Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erste Schritte mit Data Wrangler
Amazon SageMaker Data Wrangler ist eine Funktion in Amazon SageMaker Studio Classic. In diesem Abschnitt erfahren Sie, wie Sie auf Data Wrangler zugreifen und wie Sie damit beginnen können. Gehen Sie wie folgt vor:
-
Schließen Sie jeden Schritt in Voraussetzungen ab.
-
Folgen Sie den Anweisungen unter Auf Data Wrangler zugreifen, um mit der Verwendung von Data Wrangler zu beginnen.
Voraussetzungen
Zur Verwendung von Data Wrangler müssen Sie die folgenden erforderlichen Voraussetzungen ausführen.
-
Um Data Wrangler verwenden zu können, benötigen Sie Zugriff auf eine Amazon Elastic Compute Cloud (Amazon EC2)-Instance. Weitere Informationen zur Verwendung von Amazon-EC2-Instances finden Sie unter Instances. Informationen dazu, wie Sie Ihre Kontingente einsehen und bei Bedarf eine Erhöhung des Kontingents beantragen können, finden Sie unter AWS Service-Kontingente.
-
Konfigurieren Sie die in Sicherheit und Berechtigungen beschriebenen erforderlichen Berechtigungen.
-
Wenn Ihr Unternehmen eine Firewall verwendet, die den Internet-Datenverkehr blockiert, benötigen Sie Zugriff auf die folgenden URLs:
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Um Data Wrangler verwenden zu können, benötigen Sie eine aktive Studio-Classic-Instance. Informationen zum Starten einer neuen Instance finden Sie unter Überblick über die Amazon SageMaker AI-Domain. Wenn Ihre Studio-Classic-Instance bereit ist, folgen Sie den Anweisungen unter Auf Data Wrangler zugreifen.
Auf Data Wrangler zugreifen
In der folgenden Vorgehensweise wird davon ausgegangen, dass Sie die Voraussetzungen bereits abgeschlossen haben.
Gehen Sie wie folgt vor, um in Studio Classic auf Data Wrangler zuzugreifen.
-
Melden Sie sich bei Studio an. Weitere Informationen finden Sie unter Überblick über die Amazon SageMaker AI-Domain.
