Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon-S3-Buckets
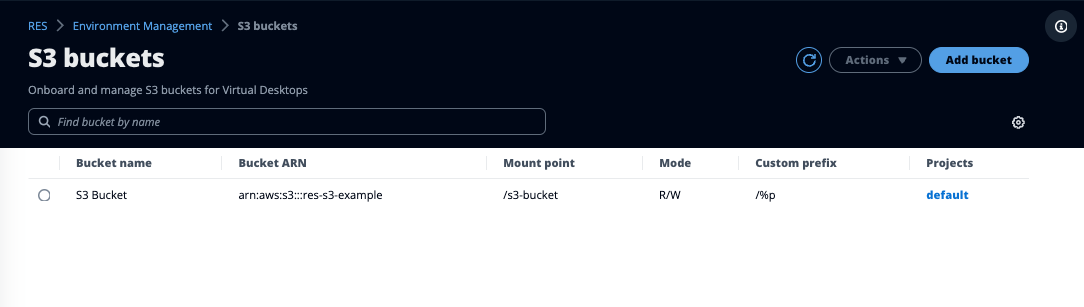
Research and Engineering Studio (RES) unterstützt das Mounten von Amazon S3 S3-Buckets auf Linux Virtual Desktop Infrastructure (VDI) -Instances. RES-Administratoren können S3-Buckets in RES integrieren, sie an Projekte anhängen, ihre Konfiguration bearbeiten und Buckets auf der Registerkarte S3-Buckets unter Environment Management entfernen.
Das S3-Buckets-Dashboard bietet eine Liste der integrierten S3-Buckets, die Ihnen zur Verfügung stehen. Über das S3-Buckets-Dashboard können Sie:
-
Verwenden Sie Bucket hinzufügen, um einen S3-Bucket in RES zu integrieren.
-
Wählen Sie einen S3-Bucket aus und verwenden Sie das Aktionsmenü, um:
-
Bearbeiten Sie einen Bucket
-
Einen Bucket entfernen
-
-
Verwenden Sie das Suchfeld, um nach dem Bucket-Namen zu suchen und integrierte S3-Buckets zu finden.
In den folgenden Abschnitten wird beschrieben, wie Sie Amazon S3 S3-Buckets in Ihren RES-Projekten verwalten.
