Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Problem RunBooks
Der folgende Abschnitt enthält Probleme, die auftreten können, deren Erkennung und Vorschläge zur Behebung des Problems.
-
Probleme mit der Identitätsverwaltung
Wenn ich mich bei der Umgebung anmelde, kehre ich sofort zur Anmeldeseite zurück
Fehler „Benutzer nicht gefunden“ beim Versuch, sich anzumelden
Der Benutzer wurde in Active Directory hinzugefügt, fehlt aber in RES
Der Benutzer ist beim Erstellen einer Sitzung nicht verfügbar
Fehler beim Überschreiten der Größenbeschränkung im CloudWatch Cluster-Manager-Protokoll
-
Virtuelle Desktops werden gestartet
Das Anmeldekonto für Windows Virtual Desktop ist auf Administrator eingestellt
Das Zertifikat läuft ab, wenn eine externe Ressource verwendet wird CertificateRenewalNode
Ein virtueller Desktop, der zuvor funktionierte, kann keine erfolgreiche Verbindung mehr herstellen
Nach der Anmeldung wird bei der VDI-Sitzung ein leerer Bildschirm angezeigt
-
Komponente für virtuelle Desktops
Die Amazon EC2 EC2-Instance wird in der Konsole wiederholt als beendet angezeigt
Das Projekt erscheint nicht im Pulldown, wenn Sie den Software-Stack bearbeiten, um es hinzuzufügen
Probleme mit den DHCP-Optionen bei der external/customer AD-Konfiguration
Firefox-Fehler MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
-
Probleme bei der Installation
Themen
........................
CloudFormationDer Stapel kann nicht erstellt werden und die Meldung "WaitCondition hat eine fehlgeschlagene Nachricht erhalten. Error:States.TaskFailed“
Um das Problem zu identifizieren, untersuchen Sie die Amazon CloudWatch Amazon-Protokollgruppe<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>. Wenn es mehrere Protokollgruppen mit demselben Namen gibt, überprüfen Sie die erste verfügbare. Eine Fehlermeldung in den Protokollen enthält weitere Informationen zu dem Problem.
Anmerkung
Stellen Sie sicher, dass die Parameterwerte keine Leerzeichen enthalten.
........................
Die E-Mail-Benachrichtigung wurde danach nicht erhaltenCloudFormationStacks wurden erfolgreich erstellt
Wenn nach der erfolgreichen Erstellung der CloudFormation Stacks keine E-Mail-Einladung empfangen wurde, überprüfen Sie Folgendes:
-
Vergewissern Sie sich, dass der E-Mail-Adressparameter korrekt eingegeben wurde.
Wenn die E-Mail-Adresse falsch ist oder kein Zugriff möglich ist, löschen Sie die Research and Engineering Studio-Umgebung und stellen Sie sie erneut bereit.
-
Suchen Sie in der Amazon EC2 EC2-Konsole nach Hinweisen auf wechselnde Instances.
Wenn Amazon EC2 EC2-Instances mit dem
<envname>Präfix als beendet angezeigt werden und dann durch eine neue Instance ersetzt werden, liegt möglicherweise ein Problem mit der Netzwerk- oder Active Directory-Konfiguration vor. -
Wenn Sie die AWS High Performance Compute-Rezepte zur Erstellung Ihrer externen Ressourcen bereitgestellt haben, stellen Sie sicher, dass die VPC, die privaten und öffentlichen Subnetze und andere ausgewählte Parameter vom Stack erstellt wurden.
Wenn einer der Parameter falsch ist, müssen Sie möglicherweise die RES-Umgebung löschen und erneut bereitstellen. Weitere Informationen finden Sie unter Deinstalliere das Produkt.
-
Wenn Sie das Produkt mit Ihren eigenen externen Ressourcen bereitgestellt haben, stellen Sie sicher, dass das Netzwerk und das Active Directory der erwarteten Konfiguration entsprechen.
Die Bestätigung, dass Infrastrukturinstanzen erfolgreich dem Active Directory beigetreten sind, ist von entscheidender Bedeutung. Probieren Sie die Schritte unter ausInstanzen laufen oder der VDC-Controller ist ausgefallen, um das Problem zu lösen.
........................
Instanzen laufen oder der VDC-Controller ist ausgefallen
Die wahrscheinlichste Ursache für dieses Problem ist die Unfähigkeit der Ressource (n), eine Verbindung zum Active Directory herzustellen oder diesem beizutreten.
Um das Problem zu überprüfen:
-
Starten Sie von der Befehlszeile aus eine Sitzung mit SSM auf der laufenden Instanz des vdc-Controllers.
-
Führen Sie
sudo su -. -
Führen Sie
systemctl status sssd.
Wenn der Status inaktiv oder ausgefallen ist oder Sie Fehler in den Protokollen sehen, konnte die Instanz Active Directory nicht beitreten.
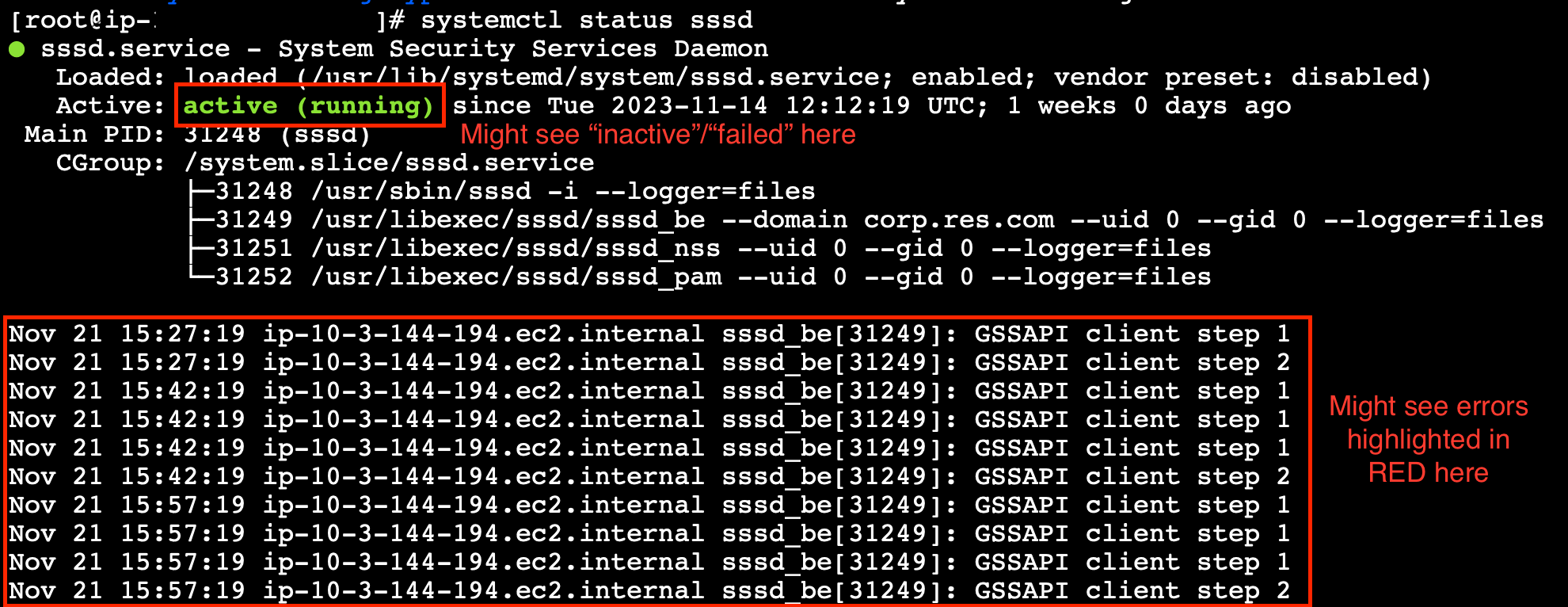
SSM-Fehlerprotokoll
Um das Problem zu lösen:
-
Führen Sie von derselben Befehlszeileninstanz aus,
cat /root/bootstrap/logs/userdata.logum die Protokolle zu untersuchen.
Das Problem könnte eine von drei möglichen Ursachen haben.
Überprüfen Sie die Protokolle. Wenn Sie sehen, dass sich Folgendes mehrfach wiederholt, konnte die Instanz dem Active Directory nicht beitreten.
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
Stellen Sie sicher, dass die Parameterwerte für Folgendes bei der Erstellung des RES-Stacks korrekt eingegeben wurden.
-
directoryservice.ldap_connection_uri
-
Verzeichnisservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.ou
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
Verzeichnisdienst.Name
-
-
Aktualisieren Sie alle falschen Werte in der DynamoDB-Tabelle. Die Tabelle befindet sich in der DynamoDB-Konsole unter Tabellen. Der Tabellenname sollte sein.
<stack name>.cluster-settings -
Nachdem Sie die Tabelle aktualisiert haben, löschen Sie den Cluster-Manager und den VDC-Controller, auf denen derzeit die Umgebungsinstanzen ausgeführt werden. Auto Scaling startet neue Instances mit den neuesten Werten aus der DynamoDB-Tabelle.
Wenn die Logs zurückgegeben werdenInsufficient permissions to modify computer account, könnte der bei der Stack-Erstellung eingegebene ServiceAccount Name falsch sein.
-
Öffnen Sie in der AWS Konsole den Secrets Manager.
-
Suchen Sie nach
directoryserviceServiceAccountUsername. Das Geheimnis sollte sein<stack name>-directoryservice-ServiceAccountUsername -
Öffnen Sie das Geheimnis, um die Detailseite anzuzeigen. Wählen Sie unter Geheimer Wert die Option Geheimen Wert abrufen und anschließend Klartext aus.
-
Wenn der Wert aktualisiert wurde, löschen Sie die derzeit laufenden Cluster-Manager- und VDC-Controller-Instanzen der Umgebung. Auto Scaling startet neue Instances mit dem neuesten Wert von Secrets Manager.
Wenn die Protokolle angezeigt werdenInvalid credentials, ist das bei der Stack-Erstellung eingegebene ServiceAccount Passwort möglicherweise falsch.
-
Öffnen Sie in der AWS Konsole den Secrets Manager.
-
Suchen Sie nach
directoryserviceServiceAccountPassword. Das Geheimnis sollte sein<stack name>-directoryservice-ServiceAccountPassword -
Öffnen Sie das Geheimnis, um die Detailseite anzuzeigen. Wählen Sie unter Geheimer Wert die Option Geheimen Wert abrufen und anschließend Klartext aus.
-
Wenn Sie das Passwort vergessen haben oder sich nicht sicher sind, ob das eingegebene Passwort korrekt ist, können Sie das Passwort in Active Directory und Secrets Manager zurücksetzen.
-
Um das Passwort zurückzusetzen inAWS Managed Microsoft AD:
-
Öffnen Sie die AWS Konsole und gehen Sie zuDirectory Service.
-
Wählen Sie die Verzeichnis-ID für Ihr RES-Verzeichnis aus und wählen Sie Aktionen.
