Amazon Redshift unterstützt ab Patch 198 nicht mehr die Erstellung neuer Python-UDFs. Bestehende Python-UDFs werden bis zum 30. Juni 2026 weiterhin funktionieren. Weitere Informationen finden Sie im Blog-Posting
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Durchführung eines Machbarkeitsnachweises für Amazon Redshift
Amazon Redshift ist ein beliebtes Cloud Data Warehouse, das einen vollständig verwalteten cloudbasierten Service bietet, der in den Amazon Simple Storage Service Data Lake eines Unternehmens, Echtzeit-Streams, Machine Learning (ML), Transaktions-Workflows und vieles mehr integriert werden kann. Die folgenden Abschnitte führen Sie durch den Prozess der Durchführung eines Machbarkeitsnachweises (PoC) auf Amazon Redshift. Diese Informationen helfen Ihnen bei der Festlegung von Zielen für Ihren Machbarkeitsnachweis und nutzen die Vorteile von Tools, mit denen Sie die Bereitstellung und Konfiguration von Services für Ihren Machbarkeitsnachweis automatisieren können.
Anmerkung
Um eine Kopie dieser Informationen als PDF zu erhalten, wählen Sie auf der Amazon-Redshift-Ressourcenseite
Wenn Sie einen Machbarkeitsnachweis für Amazon Redshift durchführen, testen und implementieren Sie Features, die von erstklassigen Sicherheitsfunktionen über elastische Skalierung, einfache Integration und Aufnahme bis hin zu flexiblen dezentralen Datenarchitekturoptionen reichen.

Folgen Sie diesen Schritten, um einen erfolgreichen Machbarkeitsnachweis durchzuführen.
Schritt 1: Festlegen des Bereichs des Machbarkeitsnachweises

Wenn Sie einen Machbarkeitsnachweis durchführen, können Sie entweder Ihre eigenen Daten oder Benchmarking-Datensätze verwenden. Wenn Sie Ihre eigenen Daten auswählen, führen Sie Ihre eigenen Abfragen anhand der Daten durch. Bei Benchmarking-Daten werden Beispielabfragen zusammen mit dem Benchmark bereitgestellt. Weitere Informationen finden Sie unter Verwenden von Beispieldatensätzen, falls Sie noch nicht bereit sind, einen Machbarkeitsnachweis mit Ihren eigenen Daten durchzuführen.
Generell empfehlen wir die Verwendung von Daten über zwei Wochen für einen Amazon-Redshift-Machbarkeitsnachweis.
Gehen Sie zunächst wie folgt vor:
Identifizieren Sie Ihre geschäftlichen und funktionalen Anforderungen und gehen Sie von dort aus rückwärts vor. Typische Beispiele sind: schnellere Leistung, geringere Kosten, Testen eines neuen Workloads oder Features oder Vergleich zwischen Amazon Redshift und einem anderen Data Warehouse.
Legen Sie spezifische Ziele fest, die zu den Erfolgskriterien für den Machbarkeitsnachweis werden. Überlegen Sie sich beispielsweise zu schnellerer Leistung eine Liste der 5 wichtigsten Prozesse, die Sie beschleunigen möchten, und geben Sie die aktuellen Laufzeiten zusammen mit der gewünschten Laufzeit an. Dabei kann es sich um Berichte, Abfragen, ETL-Prozesse, Datenerfassung oder andere aktuelle Probleme handeln.
Identifizieren Sie den spezifischen Umfang und die Artefakte, die für die Durchführung der Tests erforderlich sind. Welche Datensätze müssen Sie migrieren oder kontinuierlich in Amazon Redshift aufnehmen und welche Abfragen und Prozesse sind erforderlich, um die Tests durchzuführen, um sie anhand der Erfolgskriterien zu messen? Es gibt zwei Möglichkeiten dafür:
Verwenden Ihrer eigenen Daten
Um Ihre eigenen Daten zu testen, erstellen Sie die minimal praktikable Liste von Datenartefakten, die erforderlich ist, um Ihre Erfolgskriterien zu testen. Wenn Ihr aktuelles Data Warehouse beispielsweise über 200 Tabellen verfügt, die Berichte, die Sie testen möchten, jedoch nur 20 benötigen, kann Ihr Machbarkeitsnachweis schneller ausgeführt werden, wenn Sie nur die kleinere Teilmenge von Tabellen verwenden.
