Amazon Redshift unterstützt ab Patch 198 nicht mehr die Erstellung neuer Python-UDFs. Bestehende Python-UDFs werden bis zum 30. Juni 2026 weiterhin funktionieren. Weitere Informationen finden Sie im Blog-Posting
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren eines bereitgestellten Clusters zu Amazon Redshift Serverless
Sie können vorhandene bereitgestellte Cluster zu Amazon Redshift Serverless migrieren, um die automatische oder On-Demand-Skalierung der Rechenressourcen zu ermöglichen. Durch die Migration eines bereitgestellten Clusters zu Amazon Redshift Serverless können Sie die Kosten optimieren, indem Sie nur für die von Ihnen genutzten Ressourcen zahlen und die Kapazitäten automatisch auf Grundlage der Workload-Anforderungen skalieren. Zu den häufigsten Anwendungsfällen für die Migration gehören die Ausführung von Ad-hoc-Abfragen, regelmäßige Datenverarbeitungsaufträge oder die Verarbeitung nicht planbarer Workloads ohne Überdimensionierung von Ressourcen. Führen Sie die folgenden Aufgaben aus, um den bereitgestellten Amazon-Redshift-Cluster zur Serverless-Bereitstellungsoption zu migrieren.
Erstellen eines Snapshots des bereitgestellten Clusters
Anmerkung
Amazon Redshift wandelt verschachtelte Schlüssel automatisch in zusammengesetzte Schlüssel um, wenn Sie einen Snapshot bereitgestellter Cluster in einem Serverless-Namespace wiederherstellen.
Um Daten von Ihrem bereitgestellten Cluster zu Amazon Redshift Serverless zu übertragen, erstellen Sie einen Snapshot Ihres bereitgestellten Clusters und stellen diesen dann in Amazon Redshift Serverless wieder her.
Anmerkung
Bevor Sie Ihre Daten zu einer Serverless-Arbeitsgruppe migrieren, stellen Sie sicher, dass die Anforderungen Ihres bereitgestellten Clusters mit der RPU-Menge kompatibel sind, die Sie in Amazon Redshift Serverless auswählen.
So erstellen Sie einen Snapshot Ihres bereitgestellten Clusters
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. -
Wählen Sie im Navigationsmenü Clusters (Cluster), Snapshots und wählen Sie dann Create snapshot (Snapshot erstellen) aus.
-
Geben Sie die Eigenschaften der Snapshot-Definition ein und wählen Sie dann Create snapshot (Snapshot erstellen) aus. Es kann einige Zeit dauern, bis der Snapshot verfügbar ist.
So stellen Sie einen Snapshot bereitgestellter Cluster in einem Serverless-Namespace wieder her:
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. -
Navigieren Sie auf der Konsole für bereitgestellte Amazon Redshift-Cluster zur Seite Clusters (Cluster), Snapshots.
-
Wählen Sie einen Snapshot zum Verwenden aus.
-
Wählen Sie Restore snapshot (Snapshot wiederherstellen), Restore to serverless namespace (In Serverless-Namespace wiederherstellen).
-
Wählen Sie einen Namespace, in dem Sie Ihren Snapshot wiederherstellen möchten.
-
Bestätigen Sie, dass Sie von Ihrem Snapshot aus wiederherstellen möchten. Diese Aktion ersetzt alle Datenbanken auf Ihrem Serverless-Endpunkt durch die Daten aus Ihrem bereitgestellten Cluster. Wählen Sie Restore (Wiederherstellen) aus.
Weitere Informationen zu bereitgestellten Cluster-Snapshots finden Sie unter Amazon-Redshift-Snapshots.
Herstellen einer Verbindung mit Amazon Redshift Serverless über einen Treiber
Um über Ihren bevorzugten SQL-Client eine Verbindung zu Amazon Redshift Serverless herzustellen, können Sie die von Amazon Redshift bereitgestellte JDBC-Treiberversion 2.x verwenden. Wir empfehlen, die Verbindung zu Amazon Redshift über die neueste Version der JDBC-Treiberversion 2.x von Amazon-Redshift herzustellen. Der Portnummer ist optional. Wenn Sie keine Angaben machen, verwendet Amazon Redshift Serverless standardmäßig die Portnummer 5439. Sie können zu einem anderen Port aus dem Portbereich 5431–5455 oder 8191–8215 wechseln. Um den Standardport für einen serverlosen Endpunkt zu ändern, verwenden Sie die AWS CLI Amazon Redshift Redshift-API.
