Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
LLMs und RAG verstehen
Um zu verstehen, wie die Verbesserung der Qualität von Quelldokumenten die Qualität einer RAG-Antwort verbessert, müssen Sie die internen Abläufe eines LLM verstehen. Die wahre Stärke von LLMs liegt in ihrer Fähigkeit, Selbstaufmerksamkeitsmechanismen und Transformatorarchitekturen zu nutzen. Diese fortschrittlichen Techniken ermöglichen es den Modellen, verschiedene Teile der Eingabesequenz effektiv zu verarbeiten und miteinander in Beziehung zu setzen, unabhängig von ihrer Position oder Entfernung innerhalb des Textes. Diese Fähigkeit steht in krassem Gegensatz zu herkömmlichen Sprachmodellen, die oft mit langfristigen Abhängigkeiten und dem Verständnis des Kontextes zu kämpfen haben. Darüber hinaus werden LLMs in einem noch nie dagewesenen Umfang geschult. Einige der größten Modelle bestehen aus Billionen von Parametern und haben Terabyte an Textdaten aus verschiedenen Quellen aufgenommen. Dieser enorme Umfang ermöglicht es LLMs, ein umfassendes Sprachverständnis zu entwickeln und subtile Nuancen, Redewendungen und kontextuelle Hinweise zu erfassen, die für KI-Systeme bisher eine Herausforderung darstellten. Das Ergebnis ist eine Klasse von Modellen, die in der Lage sind, kohärenten und fließenden Text zu generieren und bemerkenswerte Fähigkeiten bei Aufgaben wie der Beantwortung von Fragen, der Textzusammenfassung und sogar der Codegenerierung unter Beweis zu stellen.
Um diese Modelle zu nutzen, können wir uns an Dienste wie Amazon Bedrock wenden, das Zugriff auf eine Vielzahl von Fundamentmodellen von Amazon und Drittanbietern wie Anthropic, Cohere und Meta bietet. Sie können Amazon Bedrock verwenden, um mit hochmodernen Modellen zu experimentieren, sie anzupassen und zu optimieren oder sie über eine einzige API in Ihre generativen AI-powered Lösungen zu integrieren.
LLMs zeichnen sich zwar durch die Erfassung von Mustern und die Generierung von kohärentem Text aus, haben jedoch häufig keinen Zugang zu aktuellen oder speziellen Informationen. RAG kombiniert die generativen Fähigkeiten von LLMs mit einer Abrufkomponente, die im Rahmen der materialisierten LLM-Aufforderung auf relevante Informationen aus externen Quellen zugreifen und diese integrieren kann. Beispiele für externe Quellen sind Knowledge Bases für Amazon Bedrock, intelligente Suchsysteme wie Amazon Kendra oder Vektordatenbanken wie Amazon OpenSearch Service.
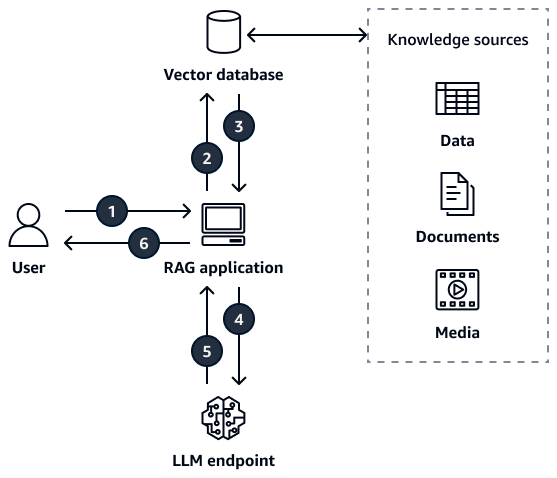
Das Diagramm beschreibt den folgenden Arbeitsablauf:
-
Der Benutzer sendet eine Anfrage an die RAG-Anwendung.
-
Die RAG-Anwendung fragt eine Vektordatenbank ab, die Wissensquellen wie Dokumente, Daten oder Medien enthält.
-
Die RAG-Anwendung ruft die relevanten Informationen auf der Grundlage semantischer Ähnlichkeiten zwischen der Abfrage und den gespeicherten Dokumenten aus der Vektordatenbank ab.
-
Die RAG-Anwendung erweitert die ursprüngliche Aufforderung um den abgerufenen Kontext und sendet ihn an den LLM-Endpunkt.
-
Der LLM-Endpunkt generiert eine Antwort und gibt sie an die RAG-Anwendung zurück.
-
Die RAG-Anwendung gibt die generierte Antwort an den Benutzer zurück.
