Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Persönliche Daten (OU — PD), Anwendungskonto
Umfrage
Wir würden uns freuen, von Ihnen zu hören. Bitte geben Sie Feedback zur AWS PRA, indem Sie an einer kurzen Umfrage teilnehmen
Das Anwendungskonto für personenbezogene Daten (PD) ist der Ort, an dem Ihr Unternehmen Dienste hostet, die personenbezogene Daten erheben und verarbeiten. Insbesondere können Sie in diesem Konto speichern, was Sie als personenbezogene Daten definieren. Die AWS PRA demonstriert anhand einer mehrstufigen serverlosen Webarchitektur eine Reihe von Beispielkonfigurationen für den Datenschutz. Wenn es darum geht, Workloads in einer AWS landing zone zu betreiben, sollten Datenschutzkonfigurationen nicht als one-size-fits-all Lösung betrachtet werden. Ihr Ziel könnte beispielsweise darin bestehen, die zugrunde liegenden Konzepte zu verstehen, zu erfahren, wie sie den Datenschutz verbessern können und wie Ihr Unternehmen Lösungen für Ihre speziellen Anwendungsfälle und Architekturen anwenden kann.
Denn AWS-Konten in Ihrem Unternehmen, das personenbezogene Daten sammelt, speichert oder verarbeitet, können Sie grundlegende AWS Organizations und wiederholbare AWS Control Tower Schutzmaßnahmen verwenden und einsetzen. Die Einrichtung einer eigenen Organisationseinheit (OU) für diese Konten ist von entscheidender Bedeutung. Möglicherweise möchten Sie Schutzmaßnahmen für die Datenresidenz nur auf eine Teilmenge von Konten anwenden, bei denen die Datenspeicherung eine zentrale Entwurfsüberlegung ist. Für viele Organisationen sind dies die Konten, die personenbezogene Daten speichern und verarbeiten.
Ihr Unternehmen könnte die Unterstützung eines speziellen Datenkontos in Betracht ziehen, in dem Sie die maßgebliche Quelle Ihrer persönlichen Datensätze speichern. Eine verlässliche Datenquelle ist ein Ort, an dem Sie die Primärversion von Daten speichern, die als die zuverlässigste und genaueste Version der Daten angesehen werden kann. Beispielsweise können Sie die Daten aus der autoritativen Datenquelle an andere Speicherorte kopieren, z. B. Amazon Simple Storage Service (Amazon S3) -Buckets im PD-Anwendungskonto, die zum Speichern von Trainingsdaten, einer Teilmenge von Kundendaten und geschwärzten Daten verwendet werden. Indem Sie diesen Ansatz mit mehreren Konten verwenden, um vollständige und endgültige personenbezogene Datensätze im Datenkonto von den nachgelagerten Kunden-Workloads im PD-Anwendungskonto zu trennen, können Sie den Umfang der Auswirkungen verringern, die bei einem unbefugten Zugriff auf Ihre Konten entstehen.
Das folgende Diagramm zeigt die AWS Sicherheits- und Datenschutzdienste, die in den Konten PD Application und Data konfiguriert sind.
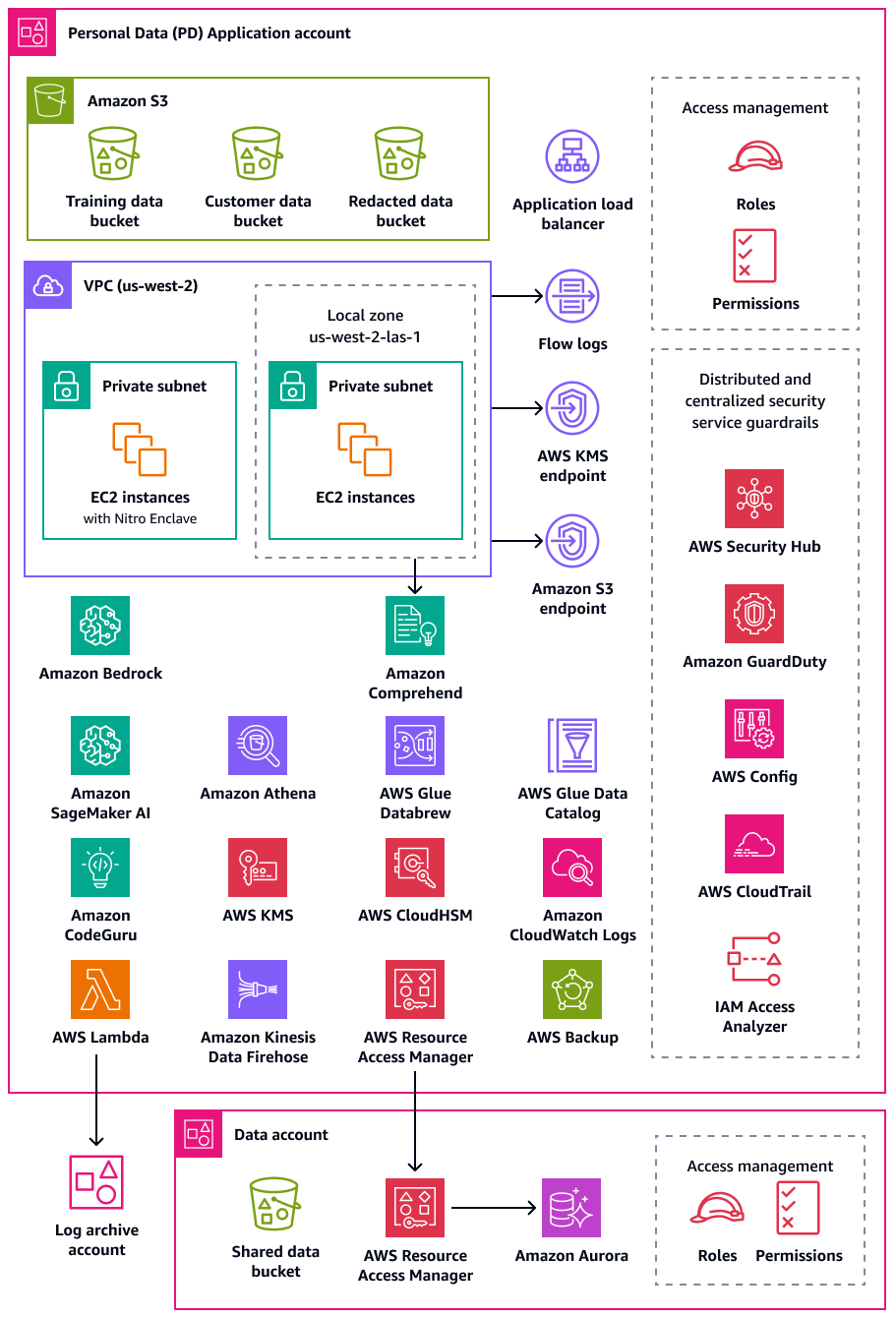
Dieser Abschnitt enthält detailliertere Informationen zu den folgenden Elementen AWS-Services , die in diesen Konten verwendet werden:
Amazon Athena
Sie können Kontrollen zur Beschränkung von Datenabfragen in Betracht ziehen, um Ihre Datenschutzziele zu erreichen. Amazon Athena ist ein interaktiver Abfrageservice, mit dem Sie Daten mithilfe von Standard-SQL direkt in Amazon S3 analysieren können. Sie müssen die Daten nicht in Athena laden; es funktioniert direkt mit den in S3-Buckets gespeicherten Daten.