-
Wählen Sie Benutzerkennwort zurücksetzen aus.
-
Geben Sie den ServiceAccount Nutzernamen ein.
-
Geben Sie ein neues Passwort ein und wählen Sie Passwort zurücksetzen.
-
-
So setzen Sie das Passwort in Secrets Manager zurück:
-
Öffnen Sie die AWS Konsole und gehen Sie zu Secrets Manager.
-
Suchen Sie nach
directoryserviceServiceAccountPassword. Das Geheimnis sollte sein<stack name>-directoryservice-ServiceAccountPassword -
Öffnen Sie das Geheimnis, um die Detailseite anzuzeigen. Wählen Sie unter Geheimer Wert die Option Geheimen Wert abrufen und anschließend Klartext aus.
-
Wählen Sie Bearbeiten aus.
-
Legen Sie ein neues Passwort für den ServiceAccount Benutzer fest und wählen Sie Speichern.
-
-
-
Wenn Sie den Wert aktualisiert haben, löschen Sie die derzeit laufenden Cluster-Manager- und VDC-Controller-Instanzen der Umgebung. Auto Scaling startet neue Instanzen mit dem neuesten Wert.
........................
Der CloudFormation Umgebungsstapel kann aufgrund eines Fehlers beim abhängigen Objekt nicht gelöscht werden
Wenn das Löschen des <env-name>-vdcvdcdcvhostsecuritygroup, könnte dies an einer Amazon EC2 EC2-Instance liegen, die mithilfe der Konsole in einem RES-created Subnetz oder einer Sicherheitsgruppe gestartet wurde. AWS
Um das Problem zu lösen, suchen und beenden Sie alle Amazon EC2 EC2-Instances, die auf diese Weise gestartet wurden. Anschließend können Sie mit dem Löschen der Umgebung fortfahren.
........................
Bei der Erstellung der Umgebung ist ein Fehler für den CIDR-Blockparameter aufgetreten
Beim Erstellen einer Umgebung wird ein Fehler für den CIDR-Blockparameter mit dem Antwortstatus [FAILED] angezeigt.
Beispiel für einen Fehler:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
Um das Problem zu lösen, ist das erwartete Format x.x.x. 0/24 oder x.x.x. 0/32
........................
CloudFormation Fehler bei der Stapelerstellung während der Umgebungserstellung
Das Erstellen einer Umgebung umfasst eine Reihe von Vorgängen zur Erstellung von Ressourcen. In einigen Regionen kann ein Kapazitätsproblem auftreten, das dazu führt, dass die CloudFormation Stack-Erstellung fehlschlägt.
Löschen Sie in diesem Fall die Umgebung und wiederholen Sie die Erstellung. Alternativ können Sie die Erstellung in einer anderen Region wiederholen.
........................
Die Erstellung eines Stacks für externe Ressourcen (Demo) schlägt mit AdDomainAdminNode CREATE_FAILED fehl
Wenn die Erstellung des Demo-Umgebungsstapels mit dem folgenden Fehler fehlschlägt, kann dies daran liegen, dass Amazon EC2-Patches während der Bereitstellung nach dem Start der Instance unerwartet ausgeführt wurden.
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
Um die Ursache des Fehlers zu ermitteln:
-
Überprüfen Sie im SSM State Manager, ob das Patchen konfiguriert ist und ob es für alle Instanzen konfiguriert ist.
-
Prüfen Sie in der RunCommand/Automation SSM-Ausführungshistorie, ob die Ausführung eines SSM-Dokuments im Zusammenhang mit dem Start einer Instanz zusammenfällt.
-
Überprüfen Sie in den Protokolldateien für die Amazon EC2 EC2-Instances der Umgebung die lokale Instance-Protokollierung, um festzustellen, ob die Instance während der Bereitstellung neu gestartet wurde.
Wenn das Problem durch das Patchen verursacht wurde, verzögern Sie das Patchen für die RES-Instances mindestens 15 Minuten nach dem Start.
........................
Probleme mit der Identitätsverwaltung
Die meisten Probleme mit Single Sign-On (SSO) und Identitätsmanagement treten aufgrund von Fehlkonfigurationen auf. Informationen zur Einrichtung Ihrer SSO-Konfiguration finden Sie unter:
Informationen zur Behebung anderer Probleme im Zusammenhang mit der Identitätsverwaltung finden Sie in den folgenden Themen zur Problembehandlung:
Themen
Wenn ich mich bei der Umgebung anmelde, kehre ich sofort zur Anmeldeseite zurück
Fehler „Benutzer nicht gefunden“ beim Versuch, sich anzumelden
Der Benutzer wurde in Active Directory hinzugefügt, fehlt aber in RES
Der Benutzer ist beim Erstellen einer Sitzung nicht verfügbar
Fehler beim Überschreiten der Größenbeschränkung im CloudWatch Cluster-Manager-Protokoll
........................
Ich bin nicht berechtigt, iam auszuführen: PassRole
Wenn Sie die Fehlermeldung erhalten, dass Sie nicht berechtigt sind, die iam: PassRole -Aktion auszuführen, müssen Ihre Richtlinien aktualisiert werden, damit Sie eine Rolle an RES übergeben können.
Bei einigen AWS Diensten können Sie eine bestehende Rolle an diesen Dienst übergeben, anstatt eine neue Servicerolle oder eine dienstverknüpfte Rolle zu erstellen. Hierzu benötigen Sie Berechtigungen für die Übergabe der Rolle an den Dienst.
Der folgende Beispielfehler tritt auf, wenn ein IAM-Benutzer namens marymajor versucht, die Konsole zu verwenden, um eine Aktion in RES auszuführen. Die Aktion erfordert jedoch, dass der Service über Berechtigungen verfügt, die durch eine Servicerolle gewährt werden. Mary besitzt keine Berechtigungen für die Übergabe der Rolle an den Dienst.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
In diesem Fall müssen Marys Richtlinien aktualisiert werden, damit sie die iam: -Aktion ausführen kann. PassRole Wenn Sie Hilfe benötigen, wenden Sie sich an Ihren AWS Administrator. Ihr Administrator hat Ihnen Ihre Anmeldeinformationen zur Verfügung gestellt.
........................
Ich möchte Personen außerhalb meinesAWSKonto, über das ich auf mein Forschungs- und Ingenieurstudio zugreifen kannAWSRessourcen
Sie können eine Rolle erstellen, mit der Benutzer in anderen Konten oder Personen außerhalb Ihrer Organisation auf Ihre Ressourcen zugreifen können. Sie können festlegen, wem die Übernahme der Rolle anvertraut wird. Im Fall von Diensten, die ressourcenbasierte Richtlinien oder Zugriffskontrolllisten (Access Control Lists, ACLs) verwenden, können Sie diese Richtlinien verwenden, um Personen Zugriff auf Ihre Ressourcen zu gewähren.
Weitere Informationen dazu finden Sie hier:
-
Informationen dazu, wie Sie den Zugriff auf Ihre Ressourcen über AWS Konten hinweg gewähren, die Sie besitzen, finden Sie im IAM-Benutzerhandbuch unter Gewähren des Zugriffs für einen IAM-Benutzer in einem anderen AWS Konto, das Sie besitzen.
-
Informationen dazu, wie Sie AWS Konten von Drittanbietern Zugriff auf Ihre Ressourcen gewähren, finden Sie im IAM-Benutzerhandbuch unter Zugriff auf AWS Konten, die Dritten gehören.
-
Informationen dazu, wie Sie Zugriff über einen Identitätsverbund gewähren, finden Sie unter Zugriff für extern authentifizierte Benutzer (Identitätsverbund) im IAM-Benutzerhandbuch.
-
Informationen zum Unterschied zwischen der Verwendung von Rollen und ressourcenbasierten Richtlinien für den kontoübergreifenden Zugriff finden Sie im IAM-Benutzerhandbuch unter Unterschiede zwischen IAM-Rollen und ressourcenbasierten Richtlinien.
........................
Wenn ich mich bei der Umgebung anmelde, kehre ich sofort zur Anmeldeseite zurück
Dieses Problem tritt auf, wenn Ihre SSO-Integration falsch konfiguriert ist. Um das Problem zu ermitteln, überprüfen Sie die Controller-Instanzprotokolle und überprüfen Sie die Konfigurationseinstellungen auf Fehler.
Um die Protokolle zu überprüfen:
-
Öffnen Sie die CloudWatch -Konsole
. -
Suchen Sie unter Protokollgruppen nach der Gruppe mit dem Namen
/.<environment-name>/cluster-manager -
Öffnen Sie die Protokollgruppe, um nach Fehlern in den Protokolldatenströmen zu suchen.
Um die Konfigurationseinstellungen zu überprüfen:
-
Öffnen Sie die DynamoDB-Konsole
-
Suchen Sie unter Tabellen die Tabelle mit dem Namen.
<environment-name>.cluster-settings -
Öffnen Sie die Tabelle und wählen Sie Tabellenelemente durchsuchen aus.
-
Erweitern Sie den Bereich Filter und geben Sie die folgenden Variablen ein:
-
Attributname — Schlüssel
-
Zustand — enthält
-
Wert — sso
-
-
Klicken Sie auf Ausführen.
-
Stellen Sie in der zurückgegebenen Zeichenfolge sicher, dass die SSO-Konfigurationswerte korrekt sind. Wenn sie falsch sind, ändern Sie den Wert des Schlüssels sso_enabled in False.
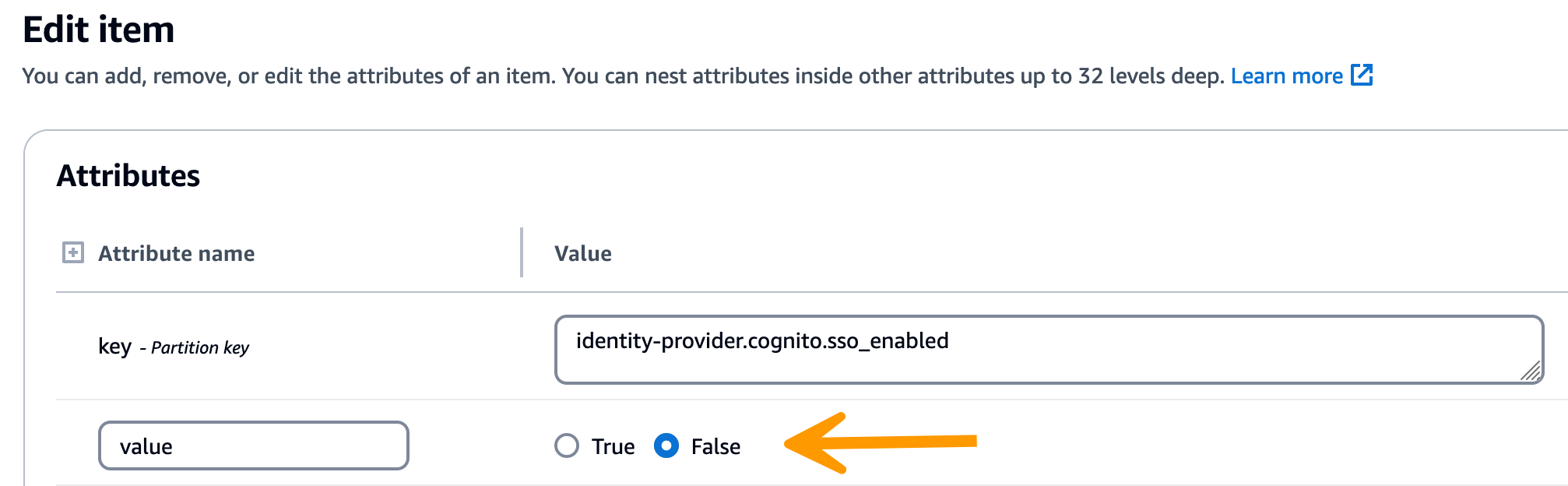
-
Kehren Sie zur RES-Benutzeroberfläche zurück, um SSO neu zu konfigurieren.
