu installieren. Da der Model Builder vom Benutzer zur benutzerdefinierten Installation einer Abhängigkeit angewiesen wird, ist der auto-Schlüssel auf False festgelegt, um die automatische Erfassung von Abhängigkeiten zu deaktivieren.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
Erstellen und Bereitstellen Ihres Modells
Rufen Sie die build-Funktion auf, um Ihr bereitstellbares Modell zu erstellen. Dieser Schritt erstellt den Inferenzcode (als inference.py) in Ihrem Arbeitsverzeichnis mit dem Code, der zum Erstellen Ihres Schemas, zum Ausführen der Serialisierung und Deserialisierung von Eingaben und Ausgaben sowie zum Ausführen anderer benutzerdefinierter Logik erforderlich ist.
Zur Integritätsprüfung packt SageMaker AI die für die Bereitstellung im Rahmen der ModelBuilder Build-Funktion erforderlichen Dateien und wählt sie aus. Während dieses Vorgangs erstellt SageMaker KI auch eine HMAC-Signatur für die Pickle-Datei und fügt den geheimen Schlüssel während deploy (oder) als Umgebungsvariable in die CreateModelAPI ein. create Beim Starten des Endpunkts wird die Umgebungsvariable verwendet, um die Integrität der Pickle-Datei zu überprüfen.
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
Stellen Sie Ihr Modell mit der vorhandenen deploy-Methode des Modells bereit. In diesem Schritt richtet SageMaker KI einen Endpunkt ein, auf dem Ihr Modell gehostet wird, während es anfängt, Vorhersagen über eingehende Anfragen zu treffen. ModelBuilder leitet zwar die Endpunktressourcen ab, die für die Bereitstellung Ihres Modells benötigt werden, Sie können diese Schätzungen jedoch mit Ihren eigenen Parameterwerten überschreiben. Das folgende Beispiel weist SageMaker KI an, das Modell auf einer einzigen ml.c6i.xlarge Instanz bereitzustellen. Ein Modell, das auf ModelBuilder basiert, ermöglicht als zusätzliche Funktion die Live-Protokollierung während der Bereitstellung.
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
Wenn Sie eine genauere Kontrolle über die Ihrem Modell zugewiesenen Endpunktressourcen wünschen, können Sie ein ResourceRequirements-Objekt verwenden. Mit dem ResourceRequirements-Objekt können Sie eine Mindestanzahl von CPUs, Beschleunigern und Kopien von Modellen anfordern, die Sie bereitstellen möchten. Sie können auch eine Mindest- und Höchstmenge an Arbeitsspeicher (in MB) anfordern. Um dieses Feature verwenden zu können, müssen Sie Ihren Endpunkttyp alsEndpointType.INFERENCE_COMPONENT_BASED angeben. Im folgenden Beispiel müssen vier Beschleuniger, eine Mindestspeichergröße von 1024 MB und eine Kopie Ihres Modells auf einem Endpunkt des Typs EndpointType.INFERENCE_COMPONENT_BASED bereitgestellt werden.
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
Verwendung Ihres eigenen Containers (BYOC)
Wenn Sie Ihren eigenen Container (erweitert von einem SageMaker AI-Container) mitbringen möchten, können Sie auch den Bild-URI angeben, wie im folgenden Beispiel gezeigt. Sie müssen auch den Modellserver identifizieren, der dem Image entspricht, damit ModelBuilder Artefakte generiert, die für den Modellserver spezifisch sind.
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
Verwendung ModelBuilder im lokalen Modus
Sie können Ihr Modell lokal bereitstellen, indem Sie das mode-Argument verwenden, um zwischen lokalen Tests und der Bereitstellung auf einem Endpunkt zu wechseln. Sie müssen die Modellartefakte im Arbeitsverzeichnis speichern, wie im folgenden Codeausschnitt dargestellt:
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
Übergeben Sie das Modellobjekt, eine SchemaBuilder-Instance, und setzen Sie den Modus auf Mode.LOCAL_CONTAINER. Wenn Sie die build-Funktion aufrufen, identifiziert ModelBuilder automatisch den unterstützten Framework-Container und sucht nach Abhängigkeiten. Das folgende Beispiel zeigt die Modellerstellung mit einem XGBoost-Modell im lokalen Modus.