Ein häufiger Anwendungsfall für Athena ist die Bereitstellung maßgeschneiderter und bereinigter Datensätze für Datenanalyseteams. Wenn die Datensätze personenbezogene Daten enthalten, können Sie den Datensatz bereinigen, indem Sie ganze Spalten mit personenbezogenen Daten maskieren, die für die Datenanalyseteams wenig Wert bieten. Weitere Informationen finden Sie unter Anonymisieren und verwalten Sie Daten in Ihrem Data Lake mit Amazon Athena und AWS Lake Formation
Wenn Ihr Datentransformationsansatz zusätzliche Flexibilität außerhalb der unterstützten Funktionen in Athena erfordert, können Sie benutzerdefinierte Funktionen definieren, die als benutzerdefinierte Funktionen (UDF) bezeichnet werden. Sie können sie UDFs in einer an Athena gesendeten SQL-Abfrage aufrufen, und sie laufen weiter. AWS Lambda Sie können UDFs in SELECT - und FILTER
SQL Abfragen verwenden, und Sie können mehrere UDFs in derselben Abfrage aufrufen. Aus Datenschutzgründen können Sie Vorlagen erstellen UDFs , die bestimmte Arten der Datenmaskierung durchführen, z. B. nur die letzten vier Zeichen jedes Werts in einer Spalte anzeigen.
Amazon Bedrock
Amazon Bedrock ist ein vollständig verwalteter Service, der Zugriff auf Basismodelle von führenden KI-Unternehmen wie AI21 Labs, Anthropic, Meta, Mistral AI und Amazon bietet. Er hilft Unternehmen dabei, generative KI-Anwendungen zu entwickeln und zu skalieren. Unabhängig davon, welche Plattform verwendet wird, können Unternehmen bei der Verwendung generativer KI Datenschutzrisiken ausgesetzt sein, einschließlich der potenziellen Offenlegung personenbezogener Daten, unbefugtem Datenzugriff und anderen Compliance-Verstößen.
Amazon Bedrock Guardrails wurde entwickelt, um diese Risiken zu minimieren, indem bewährte Sicherheits- und Compliance-Verfahren für Ihre generativen KI-Workloads in Amazon Bedrock durchgesetzt werden. Der Einsatz und die Nutzung von KI-Ressourcen entsprechen möglicherweise nicht immer den Datenschutz- und Compliance-Anforderungen eines Unternehmens. Organizations können Schwierigkeiten haben, den Datenschutz zu wahren, wenn sie generative KI-Modelle verwenden, da diese Modelle möglicherweise sensible Informationen speichern oder reproduzieren können. Amazon Bedrock Guardrails trägt zum Schutz der Privatsphäre bei, indem es Benutzereingaben auswertet und Antworten modelliert. Wenn die Eingabedaten personenbezogene Daten enthalten, kann insgesamt das Risiko bestehen, dass diese Informationen in der Ausgabe des Modells offengelegt werden.
Amazon Bedrock Guardrails bietet Mechanismen zur Durchsetzung von Datenschutzrichtlinien und zur Verhinderung unbefugter Datenoffenlegung. Es bietet Funktionen zur Inhaltsfilterung, um personenbezogene Daten in Eingaben zu erkennen und zu blockieren, thematische Einschränkungen, um den Zugriff auf unangemessene oder riskante Themen zu verhindern, und Wortfilter, um sensible Begriffe in Modellaufforderungen und -antworten zu maskieren oder zu schwärzen. Diese Funktionen tragen dazu bei, Ereignisse zu verhindern, die zu Datenschutzverletzungen führen könnten, wie z. B. voreingenommene Antworten oder die Erosion des Kundenvertrauens. Mithilfe dieser Funktionen können Sie sicherstellen, dass personenbezogene Daten von Ihren KI-Modellen nicht versehentlich verarbeitet oder weitergegeben werden. Amazon Bedrock Guardrails unterstützt die Auswertung von Eingaben und Antworten auch außerhalb von Amazon Bedrock. Weitere Informationen finden Sie unter Implementieren modellunabhängiger Sicherheitsmaßnahmen mit Amazon Bedrock Guardrails
Mit Amazon Bedrock Guardrails können Sie das Risiko von Modellhalluzinationen begrenzen, indem Sie kontextuelle Bodenprüfungen verwenden, bei denen die sachliche Grundlage und die Relevanz der Antworten bewertet werden. Ein Beispiel ist die Bereitstellung einer generativen KI-Anwendung für Kunden, die Datenquellen von Drittanbietern in einer Retrieval Augmented Generation (RAG) -Anwendung verwendet.
AWS Clean Rooms
Da Unternehmen nach Möglichkeiten suchen, durch die Analyse sich überschneidender oder sich überschneidender sensibler Datensätze miteinander zusammenzuarbeiten, ist die Wahrung der Sicherheit und des Datenschutzes dieser gemeinsam genutzten Daten ein wichtiges Anliegen. AWS Clean Roomsunterstützt Sie bei der Einrichtung von Datenreinräumen, d. h. sicheren, neutralen Umgebungen, in denen Unternehmen kombinierte Datensätze analysieren können, ohne die Rohdaten selbst gemeinsam nutzen zu müssen. Es kann auch zu einzigartigen Erkenntnissen führen, indem es anderen Organisationen Zugriff gewährt, AWS ohne Daten aus ihren eigenen Konten verschieben oder kopieren zu müssen und ohne den zugrunde liegenden Datensatz preiszugeben. Alle Daten verbleiben am Quellspeicherort. Integrierte Analyseregeln schränken die Ausgabe und die SQL-Abfragen ein. Alle Abfragen werden protokolliert, und Mitglieder der Kollaboration können sehen, wie ihre Daten abgefragt werden.