........................
Fehler „Benutzer nicht gefunden“ beim Versuch, sich anzumelden
Wenn ein Benutzer beim Versuch, sich an der RES-Schnittstelle anzumelden, den Fehler „Benutzer nicht gefunden“ erhält und der Benutzer in Active Directory präsent ist:
-
Wenn der Benutzer nicht in RES vorhanden ist und Sie ihn kürzlich zu AD hinzugefügt haben
-
Es ist möglich, dass der Benutzer noch nicht mit RES synchronisiert ist. RES synchronisiert stündlich, sodass Sie nach der nächsten Synchronisierung möglicherweise warten müssen, um zu überprüfen, ob der Benutzer hinzugefügt wurde. Um sofort zu synchronisieren, folgen Sie den Schritten unterDer Benutzer wurde in Active Directory hinzugefügt, fehlt aber in RES.
-
-
Wenn der Benutzer in RES präsent ist:
-
Stellen Sie sicher, dass die Attributzuordnung korrekt konfiguriert ist. Weitere Informationen finden Sie unter Konfiguration Ihres Identitätsanbieters für Single Sign-On (SSO).
-
Stellen Sie sicher, dass der SAML-Betreff und die SAML-E-Mail beide der E-Mail-Adresse des Benutzers zugeordnet sind.
-
........................
Der Benutzer wurde in Active Directory hinzugefügt, fehlt aber in RES
Anmerkung
Dieser Abschnitt bezieht sich auf RES 2024.10 und frühere Versionen. Für RES 2024.12 und später siehe. Wie führe ich die Synchronisierung manuell aus (Version 2024.12 und 2024.12.01) Für RES 2025.03 und höher siehe. Wie kann die Synchronisierung manuell gestartet oder gestoppt werden (Version 2025.03 und höher)
Wenn Sie dem Active Directory einen Benutzer hinzugefügt haben, dieser jedoch in RES fehlt, muss die AD-Synchronisierung ausgelöst werden. Die AD-Synchronisierung wird stündlich von einer Lambda-Funktion durchgeführt, die AD-Einträge in die RES-Umgebung importiert. Gelegentlich kommt es zu Verzögerungen, bis der nächste Synchronisierungsvorgang ausgeführt wird, nachdem Sie neue Benutzer oder Gruppen hinzugefügt haben. Sie können die Synchronisierung manuell über den Amazon Simple Queue Service initiieren.
Initiieren Sie den Synchronisierungsvorgang manuell:
-
Öffnen Sie die Amazon-SQS-Konsole
. -
Wählen Sie unter Warteschlangen die Option aus
<environment-name>-cluster-manager-tasks.fifo. -
Wählen Sie Nachrichten senden und empfangen.
-
Geben Sie für Nachrichtentext Folgendes ein:
{ "name": "adsync.sync-from-ad", "payload": {} } -
Geben Sie für Nachrichtengruppen-ID Folgendes ein:
adsync.sync-from-ad -
Geben Sie als Nachrichtendeduplizierungs-ID eine zufällige alphanumerische Zeichenfolge ein. Dieser Eintrag muss sich von allen Anrufen unterscheiden, die innerhalb der letzten fünf Minuten getätigt wurden. Andernfalls wird die Anfrage ignoriert.
........................
Der Benutzer ist beim Erstellen einer Sitzung nicht verfügbar
Wenn Sie als Administrator eine Sitzung erstellen, aber feststellen, dass ein Benutzer, der sich im Active Directory befindet, beim Erstellen einer Sitzung nicht verfügbar ist, muss sich der Benutzer möglicherweise zum ersten Mal anmelden. Sitzungen können nur für aktive Benutzer erstellt werden. Aktive Benutzer müssen sich mindestens einmal bei der Umgebung anmelden.
........................
Fehler beim Überschreiten der Größenbeschränkung im CloudWatch Cluster-Manager-Protokoll
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
Wenn Sie diesen Fehler im CloudWatch Cluster-Manager-Protokoll erhalten, hat die LDAP-Suche möglicherweise zu viele Benutzerdatensätze zurückgegeben. Um dieses Problem zu beheben, erhöhen Sie das Limit für LDAP-Suchergebnisse Ihres IDP.
........................
Speicher
Themen
........................
Ich habe das Dateisystem über RES erstellt, aber es wird nicht auf den VDI-Hosts bereitgestellt
Die Dateisysteme müssen sich im Status „Verfügbar“ befinden, bevor sie von VDI-Hosts bereitgestellt werden können. Gehen Sie wie folgt vor, um zu überprüfen, ob sich das Dateisystem im erforderlichen Zustand befindet.
Amazon EFS
-
Gehen Sie zur Amazon EFS-Konsole
. -
Vergewissern Sie sich, dass der Dateisystemstatus Verfügbar ist.
-
Wenn der Dateisystemstatus nicht verfügbar ist, warten Sie, bevor Sie VDI-Hosts starten.
Amazon FSx ONTAP
-
Gehen Sie zur Amazon FSx-Konsole
. -
Vergewissern Sie sich, dass der Status verfügbar ist.
-
Wenn der Status nicht verfügbar ist, warten Sie, bevor Sie VDI-Hosts starten.
........................
Ich habe ein Dateisystem über RES integriert, aber es wird nicht auf den VDI-Hosts bereitgestellt
Für die in RES integrierten Dateisysteme sollten die erforderlichen Sicherheitsgruppenregeln so konfiguriert sein, dass VDI-Hosts die Dateisysteme mounten können. Da diese Dateisysteme extern in RES erstellt werden, verwaltet RES die zugehörigen Sicherheitsgruppenregeln nicht.
Die Sicherheitsgruppe, die den integrierten Dateisystemen zugeordnet ist, sollte den folgenden eingehenden Datenverkehr zulassen:
NFS-Verkehr (Port: 2049) von den Linux-VDC-Hosts
SMB-Verkehr (Port: 445) von den Windows VDC-Hosts
........................
Ich kann von VDI-Hosts aus nicht read/write einschalten
ONTAP unterstützt den Sicherheitsstil UNIX, NTFS und MIXED für die Volumes. Die Sicherheitsstile bestimmen, welche Art von Berechtigungen ONTAP zur Steuerung des Datenzugriffs verwendet und welcher Clienttyp diese Berechtigungen ändern kann.
Wenn ein Volume beispielsweise den UNIX-Sicherheitsstil verwendet, können SMB-Clients aufgrund des Multiprotokollcharakters von ONTAP trotzdem auf Daten zugreifen (vorausgesetzt, sie authentifizieren und autorisieren). ONTAP verwendet jedoch UNIX-Berechtigungen, die nur UNIX-Clients mit systemeigenen Tools ändern können.
Beispiele für Anwendungsfälle im Umgang mit Berechtigungen
Verwenden eines Volumes im UNIX-Stil mit Linux-Workloads
Berechtigungen können vom Sudoer für andere Benutzer konfiguriert werden. Im Folgenden würden beispielsweise alle Mitglieder über <group-ID> volle read/write Berechtigungen für das /<project-name> Verzeichnis verfügen:
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Verwenden eines Datenträgers im NTFS-Stil bei Linux- und Windows-Workloads
Freigabeberechtigungen können mithilfe der Freigabeeigenschaften eines bestimmten Ordners konfiguriert werden. Wenn Sie beispielsweise einen Benutzer user_01 und einen Ordner angebenmyfolder, können Sie Berechtigungen für Full ControlChange, oder Read für Allow oder festlegenDeny:

Wenn das Volume sowohl von Linux- als auch von Windows-Clients verwendet werden soll, müssen wir auf der SVM eine Namenszuordnung einrichten, die jeden Linux-Benutzernamen demselben Benutzernamen mit dem NetBIOS-Domänennamenformat Domäne\ Benutzername zuordnet. Dies ist für die Übersetzung zwischen Linux- und Windows-Benutzern erforderlich. Weitere Informationen finden Sie unter Aktivieren von Multiprotokoll-Workloads mit Amazon FSx
........................
Ich habe Amazon FSx for NetApp ONTAP von RES aus erstellt, aber es ist meiner Domain nicht beigetreten
Wenn Sie Amazon FSx for NetApp ONTAP derzeit von der RES-Konsole aus erstellen, wird das Dateisystem bereitgestellt, aber es tritt der Domain nicht bei. Informationen zum Hinzufügen der erstellten ONTAP-Dateisystem-SVM zu Ihrer Domain finden Sie unter Hinzufügen von SVMs zu einem Microsoft Active Directory und folgen Sie den Schritten auf der Amazon
Nachdem es der Domäne hinzugefügt wurde, bearbeiten Sie den SMB-DNS-Konfigurationsschlüssel in der DynamoDB-Tabelle mit den Clustereinstellungen:
-
Gehen Sie zur Amazon DynamoDB DynamoDB-Konsole
. -
Wählen Sie Tabellen und dann.
<stack-name>-cluster-settings -
Erweitern Sie unter Tabellenelemente durchsuchen die Option Filter und geben Sie den folgenden Filter ein:
Attributname — Schlüssel
Bedingung — Entspricht
-
Wert -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
Wählen Sie den zurückgesandten Artikel aus und klicken Sie dann auf Aktionen, Artikel bearbeiten.
-
Aktualisieren Sie den Wert mit dem SMB-DNS-Namen, den Sie zuvor kopiert haben.
-
Klicken Sie auf Save and close.
Stellen Sie außerdem sicher, dass die dem Dateisystem zugeordnete Sicherheitsgruppe den in File System Access Control with Amazon VPC empfohlenen Datenverkehr zulässt. Neue VDI-Hosts, die das Dateisystem verwenden, können nun die zur Domäne gehörende SVM und das Dateisystem mounten.
Alternativ können Sie ein vorhandenes Dateisystem einbinden, das bereits mit Ihrer Domain verknüpft ist. Wählen Sie dazu unter Environment Management die Option Dateisysteme, Onboard-Dateisystem aus.
........................
-Snapshots
Themen
........................
