Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Fairness, Erklärbarkeit von Modellen und Erkennung von Verzerrungen mit Clarify SageMaker
Sie können Amazon SageMaker Clarify verwenden, um Fairness und die Erklärbarkeit von Modellen zu verstehen und um Verzerrungen in Ihren Modellen zu erklären und zu erkennen. Sie können einen SageMaker Clarif-Verarbeitungsauftrag so konfigurieren, dass Messwerte für Verzerrungen und Merkmalszuweisungen berechnet und Berichte zur Erklärbarkeit des Modells generiert werden. SageMaker Clarif-Verarbeitungsaufträge werden mithilfe eines speziellen SageMaker Clarif-Container-Images implementiert. Auf der folgenden Seite wird beschrieben, wie SageMaker Clarify funktioniert und wie Sie mit einer Analyse beginnen können.
Was bedeutet Fairness und Modellverständlichkeit für Vorhersagen im Bereich Machine Learning?
Machine-Learning-Modelle (ML) unterstützen die Entscheidungsfindung in Bereichen wie Finanzdienstleistungen, Gesundheitswesen, Bildung und Personalwesen. Politische Entscheidungsträger, Aufsichtsbehörden und Befürworter haben das Bewusstsein für die ethischen und politischen Herausforderungen geschärft, die Machine Learning und datengesteuerte Systeme mit sich bringen. Amazon SageMaker Clarify kann Ihnen helfen zu verstehen, warum Ihr ML-Modell eine bestimmte Vorhersage getroffen hat und ob sich diese Verzerrung während des Trainings oder der Inferenz auf diese Vorhersage auswirkt. SageMaker Clarify bietet auch Tools, mit denen Sie weniger voreingenommene und verständlichere Modelle für maschinelles Lernen erstellen können. SageMaker Clarify kann auch Modellberichte zur Unternehmensführung erstellen, die Sie Risiko- und Compliance-Teams sowie externen Aufsichtsbehörden zur Verfügung stellen können. Mit SageMaker Clarify können Sie Folgendes tun:
-
Erkennen Sie Verzerrungen und helfen Sie dabei, Ihre Modellvorhersagen zu erklären.
-
Identifizieren Sie die Arten von Verzerrungen in den Daten vor dem Training.
-
Identifizieren Sie Arten von Verzerrungen in den Daten nach dem Training, die während des Trainings oder während der Produktion Ihres Modells auftreten können.
SageMaker Clarify hilft zu erklären, wie Ihre Modelle mithilfe von Feature-Attributionen Vorhersagen treffen. Es kann auch Inferenzmodelle, die sich in der Produktion befinden, sowohl auf Verzerrungen als auch auf Drift bei der Feature-Attribution überwachen. Diese Informationen können Ihnen in folgenden Bereichen behilflich sein:
-
Regulatorische Vorschriften – Politische Entscheidungsträger und andere Aufsichtsbehörden können Bedenken haben, dass Entscheidungen, die Ergebnisse von ML-Modellen verwenden, diskriminierende Auswirkungen haben. Ein ML-Modell kann beispielsweise Verzerrungen kodieren und eine automatisierte Entscheidung beeinflussen.
-
Wirtschaft – Regulierte Bereiche benötigen möglicherweise zuverlässige Erklärungen dafür, wie ML-Modelle Vorhersagen treffen. Die Erklärbarkeit der Modelle kann für Branchen besonders wichtig sein, die auf Zuverlässigkeit, Sicherheit und Konformität angewiesen sind. Dazu können Finanzdienstleistungen, Personalwesen, Gesundheitswesen und automatisiertes Transportwesen gehören. Beispielsweise müssen Kreditanträge möglicherweise Erläuterungen dazu enthalten, wie ML-Modelle bestimmte Prognosen für Kreditsachbearbeiter, Prognostiker und Kunden getroffen haben.