-
Wählen Sie Studio.
-
Wählen Sie App starten.
-
Wählen Sie in der Auswahlliste Studio aus.
-
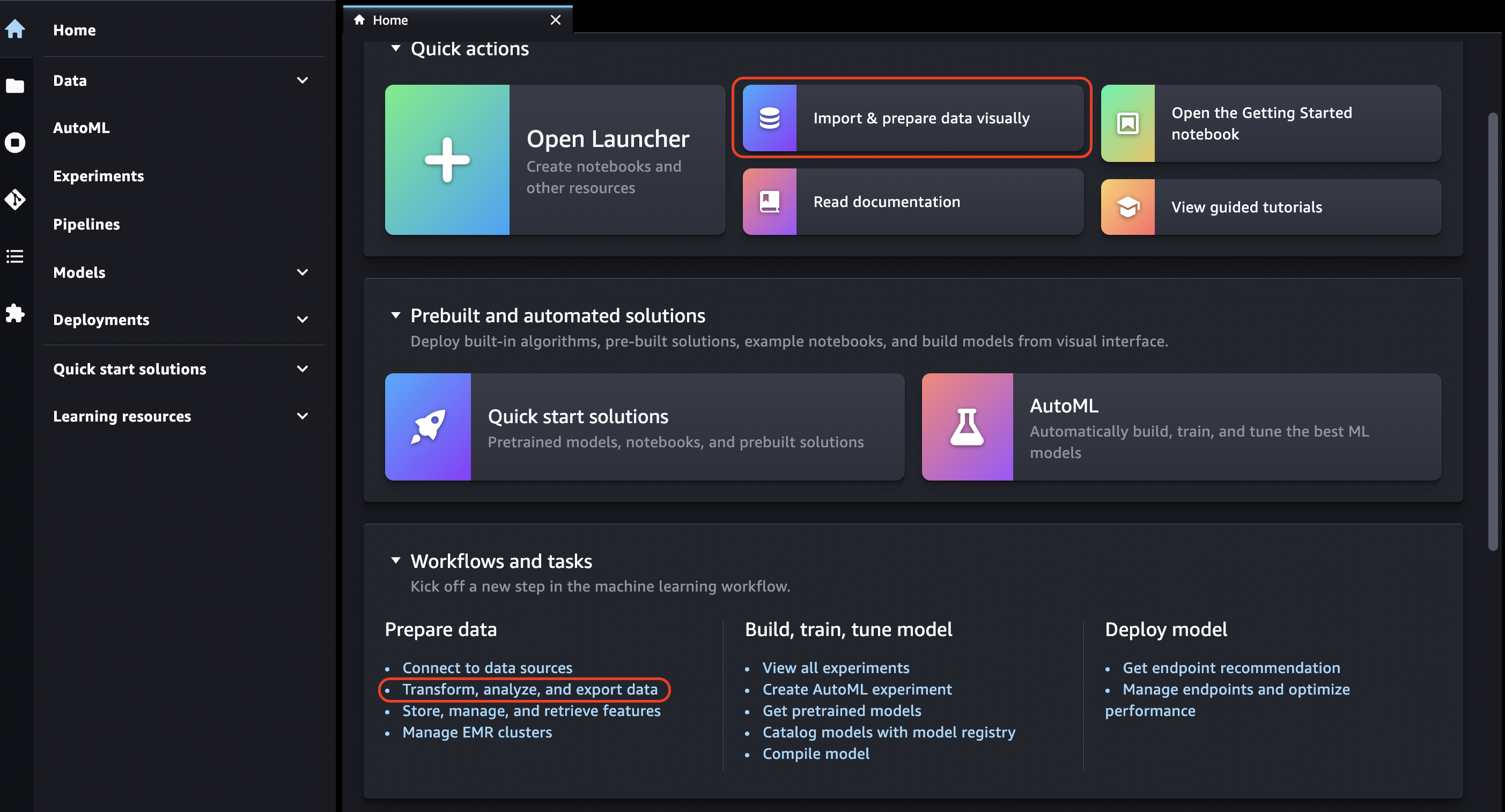
Wählen Sie das Symbol Startseite aus.
-
Wählen Sie Daten aus.
-
Wählen Sie Data Wrangler.
-
Sie können einen Data Wrangler-Flow auch erstellen, indem Sie wie folgt vorgehen.
-
Wählen Sie in der Navigationsleiste oben die Option Datei aus.
-
Wählen Sie Neu aus.
-
Wählen Sie Data Wrangler Flow aus.
-
-
(Optional) Benennen Sie das neue Verzeichnis und die .flow-Datei um.
-
Wenn Sie eine neue .flow-Datei in Studio Classic erstellen, sehen Sie möglicherweise ein Karussell, das Sie mit Data Wrangler vertraut macht.
Dies kann einige Minuten dauern.
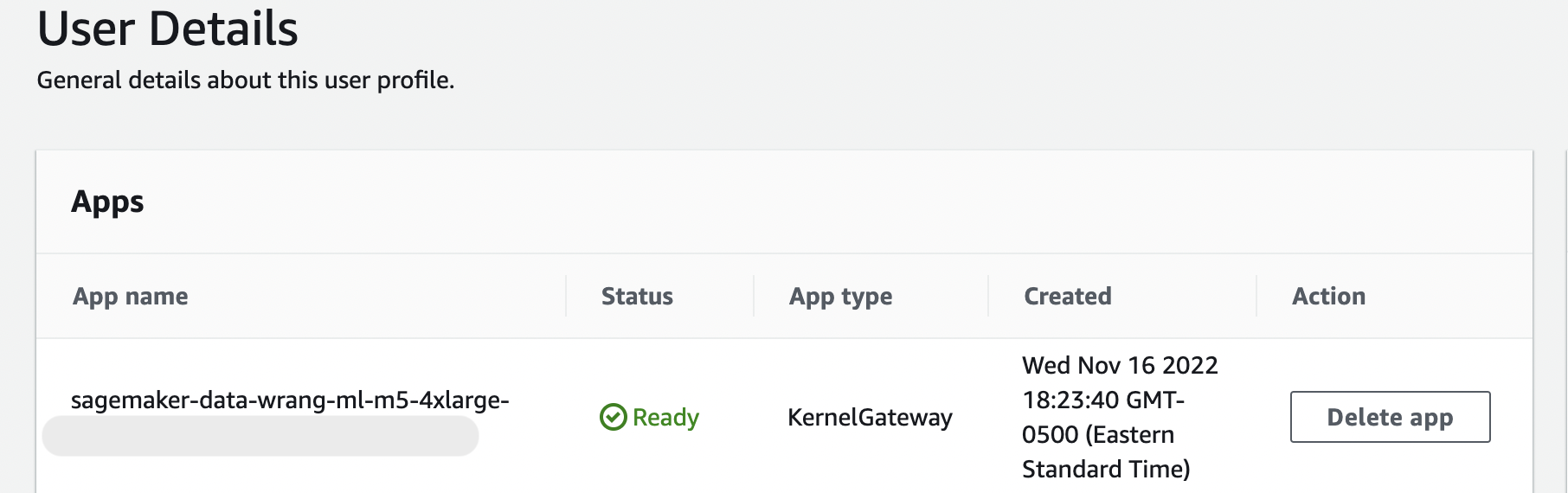
Diese Meldung bleibt bestehen, solange die KernelGatewayApp auf Ihrer Seite mit den Benutzerdetails den Status Ausstehend hat. Um den Status dieser App zu sehen, wählen Sie in der SageMaker AI-Konsole auf der Amazon SageMaker Studio Classic-Seite den Namen des Benutzers aus, den Sie für den Zugriff auf Studio Classic verwenden. Auf der Seite mit den Benutzerdetails sehen Sie unter Apps eine KernelGatewayApp. Warten Sie, bis dieser App-Status Bereit ist, um Data Wrangler zu verwenden. Dies kann etwa 5 Minuten dauern, wenn Sie Data Wrangler zum ersten Mal starten.
-
Wählen Sie zunächst eine Datenquelle aus und verwenden Sie sie, um einen Datensatz zu importieren. Weitere Informationen hierzu finden Sie unter Import.
Wenn Sie einen Datensatz importieren, wird er in Ihrem Datenablauf angezeigt. Weitere Informationen hierzu finden Sie unter Einen Data Wrangler-Fluss erstellen und verwenden.
-
Nachdem Sie einen Datensatz importiert haben, leitet Data Wrangler automatisch den Datentyp in jeder Spalte ab. Wählen Sie + neben dem Schritt Datentypen und wählen Sie Datentypen bearbeiten aus.
Wichtig