Ein Snapshot hat den Status Fehlgeschlagen
Wenn ein Snapshot auf der Seite RES-Snapshots den Status Fehlgeschlagen hat, kann die Ursache ermittelt werden, indem Sie in der CloudWatch Amazon-Protokollgruppe für den Cluster-Manager nach dem Zeitpunkt suchen, zu dem der Fehler aufgetreten ist.
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
Ein Snapshot kann nicht angewendet werden, da die Protokolle darauf hinweisen, dass die Tabellen nicht importiert werden konnten.
Wenn ein Snapshot aus einer früheren Umgebung nicht in einer neuen Umgebung angewendet werden kann, suchen Sie in den CloudWatch Protokollen nach dem Cluster-Manager, um das Problem zu identifizieren. Wenn das Problem darauf hinweist, dass die erforderlichen Tabellen nicht importiert wurden, überprüfen Sie, ob sich der Snapshot in einem gültigen Zustand befindet.
-
Laden Sie die Datei metadata.json herunter und überprüfen Sie, ob die Datei ExportStatus für die verschiedenen Tabellen den Status ABGESCHLOSSEN hat. Stellen Sie sicher, dass das Feld für die verschiedenen Tabellen festgelegt ist
ExportManifest. Wenn Sie den oben genannten Feldsatz nicht finden, befindet sich der Snapshot in einem ungültigen Zustand und kann nicht mit der Funktion „Snapshot anwenden“ verwendet werden. -
Nachdem Sie die Erstellung eines Snapshots initiiert haben, stellen Sie sicher, dass der Snapshot-Status in RES auf ABGESCHLOSSEN wechselt. Die Erstellung eines Snapshots dauert bis zu 5 bis 10 Minuten. Laden Sie die Seite Snapshot-Verwaltung neu oder besuchen Sie sie erneut, um sicherzustellen, dass der Snapshot erfolgreich erstellt wurde. Dadurch wird sichergestellt, dass sich der erstellte Snapshot in einem gültigen Zustand befindet.
........................
Infrastruktur
........................
Load Balancer-Zielgruppen ohne fehlerfreie Instanzen
Wenn Probleme wie Serverfehlermeldungen in der Benutzeroberfläche angezeigt werden oder Desktop-Sitzungen keine Verbindung herstellen können, kann dies auf ein Problem in der Infrastruktur der Amazon EC2 EC2-Instances hinweisen.
Um die Ursache des Problems zu ermitteln, suchen Sie zunächst in der Amazon EC2 EC2-Konsole nach Amazon EC2 EC2-Instances, die anscheinend wiederholt beendet und durch neue Instances ersetzt werden. In diesem Fall kann die Ursache anhand der CloudWatch Amazon-Protokolle ermittelt werden.
Eine andere Methode besteht darin, die Load Balancer im System zu überprüfen. Ein Hinweis darauf, dass möglicherweise Systemprobleme vorliegen, ist, wenn ein Load Balancer auf der Amazon EC2 EC2-Konsole keine registrierten fehlerfreien Instances anzeigt.
Ein Beispiel für ein normales Erscheinungsbild finden Sie hier:

Wenn der Health-Eintrag 0 ist, bedeutet dies, dass keine Amazon EC2 EC2-Instance für die Bearbeitung von Anfragen verfügbar ist.
Wenn der Eintrag Unhealthy nicht 0 ist, deutet dies darauf hin, dass eine Amazon EC2 EC2-Instance möglicherweise zyklisch läuft. Dies kann daran liegen, dass die installierte Anwendungssoftware die Integritätsprüfungen nicht bestanden hat.
Wenn sowohl die Einträge „Gesund“ als auch „Unhealthy“ den Wert 0 haben, deutet dies auf eine mögliche Fehlkonfiguration des Netzwerks hin. Beispielsweise verfügen die öffentlichen und privaten Subnetze möglicherweise nicht über entsprechende AZs. Wenn dieser Zustand eintritt, wird auf der Konsole möglicherweise zusätzlicher Text angezeigt, der darauf hinweist, dass der Netzwerkstatus vorhanden ist.
........................
Virtuelle Desktops werden gestartet
Themen
Das Anmeldekonto für Windows Virtual Desktop ist auf Administrator eingestellt
Das Zertifikat läuft ab, wenn eine externe Ressource verwendet wird CertificateRenewalNode
Ein virtueller Desktop, der zuvor funktionierte, kann keine erfolgreiche Verbindung mehr herstellen
Nach der Anmeldung wird bei der VDI-Sitzung ein leerer Bildschirm angezeigt
........................
Das Anmeldekonto für Windows Virtual Desktop ist auf Administrator eingestellt
Wenn Sie einen virtuellen Windows-Desktop im RES-Webportal starten können, sein Anmeldekonto jedoch beim Herstellen der Verbindung auf Administrator gesetzt ist, wurde Ihr Windows VDI möglicherweise nicht erfolgreich dem Active Directory hinzugefügt.
Stellen Sie zur Überprüfung von der Amazon EC2 EC2-Konsole aus eine Verbindung zur Windows-Instance her und überprüfen Sie die Bootstrap-Protokolle unter. C:\Users\Administrator\RES\Bootstrap\virtual-desktop-host-windows\ Eine Fehlermeldung, die mit beginnt, [Join AD] authorization failed: weist darauf hin, dass die Instance dem AD nicht beitreten konnte. Weitere Informationen zu dem Fehler finden Sie im Cluster Manager, der sich CloudWatch unter dem Namen / der Protokollgruppe anmeldet:<res-environment-name>/cluster-manager
-
Insufficient permissions to modify computer account-
Dieser Fehler weist darauf hin, dass Ihr Dienstkonto nicht über die erforderlichen Berechtigungen verfügt, um Computer zum AD hinzuzufügen. Im Richten Sie ein Dienstkonto für Microsoft Active Directory ein Abschnitt finden Sie die für das Dienstkonto erforderlichen Berechtigungen.
-
-
Invalid Credentials-
Die Anmeldeinformationen Ihres Dienstkontos in AD sind abgelaufen oder Sie haben falsche Anmeldeinformationen angegeben. Um die Anmeldeinformationen Ihres Dienstkontos zu überprüfen oder zu aktualisieren, greifen Sie in der Secrets Manager-Konsole
auf den geheimen Schlüssel zu, der das Passwort speichert. Stellen Sie sicher, dass der ARN dieses Geheimnisses im Feld Service Account Credentials Secret ARN unter Active Directory-Domäne auf der Seite Identity Management Ihrer RES-Umgebung korrekt ist.
-
........................
Das Zertifikat läuft ab, wenn eine externe Ressource verwendet wird CertificateRenewalNode
Wenn Sie das Rezept für externe Ressourcen bereitgestellt haben und "The connection has been closed. Transport error" beim Herstellen einer Verbindung zu Linux-VDIs ein Fehler auftritt, ist die wahrscheinlichste Ursache ein abgelaufenes Zertifikat, das aufgrund eines falschen Pip-Installationspfads unter Linux nicht automatisch aktualisiert wird. Zertifikate laufen nach 3 Monaten ab.
Die CloudWatch Amazon-Protokollgruppe protokolliert <envname>/vdc/dcv-connection-gateway
| 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Error in connection task: TLS handshake error: received fatal alert: CertificateUnknown | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 | | 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Certificate error: AlertReceived(CertificateUnknown) | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 |
So beheben Sie das Problem:
-
Gehen Sie in Ihrem AWS Konto zu EC2
. Wenn eine Instanz benannt ist *-CertificateRenewalNode-*, beenden Sie die Instanz. -
Gehe zu Lambda
. Sie sollten eine Lambda-Funktion mit dem Namen sehen. *-CertificateRenewalLambda-*Suchen Sie im Lambda-Code nach etwas Ähnlichem wie dem Folgenden:export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py python3 ./get-pip.py pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates git clone https://github.com/Neilpang/acme.sh.git cd acme.sh -
Die neueste Stack-Vorlage für Zertifikate für externe Ressourcen finden Sie hier.
Suchen Sie den Lambda-Code in der Vorlage: Ressourcen → CertificateRenewalLambda→ Eigenschaften → Code. Möglicherweise finden Sie etwas Ähnliches wie das Folgende: sudo yum install -y wget export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py mkdir -p pip python3 ./get-pip.py --target $PWD/pip $PWD/pip/bin/pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates VERSION=3.1.0 wget https://github.com/acmesh-official/acme.sh/archive/refs/tags/$VERSION.tar.gz -O acme-$VERSION.tar.gz tar -xvf acme-$VERSION.tar.gz cd acme.sh-$VERSION -
Ersetzen Sie den Abschnitt aus Schritt 2 in der
*-CertificateRenewalLambda-*Lambda-Funktion durch den Code aus Schritt 3. Wählen Sie Deploy aus und warten Sie, bis die Codeänderung wirksam wird. -
Um die Lambda-Funktion manuell auszulösen, wechseln Sie zur Registerkarte Test und wählen Sie dann Test aus. Es sind keine zusätzlichen Eingaben erforderlich. Dadurch sollte eine EC2-Zertifikatsinstanz erstellt werden, die das Zertifikat und die PrivateKey Geheimnisse in Secret Manager aktualisiert.
-
Beenden Sie die bestehende dcv-gateway-Instanz:
<env-name>-vdc-gateway
........................
Ein virtueller Desktop, der zuvor funktionierte, kann keine erfolgreiche Verbindung mehr herstellen
Wenn eine Desktop-Verbindung geschlossen wird oder Sie keine Verbindung mehr herstellen können, liegt das Problem möglicherweise daran, dass die zugrunde liegende Amazon EC2 EC2-Instance ausfällt oder die Amazon EC2 EC2-Instance außerhalb der RES-Umgebung beendet oder gestoppt wurde. Der Status der Admin-Benutzeroberfläche zeigt möglicherweise weiterhin den Status Bereit an, aber Versuche, eine Verbindung herzustellen, schlagen fehl.
Die Amazon EC2 EC2-Konsole sollte verwendet werden, um festzustellen, ob die Instance beendet oder gestoppt wurde. Wenn sie gestoppt wurde, versuchen Sie erneut, sie zu starten. Wenn der Status beendet ist, muss ein weiterer Desktop erstellt werden. Alle Daten, die im Home-Verzeichnis des Benutzers gespeichert wurden, sollten weiterhin verfügbar sein, wenn die neue Instanz gestartet wird.
Wenn die Instanz, die zuvor ausgefallen ist, immer noch auf der Admin-Benutzeroberfläche angezeigt wird, muss sie möglicherweise über die Admin-Benutzeroberfläche beendet werden.
........................
Ich kann nur 5 virtuelle Desktops starten
Das Standardlimit für die Anzahl der virtuellen Desktops, die ein Benutzer starten kann, ist 5. Dies kann von einem Administrator über die Admin-Benutzeroberfläche wie folgt geändert werden:
Gehe zu den Desktop-Einstellungen.
Wählen Sie die Registerkarte Allgemein aus.