Den genauen Endpunkt für den JDBC-, ODBC- oder Python-Treiber finden Sie unter Arbeitsgruppenkonfiguration in Amazon Redshift Serverless. Sie können auch den Amazon Redshift Serverless API-Vorgang GetWorkgroup oder den AWS CLI Vorgang verwenden, get-workgroups um Informationen über Ihre Arbeitsgruppe zurückzugeben und dann eine Verbindung herzustellen.
Verbinden mit passwortbasierter Authentifizierung
Verwenden Sie die folgende Syntax, um eine Verbindung über die JDBC-Treiberversion 2.x von Amazon Redshift mit passwortbasierter Authentifizierung herzustellen:
jdbc:redshift://<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com:5439/?username=username&password=password
Verwenden Sie die folgende Syntax, um eine Verbindung über den Python-Konnektor von Amazon Redshift mit passwortbasierter Authentifizierung herzustellen:
import redshift_connector with redshift_connector.connect( host='<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com', database='<database-name>', user='username', password='password' # port value of 5439 is specified by default ) as conn: pass
Verwenden Sie die folgende Syntax, um eine Verbindung über die ODBC-Treiberversion 2.x von Amazon Redshift mit passwortbasierter Authentifizierung herzustellen:
Driver={Amazon Redshift ODBC Driver (x64)}; Server=<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com; Database=database-name; User=username; Password=password
Herstellen einer Verbindung über IAM
Wenn Sie sich mit IAM anmelden möchten, verwenden Sie die API-Operation GetCredentials von Amazon Redshift Serverless.
Um die IAM-Authentifizierung zu verwenden, fügen Sie der JDBC-URL von Amazon Redshift nach jdbc:redshift: das Element iam: hinzu wie im folgenden Beispiel gezeigt.
jdbc:redshift:iam://<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com:5439/<database-name>
Dieser Endpunkt in Amazon Redshift Serverless unterstützt keine Anpassung von dbUser, dbGroup oder auto-create. Standardmäßig erstellt der Treiber automatisch Datenbankbenutzer bei der Anmeldung. Anschließend werden den Benutzern Amazon-Redshift-Datenbankrollen zugewiesen, basierend auf den in IAM angegebenen Tags oder basierend auf den in Ihrem Identitätsanbieter (IdP) definierten Gruppen.
Stellen Sie sicher, dass Ihre AWS Identität über die richtige IAM-Richtlinie für die Aktion verfügt. redshift-serverless:GetCredentials Im Folgenden finden Sie ein Beispiel für eine IAM-Richtlinie, die einer AWS Identität die richtigen Berechtigungen für die Verbindung mit Amazon Redshift Serverless gewährt. Weitere Informationen zu IAM-Berechtigungen finden Sie unter Hinzufügen und Entfernen von IAM-Identitätsberechtigungen im IAM-Benutzerhandbuch.
Um eine Verbindung über den Python-Konnektor von Amazon Redshift mit IAM-basierter Authentifizierung herzustellen, verwenden Sie iam=true im Code wie in der folgenden Syntax gezeigt:
import redshift_connector with redshift_connector.connect( iam=True, host='<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com', database='<database-name>' <IAM credentials> ) as conn: pass
Für IAM credentials können Sie beliebige Anmeldeinformationen verwenden, einschließlich der folgenden:
-
AWS Profilkonfiguration.
-
IAM-Anmeldeinformationen (eine Zugriffsschlüssel-ID, ein geheimer Zugriffsschlüssel und optional ein Sitzungstoken).
-
Identitätsanbieterverbund.
Verwenden Sie die folgende Syntax, um eine Verbindung über die ODBC-Treiberversion 2.x von Amazon Redshift mit IAM-basierter Authentifizierung und einem Profil herzustellen:
Driver={Amazon Redshift ODBC Driver (x64)}; IAM=true; Server=<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com; Database=database-name; Profile=aws-profile-name;
Verbindung über IAM mit der GetClusterCredentials API herstellen
Anmerkung
Wenn Sie eine Verbindung zu Amazon Redshift Serverless herstellen möchten, empfehlen wir Ihnen, die API GetCredentials zu verwenden. Diese API bietet eine umfassende Funktionalität für die rollenbasierte Zugriffskontrolle (RBAC) sowie weitere neue Features, die in GetClusterCredentials nicht verfügbar sind. Wir unterstützen die API GetClusterCredentials, um den Wechsel von bereitgestellten Clustern zu Serverless-Arbeitsgruppen zu vereinfachen. Wir empfehlen jedoch dringend, so bald wie möglich zur Nutzung von GetCredentials zu wechseln, um eine optimale Kompatibilität sicherzustellen.