Verwenden von Beispieldatensätzen
Wenn Sie keine eigenen Datensätze bereit haben, können Sie trotzdem mit der Durchführung eines POC auf Amazon Redshift beginnen, indem Sie die branchenüblichen Benchmark-Datensätze wie TPC-DS
oder verwenden TPC-H und Beispiel-Benchmarking-Abfragen ausführen, um die Leistungsfähigkeit von Amazon Redshift zu nutzen. Auf diese Datensätze kann von Ihrem Amazon Redshift Data Warehouse aus zugegriffen werden, nachdem es erstellt wurde. Ausführliche Anweisungen zum Zugriff auf diese Datensätze und Beispielabfragen finden Sie unter Schritt 2: Starten von Amazon Redshift.
Schritt 2: Starten von Amazon Redshift

Amazon Redshift beschleunigt Ihre Erkenntnisprozesse mit schnellem, einfachem und sicherem Cloud Data Warehousing in großem Umfang. Sie können schnell beginnen, indem Sie Ihr Warehouse auf der Redshift-Serverless-Konsole
Einrichtung von Amazon Redshift Serverless
Wenn Sie Redshift Serverless zum ersten Mal verwenden, führt Sie die Konsole durch die Schritte, die zum Starten Ihres Warehouse erforderlich sind. Möglicherweise haben Sie auch Anspruch auf eine Gutschrift für Ihre Redshift-Serverless-Nutzung in Ihrem Konto. Weitere Informationen zur Auswahl einer kostenlosen Testversion finden Sie unter Kostenlose Testversion von Amazon Redshift
Wenn Sie Redshift Serverless zuvor in Ihrem Konto gestartet haben, folgen Sie den Schritten unter Erstellen einer Arbeitsgruppe mit einem Namespace im Amazon Redshift Management Guide. Sobald Ihr Warehouse verfügbar ist, können Sie sich dafür entscheiden, die in Amazon Redshift verfügbaren Beispieldaten zu laden. Weitere Informationen zur Arbeit mit Amazon Redshift Query Editor V2 finden Sie unter Abfragen von Beispieldaten im Amazon Redshift Management Guide.
Wenn Sie Ihre eigenen Daten verwenden, anstatt den Beispieldatensatz zu laden, finden Sie weitere Informationen unter Schritt 3: Laden Ihrer Daten.
Schritt 3: Laden Ihrer Daten

Nach dem Start von Redshift Serverless besteht der nächste Schritt darin, Ihre Daten für den Machbarkeitsnachweis zu laden. Ganz gleich, ob Sie eine einfache CSV-Datei hochladen, halbstrukturierte Daten aus S3 aufnehmen oder Daten direkt streamen: Amazon Redshift bietet die Flexibilität, die Daten schnell und einfach von der Quelle in Amazon-Redshift-Tabellen zu verschieben.
Wählen Sie eine der folgenden Methoden zum Laden Ihrer Daten:
Hochladen einer lokalen Datei
Für eine schnelle Aufnahme und Analyse können Sie Amazon Redshift Query Editor V2 verwenden, um Datendateien einfach von Ihrem lokalen Desktop zu laden. Er ist in der Lage, Dateien in verschiedenen Formaten wie CSV, JSON, AVRO, PARQUET, ORC und mehr zu verarbeiten. Um als Administrator Ihre Benutzer in die Lage zu versetzen, Daten mit Query Editor V2 von einem lokalen Desktop zu laden, müssen Sie einen gemeinsamen Amazon-S3-Bucket angeben und das Benutzerkonto muss mit den entsprechenden Berechtigungen konfiguriert sein. Sie können das Verfahren unter Einfaches und sicheres Laden von Daten in Amazon Redshift mit Query Editor V2
Laden einer Amazon-S3-Datei
Um Daten aus einem Amazon-S3-Bucket in Amazon Redshift zu laden, verwenden Sie zunächst den Befehl COPY und geben Sie den Amazon-S3-Quellspeicherort und die Amazon-Redshift-Zieltabelle an. Stellen Sie sicher, dass die IAM-Rollen und -Berechtigungen ordnungsgemäß konfiguriert sind, sodass Amazon Redshift auf den angegebenen Amazon-S3-Bucket zugreifen kann. Folgen Sie der Anleitung:Laden von Daten aus Amazon S3, um eine schrittweise Anleitung zu erhalten. Sie können auch die Option Daten laden in Query Editor V2 wählen, um Daten direkt aus Ihrem S3-Bucket zu laden.