Sie können eine AWS Clean Rooms Kollaboration erstellen und andere AWS Kunden einladen, Mitglieder dieser Kollaboration zu werden. Sie gewähren einem Mitglied die Möglichkeit, die Mitgliederdatensätze abzufragen, und Sie können weitere Mitglieder auswählen, die die Ergebnisse dieser Abfragen erhalten sollen. Wenn mehr als ein Mitglied die Datensätze abfragen muss, können Sie zusätzliche Kollaborationen mit denselben Datenquellen und unterschiedlichen Mitgliedereinstellungen erstellen. Jedes Mitglied kann die Daten filtern, die mit den Mitgliedern der Kollaboration geteilt werden, und Sie können benutzerdefinierte Analyseregeln verwenden, um Beschränkungen dafür festzulegen, wie die Daten, die es der Kollaboration zur Verfügung stellt, analysiert werden können.
Neben der Beschränkung der Daten, die der Kollaboration zur Verfügung gestellt werden, und der Art und Weise, wie sie von anderen Mitgliedern verwendet werden können, stehen Ihnen auch die folgenden Funktionen zur AWS Clean Rooms Verfügung, mit denen Sie Ihre Privatsphäre schützen können:
-
Differentieller Datenschutz ist ein mathematisches Verfahren, das die Privatsphäre der Benutzer verbessert, indem den Daten eine sorgfältig abgestimmte Menge an Rauschen hinzugefügt wird. Dies trägt dazu bei, das Risiko einer erneuten Identifizierung einzelner Benutzer innerhalb des Datensatzes zu verringern, ohne die interessierenden Werte zu verschleiern. Für die Verwendung von AWS Clean Rooms Differential Privacy sind keine unterschiedlichen Datenschutzkenntnisse erforderlich.
-
AWS Clean Rooms ML ermöglicht es zwei oder mehr Parteien, ähnliche Benutzer in ihren Daten zu identifizieren, ohne die Daten direkt miteinander zu teilen. Dadurch wird das Risiko von Inferenzangriffen auf Mitglieder reduziert, bei denen ein Mitglied der Kollaboration Personen im Datensatz des anderen Mitglieds identifizieren kann. Durch die Erstellung eines Lookalike-Modells und die Generierung eines Lookalike-Segments hilft Ihnen AWS Clean Rooms ML dabei, Datensätze zu vergleichen, ohne die Originaldaten offenzulegen. Dies setzt nicht voraus, dass eines der Mitglieder über ML-Fachkenntnisse verfügt oder Arbeiten außerhalb von ausführt. AWS Clean Rooms Sie behalten die volle Kontrolle und das Eigentum an dem trainierten Modell.
-
Cryptographic Computing for Clean Rooms (C3R) kann zusammen mit Analyseregeln verwendet werden, um Erkenntnisse aus sensiblen Daten zu gewinnen. Es schränkt kryptografisch ein, was jede andere an der Zusammenarbeit beteiligte Partei lernen kann. Mit dem C3R-Verschlüsselungsclient werden die Daten auf dem Client verschlüsselt, bevor sie an ihn weitergegeben werden. AWS Clean Rooms Da die Datentabellen mit einem clientseitigen Verschlüsselungstool verschlüsselt werden, bevor sie auf Amazon S3 hochgeladen werden, bleiben die Daten verschlüsselt und bleiben während der Verarbeitung erhalten.
In der AWS PRA empfehlen wir, AWS Clean Rooms Kollaborationen im Datenkonto zu erstellen. Sie können sie verwenden, um verschlüsselte Kundendaten mit Dritten zu teilen. Verwenden Sie sie nur, wenn sich die bereitgestellten Datensätze überschneiden. Weitere Informationen zur Bestimmung von Überschneidungen finden Sie in der AWS Clean Rooms Dokumentation unter Analyseregel auflisten.
CloudWatch Amazon-Protokolle
Amazon CloudWatch Logs hilft Ihnen dabei, die Protokolle all Ihrer Systeme und Anwendungen zu zentralisieren, AWS-Services sodass Sie sie überwachen und sicher archivieren können. In CloudWatch Logs können Sie eine Datenschutzrichtlinie für neue oder bestehende Protokollgruppen verwenden, um das Risiko der Offenlegung personenbezogener Daten zu minimieren. Mithilfe von Datenschutzrichtlinien können sensible Daten, wie z. B. personenbezogene Daten, in Ihren Protokollen erkannt werden. Die Datenschutzrichtlinie kann diese Daten maskieren, wenn Benutzer über die auf die Protokolle zugreifen AWS-Managementkonsole. Wenn Benutzer gemäß der allgemeinen Zweckspezifikation für Ihren Workload direkten Zugriff auf die personenbezogenen Daten benötigen, können Sie diesen Benutzern logs:Unmask Berechtigungen zuweisen. Sie können auch eine kontoweite Datenschutzrichtlinie erstellen und diese Richtlinie einheitlich auf alle Konten in Ihrer Organisation anwenden. Dadurch wird die Maskierung standardmäßig für alle aktuellen und future Protokollgruppen in CloudWatch Logs konfiguriert. Wir empfehlen außerdem, Prüfberichte zu aktivieren und sie an eine andere Protokollgruppe, einen Amazon S3 S3-Bucket oder Amazon Data Firehose zu senden. Diese Berichte enthalten eine detaillierte Aufzeichnung der Datenschutzergebnisse für jede Protokollgruppe.