RAG verwendet im Kern einen zweistufigen Prozess. In der ersten Phase identifiziert und ruft ein Abrufmodell relevante Dokumente oder Passagen auf der Grundlage der Eingabeabfrage ab. Bei diesem Abrufmodell kann es sich um ein herkömmliches Informationsabrufsystem, ein dichtes Abrufmodell oder eine Kombination aus beidem handeln. In der zweiten Phase werden die abgerufenen Informationen und die ursprüngliche Anfrage als vollständig materialisierte Eingabeaufforderungsvorlage in ein LLM eingespeist. LLMs hängen stark von der Qualität des Quellinhalts ab, der von der Retriever-Komponente geliefert wird. Sie wenden einen Mechanismus der Selbstaufmerksamkeit an, um mathematisch zu kodieren, wie sich der abgerufene Inhalt auf die Aufgabe bezieht. Das LLM generiert dann eine Antwort, die sowohl auf der Anfrage als auch auf den abgerufenen Informationen basiert. In RAG stellt die Kontrolle der Qualität der abgerufenen Quelldokumente ein direktes Mittel zur Verbesserung der internen Darstellung einer Aufgabe durch ein LLM dar. RAG ergänzt die Trainingsdaten des LLM effektiv mit relevanten externen Daten. Dieser Ansatz ermöglicht es der RAG, die Stärken sowohl von LLMs als auch von Retrievalsystemen zu nutzen und so genauere und fundiertere Antworten zu generieren, die aktuelles und spezialisiertes Wissen einbeziehen.
Vektoren und Einbettungen
Vektoren und Einbettungen sind grundlegende Konzepte des maschinellen Lernens und der Verarbeitung natürlicher Sprache. Vektoren sind mathematische Objekte, die Größen darstellen, die sowohl Größe als auch Richtung haben. Im Kontext der Verarbeitung natürlicher Sprache (NLP) werden Wörter, Sätze oder Dokumente häufig als Vektoren in hochdimensionalen Vektorräumen dargestellt. Einbettungen hingegen sind eine Möglichkeit, Objekte wie Wörter oder Dokumente in einem niederdimensionalen Vektorraum darzustellen, in dem die Beziehungen zwischen den Vektoren semantische oder syntaktische Ähnlichkeiten aufweisen. Worteinbettungen ermöglichen es beispielsweise Wörtern mit ähnlicher Bedeutung, ähnliche Vektordarstellungen zu haben. Dies hilft Algorithmen, Sprache effektiver zu verstehen und zu verarbeiten.
Vektor-Datenbanken
In der generativen KI ist eine Vektordatenbank eine Datenbank, die Vektordarstellungen von Dokumenten, Abfragen oder anderen Objekten speichert und verwaltet. Sie wurde entwickelt, um Vektoren effizient zu speichern und abzurufen. Dies unterstützt schnelle und skalierbare Operationen wie semantische Suche und Ähnlichkeitsabgleich. Vektordatenbanken indizieren Vektoren mithilfe spezialisierter Datenstrukturen wie Hierarchical Navigable Small World (HNSW) -Graphen oder K-Nearest Neighbors-Algorithmen (KNN). Diese Datenstrukturen ermöglichen eine schnelle Suche nach dem nächsten Nachbarn, sodass ähnliche Vektoren schnell in der Datenbank gefunden werden können.
Semantische Suche
Die semantische Suche ist eine Technik, mit der die Relevanz von Suchergebnissen verbessert wird, indem sie die Absicht und den Kontext der Anfrage versteht und nicht nur nach passenden Schlüsselwörtern sucht. Technisch gesehen beinhaltet die semantische Suche den Vergleich der Vektordarstellungen der Abfrage mit den Dokumenten in der Datenbank, um die relevantesten Treffer zu finden. Für die semantische Suche können verschiedene Abrufstrategien verwendet werden, darunter, aber nicht beschränkt auf:
-
HNSW — Eine graphenbasierte Datenstruktur, die Vektoren so organisiert, dass die Suche nach nächstgelegenen Nachbarn effizient ist.
-
KNN — Ein Algorithmus, der anhand einer Entfernungsmetrik, z. B. der Kosinusähnlichkeit, die K Vektoren ermittelt, die einem Abfragevektor am nächsten sind.
-
Kosinusähnlichkeit — Ein Maß für die Ähnlichkeit zwischen zwei Vektoren, die ungleich Null sind, das den Kosinus des Winkels zwischen ihnen misst. Es wird häufig bei der semantischen Suche verwendet, um die Richtung von Vektoren in einem hochdimensionalen Raum zu vergleichen.
-
Locality-sensitive Hashing (LSH) — Eine Technik, bei der ähnliche Vektoren mit hoher Wahrscheinlichkeit in dieselben oder benachbarte Buckets gehasht werden. Dies ermöglicht die ungefähre Suche nach dem nächsten Nachbarn, was schneller sein kann als exakte Suchen in hochdimensionalen Räumen.