Nachdem Sie Transformationen zum Schritt Datentypen hinzugefügt haben, können Sie Spaltentypen mithilfe von Update-Typen nicht massenweise aktualisieren.
-
Verwenden Sie den Datenablauf, um Transformationen und Analysen hinzuzufügen. Weitere Informationen hierzu finden Sie unter Daten transformieren und Analysieren und Visualisieren.
-
Um einen vollständigen Datenablauf zu exportieren, wählen Sie Exportieren und wählen Sie eine Exportoption. Weitere Informationen hierzu finden Sie unter Exportieren.
-
Wählen Sie abschließend das Symbol Komponenten und Registrierungen und anschließend Data Wrangler aus der Dropdown-Liste aus, um alle von Ihnen erstellten .flow-Dateien anzuzeigen. Sie können dieses Menü verwenden, um Datenabläufe zu suchen und zwischen ihnen zu wechseln.
Nachdem Sie Data Wrangler gestartet haben, können Sie im folgenden Abschnitt erläutern, wie Sie Data Wrangler verwenden können, um einen ML-Datenvorbereitungsablauf zu erstellen.
Data Wrangler aktualisieren
Wir empfehlen Ihnen, die App von Data Wrangler Studio Classic regelmäßig zu aktualisieren, um auf die neuesten Features und Updates zugreifen zu können. Der Name der Data Wrangler-App beginnt mit sagemaker-data-wrang. Informationen zum Aktualisieren einer Studio-Classic-App finden Sie unter Amazon SageMaker Studio Classic-Apps herunterfahren und aktualisieren.
Demo: Exemplarische Vorgehensweise zum Data Wrangler Titanic-Datensatz
In den folgenden Abschnitten finden Sie eine exemplarische Vorgehensweise für die ersten Schritte zur Verwendung von Data Wrangler. Bei dieser exemplarischen Vorgehensweise wird davon ausgegangen, dass Sie die Schritte unter Auf Data Wrangler zugreifen bereits ausgeführt haben und eine neue Datenablaufdatei geöffnet haben, die Sie für die Demo verwenden möchten. Möglicherweise möchten Sie diese .flow-Datei in einen ähnlichen Namen wie titanic-demo.flow umbenennen.