CodeGuru Amazon-Rezensent
Sowohl aus Datenschutz- als auch aus Sicherheitsgründen ist es für viele Unternehmen von entscheidender Bedeutung, dass sie die kontinuierliche Einhaltung der Vorschriften sowohl während der Implementierung als auch nach der Bereitstellung gewährleisten. Die AWS PRA beinhaltet proaktive Kontrollen in den Bereitstellungspipelines für Anwendungen, die personenbezogene Daten verarbeiten. Amazon CodeGuru Reviewer kann potenzielle Fehler erkennen, durch die personenbezogene Daten in Java- und Python-Code offengelegt werden könnten. JavaScript Es bietet Entwicklern Vorschläge zur Verbesserung des Codes. CodeGuru Der Prüfer kann Fehler anhand einer Vielzahl von Sicherheits-, Datenschutz- und allgemein empfohlenen Vorgehensweisen identifizieren. Es wurde für die Zusammenarbeit mit mehreren Quellanbietern entwickelt AWS CodeCommit, darunter Bitbucket und Amazon S3. GitHub Zu den Datenschutzmängeln, die der CodeGuru Prüfer erkennen kann, gehören:
-
SQL-Injektion
-
Unsichere Cookies
-
Fehlende Autorisierung
-
Clientseitige Neuverschlüsselung AWS KMS
Eine vollständige Liste dessen, was CodeGuru Reviewer erkennen kann, finden Sie in der Amazon CodeGuru Detector Library.
Amazon Comprehend
Amazon Comprehend ist ein Service zur Verarbeitung natürlicher Sprache (NLP), der maschinelles Lernen nutzt, um wertvolle Erkenntnisse und Zusammenhänge in englischen Textdokumenten aufzudecken. Amazon Comprehend kann personenbezogene Daten in strukturierten, halbstrukturierten oder unstrukturierten Textdokumenten erkennen und redigieren. Weitere Informationen finden Sie unter Persönlich identifizierbare Informationen (PII) in der Amazon Comprehend Comprehend-Dokumentation.
Da Amazon Comprehend viele Optionen für die Anwendungsintegration bietet AWS SDKs, können Sie Amazon Comprehend verwenden, um personenbezogene Daten an vielen verschiedenen Orten zu identifizieren, an denen Sie Daten sammeln, speichern und verarbeiten. Sie können die Funktionen von Amazon Comprehend ML verwenden, um personenbezogene Daten in Anwendungsprotokollen
-
REPLACE_WITH_PII_ENTITY_TYPEersetzt jede PII-Entität durch ihre Typen. Zum Beispiel würde Jane Doe durch NAME ersetzt werden. -
MASKersetzt die Zeichen in PII-Entitäten durch ein Zeichen Ihrer Wahl (! , #, $,%, &,, oder @). Jane Doe könnte beispielsweise durch **** *** ersetzt werden.
Amazon Data Firehose
Amazon Data Firehose kann verwendet werden, um Streaming-Daten zu erfassen, zu transformieren und in nachgelagerte Dienste wie Amazon Managed Service für Apache Flink oder Amazon S3 zu laden. Firehose wird häufig verwendet, um große Mengen an Streaming-Daten, wie z. B. Anwendungsprotokolle, zu transportieren, ohne dass Verarbeitungspipelines von Grund auf neu erstellt werden müssen.
Sie können Lambda-Funktionen verwenden, um eine benutzerdefinierte oder integrierte Verarbeitung durchzuführen, bevor die Daten flussabwärts gesendet werden. Aus Datenschutzgründen unterstützt diese Funktion die Datenminimierung und Anforderungen an die grenzüberschreitende Datenübertragung. Sie können beispielsweise Lambda und Firehose verwenden, um Protokolldaten aus mehreren Regionen zu transformieren, bevor sie im Log Archive-Konto zentralisiert werden. Weitere Informationen finden Sie unter Biogen: Zentralisierte Protokollierungslösung für mehrere Konten
Amazon DataZone
Wenn Unternehmen ihren Ansatz zur gemeinsamen Nutzung von Daten über AWS-Services solche Systeme immer weiter ausweiten AWS Lake Formation, möchten sie sicherstellen, dass der differenzierte Zugriff von denjenigen kontrolliert wird, die mit den Daten am besten vertraut sind: den Dateneigentümern. Diese Dateneigentümer sind sich jedoch möglicherweise der Datenschutzanforderungen bewusst, wie z. B. der Einwilligung oder Überlegungen zur grenzüberschreitenden Datenübertragung. Amazon DataZone unterstützt die Dateneigentümer und das Data Governance-Team dabei, Daten unternehmensweit gemäß Ihren Datenverwaltungsrichtlinien auszutauschen und zu nutzen. Bei Amazon DataZone verwalten Geschäftsbereiche (LOBs) ihre eigenen Daten, und ein Katalog verfolgt diese Eigentümerschaft. Interessierte Parteien können im Rahmen ihrer Geschäftsaufgaben nach Daten suchen und Zugriff darauf beantragen. Solange die von den Datenherausgebern festgelegten Richtlinien eingehalten werden, kann der Dateneigentümer Zugriff auf die zugrunde liegenden Tabellen gewähren, ohne dass ein Administrator erforderlich ist oder die Daten verschoben werden müssen.
Im Datenschutzkontext DataZone kann Amazon in den folgenden Beispielanwendungsfällen hilfreich sein:
-
Eine kundenorientierte Anwendung generiert Nutzungsdaten, die an eine separate Marketing-Abteilung weitergegeben werden können. Sie müssen sicherstellen, dass nur Daten von Kunden, die sich für Marketing entschieden haben, im Katalog veröffentlicht werden.
-
Europäische Kundendaten werden zwar veröffentlicht, können aber nur von LOBs Einheimischen im Europäischen Wirtschaftsraum (EWR) abonniert werden. Weitere Informationen finden Sie unter Verbessern Sie die Datensicherheit mit detaillierten Zugriffskontrollen in Amazon
. DataZone
In der AWS PRA können Sie die Daten im gemeinsam genutzten Amazon S3 S3-Bucket mit Amazon DataZone als Datenproduzent verbinden.
AWS Glue
Die Pflege von Datensätzen, die personenbezogene Daten enthalten, ist ein wichtiger Bestandteil von Privacy by Design. Die Daten einer Organisation können in strukturierter, halbstrukturierter oder unstrukturierter Form vorliegen. Personenbezogene Datensätze ohne Struktur können die Durchführung einer Reihe von Maßnahmen zur Verbesserung des Datenschutzes erschweren, darunter die Datenminimierung, das Aufspüren von Daten, die einer einzelnen betroffenen Person im Rahmen einer Anfrage einer betroffenen Person zugeschrieben wurden, die Sicherstellung einer konsistenten Datenqualität und die allgemeine Segmentierung von Datensätzen. AWS Glueist ein vollständig verwalteter ETL-Service (Extrahieren, Transformieren und Laden). Er kann Ihnen helfen, Daten zu kategorisieren, zu bereinigen, anzureichern und zwischen Datenspeichern und Datenströmen zu verschieben. AWS Glue Funktionen sollen Ihnen helfen, Datensätze für Analysen, maschinelles Lernen und Anwendungsentwicklung zu entdecken, vorzubereiten, zu strukturieren und zu kombinieren. Sie können sie verwenden AWS Glue , um zusätzlich zu Ihren vorhandenen Datensätzen eine vorhersehbare und gemeinsame Struktur zu erstellen. AWS Glue Data Catalog, AWS Glue DataBrew, und AWS Glue Datenqualität sind AWS Glue Funktionen, die dazu beitragen können, die Datenschutzanforderungen Ihres Unternehmens zu erfüllen.