Wählen Sie das Bearbeitungssymbol rechts neben „Standardmäßig zulässige Sitzungen pro Benutzer pro Projekt“ und ändern Sie den Wert auf den gewünschten neuen Wert.
Wählen Sie Absenden aus.
Aktualisieren Sie die Seite, um zu bestätigen, dass die neue Einstellung vorhanden ist.
........................
Windows-Desktop-Verbindungsversuche schlagen fehl mit der Meldung „Die Verbindung wurde geschlossen“. Transportfehler“
Wenn eine Windows-Desktop-Verbindung mit dem UI-Fehler „Die Verbindung wurde geschlossen“ fehlschlägt. „Transportfehler“: Die Ursache kann auf ein Problem in der DCV-Serversoftware zurückzuführen sein, das mit der Zertifikatserstellung auf der Windows-Instanz zusammenhängt.
Die CloudWatch Amazon-Protokollgruppe protokolliert <envname>/vdc/dcv-connection-gateway möglicherweise den Fehler beim Verbindungsversuch mit Meldungen, die den folgenden ähneln:
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
In diesem Fall besteht eine Lösung möglicherweise darin, den SSM Session Manager zu verwenden, um eine Verbindung zur Windows-Instance herzustellen und die folgenden 2 zertifikatsbezogenen Dateien zu entfernen:
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
Die Dateien sollten automatisch neu erstellt werden und ein nachfolgender Verbindungsversuch könnte erfolgreich sein.
Wenn diese Methode das Problem behebt und wenn bei Neustarts von Windows-Desktops derselbe Fehler auftritt, verwenden Sie die Funktion „Software-Stack erstellen“, um einen neuen Windows-Softwarestack der festen Instanz mit den neu generierten Zertifikatsdateien zu erstellen. Dadurch kann ein Windows-Softwarestack entstehen, der für erfolgreiche Starts und Verbindungen verwendet werden kann.
........................
VDIs stecken im Bereitstellungsstatus fest
Wenn ein Desktop-Start in der Admin-Benutzeroberfläche im Bereitstellungsstatus verbleibt, kann dies mehrere Gründe haben.
Um die Ursache zu ermitteln, überprüfen Sie die Protokolldateien auf der Desktop-Instanz und suchen Sie nach Fehlern, die das Problem verursachen könnten. Dieses Dokument enthält eine Liste von Protokolldateien und CloudWatch Amazon-Protokollgruppen, die relevante Informationen im Abschnitt Nützliche Protokoll- und Ereignisinformationsquellen enthalten.
Im Folgenden sind mögliche Ursachen für dieses Problem aufgeführt.
-
Die verwendete AMI-ID wurde als Software-Stack registriert, wird aber von RES nicht unterstützt.
Das Bootstrap-Bereitstellungsskript konnte nicht abgeschlossen werden, da das Amazon Machine Image (AMI) nicht über die erwartete Konfiguration oder die erforderlichen Tools verfügt. Die Protokolldateien auf der Instance, z. B.
/root/bootstrap/logs/auf einer Linux-Instance, können diesbezüglich nützliche Informationen enthalten. AMI-IDs aus dem AWS Marketplace funktionieren möglicherweise nicht für RES-Desktop-Instances. Sie müssen getestet werden, um zu bestätigen, ob sie unterstützt werden. -
Benutzerdatenskripts werden nicht ausgeführt, wenn die virtuelle Windows-Desktop-Instanz von einem benutzerdefinierten AMI aus gestartet wird.
Standardmäßig werden Benutzerdatenskripts einmal ausgeführt, wenn eine Amazon EC2 EC2-Instance gestartet wird. Wenn Sie ein AMI aus einer vorhandenen virtuellen Desktop-Instance erstellen, dann einen Software-Stack beim AMI registrieren und versuchen, einen anderen virtuellen Desktop mit diesem Software-Stack zu starten, werden Benutzerdatenskripts auf der neuen virtuellen Desktop-Instance nicht ausgeführt.
Um das Problem zu beheben, öffnen Sie ein PowerShell Befehlsfenster als Administrator auf der ursprünglichen virtuellen Desktop-Instance, mit der Sie das AMI erstellt haben, und führen Sie den folgenden Befehl aus:
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –ScheduleErstellen Sie dann ein neues AMI aus der Instance. Sie können das neue AMI verwenden, um Software-Stacks zu registrieren und anschließend neue virtuelle Desktops zu starten. Beachten Sie, dass Sie denselben Befehl auch für die Instance ausführen können, die im Bereitstellungsstatus verbleibt, und die Instance neu starten können, um die virtuelle Desktop-Sitzung zu reparieren. Beim Starten eines anderen virtuellen Desktops über das falsch konfigurierte AMI treten Sie jedoch erneut auf dasselbe Problem.
........................
VDIs geraten nach dem Start in den Fehlerstatus
- Mögliches Problem 1: Das Home-Dateisystem hat ein Verzeichnis für den Benutzer mit unterschiedlichen POSIX-Berechtigungen.
-
Dies könnte das Problem sein, mit dem Sie konfrontiert sind, wenn die folgenden Szenarien zutreffen:
-
Die bereitgestellte RES-Version ist 2024.01 oder höher.
-
Während der Bereitstellung des RES-Stacks
EnableLdapIDMappingwurde das Attribut für auf gesetzt.True -
Das bei der Bereitstellung des RES-Stacks angegebene Home-Dateisystem wurde in einer Version vor RES 2024.01 oder in einer früheren Umgebung mit der Einstellung auf verwendet.
EnableLdapIDMappingFalse
Lösungsschritte: Löschen Sie die Benutzerverzeichnisse im Dateisystem.
-
SSM zum Cluster-Manager-Host.
-
cd /home. -
ls- sollte Verzeichnisse mit Verzeichnisnamen auflisten, die mit Benutzernamen übereinstimmen, wieadmin1,admin2.. und so weiter. -
Löscht die Verzeichnisse,
sudo rm -r 'dir_name'. Löschen Sie nicht die Verzeichnisse ssm-user und ec2-user. -
Wenn die Benutzer bereits mit der neuen Umgebung synchronisiert sind, löschen Sie die Benutzer aus der DDB-Tabelle des Benutzers (außer clusteradmin).
-
AD-Synchronisierung initiieren —
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-adim Cluster-Manager Amazon EC2 ausführen. -
Starten Sie die VDI-Instanz im
ErrorStatus von der RES-Webseite aus neu. Stellen Sie sicher, dass der VDI in etwa 20 Minuten in denReadyStatus übergeht.
-
........................
Nach der Anmeldung wird bei der VDI-Sitzung ein leerer Bildschirm angezeigt
Wenn eine VDI-Sitzung mit dem Typ Konsolensitzung leer ist und nach der Anmeldung nicht reagiert, bedeutet dies, dass der X-Server defekt ist. Dies ist wahrscheinlich auf ein Betriebssystemproblem zurückzuführen, bei dem DCV versucht, den Desktop zu streamen, aber es gibt keinen zum Streamen. Die wahrscheinlichste Ursache dafür ist ein Problem mit der Xorg-Konfiguration. Der folgende Befehl kann ausgeführt werden, um sich weniger auf die Xorg-Standardkonfiguration zu verlassen.
Debian-basiertes Linux:
dpkg-divert --package nice-xdcv --divert /usr/bin/Xorg.orig --rename /usr/bin/Xorg ln -sf /usr/bin/Xdcv-console /usr/bin/Xorg
Linux auf Red Hat-Basis:
rpm -q --whatprovides /usr/bin/Xorg && \ cp /usr/bin/Xorg /usr/bin/Xorg.orig && \ ln -sf /usr/bin/Xdcv-console /usr/bin/Xorg
........................
Komponente für virtuelle Desktops
Themen
Die Amazon EC2 EC2-Instance wird in der Konsole wiederholt als beendet angezeigt
Das Projekt erscheint nicht im Pulldown, wenn Sie den Software-Stack bearbeiten, um es hinzuzufügen
Probleme mit den DHCP-Optionen bei der external/customer AD-Konfiguration
Firefox-Fehler MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
........................
Die Amazon EC2 EC2-Instance wird in der Konsole wiederholt als beendet angezeigt
Wenn eine Infrastruktur-Instance in der Amazon EC2 EC2-Konsole wiederholt als beendet angezeigt wird, kann die Ursache mit ihrer Konfiguration zusammenhängen und vom Typ der Infrastruktur-Instance abhängen. Im Folgenden finden Sie Methoden, um die Ursache zu ermitteln.
Wenn die vdc-controller-Instance in der Amazon EC2 EC2-Konsole wiederholt den Status „Beendet“ anzeigt, kann dies an einem falschen Secret-Tag liegen. Geheimnisse, die von RES verwaltet werden, haben Tags, die als Teil der IAM-Zugriffskontrollrichtlinien verwendet werden, die den Amazon EC2 EC2-Infrastruktur-Instances zugeordnet sind. Wenn der vdc-Controller zyklisch läuft und der folgende Fehler in der CloudWatch Protokollgruppe erscheint, kann dies daran liegen, dass ein Geheimnis nicht korrekt markiert wurde. Beachten Sie, dass das Geheimnis mit dem folgenden Tag versehen werden muss:
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
Die CloudWatch Amazon-Protokollmeldung für diesen Fehler wird etwa wie folgt aussehen:
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Überprüfen Sie die Tags auf der Amazon EC2 EC2-Instance und vergewissern Sie sich, dass sie mit der obigen Liste übereinstimmen.
........................
Die vdc-Controller-Instanz läuft, weil sie dem AD nicht beitreten konnte. /Das eVDI-Modul zeigt die fehlgeschlagene API-Zustandsprüfung
Wenn das eVDI-Modul die Zustandsprüfung nicht besteht, wird im Abschnitt Umgebungsstatus Folgendes angezeigt.

In diesem Fall besteht der allgemeine Pfad zum Debuggen darin, in die CloudWatch<env-name>/cluster-manager
Mögliche Probleme:
-
Wenn die Protokolle den Text enthalten
Insufficient permissions, stellen Sie sicher, dass der ServiceAccount Benutzername, der bei der Erstellung des Res-Stacks angegeben wurde, richtig geschrieben ist.Beispiel für eine Protokollzeile:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
Sie können über die SecretsManager Konsole
auf den bei der RES-Bereitstellung angegebenen ServiceAccount Benutzernamen zugreifen. Suchen Sie das entsprechende Geheimnis im Secrets Manager und wählen Sie Retrieve Plain Text. Wenn der Benutzername falsch ist, wählen Sie Bearbeiten, um den Geheimwert zu aktualisieren. Beenden Sie die aktuellen Cluster-Manager- und VDC-Controller-Instanzen. Die neuen Instanzen werden sich in einem stabilen Zustand befinden. -
Der Benutzername muss "ServiceAccount" lauten, wenn Sie die Ressourcen verwenden, die durch den bereitgestellten externen Ressourcenstapel erstellt wurden. Wenn der
DisableADJoinParameter bei der Bereitstellung von RES auf False gesetzt wurde, stellen Sie sicher, dass der Benutzer ServiceAccount "" über die erforderlichen Berechtigungen zum Erstellen von Computerobjekten im AD verfügt.