-
Datenwissenschaft – Datenwissenschaftler und ML-Ingenieure können ML-Modelle debuggen und verbessern, wenn sie feststellen können, ob ein Modell auf der Grundlage verrauschter oder irrelevanter Merkmale Schlüsse zieht. Sie können auch die Einschränkungen ihrer Modelle und die Fehlerquellen verstehen, auf die ihre Modelle stoßen können.
Einen Blogbeitrag, der zeigt, wie man ein vollständiges Modell für maschinelles Lernen für betrügerische Automobilschadensfälle konzipiert und erstellt, das SageMaker Clarify in eine SageMaker KI-Pipeline integriert, finden Sie unter The Architect und erstellen Sie den gesamten Machine-Learning-Lebenszyklus mit AWS: einer umfassenden Amazon SageMaker AI-Demo
Bewährte Methoden zur Bewertung von Fairness und Erklärbarkeit im ML-Lebenszyklus
Fairness als Prozess: Die Begriffe Voreingenommenheit und Fairness hängen von ihrer Anwendung ab. Die Messung der Verzerrung und die Wahl der Messwerte für die Verzerrung können sich an sozialen, rechtlichen und anderen nichttechnischen Überlegungen orientieren. Die erfolgreiche Einführung fairnessorientierter ML-Ansätze beinhaltet die Konsensbildung und die Zusammenarbeit zwischen den wichtigsten Interessengruppen. Dazu können Produkte, Richtlinien, Recht, Technik, AI/ML Teams, Endbenutzer und Gemeinschaften gehören.
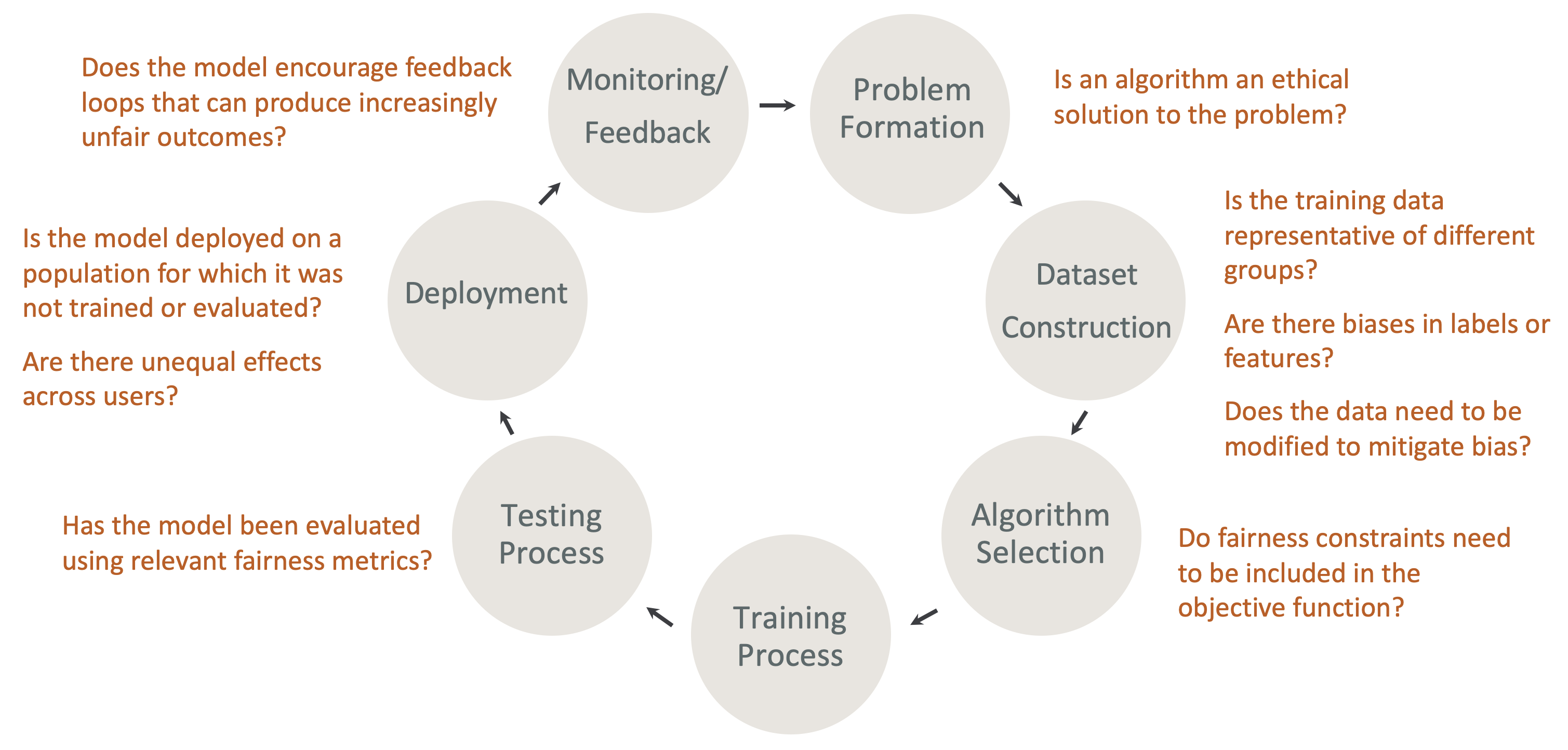
Fairness und erklärbare Gestaltung im ML-Lebenszyklus – Berücksichtigen Sie Fairness und Erklärbarkeit in jeder Phase des ML-Lebenszyklus. Diese Phasen umfassen die Problemformulierung, die Erstellung des Datensatzes, die Auswahl des Algorithmus, den Modelltrainingsprozess, den Testprozess, die Bereitstellung sowie die Überwachung und Rückmeldung. Für diese Analyse ist es wichtig, über die richtigen Tools zu verfügen. Wir empfehlen, während des ML-Lebenszyklus die folgenden Fragen zu stellen:
-
Fördert das Modell Rückkopplungsschleifen, die zu zunehmend unfairen Ergebnissen führen können?
-
Ist ein Algorithmus eine ethische Lösung für das Problem?
-
Sind die Trainingsdaten repräsentativ für verschiedene Gruppen?
-
Gibt es Verzerrungen bei Bezeichnungen oder Merkmalen?
-
Müssen die Daten geändert werden, um Verzerrungen zu verringern?
-
Müssen Fairnessbeschränkungen in die Zielfunktion aufgenommen werden?
-
Wurde das Modell anhand relevanter Fairness-Kennzahlen bewertet?
-
Gibt es ungleiche Auswirkungen auf die einzelnen Nutzer?
-
Wird das Modell in einer Population eingesetzt, für die es nicht trainiert oder evaluiert wurde?
Leitfaden zu den SageMaker KI-Erläuterungen und der Dokumentation zu Vorurteilen
Verzerrungen können sowohl vor als auch nach dem Training eines Modells auftreten und in den Daten gemessen werden. SageMaker Clarify kann Erklärungen für Modellvorhersagen nach dem Training und für Modelle liefern, die in der Produktion eingesetzt werden. SageMaker Clarify kann auch Modelle, die sich in der Produktion befinden, auf Abweichungen bei ihren grundlegenden erklärenden Attributen hin überwachen und bei Bedarf Basiswerte berechnen. Die Dokumentation zur Erklärung und Erkennung von Verzerrungen mithilfe von SageMaker Clarify ist wie folgt strukturiert:
-
Informationen zur Einrichtung eines Verarbeitungsauftrags aus Gründen der Verzerrung und Erklärbarkeit finden Sie unter Einen SageMaker Clarif-Verarbeitungsjob konfigurieren.
-
Informationen zur Erkennung von Verzerrungen bei der Vorverarbeitung von Daten, bevor sie zum Trainieren eines Modells verwendet werden, finden Sie unter Pre-training Datenverzerrung.