AWS Glue Data Catalog
AWS Glue Data Cataloghilft Ihnen dabei, verwaltbare Datensätze einzurichten. Der Datenkatalog enthält Verweise auf Daten, die als Quellen und Ziele für Extraktions-, Transformations- und Ladeaufträge (ETL) verwendet werden. AWS Glue Die Informationen im Datenkatalog werden als Metadatentabellen gespeichert, und jede Tabelle gibt einen einzelnen Datenspeicher an. Sie führen einen AWS Glue
Crawler aus, um die Daten in einer Vielzahl von Datenspeichertypen zu inventarisieren. Sie fügen dem Crawler integrierte und benutzerdefinierte Klassifikatoren hinzu, und diese Klassifikatoren leiten das Datenformat und das Schema der persönlichen Daten ab. Der Crawler schreibt dann die Metadaten in den Datenkatalog. Eine zentralisierte Metadatentabelle kann es einfacher machen, auf Anfragen von betroffenen Personen (z. B. das Recht auf Löschung) zu reagieren, da sie für Struktur und Vorhersehbarkeit bei unterschiedlichen Quellen personenbezogener Daten in Ihrer Umgebung sorgt. AWS Ein umfassendes Beispiel dafür, wie Sie Data Catalog verwenden können, um automatisch auf diese Anfragen zu antworten, finden Sie unter Umgang mit Datenlöschanfragen in Ihrem Data Lake mit Amazon S3 Find and Forget
AWS Glue DataBrew
AWS Glue DataBrewhilft Ihnen bei der Bereinigung und Normalisierung von Daten und kann Transformationen an den Daten durchführen, z. B. das Entfernen oder Maskieren personenbezogener Daten und das Verschlüsseln sensibler Datenfelder in Datenpipelines. Sie können die Herkunft Ihrer Daten auch visuell abbilden, um die verschiedenen Datenquellen und Transformationsschritte zu verstehen, die die Daten durchlaufen haben. Diese Funktion wird immer wichtiger, da Ihr Unternehmen daran arbeitet, die Herkunft personenbezogener Daten besser zu verstehen und nachzuverfolgen. DataBrew hilft Ihnen dabei, personenbezogene Daten bei der Datenaufbereitung zu maskieren. Sie können im Rahmen der Erstellung von Datenprofilen personenbezogene Daten erkennen und Statistiken erstellen, z. B. die Anzahl der Spalten, die personenbezogene Daten enthalten könnten, und mögliche Kategorien. Anschließend können Sie integrierte Techniken zur umkehrbaren oder irreversiblen Datentransformation verwenden, einschließlich Substitution, Hashing, Verschlüsselung und Entschlüsselung, ohne Code schreiben zu müssen. Sie können die bereinigten und maskierten Datensätze anschließend für Analyse-, Berichts- und Machine-Learning-Aufgaben verwenden. Zu den in verfügbaren Techniken zur Datenmaskierung gehören: DataBrew
-
Hashing — Wenden Sie Hashfunktionen auf die Spaltenwerte an.
-
Substitution — Ersetzen Sie persönliche Daten durch andere, authentisch aussehende Werte.
-
Nullstellen oder Löschen — Ersetzt ein bestimmtes Feld durch einen Nullwert oder löscht die Spalte.
-
Ausblenden — Verwenden Sie Zeichenverschlüsselung oder maskieren Sie bestimmte Teile in den Spalten.
Im Folgenden sind die verfügbaren Verschlüsselungstechniken aufgeführt:
-
Deterministische Verschlüsselung — Wenden Sie deterministische Verschlüsselungsalgorithmen auf die Spaltenwerte an. Deterministische Verschlüsselung erzeugt immer denselben Chiffretext für einen Wert.
-
Probabilistische Verschlüsselung — Wenden Sie probabilistische Verschlüsselungsalgorithmen auf die Spaltenwerte an. Probabilistische Verschlüsselung erzeugt bei jeder Anwendung einen anderen Chiffretext.
Eine vollständige Liste der bereitgestellten Rezepte zur Transformation personenbezogener Daten finden Sie unter DataBrew Rezeptschritte für personenbezogene Daten (PII).
AWS Glue Qualität der Daten
AWS Glue Data Quality hilft Ihnen dabei, die Bereitstellung hochwertiger Daten über Daten-Pipelines proaktiv zu automatisieren und zu operationalisieren, bevor sie an Ihre Datenverbraucher geliefert werden. AWS Glue Data Quality bietet statistische Analysen von Datenqualitätsproblemen in Ihren Daten-Pipelines, kann Warnmeldungen in Amazon EventBridge auslösen und Empfehlungen für Qualitätsregeln zur Behebung aussprechen. AWS Glue Data Quality unterstützt auch die Erstellung von Regeln in einer domänenspezifischen Sprache, sodass Sie benutzerdefinierte Datenqualitätsregeln erstellen können.
AWS Key Management Service
AWS Key Management Service (AWS KMS) hilft Ihnen dabei, kryptografische Schlüssel zu erstellen und zu kontrollieren, um Ihre Daten zu schützen. AWS KMS verwendet Hardware-Sicherheitsmodule zum Schutz und zur Validierung AWS KMS keys im Rahmen des FIPS 140-2 Cryptographic Module Validation Program. Weitere Informationen zur Verwendung dieses Dienstes in einem Sicherheitskontext finden Sie in der AWS Sicherheitsreferenzarchitektur.
AWS KMS lässt sich in AWS-Services die meisten Verschlüsselungslösungen integrieren, und Sie können KMS-Schlüssel in Ihren Anwendungen verwenden, die personenbezogene Daten verarbeiten und speichern. Sie können AWS KMS sie verwenden, um eine Vielzahl Ihrer Datenschutzanforderungen zu erfüllen und personenbezogene Daten zu schützen, darunter:
-
Mithilfe von vom Kunden verwalteten Schlüsseln haben Sie mehr Kontrolle über Gültigkeitsdauer, Rotation, Ablauf und andere Optionen.