In dieser exemplarischen Vorgehensweise wird der Titanic-Datensatz
In diesem Tutorial führen Sie die folgenden Schritte durch:
-
Führen Sie eine der folgenden Aktionen aus:
-
Öffnen Sie Ihren Data Wrangler-Flow und wählen Sie Beispieldatensatz verwenden aus.
-
Laden Sie den Titanic-Datensatz
auf Amazon Simple Storage Service (Amazon S3) hoch und importieren Sie diesen Datensatz anschließend in Data Wrangler.
-
-
Analysieren Sie diesen Datensatz mithilfe von Data Wrangler-Analysen.
-
Definieren Sie einen Datenablauf mithilfe von Data Wrangler-Datentransformationen.
-
Exportieren Sie Ihren Flow in ein Jupyter Notebook, mit dem Sie einen Data Wrangler-Auftrag erstellen können.
-
Verarbeiten Sie Ihre Daten und starten Sie einen SageMaker Trainingsjob, um einen XGBoost Binary Classifier zu trainieren.
Laden Sie den Datensatz auf S3 hoch und importieren Sie ihn
Zu Beginn können Sie eine der folgenden Methoden verwenden, um den Titanic-Datensatz in Data Wrangler zu importieren:
-
Den Datensatz direkt aus dem Data Wrangler-Flow importieren
-
Hochladen des Datensatzes auf Amazon S3 und anschließendes Importieren in Data Wrangler
Um den Datensatz direkt in Data Wrangler zu importieren, öffnen Sie den Ablauf und wählen Sie Beispieldatensatz verwenden.
Das Hochladen des Datensatzes auf Amazon S3 und das Importieren in Data Wrangler entspricht eher der Erfahrung, die Sie beim Importieren Ihrer eigenen Daten gemacht haben. In den folgenden Informationen erfahren Sie, wie Sie Ihren Datensatz hochladen und importieren können.
Bevor Sie mit dem Import der Daten in Data Wrangler beginnen, laden Sie den Titanic-Datensatz
Wenn Sie ein neuer Benutzer von Amazon S3 sind, können Sie dies per Drag & Drop in der Amazon S3-Konsole tun. Wie das geht, erfahren Sie unter Hochladen von Dateien und Ordnern mithilfe von Drag & Drop im Amazon Simple Storage Service-Benutzerhandbuch.
Wichtig
Laden Sie Ihren Datensatz in einen S3-Bucket in derselben AWS Region hoch, die Sie für die Durchführung dieser Demo verwenden möchten.
Wenn Ihr Datensatz erfolgreich auf Amazon S3 hochgeladen wurde, können Sie ihn in Data Wrangler importieren.
Importieren Sie den Titanic-Datensatz in Data Wrangler
-
Wählen Sie auf der Registerkarte Daten importieren die Schaltfläche Datenablauf oder wählen Sie die Registerkarte Importieren.
-
Wählen Sie Amazon S3.
-
Verwenden Sie die Tabelle Datensatz aus S3 importieren, um den Bucket zu finden, zu dem Sie den Titanic-Datensatz hinzugefügt haben. Wählen Sie die CSV-Datei des Titanic-Datensatzes aus, um den Bereich Details zu öffnen.
-
Unter Details sollte der Dateityp CSV lauten. Markieren Sie Erste Zeile ist Kopfzeile, um anzugeben, dass es sich bei der ersten Zeile des Datensatzes um eine Kopfzeile handelt. Sie können dem Datensatz auch einen freundlicheren Namen geben, z. B.
Titanic-train. -
Wählen Sie die Schaltfläche Import aus.
Wenn Ihr Datensatz in Data Wrangler importiert wird, wird er auf Ihrer Registerkarte Datenablauf angezeigt. Sie können auf einen Knoten doppelklicken, um die Detailansicht des Knotens aufzurufen, in der Sie Transformationen oder Analysen hinzufügen können. Sie können das Plussymbol für einen Schnellzugriff auf die Navigation verwenden. Im nächsten Abschnitt verwenden Sie diesen Datenablauf, um Analyse- und Transformationsschritte hinzuzufügen.