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
Rufen Sie die deploy-Funktion für die lokale Bereitstellung auf, wie im folgenden Codeausschnitt dargestellt. Wenn Sie Parameter für Instance-Typ oder -Anzahl Parameter angeben, werden diese Argumente ignoriert.
predictor_local = xgb_local_builder.deploy()
Fehlerbehebung für den lokalen Modus
Abhängig von Ihrer individuellen lokalen Konfiguration können Probleme beim Betrieb von ModelBuilder in Ihrer Umgebung auftreten. In der folgenden Liste finden Sie einige Probleme, mit denen Sie möglicherweise konfrontiert werden, und Informationen zu deren Behebung.
Wird bereits verwendet: Möglicherweise ist ein
Address already in use-Fehler aufgetreten. In diesem Fall ist es möglich, dass ein Docker-Container auf diesem Port läuft oder ein anderer Prozess ihn verwendet. Sie können dem in der Linux-Dokumentationbeschriebenen Ansatz folgen, um den Prozess zu identifizieren und Ihren lokalen Prozess ordnungsgemäß von Port 8080 auf einen anderen Port umzuleiten oder die Docker-Instance zu bereinigen. IAM-Berechtigungsproblem: Möglicherweise tritt ein Berechtigungsproblem auf, wenn Sie versuchen, ein Amazon-ECR-Image abzurufen oder auf Amazon S3 zuzugreifen. Navigieren Sie in diesem Fall zur Ausführungsrolle der Notebook- oder Studio-Classic-Instance, um die Richtlinie für
SageMakerFullAccessoder die entsprechenden API-Berechtigungen zu überprüfen.Problem mit der EBS-Volumenkapazität: Wenn Sie ein großes Sprachmodell (LLM) bereitstellen, geht Ihnen möglicherweise der Speicherplatz aus, während Sie Docker im lokalen Modus ausführen, oder es kommt zu Speicherbeschränkungen für den Docker-Cache. In diesem Fall können Sie versuchen, Ihr Docker-Volume in ein Dateisystem zu verschieben, das über ausreichend Speicherplatz verfügt. Führen Sie die folgenden Schritte aus, um Ihr Docker-Volume zu verschieben:
Öffnen Sie ein Terminal und führen Sie
dfaus, um die Festplattennutzung anzuzeigen, wie in der folgenden Ausgabe gezeigt:(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000Verschieben Sie das Standard-Docker-Verzeichnis von
/dev/nvme0n1p1nach,/dev/nvme2n1damit Sie das 256 GB SageMaker AI-Volume vollständig nutzen können. Weitere Informationen finden Sie in der Dokumentation zum Verschieben Ihres Docker-Verzeichnisses. Stoppen Sie Docker mit dem folgenden Befehl:
sudo service docker stopFügen Sie
daemon.jsonzu/etc/dockerhinzu oder hängen Sie den folgenden JSON-Blob an den vorhandenen an.{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }Verschieben Sie das Docker-Verzeichnis
/var/lib/dockermit dem folgenden Befehl nach/home/ec2-user/SageMaker AI:sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}Starten Sie den Docker mit dem folgenden Befehl:
sudo service docker startReinigen Sie den Papierkorb mit dem folgenden Befehl:
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *Wenn Sie eine SageMaker Notebook-Instanz verwenden, können Sie die Schritte in der Docker-Vorbereitungsdatei befolgen, um Docker
für den lokalen Modus vorzubereiten.
ModelBuilder Beispiele
Weitere Beispiele für die Verwendung ModelBuilder beim Erstellen Ihrer Modelle finden Sie unter ModelBuilderBeispielnotizbücher