-
Informationen zur Erkennung von Daten nach dem Training und Modellverzerrungen finden Sie unter Post-training Daten- und Modellverzerrungen.
-
Informationen zum modellunabhängigen Ansatz der Feature-Attribution zur Erklärung von Modellprognose nach dem Training finden Sie unter Erklärbarkeit des Modells.
-
Weitere Informationen zur Überwachung der Abweichungen der Beiträge der Features vom Ausgangswert, der während der Modelltraining ermittelt wurde, finden Sie unter Feature-Attributions-Drift für Modelle in der Produktion.
-
Informationen zu Überwachungsmodellen, die für die Basislinienverschiebung in Produktion sind, finden Sie unter Bias-Drift bei Modellen in der Produktion.
-
Informationen zum Abrufen von Erklärungen in Echtzeit von einem SageMaker KI-Endpunkt finden Sie unterOnline-Erklärbarkeit mit Clarify SageMaker.
Wie SageMaker Clarify Processing Jobs funktionieren
Sie können SageMaker Clarify verwenden, um Ihre Datensätze und Modelle auf Erklärbarkeit und Verzerrungen zu analysieren. Ein SageMaker Clarif-Verarbeitungsauftrag verwendet den SageMaker Clarif-Verarbeitungscontainer, um mit einem Amazon S3 S3-Bucket zu interagieren, der Ihre Eingabedatensätze enthält. Sie können SageMaker Clarify auch verwenden, um ein Kundenmodell zu analysieren, das auf einem SageMaker KI-Inferenzendpunkt eingesetzt wird.
Die folgende Grafik zeigt, wie ein SageMaker Clarif-Verarbeitungsjob mit Ihren Eingabedaten und optional mit einem Kundenmodell interagiert. Diese Interaktion hängt von der spezifischen Art der durchgeführten Analyse ab. Der SageMaker Clarify-Verarbeitungscontainer bezieht den Eingabedatensatz und die Konfiguration für die Analyse aus einem S3-Bucket. Für bestimmte Analysetypen, einschließlich der Merkmalsanalyse, muss SageMaker der Clarifesty-Verarbeitungscontainer Anfragen an den Modellcontainer senden. Anschließend ruft er die Modellvorhersagen aus der Antwort ab, die der Modellcontainer sendet. Danach berechnet der SageMaker Clarify-Verarbeitungscontainer die Analyseergebnisse und speichert sie im S3-Bucket.

Sie können einen SageMaker Clarif-Verarbeitungsauftrag in mehreren Phasen des Lebenszyklus des maschinellen Lernens ausführen. SageMaker Clarify kann Ihnen bei der Berechnung der folgenden Analysetypen helfen:
-
Pre-training Bias-Metriken. Diese Metriken können Ihnen helfen, die Verzerrung in Ihren Daten zu verstehen, sodass Sie sie beheben und Ihr Modell anhand eines faireren Datensatzes trainieren können. Weitere Informationen über Messwerte Pre-training Bias-Metriken für Verzerrungen vor dem Training finden Sie unter. Um einen Auftrag zur Analyse von Verzerrungsmetriken vor dem Training auszuführen, müssen Sie den Datensatz und eine Konfigurationsdatei für die JSON-Analyse bereitstellen. Analyse-Konfigurationsdateien
-
Post-training Bias-Metriken. Diese Metriken nach dem Training können Ihnen dabei helfen, Verzerrungen zu verstehen, die durch einen Algorithmus, durch Hyperparameter-Entscheidungen oder durch Verzerrungen verursacht wurden, oder jegliche Verzerrungen, die zu einem früheren Zeitpunkt nicht offensichtlich waren. Weitere Informationen zu Messwerten für Verzerrungen nach dem Training finden Sie unterPost-training Daten- und Modellverzerrungsmetriken. SageMaker Clarify verwendet die Modellvorhersagen zusätzlich zu den Daten und Bezeichnungen, um Verzerrungen zu identifizieren. Um einen Auftrag zur Analyse von Verzerrungsmetriken nach dem Training auszuführen, müssen Sie den Datensatz und eine Konfigurationsdatei für die JSON-Analyse bereitstellen. Die Konfiguration sollte den Modell- oder Endpunktnamen enthalten.