Kontinuierliche Datenerfassung
Autocopy (in der Vorschauversion) ist eine Erweiterung des COPY-Befehls, die das kontinuierliche Laden von Daten aus Amazon-S3-Buckets automatisiert. Wenn Sie einen Kopierjob erstellen, erkennt Amazon Redshift, wenn neue Amazon-S3-Dateien in einem bestimmten Pfad erstellt werden, und lädt diese dann automatisch, ohne dass Sie aktiv werden müssen. Amazon Redshift verfolgt die geladenen Dateien, um sicherzustellen, dass sie nur einmal geladen werden. Eine Anleitung zum Erstellen von Kopierjobs finden Sie unter COPY JOB.
Anmerkung
Autocopy befindet sich derzeit in der Vorschauversion und wird nur in bestimmten bereitgestellten Clustern unterstützt. AWS-Regionen Informationen zum Erstellen eines Vorschau-Clusters für Autocopy finden Sie unter Erstellen einer S3-Ereignisintegration, um Dateien automatisch aus Amazon-S3-Buckets zu kopieren.
Laden Ihrer Streaming-Daten
Die Streaming-Erfassung ermöglicht das Erfassen von Stream-Daten mit geringer Latenz und hoher Geschwindigkeit aus Amazon Kinesis Data Streams
Schritt 4: Analysieren Ihrer Daten

Nachdem Sie Ihre Redshift-Serverless-Arbeitsgruppe und Ihren Namespace erstellt und Ihre Daten geladen haben, können Sie sofort Abfragen ausführen, indem Sie Query Editor V2 im Navigationsbereich der Redshift-Serverless-Konsole
Abfrage mit Amazon Redshift Query Editor V2
Sie können über die Amazon-Redshift-Konsole auf Query Editor V2 zugreifen. Eine vollständige Anleitung zur Konfiguration, Verbindung und Ausführung von Abfragen mit Query Editor V2 finden Sie unter Vereinfachen Ihrer Datenanalyse mit Amazon Redshift Query Editor V2
