Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Plan in Amazon Redshift abfragen
Ein Abfrageplan ist eine Liste von Anweisungen, die die Ausführungs-Engine befolgen muss, um eine Abfrage der Daten auszuführen. Sie können einen Abfrageplan erstellen, indem Sie den Befehl EXPLAIN gefolgt vom eigentlichen Abfragetext ausführen, wie die folgende Beispielabfrage zeigt:
EXPLAIN select s.s_name, sum(li.l_quantity) as quantity from tpch.lineitem li join tpch.orders o on o.o_orderkey = li.l_orderkey and o.o_orderdate > '1992-05-01' join tpch.supplier s on s.s_suppkey = li.l_suppkey group by s.s_name order by quantity desc limit 10;
Wenn Sie den EXPLAIN Befehl für das obige Abfragebeispiel ausführen, erhalten Sie die folgende Ausgabe:
XN Limit (cost=1004400430902.15..1004400430902.17 rows=10 width=39) -> XN Merge (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Merge Key: sum(li.l_quantity) -> XN Network (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Send to leader -> XN Sort (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Sort Key: sum(li.l_quantity) -> XN HashAggregate (cost=4400430218.24..4400430243.06 rows=9928 width=39) -> XN Hash Join DS_BCAST_INNER (cost=21489.58..4400401726.35 rows=5698378 width=39) Hash Cond: ("outer".l_suppkey = "inner".s_suppkey) -> XN Hash Join DS_DIST_NONE (cost=21364.58..273387.85 rows=5698378 width=14) Hash Cond: ("outer".l_orderkey = "inner".o_orderkey) -> XN Seq Scan on lineitem li (cost=0.00..60012.15 rows=6001215 width=22) -> XN Hash (cost=17803.81..17803.81 rows=1424306 width=8) -> XN Seq Scan on orders o (cost=0.00..17803.81 rows=1424306 width=8) Filter: (o_orderdate > '1992-05-01'::date) -> XN Hash (cost=100.00..100.00 rows=10000 width=33) -> XN Seq Scan on supplier s (cost=0.00..100.00 rows=10000 width=33)
Anmerkung
Bei der Beispielausgabe eines Abfrageplans handelt es sich um eine vereinfachte, allgemeine Ansicht der Abfrageausführung. Der Beispielplan veranschaulicht nicht die Details der parallel Abfrageverarbeitung. Ausführliche Informationen erhalten Sie, wenn Sie die Abfrage ausführen und dann die Ansichten SVL_QUERY_SUMMARY oder SVL_QUERY_REPORT verwenden, um zusammenfassende Informationen zur Abfrage abzurufen.
Amazon-Redshift-Abfrage-Editor v2
Sie können die Abfragepläne auch in Amazon Redshift anzeigen, indem Sie die Option Explain im Abfrage-Editor v2 verwenden. Anweisungen finden Sie unter Arbeiten mit dem Abfrage-Editor v2 in der Amazon Redshift Redshift-Dokumentation.
Der vom Abfrage-Editor v2 generierte Abfrageplan enthält die folgenden Informationen:
-
Welche Operationen führt die Ausführungs-Engine durch, wobei sie die Ergebnisse von unten nach oben liest
-
Welche Art von Schritt führt jede Operation aus
-
Welche Tabellen und Spalten werden in den einzelnen Operationen verwendet
-
Wie viele Daten werden in jedem Vorgang verarbeitet, gemessen an der Anzahl der Zeilen und der Datenbreite in Byte
-
Die relativen Kosten des Vorgangs (Die Kosten sind eine Kennzahl, mit der die relativen Ausführungszeiten der Schritte innerhalb eines Plans verglichen werden. Die Kosten liefern keine genauen Informationen über die tatsächlichen Ausführungszeiten oder den Speicherverbrauch und ermöglichen auch keinen aussagekräftigen Vergleich zwischen Ausführungsplänen. Die Kosten geben Ihnen jedoch einen Hinweis darauf, welche Operationen in einer Abfrage die meisten Ressourcen verbrauchen.)
ERLÄUTERN SIE DIE PLÄNE
Sie können die STL_EXPLAIN-Systemtabelle verwenden, um den EXPLAIN Plan für eine Abfrage anzuzeigen, die zur Ausführung eingereicht wurde. Insgesamt STL_EXPLAIN kann die Verwendung dazu beitragen, die Leistung, Effizienz und Kosteneffektivität Ihrer Amazon Redshift Redshift-Abfragen zu verbessern.