-
Shapley-Werte, die Ihnen dabei helfen können, zu verstehen, welchen Einfluss Ihre Features auf die Prognose Ihres Modells hat. Weitere Informationen zu Shapley-Werten finden Sie unter Feature-Attributionen, die Shapley-Werte verwenden. Für diese Funktion ist ein trainiertes Modell erforderlich.
-
Partielle Abhängigkeitsdiagramme (PDPs) können Ihnen helfen zu verstehen, wie stark sich Ihre vorhergesagte Zielvariable ändern würde, wenn Sie den Wert eines Features variieren würden. Weitere Informationen zu PDPs finden Sie unter Für Analyse partieller Abhängigkeitsdiagramme (PDPs) diese Funktion ist ein trainiertes Modell erforderlich.
SageMaker Clarify benötigt Modellvorhersagen, um Verzerrungsmetriken und Merkmalszuweisungen nach dem Training zu berechnen. Sie können einen Endpunkt angeben oder SageMaker Clarify erstellt anhand Ihres Modellnamens einen kurzlebigen Endpunkt, der auch als Schattenendpunkt bezeichnet wird. Der SageMaker Clarith-Container löscht den Schattenendpunkt, nachdem die Berechnungen abgeschlossen sind. Auf einer höheren Ebene führt der SageMaker Clarith-Container die folgenden Schritte aus:
-
Überprüft Eingaben und Parameter.
-
Erzeugt den Schattenendpunkt (falls ein Modellname angegeben wird).
-
Lädt den Eingabedatensatz in einen Datenrahmen.
-
Ruft bei Bedarf Modellvorhersagen vom Endpunkt ab.
-
Berechnet Messwerte für Verzerrungen und Merkmalszuschreibungen.
-
Löscht den Schattenendpunkt.
-
Generieren Sie die Analyseergebnisse.
Nach Abschluss SageMaker des Clarif-Verarbeitungsauftrags werden die Analyseergebnisse an dem Ausgabeort gespeichert, den Sie im Verarbeitungsausgabeparameter des Jobs angegeben haben. Zu diesen Ergebnissen gehören eine JSON-Datei mit Bias-Metriken und globalen Feature-Attributionen, ein grafischer Bericht und zusätzliche Dateien für lokale Feature-Attributionen. Sie können die Ergebnisse vom Ausgabespeicherort herunterladen und anzeigen.
Weitere Informationen zu Bias-Metriken, Erklärbarkeit und deren Interpretation finden Sie unter Erfahren Sie, wie Amazon SageMaker Clarify hilft, Verzerrungen zu erkennen
Beispiel-Notebooks
Die folgenden Abschnitte enthalten Notizbücher, die Ihnen den Einstieg in die Verwendung von SageMaker Clarify, die Verwendung von Clarify für spezielle Aufgaben, einschließlich Aufgaben innerhalb eines verteilten Jobs, und für Computer Vision erleichtern sollen.