Wenn Sie einen Auslastungstest als Teil Ihres Machbarkeitsnachweises durchführen möchten, können Sie dies alternativ mit den folgenden Schritten tun, um Apache JMeter zu installieren und auszuführen.
Durchführen eines Auslastungstests mit Apache JMeter
Um einen Auslastungstest durchzuführen, um „N“ Benutzer zu simulieren, die gleichzeitig Anfragen an Amazon Redshift senden, können Sie Apache JMeter
Um Apache JMeter für die Ausführung in Ihrer Redshift Serverless-Arbeitsgruppe zu installieren und zu konfigurieren, folgen Sie den Anweisungen unter Automatisieren von Amazon Redshift Redshift-Lasttests mit dem
Nachdem Sie die Anpassung Ihrer SQL-Anweisungen und die Fertigstellung Ihres Testplans abgeschlossen haben, speichern Sie Ihren Testplan und führen Sie ihn für Ihre Redshift-Serverless-Arbeitsgruppe aus. Um den Fortschritt Ihres Tests zu überwachen, öffnen Sie die Redshift-Serverless-Konsole
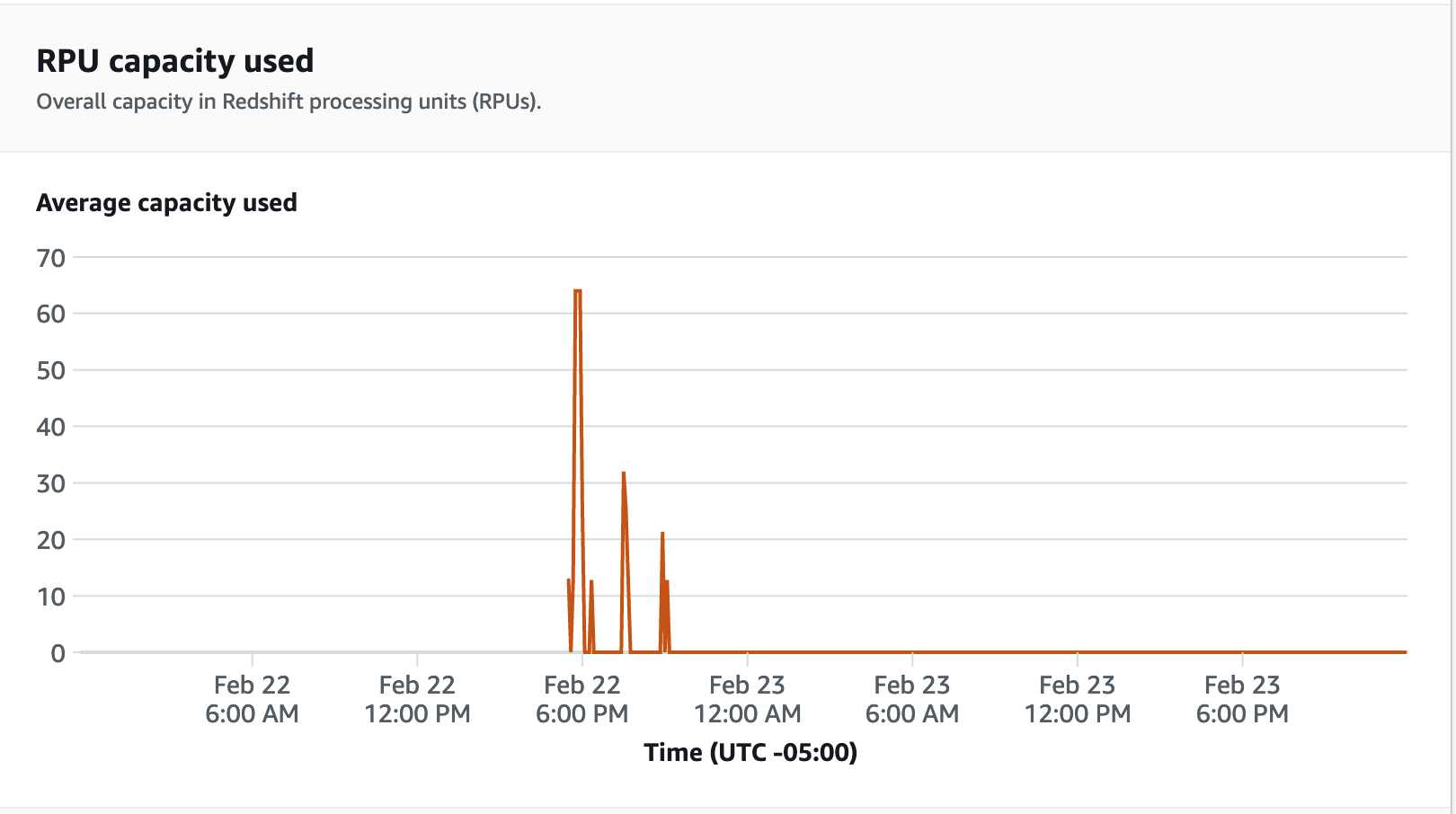
Wählen Sie für Leistungsmetriken die Registerkarte Datenbankleistung auf der Redshift-Serverless-Konsole, um Metriken wie Datenbankverbindungen und CPU-Auslastung zu überwachen. Hier können Sie ein Diagramm anzeigen, um die verwendete RPU-Kapazität zu überwachen und zu beobachten, wie Redshift Serverless automatisch skaliert, um gleichzeitigen Workload-Anforderungen gerecht zu werden, während der Auslastungstest für Ihre Arbeitsgruppe ausgeführt wird.