Datenfluss
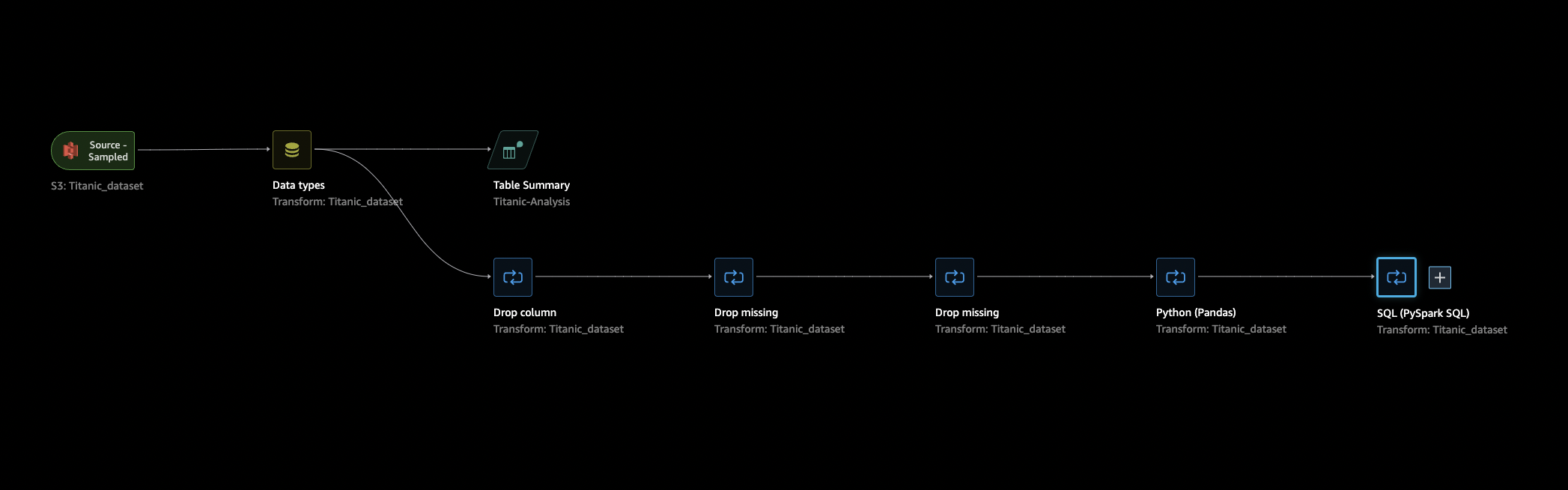
Im Abschnitt Datenablauf sind die einzigen Schritte im Datenablauf Ihr kürzlich importierter Datensatz und ein Datentyp-Schritt. Nachdem Sie die Transformationen angewendet haben, können Sie zu dieser Registerkarte zurückkehren und sehen, wie der Datenablauf aussieht. Fügen Sie nun auf den Registerkarten Vorbereiten und Analysieren einige grundlegende Transformationen hinzu.
Vorbereiten und Visualisieren
Data Wrangler verfügt über integrierte Transformationen und Visualisierungen, mit denen Sie Ihre Daten analysieren, bereinigen und transformieren können.
Auf der Registerkarte Daten der Knotendetailansicht sind alle integrierten Transformationen im rechten Bereich aufgeführt, der auch einen Bereich enthält, in dem Sie benutzerdefinierte Transformationen hinzufügen können. Der folgende Anwendungsfall zeigt, wie diese Transformationen verwendet werden.
Um Informationen zu erhalten, die Ihnen bei der Data Exploration und dem Feature Engineering helfen könnten, erstellen Sie einen Bericht über Datenqualität und Erkenntnisse. Die Informationen aus dem Bericht können Ihnen dabei helfen, Ihre Daten zu bereinigen und zu verarbeiten. Er gibt Ihnen Informationen wie die Anzahl der fehlenden Werte und die Anzahl der Ausreißer. Wenn Sie Probleme mit Ihren Daten haben, wie z. B. Target Leakage oder Ungleichgewichte, können Sie mithilfe des Insights-Berichts auf diese Probleme aufmerksam gemacht werden. Weitere Informationen zum Erstellen eines Berichts finden Sie unter Erhalten Sie Einblicke in Daten und Datenqualität.
Data Exploration
Erstellen Sie zunächst mithilfe einer Analyse eine Tabellenübersicht der Daten. Gehen Sie wie folgt vor:
-
Wählen Sie in Ihrem Datenablauf das Pluszeichen + neben dem Schritt Datentyp aus und dann Analyse hinzufügen.
-
Wählen Sie im Bereich Analyse in der Dropdown-Liste die Option Tabellenübersicht aus.