-
-
Wenn der verwendete Benutzername korrekt war, die Protokolle jedoch den Text enthalten
Invalid credentials, ist das von Ihnen eingegebene Passwort möglicherweise falsch oder abgelaufen.Beispiel für eine Protokollzeile:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
Sie können das Passwort, das Sie bei der Erstellung der Umgebung eingegeben haben, lesen, indem Sie in der Secrets Manager-Konsole
auf das Geheimnis zugreifen, das das Passwort speichert. Wählen Sie das Geheimnis aus (z. B. <env_name>directoryserviceServiceAccountPassword) und wählen Sie Klartext abrufen aus. -
Wenn das Passwort im Secret falsch ist, wählen Sie Bearbeiten, um den Wert im Secret zu aktualisieren. Beenden Sie die aktuellen Cluster-Manager- und VDC-Controller-Instanzen. Die neuen Instanzen verwenden das aktualisierte Passwort und befinden sich in einem stabilen Zustand.
-
Wenn das Passwort korrekt ist, kann es sein, dass das Passwort im verbundenen Active Directory abgelaufen ist. Sie müssen zuerst das Passwort im Active Directory zurücksetzen und dann das Geheimnis aktualisieren. Sie können das Benutzerkennwort im Active Directory von der Directory Service Console
aus zurücksetzen: -
Wählen Sie die entsprechende Verzeichnis-ID
-
Wählen Sie Aktionen, Benutzerkennwort zurücksetzen und füllen Sie dann das Formular mit dem Benutzernamen (z. B. "ServiceAccount„) und dem neuen Passwort aus.
-
Wenn sich das neu eingestellte Passwort vom vorherigen Passwort unterscheidet, aktualisieren Sie das Passwort im entsprechenden Secret Manager-Geheimnis (z.
<env_name>directoryserviceServiceAccountPasswordB. -
Beenden Sie die aktuellen Cluster-Manager- und VDC-Controller-Instanzen. Die neuen Instanzen werden sich in einem stabilen Zustand befinden.
-
-
........................
Das Projekt erscheint nicht im Pulldown, wenn Sie den Software-Stack bearbeiten, um es hinzuzufügen
Dieses Problem kann mit dem folgenden Problem im Zusammenhang mit der Synchronisierung des Benutzerkontos mit AD zusammenhängen. Wenn dieses Problem auftritt, überprüfen Sie die CloudWatch Amazon-Protokollgruppe des Cluster-Managers auf den Fehler "<user-home-init> account not available yet. waiting for user to be synced", um festzustellen, ob die Ursache dieselbe ist oder zusammenhängt.
........................
Cluster-Manager Amazon CloudWatch Log zeigt „<>User-Home-Init-Konto noch nicht verfügbar. wartet darauf, dass der Benutzer synchronisiert wird“ (wobei das Konto ein Benutzername ist)
Der SQS-Abonnent ist beschäftigt und steckt in einer Endlosschleife fest, weil er nicht auf das Benutzerkonto zugreifen kann. Dieser Code wird ausgelöst, wenn versucht wird, während der Benutzersynchronisierung ein Home-Dateisystem für einen Benutzer zu erstellen.
Der Grund, warum es nicht in der Lage ist, auf das Benutzerkonto zuzugreifen, ist möglicherweise, dass RES für das verwendete AD nicht korrekt konfiguriert wurde. Ein Beispiel könnte sein, dass der bei der Erstellung der BI/RES Umgebung verwendete ServiceAccountCredentialsSecretArn Parameter nicht der richtige Wert war.
........................
Beim Anmeldeversuch wird auf dem Windows-Desktop angezeigt: „Ihr Konto wurde deaktiviert. Bitte wenden Sie sich an Ihren Administrator.“

Wenn sich der Benutzer auf einem gesperrten Bildschirm nicht wieder anmelden kann, kann dies darauf hindeuten, dass der Benutzer in dem für RES konfigurierten AD deaktiviert wurde, nachdem er sich erfolgreich über SSO angemeldet hat.
Die SSO-Anmeldung sollte fehlschlagen, wenn das Benutzerkonto in AD deaktiviert wurde.
........................
Probleme mit den DHCP-Optionen bei der external/customer AD-Konfiguration
Wenn Sie bei der Verwendung von RES "The connection has been closed. Transport
error" mit Ihrem eigenen Active Directory auf einen Fehler bei virtuellen Windows-Desktops stoßen, suchen Sie im CloudWatch Amazon-Protokoll von dcv-connection-gateway nach etwas Ähnlichem wie dem Folgenden:
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
Wenn Sie einen AD-Domänencontroller für Ihre DHCP-Optionen für Ihre eigene VPC verwenden, müssen Sie:
-
Fügen Sie den beiden AmazonProvided Domain-Controller-IPs DNS hinzu.
-
Setzen Sie den Domainnamen auf ec2.internal.
Ein Beispiel wird hier gezeigt. Ohne diese Konfiguration gibt der Windows-Desktop einen Transportfehler RES/DCV aus, weil nach dem Hostnamen ip-10-0-x-xx.ec2.internal gesucht wird.

........................
Firefox-Fehler MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Wenn Sie den Firefox-Webbrowser verwenden, wird möglicherweise die Fehlermeldung vom Typ MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING angezeigt, wenn Sie versuchen, eine Verbindung zu einem virtuellen Desktop herzustellen.
Die Ursache ist, dass der RES-Webserver mit TLS + Stapling On eingerichtet ist, aber nicht mit Stapling Validation reagiert (siehe. https://support.mozilla.org/en-US/questions/1372483
Sie können dieses Problem beheben, indem Sie den Anweisungen unter folgen:. https://really-simple-ssl.com/mozilla_pkix_error_required_tls_feature_missing
........................
Löschen von Umgebungen
Themen
........................
Der res-xxx-cluster-Stack befindet sich im Status „DELETE_FAILED“ und kann aufgrund des Fehlers „Rolle ist ungültig oder kann nicht angenommen werden“ nicht manuell gelöscht werden
Wenn Sie feststellen, dass sich der Stack „res-xxx-cluster“ im Status „DELETE_FAILED“ befindet und nicht manuell gelöscht werden kann, können Sie die folgenden Schritte ausführen, um ihn zu löschen.
Wenn Sie sehen, dass sich der Stack im Status „DELETE_FAILED“ befindet, versuchen Sie zunächst, ihn manuell zu löschen. Möglicherweise wird ein Dialogfeld angezeigt, in dem Delete Stack bestätigt wird. Wählen Sie Löschen aus.
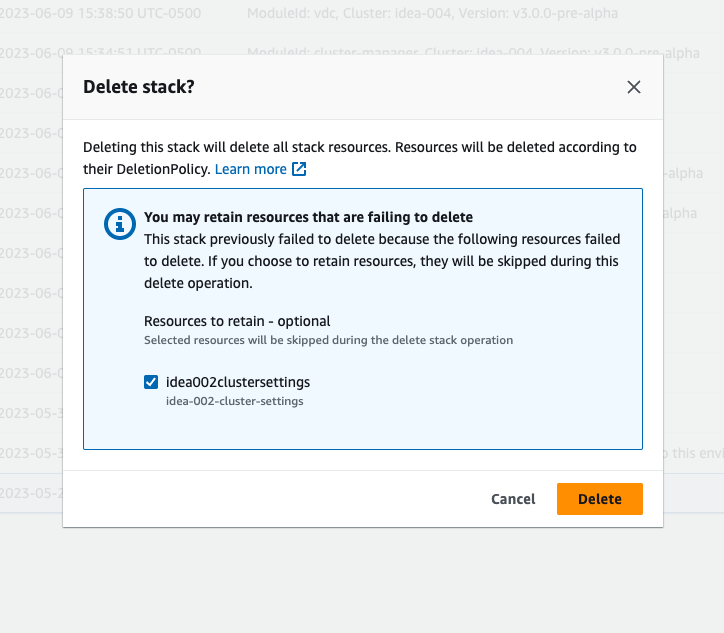
Selbst wenn Sie alle erforderlichen Stack-Ressourcen löschen, wird manchmal immer noch die Meldung angezeigt, dass Sie Ressourcen auswählen müssen, die beibehalten werden sollen. Wählen Sie in diesem Fall alle Ressourcen als „beizubehaltende Ressourcen“ aus und klicken Sie auf Löschen.
Möglicherweise wird ein Fehler angezeigt, der wie folgt aussieht Role: arn:aws:iam::... is Invalid or cannot
be assumed
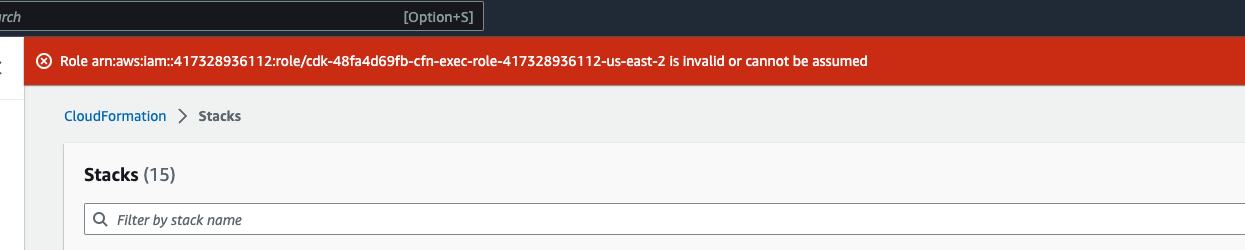
Das bedeutet, dass die Rolle, die zum Löschen des Stacks erforderlich ist, zuerst gelöscht wurde, bevor der Stapel gelöscht wurde. Um dies zu umgehen, kopieren Sie den Namen der Rolle. Gehen Sie zur IAM-Konsole und erstellen Sie mithilfe der folgenden Parameter eine Rolle mit diesem Namen:
-
Wählen Sie für den Typ Vertrauenswürdige Entität die Option AWSService aus.
-
Wählen Sie für Anwendungsfall unter
Use cases for otherAWS servicesWählen ausCloudFormation.

Wählen Sie Weiter aus. Stellen Sie sicher, dass Sie den Rollen '' und AWSCloudFormationFullAccess 'AdministratorAccess' die Berechtigungen geben. Ihre Bewertungsseite sollte so aussehen:

Gehen Sie dann zurück zur CloudFormation Konsole und löschen Sie den Stack. Sie sollten es jetzt löschen können, seit Sie die Rolle erstellt haben. Gehen Sie abschließend zur IAM-Konsole und löschen Sie die von Ihnen erstellte Rolle.
........................
Protokolle sammeln
Von der EC2-Konsole aus bei einer EC2-Instance anmelden
-
Folgen Sie diesen Anweisungen, um sich bei Ihrer Linux EC2-Instance anzumelden.
-
Folgen Sie diesen Anweisungen, um sich bei Ihrer Windows EC2-Instance anzumelden. Öffnen Sie dann Windows, PowerShell um beliebige Befehle auszuführen.