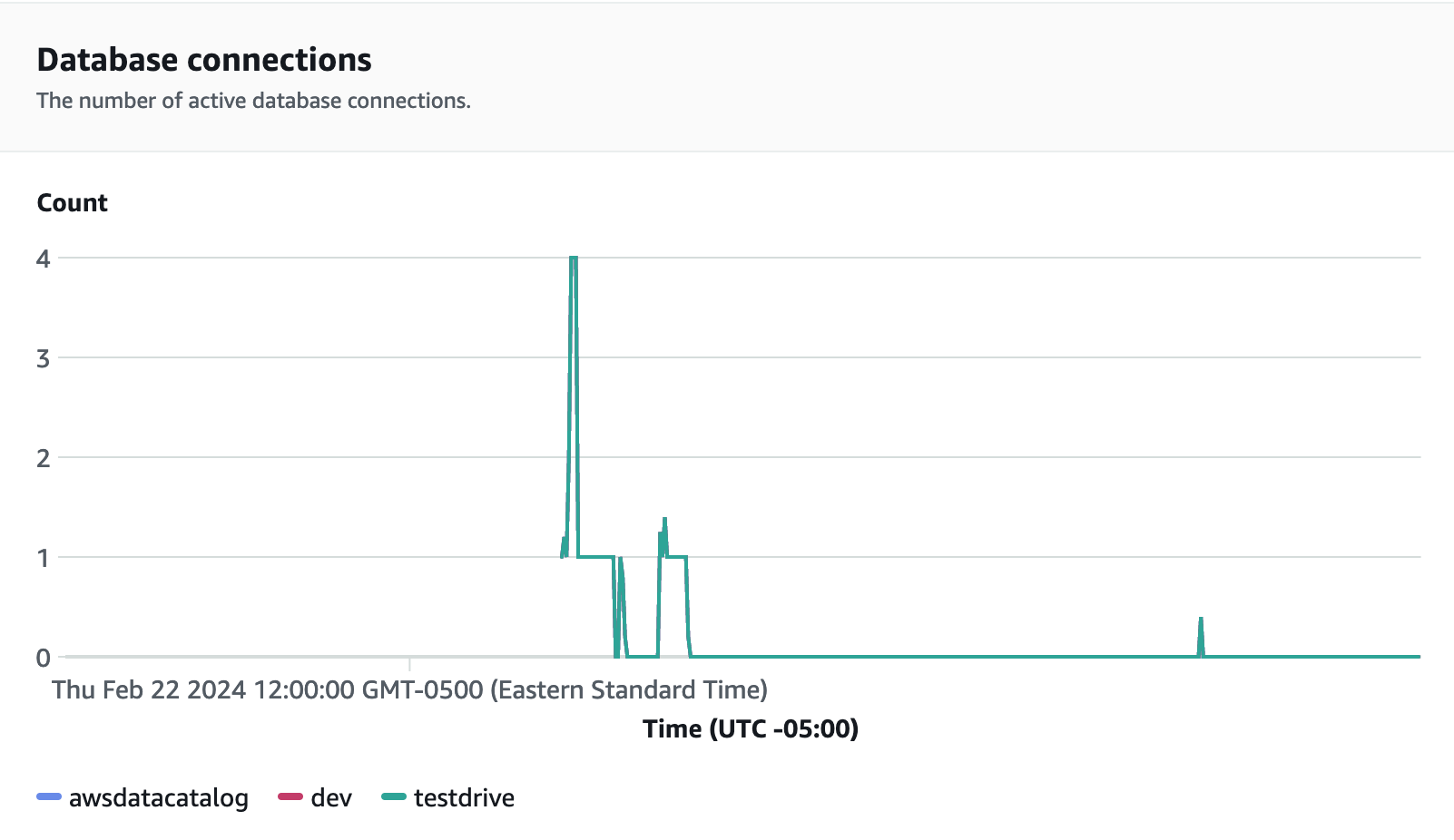
Datenbankverbindungen sind eine weitere nützliche Metrik, die Sie während der Ausführung des Auslastungstests überwachen können, um zu sehen, wie Ihre Arbeitsgruppe zahlreiche gleichzeitige Verbindungen zu einem bestimmten Zeitpunkt verarbeitet, um den steigenden Workload-Anforderungen gerecht zu werden.
Schritt 5: Optimieren

Amazon Redshift ermöglicht es Zehntausenden von Benutzern, täglich Exabyte an Daten zu verarbeiten und ihre Analytik-Workloads zu optimieren, indem es eine Vielzahl von Konfigurationen und Features zur Unterstützung individueller Anwendungsfälle bereitstellt. Bei der Wahl zwischen diesen Optionen suchen Kunden nach Tools, mit denen sie die optimale Data-Warehouse-Konfiguration zur Unterstützung ihrer Amazon-Redshift-Workloads ermitteln können.
Test Drive
Sie können Test Drive