-
Geben Sie der Tabellenübersicht einen Namen.
-
Wählen Sie Vorschau aus, um eine Vorschau der Tabelle anzuzeigen, die erstellt wird.
-
Wählen Sie Speichern, um sie in Ihrem Datenablauf zu speichern. Sie wird unter Alle Analysen angezeigt.
Anhand der angezeigten Statistiken können Sie zu diesem Datensatz Beobachtungen machen, die den folgenden ähneln:
-
Der durchschnittliche Fahrpreis (Mittelwert) liegt bei etwa 33 $, während der Höchstpreis bei über 500 $ liegt. Diese Spalte enthält wahrscheinlich Ausreißer.
-
Verwendet dieser Datensatz ?, um auf fehlende Werte hinzuweisen. In einer Reihe von Spalten fehlen Werte: cabin, embarked und home.dest
-
In der Alterskategorie fehlen über 250 Werte.
Bereinigen Sie als Nächstes Ihre Daten anhand der Erkenntnisse, die Sie aus diesen Statistiken gewonnen haben.
Bereinigen ungenutzter Spalten
Bereinigen Sie den Datensatz anhand der Analyse aus dem vorherigen Abschnitt, um ihn für das Training vorzubereiten. Um Ihrem Datenablauf eine neue Transformation hinzuzufügen, wählen Sie + neben dem Schritt Datentyp in Ihrem Datenablauf und wählen Sie Transformation hinzufügen aus.
Löschen Sie zunächst die Spalten, die Sie nicht für das Training verwenden möchten. Sie können dazu die Datenanalysebibliothek Pandas
Gehen Sie wie folgt vor, um die ungenutzten Spalten zu löschen.
So löschen Sie die unbenutzten Spalten:
-
Öffnen Sie den Data Wrangler-Flow.
-
Es gibt zwei Knoten in Ihrem Data Wrangler-Flow. Wählen Sie + rechts neben dem Knoten Datentypen.
-
Wählen Sie Transformation hinzufügen aus.
-
Wählen Sie in der Spalte Alle Schritte die Option Schritt hinzufügen aus.
-
Wählen Sie in der Liste der Standardtransformationen die Option Spalten verwalten aus. Bei den Standardtransformationen handelt es sich um vorgefertigte, integrierte Transformationen. Vergewissern Sie sich, dass Spalte löschen ausgewählt ist.
-
Überprüfen Sie unter Zu löschende Spalten die folgenden Spaltennamen:
-
Kabine
-
Fahrkarte
-
Name
-
Geschwister
-
Pfirsich
-
home.dest
-
Boot
-
body
-
-
Wählen Sie Preview (Vorschau) aus.
-
Vergewissern Sie sich, dass die Spalten gelöscht wurden, und wählen Sie dann Hinzufügen.
Führen Sie dazu mit „Pandas“ die folgenden Schritte aus:
-
Wählen Sie in der Spalte Alle Schritte die Option Schritt hinzufügen aus.
-
Wählen Sie in der Liste Benutzerdefinierte Transformation die Option Benutzerdefinierte Transformation aus.
-
Geben Sie einen Namen für Ihre Transformation ein und wählen Sie Python (Pandas) aus der Dropdown-Liste aus.
-
Geben Sie das folgende Python-Skript in das Code-Feld ein.
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
Wählen Sie Vorschau, um eine Vorschau der Änderung anzuzeigen, und wählen Sie dann Hinzufügen, um die Transformation hinzuzufügen.
Bereinigen fehlender Werte
Bereinigen Sie jetzt die fehlenden Werte. Sie können dies mit der Transformationsgruppe Umgang mit fehlenden Werten tun.
In einer Reihe von Spalten fehlen Werte. Von den übrigen Spalten enthalten Alter und Fahrpreis fehlende Werte. Überprüfen Sie dies mit einer benutzerdefinierten Transformation.