Sammeln von Infrastruktur-Hostprotokollen
-
Cluster-manager: Rufen Sie Protokolle für den Clustermanager von den folgenden Orten ab und hängen Sie sie an das Ticket an.
-
Alle Protokolle aus der CloudWatch Protokollgruppe
<env-name>/cluster-manager. -
Alle Protokolle im
/root/bootstrap/logsVerzeichnis auf der<env-name>-cluster-managerEC2-Instance. Folgen Sie den Anweisungen unter „Von der EC2-Konsole aus bei einer EC2-Instance anmelden“ am Anfang dieses Abschnitts, um sich bei Ihrer Instance anzumelden.
-
-
Vdc-controller: Rufen Sie die Logs für den vdc-Controller von den folgenden Stellen ab und hängen Sie sie an das Ticket an.
-
Alle Protokolle aus der CloudWatch Protokollgruppe.
<env-name>/vdc-controller -
Alle Protokolle im
/root/bootstrap/logsVerzeichnis auf der<env-name>-vdc-controllerEC2-Instance. Folgen Sie den Anweisungen unter „Von der EC2-Konsole aus bei einer EC2-Instance anmelden“ am Anfang dieses Abschnitts, um sich bei Ihrer Instance anzumelden.
-
Eine Möglichkeit, die Protokolle einfach abzurufen, besteht darin, den Anweisungen im Protokolle von Linux EC2-Instances werden heruntergeladen Abschnitt zu folgen. Der Modulname wäre der Instanzname.
Sammeln von VDI-Protokollen
- Identifizieren Sie die entsprechende Amazon EC2 EC2-Instance
-
Wenn ein Benutzer einen VDI mit einem Sitzungsnamen starten würde
VDI1, wäre der entsprechende Name der Instance auf der Amazon EC2 EC2-Konsole.<env-name>-VDI1-<user name> - Sammeln Sie Linux-VDI-Protokolle
-
Melden Sie sich von der Amazon EC2 EC2-Konsole aus bei der entsprechenden Amazon EC2 EC2-Instance an, indem Sie den Anweisungen folgen, die am Anfang dieses Abschnitts unter „Von der EC2-Konsole aus bei einer EC2-Instance anmelden“ verlinkt sind. Rufen Sie alle Protokolle unter den
/var/log/dcv/Verzeichnissen/root/bootstrap/logsund auf der VDI Amazon EC2 EC2-Instance ab.Eine Möglichkeit, die Protokolle abzurufen, besteht darin, sie auf S3 hochzuladen und dann von dort herunterzuladen. Dazu können Sie die folgenden Schritte ausführen, um alle Protokolle aus einem Verzeichnis abzurufen und sie dann hochzuladen:
-
Gehen Sie wie folgt vor, um die DCV-Protokolle in das
/root/bootstrap/logsVerzeichnis zu kopieren:sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
Folgen Sie nun den im nächsten Abschnitt aufgeführten SchrittenVDI-Protokolle werden heruntergeladen, um die Protokolle herunterzuladen.
-
- Sammeln Sie Windows VDI-Protokolle
-
Melden Sie sich von der Amazon EC2 EC2-Konsole aus bei der entsprechenden Amazon EC2 EC2-Instance an, indem Sie den Anweisungen folgen, die am Anfang dieses Abschnitts unter „Von der EC2-Konsole aus bei einer EC2-Instance anmelden“ verlinkt sind. Rufen Sie alle Protokolle unter dem
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\Verzeichnis auf der VDI EC2-Instance ab.Eine Möglichkeit, die Protokolle abzurufen, besteht darin, sie auf S3 hochzuladen und dann von dort herunterzuladen. Folgen Sie dazu den im nächsten Abschnitt aufgeführten SchrittenVDI-Protokolle werden heruntergeladen.
........................
VDI-Protokolle werden heruntergeladen
Aktualisieren Sie die IAM-Rolle der VDI EC2-Instanz, um den S3-Zugriff zu ermöglichen.
Gehen Sie zur EC2-Konsole und wählen Sie Ihre VDI-Instanz aus.
Wählen Sie die IAM-Rolle aus, die sie verwendet.
-
Wählen Sie im Dropdownmenü Berechtigungen hinzufügen im Abschnitt Berechtigungsrichtlinien die Option Richtlinien anhängen aus und wählen Sie dann die AmazonS3FullAccessRichtlinie aus.
Wählen Sie Berechtigungen hinzufügen aus, um diese Richtlinie anzuhängen.
-
Folgen Sie anschließend je nach VDI-Typ den unten aufgeführten Schritten, um die Protokolle herunterzuladen. Der Modulname wäre der Instanzname.
-
Bearbeiten Sie abschließend die Rolle, um die
AmazonS3FullAccessRichtlinie zu entfernen.
Anmerkung
Alle VDIs verwenden dieselbe IAM-Rolle, nämlich <env-name>-vdc-host-role-<region>
........................
Protokolle von Linux EC2-Instances werden heruntergeladen
Melden Sie sich bei der EC2-Instance an, von der Sie Logs herunterladen möchten, und führen Sie die folgenden Befehle aus, um alle Logs in einen S3-Bucket hochzuladen:
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
Gehen Sie danach zur S3-Konsole, wählen Sie den Bucket mit dem Namen aus <environment_name>-cluster-<region>-<aws_account_number> und laden Sie die zuvor hochgeladene <module_name>_logs.tar.gz Datei herunter.
........................
Protokolle von Windows EC2-Instances werden heruntergeladen
Melden Sie sich bei der EC2-Instance an, von der Sie Protokolle herunterladen möchten, und führen Sie die folgenden Befehle aus, um alle Protokolle in einen S3-Bucket hochzuladen:
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
Gehen Sie danach zur S3-Konsole, wählen Sie den Bucket mit dem Namen aus <environment_name>-cluster-<region>-<aws_account_number> und laden Sie die zuvor hochgeladene <module_name>_logs.zip Datei herunter.
........................
Sammeln von ECS-Protokollen für den WaitCondition Fehler
-
Gehen Sie zum bereitgestellten Stack und wählen Sie die Registerkarte Ressourcen aus.
-
Erweitern Sie Deploy ResearchAndEngineeringStudio→ → Installer → Tasks CreateTaskDef→ CreateContainer→ und wählen Sie die Protokollgruppe aus LogGroup, um die CloudWatch Logs zu öffnen.
-
Besorgen Sie sich das neueste Protokoll aus dieser Protokollgruppe.
........................
Fehler beim Löschen der Netzwerkschnittstelle
Wenn Sie im Abschnitt Ereignisse beim detachvpcfromlambdacustomresource Löschen des RES-Finalizer-Stacks einen Löschfehler feststellen, bedeutet dies höchstwahrscheinlich, dass der Lambda-Service die an RES-Lambdas angeschlossenen Netzwerkschnittstellen entweder nicht oder nicht rechtzeitig gelöscht hat.
Sie können diese veralteten Netzwerkschnittstellen manuell löschen, indem Sie in der Amazon EC2 EC2-KonsoleAWS Lambda VPC ENI- Es sollten bis zu 14 Netzwerkschnittstellen vorhanden sein, es könnten jedoch auch weniger sein, je nachdem, wie viele Lambda erfolgreich löschen konnte. Löschen Sie diese Netzwerkschnittstellen manuell und starten Sie dann das Löschen des RES-Stacks erneut.{RES-Environment-Name}
Demo-Umgebung
Themen
........................
Anmeldefehler in der Demo-Umgebung bei der Bearbeitung der Authentifizierungsanfrage an den Identitätsanbieter
Problem
Wenn Sie versuchen, sich anzumelden und die Meldung „Unerwarteter Fehler bei der Bearbeitung der Authentifizierungsanfrage an den Identitätsanbieter“ angezeigt wird, sind Ihre Passwörter möglicherweise abgelaufen. Dies kann entweder das Passwort für den Benutzer sein, mit dem Sie sich anmelden möchten, oder Ihr Directory Service Directory-Dienstkonto.
Schadensbegrenzung
-
Setzen Sie die Benutzer- und Dienstkontokennwörter in der Directory Service Console
zurück. -
Aktualisieren Sie die Passwörter für das Dienstkonto in Secrets Manager
so, dass sie mit dem neuen Passwort übereinstimmen, das Sie oben eingegeben haben: -
für den Keycloak-Stack: PasswordSecret-... - ResExternal -... - DirectoryService-... mit Beschreibung: Passwort für Microsoft Active Directory
-
für RES: res- ServiceAccountPassword -... mit Beschreibung: Directory Service Directory-Dienstkontokennwort
-
-
Gehen Sie zur EC2-Konsole
und beenden Sie die Cluster-Manager-Instance. Auto Scaling Scaling-Regeln lösen automatisch die Bereitstellung einer neuen Instanz aus.
........................
Demo-Stack-Keycloak funktioniert nicht
Problem
Wenn Ihr Keycloak-Server abgestürzt ist und sich beim Neustart des Servers die IP der Instanz geändert hat, hat dies möglicherweise dazu geführt, dass Keycloak kaputt gegangen ist. Die Anmeldeseite Ihres RES-Portals kann entweder nicht geladen werden oder bleibt in einem Ladezustand hängen, der nie behoben wird.
Schadensbegrenzung
Sie müssen die bestehende Infrastruktur löschen und den Keycloak-Stack erneut bereitstellen, um Keycloak wieder in einen fehlerfreien Zustand zu versetzen. Dazu gehen Sie wie folgt vor:
-
Gehe zu Cloudformation. Du solltest dort zwei Stacks sehen, die sich auf Keycloak beziehen:
-
<env-name>-RESSsoKeycloak-<random characters><env-name>-RESSsoKeycloak-<random characters>-RESSsoKeycloak-*
-
-
Löschen Sie Stack1. Wenn Sie aufgefordert werden, den verschachtelten Stapel zu löschen, wählen Sie Ja aus, um den verschachtelten Stapel zu löschen.
Stellen Sie sicher, dass der Stapel vollständig gelöscht wurde.
-
Stellen Sie diesen Stack manuell mit genau den gleichen Parameterwerten wie der gelöschte Stack bereit. Stellen Sie ihn von der CloudFormation Konsole aus bereit, indem Sie zu Stack erstellen → Mit neuen Ressourcen (Standard) → Eine vorhandene Vorlage auswählen → Eine Vorlagendatei hochladen gehen. Füllen Sie die erforderlichen Parameter mit denselben Eingaben aus wie für den gelöschten Stack. Sie können diese Eingaben in Ihrem gelöschten Stack finden, indem Sie den Filter in der CloudFormation Konsole ändern und zur Registerkarte Parameter wechseln. Stellen Sie sicher, dass der Umgebungsname, das key pair und andere Parameter mit den ursprünglichen Stack-Parametern übereinstimmen.
-
Sobald der Stack bereitgestellt ist, kann Ihre Umgebung wieder verwendet werden. Sie finden den auf ApplicationUrl der Registerkarte Ausgaben des bereitgestellten Stacks.
