Amazon Redshift unterstützt ab Patch 198 nicht mehr die Erstellung neuer Python-UDFs. Bestehende Python-UDFs werden bis zum 30. Juni 2026 weiterhin funktionieren. Weitere Informationen finden Sie im Blog-Posting
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anzeigen der Parallelität des Workloads und der Parallelitätsskalierungsdaten
Mit Nebenläufigkeitsskalierungsmetriken in Amazon Redshift können Sie Folgendes tun:
-
Analysieren Sie, ob Sie die Anzahl von Abfragen in der Warteschlange reduzieren können, indem Sie die Parallelität skalieren. Sie können nach WLM-Warteschlange oder für alle WLM-Warteschlangen vergleichen.
-
Anzeigen von Nebenläufigkeitsskalierungsaktivitäten in Nebenläufigkeitsskalierungs-Clustern. So können Sie feststellen, ob die Nebenläufigkeitsskalierung durch
max_concurrency_scaling_clustersbegrenzt wird. Wenn dies zutrifft, können Siemax_concurrency_scaling_clustersim DB-Parameter erhöhen. -
Anzeigen der Gesamtnutzung der Nebenläufigkeitsskalierung für alle Nebenläufigkeitsskalierungs-Cluster zusammen.
So zeigen Sie die Parallelitäts-Skalierungsdaten an:
-
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. -
Wählen Sie im Navigationsmenü Clusters (Cluster) und dann den Cluster-Namen aus der Liste aus, um die Details zu dem Cluster aufzurufen. Die Details des Clusters werden möglicherweise unter anderem auf den Registerkarten Cluster-Leistung, Abfrageüberwachung, Datenbanken, Datashares, Zeitpläne, Wartung und Eigenschaften angezeigt.
-
Wählen Sie die Registerkarte Query monitoring (Abfrageüberwachung) für Metriken zu Ihren Abfragen aus.
-
Wählen Sie im Abschnitt Query monitoring (Abfrageüberwachung) die Registerkarte Workload Concurrency (Workload-Parallelität) aus.
Die Registerkarte enthält folgende Diagramme:
-
Queued vs. Running queries on the cluster (Abfragen in der Warteschlange vs. ausgeführte Abfragen auf dem Cluster) – die Anzahl der ausgeführten Abfragen (Haupt-Cluster und Nebenläufigkeitsskalierungs-Cluster) im Vergleich zur Anzahl der Abfragen, die in allen WLM-Warteschlangen im Cluster warten.
-
Queued vs. Running queries per queue (Abfragen in der Warteschlange vs. ausgeführte Abfragen pro Warteschlange) – die Anzahl der ausgeführten Abfragen (Haupt-Cluster und Nebenläufigkeitsskalierungs-Cluster) im Vergleich zur Anzahl der Abfragen, die in jeder WLM-Warteschlange warten.
-
Concurrency scaling activity (Nebenläufigkeitsskalierungsaktivität) – die Anzahl der Nebenläufigkeitsskalierungs-Cluster, die Abfragen aktiv verarbeiten.
-
Concurrency scaling usage (Nutzung der Nebenläufigkeitsskalierung) – die Nutzung von Nebenläufigkeitsskalierungs-Clustern mit aktiver Abfrageverarbeitungsaktivität.
-
Diagramme der Parallelität des Workloads
Im Folgenden finden Sie einige Beispiele für Diagramme, die in der neuen Amazon-Redshift-Konsole angezeigt werden. Um ähnliche Diagramme in Amazon zu erstellen CloudWatch, können Sie die Parallelitätsskalierung und die CloudWatch WLM-Metriken verwenden. Weitere Informationen zu CloudWatch Metriken für Amazon Redshift finden Sie unterLeistungsdaten in Amazon Redshift.
-
Queued vs. Running queries on the cluster (Abfragen in der Warteschlange vs. ausgeführte Abfragen auf dem Cluster)
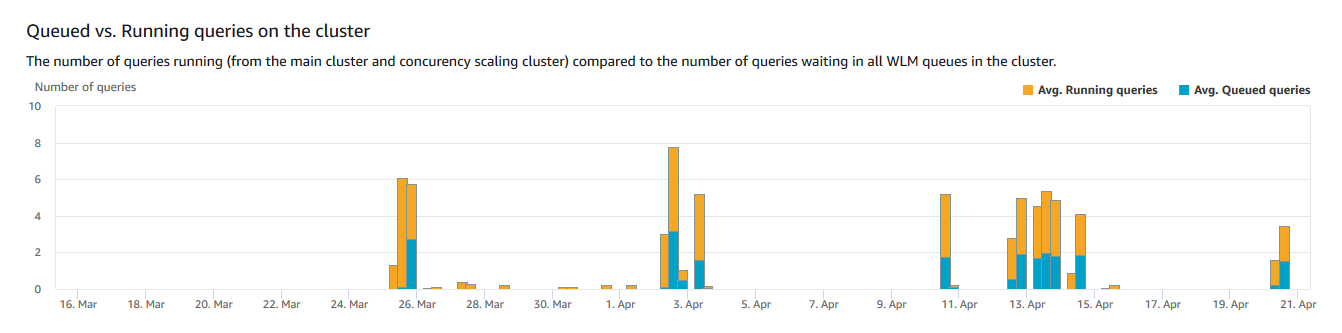
-
Queued vs. Running queries per queue (Abfragen in der Warteschlange vs. ausgeführte Abfragen pro Warteschlange)

-
Concurrency scaling activity (Parallelitätsskalierungsaktivität)

-
Concurrency scaling usage (Nutzung der Parallelitätsskalierung)