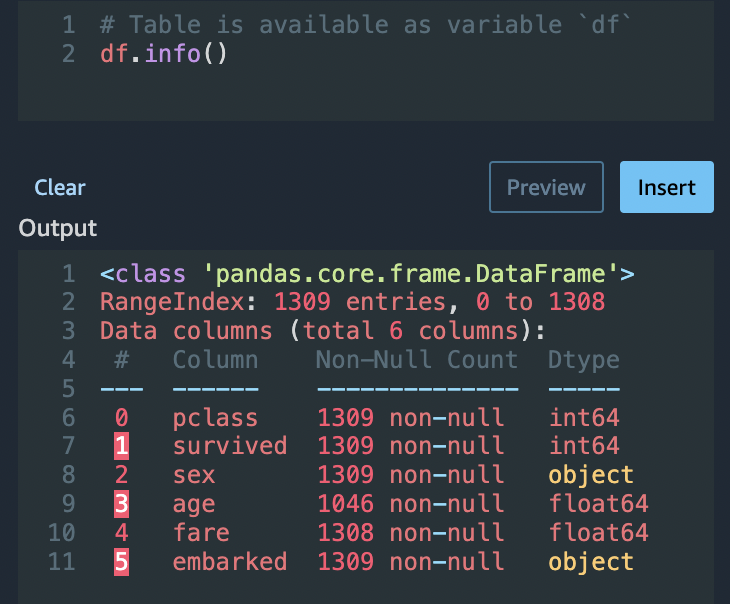
Verwenden Sie die Option Python (Pandas) und verwenden Sie Folgendes, um schnell die Anzahl der Einträge in jeder Spalte zu überprüfen:
df.info()
Gehen Sie wie folgt vor, um Zeilen mit fehlenden Werten in der Kategorie Alter zu löschen:
-
Wählen Sie Fehlende Werte handhaben aus.
-
Wählen Sie für den Transformer die Option Drop missing aus.
-
Wählen Sie das Alter für die Eingabespalte aus.
-
Wählen Sie Vorschau aus, um den neuen Datenrahmen zu sehen, und wählen Sie dann Hinzufügen, um die Transformation zu Ihrem Schema hinzuzufügen.
-
Wiederholen Sie den Vorgang für fare.
Sie können dies df.info() im Abschnitt Benutzerdefinierte Transformation verwenden, um zu bestätigen, dass alle Zeilen jetzt 1.045 Werte haben.
Benutzerdefinierte Pandas: Codieren
Probieren Sie das Flat-Encoding mit Pandas. Beim Codieren von kategorischen Daten wird für Kategorien eine numerische Darstellung erstellt. Wenn Ihre Kategorien z. B. Dog und Cat sind, können Sie diese Informationen in zwei Vektoren kodieren: [1,0] für Dog und [0,1] für Cat.
-
Wählen Sie im Abschnitt Benutzerdefinierte Transformation die Option Python (Pandas) aus der Dropdown-Liste aus.
-
Geben Sie Folgendes in das Code-Feld ein.
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
Wählen Sie Vorschau, um eine Vorschau der Änderung anzuzeigen. Die codierte Version jeder Spalte wird dem Datensatz hinzugefügt.
-
Wählen Sie Hinzufügen, um die Transformation hinzuzufügen.
Benutzerdefiniertes SQL: Spalten AUSWÄHLEN
Wählen Sie nun die Spalten, die Sie weiterhin mit SQL verwenden möchten. Wählen Sie für diese Demo die Spalten aus, die in der folgenden SELECT Anweisung aufgeführt sind. Da survived Ihre Zielspalte für das Training ist, sollten Sie diese Spalte an die erste Stelle setzen.
-
Wählen Sie im Abschnitt Benutzerdefinierte Transformation die Option SQL (PySpark SQL) aus der Dropdownliste aus.
-
Geben Sie Folgendes in das Code-Feld ein.
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
Wählen Sie Vorschau, um eine Vorschau der Änderung anzuzeigen. Die in Ihrer
SELECT-Anweisung aufgeführten Spalten sind die einzigen verbleibenden Spalten. -
Wählen Sie Hinzufügen, um die Transformation hinzuzufügen.
In ein Data Wrangler-Notebook exportieren
Wenn Sie mit der Erstellung eines Datenablaufs fertig sind, stehen Ihnen eine Reihe von Exportoptionen zur Verfügung. Im folgenden Abschnitt wird erklärt, wie Sie in ein Data Wrangler-Auftrags-Notebook exportieren. Ein Data Wrangler-Auftrag wird verwendet, um Ihre Daten anhand der in Ihrem Datenfluss definierten Schritte zu verarbeiten. Weitere Informationen zu allen Exportoptionen finden Sie unter Exportieren.