-
Verwendung spezieller, vom Kunden verwalteter Schlüssel zum Schutz personenbezogener Daten und Geheimnisse, die den Zugriff auf persönliche Daten ermöglichen.
-
Definition von Datenklassifizierungsebenen und Benennung von mindestens einem dedizierten, vom Kunden verwalteten Schlüssel pro Ebene. Beispielsweise verfügen Sie möglicherweise über einen Schlüssel zum Verschlüsseln von Betriebsdaten und einen anderen zum Verschlüsseln personenbezogener Daten.
-
Verhinderung eines unbeabsichtigten kontoübergreifenden Zugriffs auf KMS-Schlüssel
-
Speichern von KMS-Schlüsseln innerhalb derselben Ressource AWS-Konto wie die zu verschlüsselnde Ressource.
-
Implementierung der Aufgabentrennung für die Verwaltung und Verwendung von KMS-Schlüsseln. Weitere Informationen finden Sie unter So verwenden Sie KMS und IAM, um unabhängige Sicherheitskontrollen für verschlüsselte Daten in S3 zu aktivieren
(AWS Blogbeitrag). -
Durchsetzung der automatischen Schlüsselrotation durch präventive und reaktive Schutzmaßnahmen
Standardmäßig werden KMS-Schlüssel gespeichert und können nur in der Region verwendet werden, in der sie erstellt wurden. Wenn Ihre Organisation spezielle Anforderungen an Datenresidenz und Datenhoheit stellt, sollten Sie überlegen, ob KMS-Schlüssel für mehrere Regionen für Ihren Anwendungsfall geeignet sind. Schlüssel für mehrere Regionen sind unterschiedliche KMS-Schlüssel für spezielle Zwecke, AWS-Regionen die synonym verwendet werden können. Bei der Erstellung eines regionsübergreifenden Schlüssels werden Ihre Schlüsselmaterialien über die AWS-Region Landesgrenzen hinweg transportiert AWS KMS, sodass diese fehlende regionale Abschottung möglicherweise nicht mit den Souveränitäts- und Ansässigkeitszielen Ihrer Organisation vereinbar ist. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, einen anderen Typ von KMS-Schlüssel zu verwenden, z. B. einen regionsspezifischen, vom Kunden verwalteten Schlüssel.
Externe Schlüsselspeicher
Für viele Unternehmen erfüllt der standardmäßige AWS KMS Schlüsselspeicher im AWS Cloud ihre Datenhoheit und allgemeine regulatorische Anforderungen. Einige erfordern jedoch möglicherweise, dass Verschlüsselungsschlüssel außerhalb einer Cloud-Umgebung erstellt und verwaltet werden und dass Sie über unabhängige Autorisierungs- und Prüfpfade verfügen. Wenn externe Schlüsselspeicher aktiviert sind AWS KMS, können Sie persönliche Daten mit Schlüsselmaterial verschlüsseln, das Ihrem Unternehmen gehört und außerhalb von AWS Cloud Sie interagieren weiterhin wie gewohnt mit der AWS KMS API, AWS KMS interagieren jedoch nur mit der externen Schlüsselspeicher-Proxy-Software (XKS-Proxy), die Sie bereitstellen. Ihr externer Schlüsselspeicher-Proxy vermittelt dann die gesamte Kommunikation zwischen AWS KMS und Ihrem externen Schlüsselmanager.
Wenn Sie einen externen Schlüsselspeicher für die Datenverschlüsselung verwenden, ist es wichtig, dass Sie den zusätzlichen Betriebsaufwand im Vergleich zur Aufbewahrung von Schlüsseln berücksichtigen. AWS KMS Bei einem externen Schlüsselspeicher müssen Sie den externen Schlüsselspeicher erstellen, konfigurieren und verwalten. Wenn die zusätzliche Infrastruktur, die Sie verwalten müssen, wie z. B. der XKS-Proxy, Fehler aufweist und die Konnektivität unterbrochen wird, können Benutzer die Daten möglicherweise vorübergehend nicht entschlüsseln und nicht darauf zugreifen. Arbeiten Sie eng mit den für die Einhaltung von Vorschriften und behördlichen Vorschriften zuständigen Stellen zusammen, um die rechtlichen und vertraglichen Verpflichtungen zur Verschlüsselung personenbezogener Daten sowie Ihre Service Level Agreements für Verfügbarkeit und Ausfallsicherheit zu verstehen.
AWS Lake Formation
Viele Organisationen, die ihre Datensätze mithilfe strukturierter Metadatenkataloge katalogisieren und kategorisieren, möchten diese Datensätze in ihrer gesamten Organisation gemeinsam nutzen. Sie können AWS Identity and Access Management (IAM) -Berechtigungsrichtlinien verwenden, um den Zugriff auf ganze Datensätze zu kontrollieren. Für Datensätze, die personenbezogene Daten unterschiedlicher Sensibilität enthalten, ist jedoch häufig eine genauere Kontrolle erforderlich. Beispielsweise könnten die Zweckspezifikation und die Nutzungsbeschränkung
Data Lakes, die den Zugriff auf große Mengen sensibler Daten
Sie können die tagbasierte Zugriffskontrollfunktion in Lake Formation verwenden. Die tagbasierte Zugriffskontrolle ist eine Autorisierungsstrategie, bei der Berechtigungen auf der Grundlage von Attributen definiert werden. In Lake Formation werden diese Attribute LF-Tags genannt. Mithilfe eines LF-Tags können Sie diese Tags an Datenbanken, Tabellen und Spalten im Datenkatalog anhängen und dieselben Tags auch IAM-Prinzipalen zuweisen. Lake Formation ermöglicht Operationen mit diesen Ressourcen, wenn dem Prinzipal Zugriff auf einen Tag-Wert gewährt wurde, der dem Ressourcen-Tag-Wert entspricht. Die folgende Abbildung zeigt, wie Sie LF-Tags und Berechtigungen zuweisen können, um einen differenzierten Zugriff auf personenbezogene Daten zu ermöglichen.