........................
Probleme mit Active Directory
Themen
Mein VDI steckt lange Zeit im Bereitstellungsstatus fest, oder ich kann meinen VDI nicht als AD-Benutzer anmelden, nachdem der VDI bereit ist
Überprüfen Sie zunächst die VDI-Installations- und Konfigurationsprotokolle (/root/bootstrap/logs/und /opt/idea/app/logs/ Verzeichnisse für Linux oder C:\Program Files\RES\app\logs\ Verzeichnisse für Windows) auf Installations C:\Users\Administrator\RES\Bootstrap\Log\ - oder Konfigurationsfehler.
Wenn Sie eine Fehlermeldung finden, die besagt, dass die Instanz Active Directory nicht beitreten konnte, liegt das in der Regel daran, dass der Cluster-Manager das Computerkonto für die Instanz in Ihrem AD nicht voreinstellen kann. Überprüfen Sie die Cluster Manager-Protokolle unter der / CloudWatch Protokollgruppe und filtern Sie nach Fehlermeldungen, die Folgendes environment-name/cluster-manager[preset-computer] enthalten: Häufige Probleme sind unter anderem:
-
Die Anmeldeinformationen für das AD-Dienstkonto sind ungültig.
-
Überprüfen Sie das geheime Dienstkonto, das Sie RES zur Verfügung gestellt haben. Stellen Sie sicher, dass der Benutzername und das Passwort als Schlüssel-Wert-Paar angegeben werden
{und dass die Anmeldeinformationen gültig sind. Sie müssen die Cluster Manager-Instanz wechseln, indem Sie die bestehende Instanz beenden und der Auto Scaling-Gruppe erlauben, automatisch eine neue zu starten, nachdem Sie den geheimen Dienstkontoschlüssel geändert haben. Starten Sie dann neue VDIs, um die Änderung zu übernehmen.username:password}
-
-
Das Dienstkonto ist nicht berechtigt, Computerkonten in AD zu erstellen.
-
Stellen Sie sicher, dass Ihr Dienstkonto über alle erforderlichen Berechtigungen verfügt, die unter aufgeführt sindRichten Sie ein Dienstkonto für Microsoft Active Directory ein. Sie müssen neue VDIs starten, nachdem Sie die Dienstkontoberechtigungen in AD repariert haben.
-
-
Es kann keine Verbindung zum LDAP-Server hergestellt werden.
-
Stellen Sie sicher, dass Ihre AD-Konfiguration eine LDAP/LDAPS Verbindung innerhalb der VPC zulässt und dass die DHCP-Option Ihrer VPC richtig eingestellt ist. Gehen Sie dazu wie folgt Erstellen oder Ändern eines DHCP-Optionssatzes für AWS Managed Microsoft AD vor, wenn Sie Managed AD verwenden. AWS
-
Für eine LDAPS-Verbindung ist der
DomainTLSCertificateSecretArnParameter erforderlich, und Sie müssen ein gültiges CA-Zertifikat angeben, um die Verbindung zu sichern. Sie müssen die Cluster Manager-Instanz wechseln, indem Sie die bestehende Instanz beenden und der Auto Scaling-Gruppe erlauben, automatisch eine neue zu starten, nachdem Sie den geheimen TLS-Zertifikatsschlüssel geändert haben. Starten Sie dann neue VDIs, um die Änderung zu übernehmen. -
Um die Verbindung zwischen RES und Ihrem AD zu testen, führen Sie den folgenden ldapsearch-Befehl auf der Cluster Manager-Instanz aus (ersetzen Sie die Benutzer-OU, den LDAP-Verbindungs-URI, den Benutzernamen und das Passwort des Dienstkontos). Dieser Befehl sollte alle Benutzer unter der angegebenen Organisationseinheit zurückgeben, wenn Ihr AD ordnungsgemäß konfiguriert ist, um die Verbindung zu ermöglichen.
ldapsearch -x -b "OU=Users,OU=RES,OU=CORP,DC=corp,DC=res,DC=com" -D "ServiceAccount@corp.res.com" -H ldap://corp.res.com -wservice-account-password"(objectClass=group)"
-
Wenn Sie DisableAdJoin true bei der Installation von RES auf setzen, stellen Ihre Linux-VDIs nur eine Verbindung zum Active Directory her, anstatt es über den SSSD-Dienst zu verbinden. Stellen Sie von der EC2-Konsole aus eine Connect zu Ihrer VDI-Instanz her und führen Sie den Befehl id darauf aus. Wenn der Befehl die UID/GID des entsprechenden AD-Benutzers nicht zurückgeben kann, überprüfen Sie den SSSD-Dienststatus mithilfe des Befehls usernamesudo systemctl status sssd auf der VDI-Instanz sowie anhand der SSSD-Dienstprotokolle im Verzeichnis. /var/log/sssd/
Wenn Sie SSSD-Konfigurationen anpassen müssen, um eine Verbindung zu Ihrem AD herzustellen, können Sie die SSSD-Konfigurationsdatei (/etc/sssd/sssd.conf) manuell bearbeiten und den SSSD-Dienst mithilfe eines Befehls sudo systemctl restart sssd auf dem Infra-/VDI-Host (Version 2024.12.01 und früher) neu starten oder zusätzliche SSSD-Konfigurationen über das RES-Webportal bereitstellen, Active Directory-Synchronisierung die anschließend automatisch auf Ihre vorhandenen oder neuen VDIs angewendet werden (Version 2025.03 und später).
........................
Ich kann mich nach der Konfiguration von SSO nicht im RES-Webportal anmelden
Überprüfen Sie die Tabellen environment-name.accounts.usersenvironment-name.accounts.groups/ CloudWatch Protokollgruppe (vor Version 2024.12) oder environment-name/cluster-manager/ CloudWatch Protokollgruppe (Version 2024.12 und höher).environment-name/ad-sync
Neben den unter genannten häufigen Problemen mit der AD-Konfiguration können weitere Mein VDI steckt lange Zeit im Bereitstellungsstatus fest, oder ich kann meinen VDI nicht als AD-Benutzer anmelden, nachdem der VDI bereit ist Fehler auftreten:
-
Das Dienstkonto ist nicht berechtigt, Benutzer und Gruppen in AD abzufragen.
-
Stellen Sie sicher, dass Ihr Dienstkonto über alle erforderlichen Berechtigungen verfügt, die unter aufgeführt sindRichten Sie ein Dienstkonto für Microsoft Active Directory ein.
-
-
Benutzer/Gruppen in Active Directory fehlen erforderliche Attribute wie die E-Mail-Adresse.
-
Aktualisieren Sie Ihre Benutzer-/Gruppenattribute entsprechend, um das Problem zu beheben.
-
Nachdem Sie das AD-Synchronisierungsproblem behoben haben, können Sie auf die nächste geplante AD-Synchronisierung warten, die jede Stunde stattfindet, oder sie manuell auslösen, indem Sie den Anweisungen in Wie führe ich die Synchronisierung manuell aus (Version 2024.12 und 2024.12.01) (Version 2024.12 und 2024.12.01) oder Wie kann die Synchronisierung manuell gestartet oder gestoppt werden (Version 2025.03 und höher) (Version 2025.03 und höher) folgen.
........................
AD-Benutzer können mit dem Dateibrowser nicht auf das Basisverzeichnis zugreifen, auch wenn Linux-VDIs erfolgreich gestartet wurden
Überprüfen Sie, ob der AD-Benutzer für den Cluster Manager sichtbar ist, indem Sie den Befehl id auf der Cluster Manager-Instanz ausführen. Wenn der Befehl die UID/GID des entsprechenden AD-Benutzers nicht zurückgeben kann, überprüfen Sie die Cluster Manager-Protokolle unter der username/ CloudWatch Protokollgruppe und suchen Sie nach Fehlern beim Starten des SSSD-Dienstes. Wenn die Cluster Manager-Protokolle keinen Fehler enthalten, überprüfen Sie den SSSD-Dienststatus mithilfe des Befehls environment-name/cluster-managersudo systemctl status sssd auf der Cluster Manager-Instanz sowie anhand der SSSD-Dienstprotokolle im Verzeichnis. /var/log/sssd/
Wenn der AD-Benutzer für den Cluster-Manager sichtbar ist, überprüfen Sie die UID/GID im Home-Verzeichnis des Benutzers (/home/), indem Sie den Befehl ausführen. usernamels -n /home Vergleichen Sie die UID/ GID des Home-Verzeichnisses des Benutzers mit der vom Befehl zurückgegebenen UID/GID. id Wenn die UID/GID nicht übereinstimmt, bedeutet dies, dass das Home-Verzeichnis des Benutzers möglicherweise außerhalb von RES oder anhand einer früheren RES-Bereitstellung erstellt wurde. Erstellen Sie eine Sicherungskopie aller wichtigen Benutzerdaten, löschen Sie das Home-Verzeichnis und starten Sie mit dem Benutzer ein neues Linux-VDI. Das Home-Verzeichnis wird mit der richtigen UID /GID neu erstellt, nachdem der neue VDI erfolgreich bereitgestellt wurde.username
........................
Der AD-Administratorbenutzer kann nicht auf den Bastion Host zugreifen, nachdem der SSH-Zugriff aktiviert wurde
Überprüfen Sie, ob der AD-Benutzer für den Bastion Host sichtbar ist, indem Sie den Befehl id auf der Bastion Host-Instanz ausführen. Wenn der Befehl die UID/GID des entsprechenden AD-Benutzers nicht zurückgeben kann, überprüfen Sie die Bastion Host-Protokolle unter der username/ CloudWatch Protokollgruppe und suchen Sie nach Fehlern beim Starten des SSSD-Dienstes. Wenn die Bastion-Host-Protokolle keinen Fehler enthalten, überprüfen Sie den SSSD-Dienststatus mithilfe des Befehls environment-name/bastion-hostsudo systemctl status sssd auf der Bastion-Host-Instanz sowie den SSSD-Dienstprotokollen unter dem Verzeichnis. /var/log/sssd/
........................
Mein vom externen RES-Ressourcenstapel bereitgestelltes Active Directory anzeigen und verwalten
Wenn Ihr AWS verwaltetes Active Directory durch einen externen RES-Ressourcenstapel bereitgestellt wird, sollte unter Ihrem AWS Konto eine Instanz vorhanden sein, deren Name mit AdDomainWindowsNode- bereitgestellt beginnt und die für den Zugriff auf und die Verwaltung von Active Directory verwendet werden kann. Sie können die Instance über Fleet Manager in der EC2-Konsole mit den folgenden Anmeldeinformationen anmelden:external-resource-stack-name-WindowsManagementHost
Nutzername: Admin
Passwort: AdminPassword Parameter, der bei der Bereitstellung des externen Ressourcenstapels bereitgestellt wurde
Informationen zur Verwaltung Ihres AWS verwalteten Active Directorys finden Sie unter Benutzer und Gruppen mit einer Amazon EC2 EC2-Instance verwalten im AWSDirectory Service Administration Guide.
........................