Erste Schritte
Die folgenden Beispielnotizbücher zeigen, wie Sie SageMaker Clarify verwenden können, um mit Aufgaben zur Erklärbarkeit und Modellverzerrungen zu beginnen. Zu diesen Aufgaben gehören die Erstellung eines Auftrags zur Verarbeitung, das Trainieren eines Modells für Machine Learning (ML) und die Überwachung von Modellvorhersagen:
-
Erklärbarkeit und Erkennung von Verzerrungen mit Amazon SageMaker Clarify — Verwenden Sie SageMaker Clarify
, um einen Verarbeitungsjob zu erstellen, um Verzerrungen zu erkennen und Modellvorhersagen zu erklären. -
Überwachung von Verzerrungsabweichungen und Abweichungen bei der Merkmalszuweisung Amazon SageMaker Clarify
— Verwenden Sie Amazon SageMaker Model Monitor, um Verzerrungen und Abweichungen bei der Merkmalszuweisung im Laufe der Zeit zu überwachen. -
So lesen Sie einen Datensatz im Format JSON Lines in
einen SageMaker Clarif-Verarbeitungsauftrag ein. -
Bias abschwächen, ein anderes Modell ohne Vorurteile trainieren und es in das Modellregister aufnehmen — Verwenden Sie
Synthetic Minority Over-sampling Technique (SMOTE) und SageMaker Clarify, um Verzerrungen zu reduzieren, trainieren Sie ein anderes Modell und nehmen Sie das neue Modell dann in das Modellregister auf. Dieses BeispielNotebook zeigt auch, wie die neuen Modellartefakte, einschließlich Daten, Code und Modellmetadaten, in die Modellregistrierung aufgenommen werden. Dieses Notizbuch ist Teil einer Reihe, die zeigt, wie SageMaker Clarify in eine SageMaker KI-Pipeline integriert werden kann, die in The Architect beschrieben ist, und den gesamten Lebenszyklus des maschinellen Lernens mit einem Blogbeitrag aufbauen kann. AWS
Sonderfälle
Die folgenden Notizbücher zeigen Ihnen, wie Sie SageMaker Clarify für spezielle Fälle verwenden, auch in Ihrem eigenen Container, und für Aufgaben zur Verarbeitung natürlicher Sprache:
-
Fairness und Erklärbarkeit mit SageMaker Clarify (Bring Your Own Container) — Erstellen Sie Ihr eigenes
Modell und Ihren eigenen Container, die in SageMaker Clarify integriert werden können, um Verzerrungen zu messen und einen Bericht zur Erklärbarkeitsanalyse zu erstellen. In diesem Beispielnotizbuch werden auch wichtige Begriffe vorgestellt und es wird gezeigt, wie Sie über Studio Classic auf den Bericht zugreifen können. SageMaker -
Fairness und Erklärbarkeit mit SageMaker Clarify Spark Distributed Processing
— Verwenden Sie verteilte Verarbeitung, um einen SageMaker Clarif-Job auszuführen, der die Verzerrung eines Datensatzes vor dem Training und die Verzerrung eines Modells nach dem Training misst. Dieses Beispielnotizbuch zeigt Ihnen auch, wie Sie eine Erklärung für die Bedeutung der Eingabefunktionen für die Modellausgabe erhalten und über Studio Classic auf den Bericht zur Erklärbarkeitsanalyse zugreifen können. SageMaker -
Erklärbarkeit mit SageMaker Clarify — Partielle Abhängigkeitsdiagramme (PDP) — Verwenden Sie SageMaker Clarify, um PDPs
zu generieren und auf einen Bericht zur Erklärbarkeit des Modells zuzugreifen. -
Erläuterung der Textstimmungsanalyse mithilfe der Erklärbarkeit von SageMaker Clarify Natural Language Processing (NLP) — Verwenden Sie Clarify für die Stimmungsanalyse
von Text. SageMaker -
Verwenden Sie Erklärbarkeit durch Computer Vision (CV) mit Bildklassifizierung
und Objekterkennung
Es wurde verifiziert, dass diese Notizbücher in Amazon SageMaker Studio Classic laufen. Anweisungen zum Öffnen eines Notebooks in Studio Classic finden Sie unter Erstellen oder öffnen Sie ein Amazon SageMaker Studio Classic-Notizbuch. Wenn Sie aufgefordert werden, einen Kernel auszuwählen, wählen Sie Python 3 (Data Science).