Die Verwendung STL_EXPLAIN bietet folgende Vorteile:
-
Leistungsoptimierung —
STL_EXPLAINkann dabei helfen, Bereiche einer Abfrage zu identifizieren, die für eine bessere Leistung optimiert werden können. -
Abfrageplanung —
STL_EXPLAINkann Informationen darüber liefern, wie Amazon Redshift die Abfrage ausführt, und kann helfen, potenzielle Engpässe in der Abfrage zu identifizieren. -
Debugging —
STL_EXPLAINkann bei der Diagnose von Problemen mit einer Abfrage helfen, indem es die Schritte zeigt, die Amazon Redshift zur Ausführung dieser Abfrage unternimmt. -
Das Verständnis des Verhaltens von Amazon Redshift —
STL_EXPLAINkann Einblicke in die Verarbeitung von Abfragen durch Amazon Redshift geben. Dies kann dazu beitragen, Ihr Verständnis des Verhaltens von Amazon Redshift zu verbessern. -
Kostenoptimierung —
STL_EXPLAINkann Informationen über die geschätzten Kosten einer Anfrage liefern. Auf diese Weise können Sie Bereiche identifizieren, in denen Sie die Kosten optimieren können.
Die folgende Abfrage ist ein Beispiel, das die Planknoten für eine bestimmte Abfrage zurückgibt:
select nodeid as id, plannode, info from stl_explain where query=1042904 order by nodeid;
Die vorherige Abfrage gibt die folgende Ausgabe zurück.
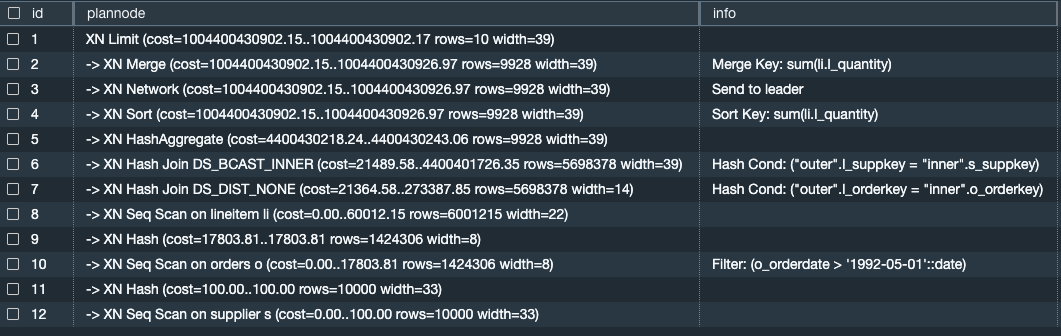
Der EXPLAIN Plan gibt nützliche Messwerte für jeden Vorgang zurück, einschließlich Kennzahlen zu Kosten, Zeilen und Breite. In Zeile 7 der vorherigen Abfrage wird beispielsweise Folgendes zurückgegeben:
-> XN Hash Join DS_DIST_NONE (cost=21364.58..273387.85 rows=5698378 width=14)
Kosten
Kosten sind ein relativer Wert, der für den Vergleich von Vorgängen innerhalb eines Plans nützlich ist. Die Kosten bestehen aus zwei Dezimalwerten, die durch zwei Perioden getrennt sind. In diesem Beispiel entsprechen die Kosten21364.58..273387.85. Berücksichtigen Sie dabei Folgendes:
-
Der erste Wert (in diesem Fall
21364.58) gibt die relativen Kosten für die Rückgabe der ersten Zeile für diesen Vorgang an. -
Der zweite Wert (in diesem Fall
273387.85) gibt die relativen Kosten für den Abschluss des Vorgangs an.
Die Kosten im Abfrageplan sind kumulativ und werden von niedrigeren zu höheren Zeilen zusammengefasst. In der obigen Beispielausgabe enthält Zeile 7 die Kosten der anderen Operationen in den Zeilen darunter (d. h. Zeilen 8—12 und darüber hinaus).
Rows
Zeilen ist die geschätzte Anzahl der zurückzugebenden Zeilen. In diesem Beispiel wird erwartet, dass der Scan 5.698.378 Zeilen zurückgibt. Die Schätzung der Zeilen basiert auf den verfügbaren Statistiken, die durch den Befehl generiert wurden. ANALYZE Wenn ANALYZE die Schätzung in letzter Zeit nicht ausgeführt wurde, ist sie weniger zuverlässig.
Width
Die Breite ist die geschätzte Breite der durchschnittlichen Zeile in Byte. In diesem Beispiel wird erwartet, dass die durchschnittliche Zeile 14 Byte breit ist.