Sie können mithilfe der API GetClusterCredentials eine Verbindung zu Amazon Redshift Serverless herstellen. Um diese Authentifizierungsmethode zu implementieren, ändern Sie Ihren Client oder Ihre Anwendung, indem Sie die folgenden Parameter integrieren:
iam=trueclusterid/cluster_identifier=redshift-serverless-<workgroup-name>region=<aws-region>
Die folgenden Beispiele zeigen das BrowserSAML-Plugin für alle drei Treiber. Dies stellt einen von mehreren verfügbaren Authentifizierungsansätzen dar. Die Beispiele können geändert werden, um abhängig von Ihren spezifischen Anforderungen alternative Authentifizierungsmethoden oder Plugins zu verwenden.
IAM-Richtlinienberechtigungen für GetClusterCredentials
Im Folgenden finden Sie ein Beispiel für eine IAM-Richtlinie mit den Berechtigungen, die für die Verwendung von GetClusterCredentials mit Amazon Redshift Serverless erforderlich sind:
Verwenden Sie die folgende Syntax, um über die JDBC-Treiberversion 2.x von Amazon Redshift eine Verbindung mit GetClusterCredentials herzustellen:
jdbc:redshift:iam://redshift-serverless-<workgroup-name>:<aws-region>/<database-name>?plugin_name=com.amazon.redshift.plugin.BrowserSamlCredentialsProvider&login_url=<single sign-on URL from IdP>"
Verwenden Sie die folgende Syntax, um über den Python-Konnektor von Amazon Redshift eine Verbindung mit GetClusterCredentials herzustellen:
import redshift_connector with redshift_connector.connect( iam=True, cluster_identifier='redshift-serverless-<workgroup-name>', region='<aws-region>', database='<database-name>', credentials_provider='BrowserSamlCredentialsProvider' login_url='<single sign-on URL from IdP>' # port value of 5439 is specified by default ) as conn: pass
Verwenden Sie die folgende Syntax, um über die ODBC-Treiberversion 2.x von Amazon Redshift eine Verbindung mit GetClusterCredentials herzustellen:
Driver= {Amazon Redshift ODBC Driver (x64)}; IAM=true; isServerless=true; ClusterId=redshift-serverless-<workgroup-name>; region=<aws-region>; plugin_name=BrowserSAML;login_url=<single sign-on URL from IdP>
Im Folgenden finden Sie ein Beispiel für eine ODBC-DSN-Konfiguration in Windows:
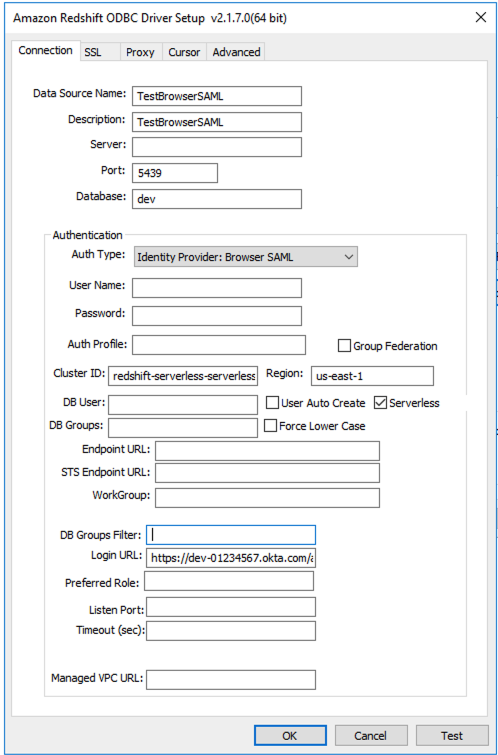
Verwenden des Amazon-Redshift-Serverless-SDK
Wenn Sie Verwaltungsskripte mit dem Amazon-Redshift-SDK geschrieben haben, müssen Sie das neue Amazon-Redshift-Serverless-SDK verwenden, um Amazon Redshift Serverless und zugehörige Ressourcen zu verwalten. Weitere Informationen zu verfügbaren API-Operationen finden Sie im API-Referenzhandbuch zu Amazon Redshift Serverless.