In ein Data Wrangler-Auftrags-Notebook exportieren
Wenn Sie Ihren Datenablauf mit einem Data Wrangler-Auftrag exportieren, erstellt der Prozess automatisch ein Jupyter Notebook. Dieses Notizbuch wird automatisch in Ihrer Studio Classic-Instanz geöffnet und ist so konfiguriert, dass es einen SageMaker Verarbeitungsauftrag zur Ausführung Ihres Data Wrangler-Datenflusses ausführt, der als Data Wrangler-Job bezeichnet wird.
-
Speichern Sie Ihren Datenablauf. Wählen Sie Datei und dann Data Wrangler-Flow speichern aus.
-
Kehren Sie zur Registerkarte Datenablauf zurück, wählen Sie den letzten Schritt in Ihrem Datenablauf (SQL) aus und klicken Sie dann auf +, um die Navigation zu öffnen.
-
Wählen Sie Exportieren und Amazon S3 (über Jupyter Notebook) aus. Dadurch wird ein Jupyter Notebook geöffnet.
-
Wählen Sie einen beliebigen Python-3-Kernel (Data Science) für den Kernel.
-
Wenn der Kernel gestartet wird, führen Sie die Zellen im Notizbuch aus, bis Sie den SageMaker Trainingsjob starten (optional).
-
Optional können Sie die Zellen in Kick off SageMaker Training Job (optional) ausführen, wenn Sie einen KI-Trainingsjob zum Trainieren eines SageMaker XGBoost-Klassifikators erstellen möchten. Die Kosten für die Durchführung eines SageMaker Schulungsjobs finden Sie in den SageMaker Amazon-Preisen
. Alternativ können Sie die in Training zu XGBoost Classifier enthaltenen Codeblöcke zum Notebook hinzufügen und sie ausführen, um die XGBoost-Open-Source-Bibliothek zum Trainieren eines XGBoost-Klassifikators
zu verwenden. -
Kommentieren Sie die Zelle aus, führen Sie sie unter Cleanup aus und führen Sie sie aus, um das SageMaker Python-SDK auf seine ursprüngliche Version zurückzusetzen.
Sie können den Status Ihres Data Wrangler-Jobs in der SageMaker AI-Konsole auf der Registerkarte Verarbeitung überwachen. Darüber hinaus können Sie Ihren Data Wrangler-Job mit Amazon überwachen. CloudWatch Weitere Informationen finden Sie unter Überwachen von SageMaker Amazon-Verarbeitungsaufträgen mit CloudWatch Protokollen und Metriken.
Wenn Sie einen Schulungsjob gestartet haben, können Sie dessen Status mithilfe der SageMaker AI-Konsole unter Schulungsjobs im Bereich Schulung überwachen.
Training zu XGBoost Classifier
Sie können einen XGBoost Binary Classifier entweder mit einem Jupyter-Notebook oder einem Amazon Autopilot trainieren. SageMaker Sie können Autopilot verwenden, um Modelle anhand der Daten, die Sie direkt aus Ihrem Data Wrangler-Flow transformiert haben, automatisch zu trainieren und zu optimieren. Informationen zu Autopilot finden Sie unter Automatisches Schulen von Modellen auf Ihrem Datenfluss.
In demselben Notebook, mit dem der Data Wrangler-Auftrag gestartet wurde, können Sie die Daten abrufen und einen XGBoost Binary Classifier mit den vorbereiteten Daten mit minimaler Datenaufbereitung trainieren.
-
Aktualisieren Sie zunächst die erforderlichen Module mithilfe von
pipund entfernen Sie die _SUCCESS-Datei (diese letzte Datei ist bei der Verwendung vonawswranglerproblematisch).! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Lesen Sie die Daten aus Amazon S3. Sie können
awswrangleres verwenden, um alle CSV-Dateien im S3-Präfix rekursiv zu lesen. Die Daten werden dann in Funktionen und Beschriftungen aufgeteilt. Die Beschriftung ist die erste Spalte des Datenrahmens.import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
Erstellen Sie abschließend DMatrices (die primitive XGBoost-Struktur für Daten) und führen Sie eine Kreuzvalidierung mithilfe der binären XGBoost-Klassifikation durch.
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Fahren Sie Data Wrangler herunter
Wenn Sie Data Wrangler nicht mehr verwenden, empfehlen wir Ihnen, die Instance herunterzufahren, auf der Data Wrangler läuft, um zusätzliche Kosten zu vermeiden. Informationen zum Herunterfahren der Data Wrangler-App und der zugeordneten Instance finden Sie unter Data Wrangler herunterfahren.