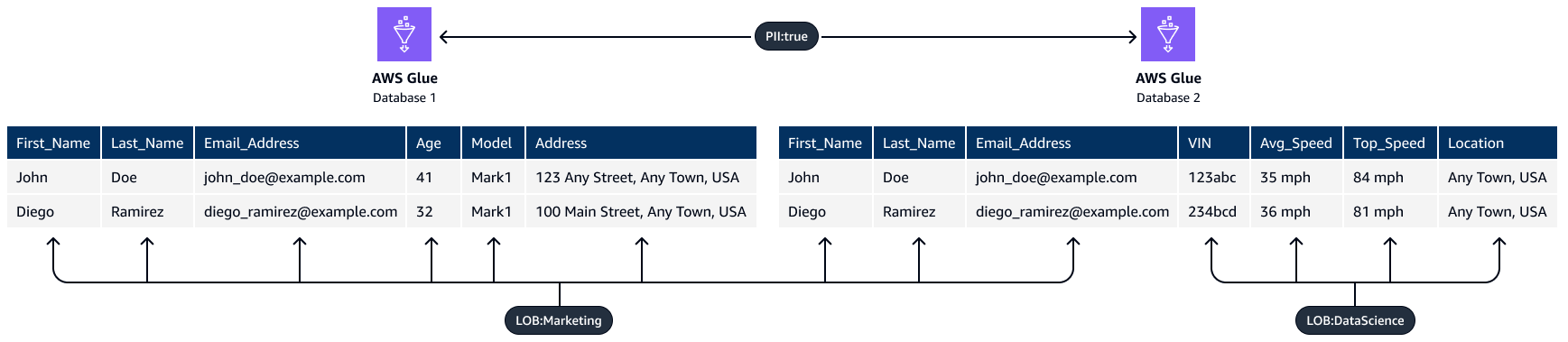
In diesem Beispiel wird der hierarchische Charakter von Tags verwendet. Beide Datenbanken enthalten persönlich identifizierbare Informationen (PII:true), aber Tags auf Spaltenebene beschränken bestimmte Spalten auf verschiedene Teams. In diesem Beispiel können IAM-Prinzipale mit dem PII:true LF-Tag auf die AWS Glue Datenbankressourcen zugreifen, die dieses Tag haben. Principals mit dem LOB:DataScience LF-Tag können auf bestimmte Spalten zugreifen, die dieses Tag haben, und Principals mit dem LOB:Marketing LF-Tag können nur auf Spalten zugreifen, die dieses Tag haben. Das Marketing kann nur auf PII zugreifen, die für Marketing-Anwendungsfälle relevant sind, und das Data-Science-Team kann nur auf PII zugreifen, die für seine Anwendungsfälle relevant sind.
AWS Local Zones
Wenn Sie die Anforderungen an die Datenresidenz erfüllen müssen, können Sie Ressourcen einsetzen, die personenbezogene Daten speichern und verarbeiten, um diese Anforderungen AWS-Regionen zu erfüllen. Sie können auch Ressourcen verwenden AWS Local Zones, die Ihnen dabei helfen, Rechen-, Speicher-, Datenbank- und andere ausgewählte AWS Ressourcen in der Nähe von Ballungs- und Industriezentren zu platzieren. Eine lokale Zone ist eine Erweiterung einer Zone AWS-Region , die sich in geografischer Nähe zu einer großen Metropolregion befindet. Sie können bestimmte Ressourcentypen innerhalb einer lokalen Zone in der Nähe der Region platzieren, der die lokale Zone entspricht. Local Zones können Ihnen dabei helfen, die Anforderungen an die Datenresidenz zu erfüllen, wenn eine Region innerhalb derselben Rechtsordnung nicht verfügbar ist. Wenn Sie Local Zones verwenden, sollten Sie die Datenresidenzkontrollen berücksichtigen, die in Ihrer Organisation implementiert sind. Beispielsweise benötigen Sie möglicherweise ein Steuerelement, um Datenübertragungen von einer bestimmten lokalen Zone in eine andere Region zu verhindern. Weitere Informationen zur Einhaltung von Leitplanken für grenzüberschreitende Datenübertragungen finden Sie unter Bewährte Methoden zur Verwaltung der Datenresidenz bei der AWS Local Zones Verwendung von landing zone Controls
AWS Nitro-Enklaven
Betrachten Sie Ihre Datensegmentierungsstrategie aus der Perspektive der Verarbeitung, z. B. bei der Verarbeitung personenbezogener Daten mit einem Rechenservice wie Amazon Elastic Compute Cloud (Amazon EC2). Confidential Computing als Teil einer umfassenderen Architekturstrategie kann Ihnen helfen, die Verarbeitung personenbezogener Daten in einer isolierten, geschützten und vertrauenswürdigen CPU-Enklave zu isolieren. Enklaven sind separate, gehärtete und stark eingeschränkte virtuelle Maschinen. AWS Nitro Enclaves ist eine Amazon EC2 EC2-Funktion, mit der Sie diese isolierten Computerumgebungen erstellen können. Weitere Informationen finden Sie unter Das Sicherheitsdesign des AWS Nitro-Systems (Whitepaper).AWS
Nitro Enclaves stellen einen Kernel bereit, der vom Kernel der übergeordneten Instanz getrennt ist. Der Kernel der übergeordneten Instanz hat keinen Zugriff auf die Enklave. Benutzer können weder per SSH noch remote auf die Daten und Anwendungen in der Enklave zugreifen. Anwendungen, die personenbezogene Daten verarbeiten, können in die Enklave eingebettet und so konfiguriert werden, dass sie den Vsock der Enklave verwenden, den Socket, der die Kommunikation zwischen der Enklave und der übergeordneten Instanz erleichtert.
Ein Anwendungsfall, in dem Nitro Enclaves nützlich sein kann, ist die gemeinsame Verarbeitung zwischen zwei Datenprozessoren, die getrennt AWS-Regionen sind und sich möglicherweise nicht gegenseitig vertrauen. Die folgende Abbildung zeigt, wie Sie eine Enklave für die zentrale Verarbeitung, einen KMS-Schlüssel zum Verschlüsseln der personenbezogenen Daten vor dem Senden an die Enklave und eine AWS KMS key Richtlinie verwenden können, mit der überprüft wird, ob die Enklave, die die Entschlüsselung anfordert, die eindeutigen Maße in ihrem Bescheinigungsdokument enthält. Weitere Informationen und Anweisungen finden Sie unter Verwenden der kryptografischen Bescheinigung mit. AWS KMS Ein Beispiel für eine Schlüsselrichtlinie finden Sie Für die Verwendung eines Schlüssels ist eine Bescheinigung erforderlich AWS KMS in diesem Handbuch.
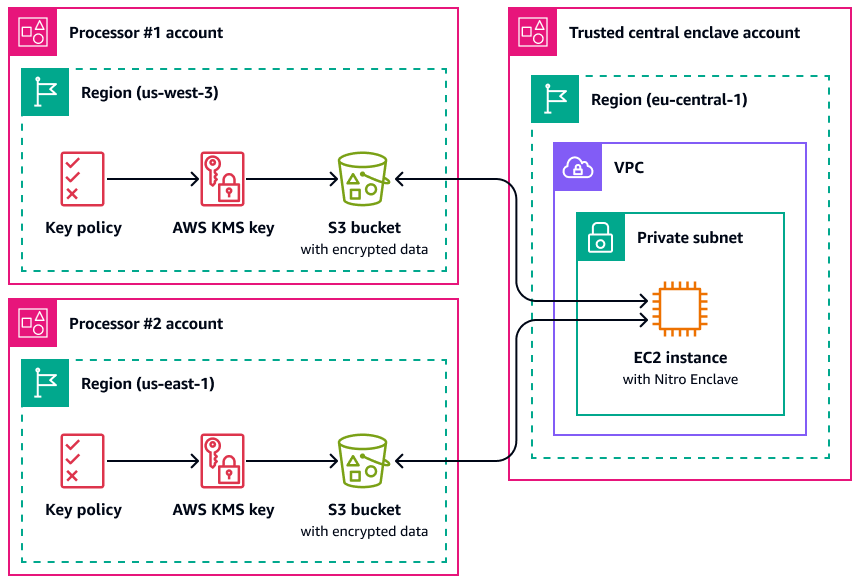
Bei dieser Implementierung haben nur die jeweiligen Datenprozessoren und die zugrunde liegende Enklave Zugriff auf die personenbezogenen Daten im Klartext. Der einzige Ort, an dem die Daten außerhalb der Umgebungen der jeweiligen Datenverarbeiter offengelegt werden, ist die Enklave selbst, die darauf ausgelegt ist, Zugriff und Manipulation zu verhindern.
AWS PrivateLink
Viele Unternehmen möchten die Offenlegung personenbezogener Daten durch nicht vertrauenswürdige Netzwerke einschränken. Wenn Sie beispielsweise den Datenschutz Ihrer gesamten Anwendungsarchitektur verbessern möchten, können Sie Netzwerke nach Datensensitivität segmentieren (ähnlich der logischen und physischen Trennung von Datensätzen, die in diesem AWS-Services und Funktionen, die bei der Segmentierung von Daten helfen Abschnitt behandelt wird). AWS PrivateLinkhilft Ihnen dabei, unidirektionale, private Verbindungen von Ihren virtuellen privaten Clouds (VPCs) zu Diensten außerhalb der VPC herzustellen. Mithilfe AWS PrivateLink können Sie dedizierte private Verbindungen zu den Diensten einrichten, die personenbezogene Daten in Ihrer Umgebung speichern oder verarbeiten. Sie müssen keine Verbindung zu öffentlichen Endpunkten herstellen und diese Daten über nicht vertrauenswürdige öffentliche Netzwerke übertragen. Wenn Sie AWS PrivateLink Dienstendpunkte für die im Leistungsumfang enthaltenen Dienste aktivieren, ist für die Kommunikation kein Internet-Gateway, kein NAT-Gerät, keine öffentliche IP-Adresse, AWS Direct Connect Verbindung oder AWS Site-to-Site VPN Verbindung erforderlich. Wenn Sie eine Verbindung AWS PrivateLink zu einem Dienst herstellen, der Zugriff auf personenbezogene Daten bietet, können Sie VPC-Endpunktrichtlinien und Sicherheitsgruppen verwenden, um den Zugriff gemäß der Datenperimeter-Definition
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) hilft Ihnen dabei, Ihre Ressourcen sicher gemeinsam zu nutzen, AWS-Konten um den betrieblichen Aufwand zu reduzieren und für Transparenz und Überprüfbarkeit zu sorgen. Bei der Planung Ihrer Strategie zur Segmentierung mehrerer Konten sollten Sie erwägen, persönliche Datenspeicher, die Sie in einem separaten, isolierten Konto speichern, gemeinsam AWS RAM zu nutzen. Sie können diese personenbezogenen Daten zu Verarbeitungszwecken an andere vertrauenswürdige Konten weitergeben. In können Sie Berechtigungen verwalten AWS RAM, die definieren, welche Aktionen für gemeinsam genutzte Ressourcen ausgeführt werden können. Alle API-Aufrufe von AWS RAM sind angemeldet CloudTrail. Sie können Amazon CloudWatch Events auch so konfigurieren, dass Sie automatisch über bestimmte Ereignisse informiert werden AWS RAM, z. B. wenn Änderungen an einer Ressourcenfreigabe vorgenommen werden.
Obwohl Sie viele Arten von AWS Ressourcen mit anderen teilen können, AWS-Konten indem Sie ressourcenbasierte Richtlinien in IAM oder Bucket-Richtlinien in Amazon S3 verwenden, AWS RAM bietet dies mehrere zusätzliche Vorteile für den Datenschutz. AWS bietet Dateneigentümern zusätzliche Transparenz darüber, wie und mit wem die Daten in Ihrem AWS-Konten Unternehmen geteilt werden, einschließlich:
-
Die Möglichkeit, eine Ressource mit einer gesamten Organisationseinheit gemeinsam zu nutzen, anstatt die Kontenlisten manuell zu aktualisieren IDs
-
Durchsetzung des Einladungsverfahrens für die Initiierung der gemeinsamen Nutzung, falls das Kundenkonto nicht Teil Ihres Unternehmens ist
-
Transparenz darüber, welche spezifischen IAM-Principals Zugriff auf die einzelnen Ressourcen haben
Wenn Sie zuvor eine ressourcenbasierte Richtlinie zur Verwaltung einer Ressourcenfreigabe verwendet haben und diese AWS RAM stattdessen verwenden möchten, verwenden Sie den API-Vorgang. PromoteResourceShareCreatedFromPolicy
Amazon SageMaker KI
Amazon SageMaker AI
SageMaker Amazon-Modellmonitor
Viele Unternehmen berücksichtigen beim Training von ML-Modellen die Datendrift. Datendrift ist eine signifikante Variation zwischen den Produktionsdaten und den Daten, die zum Trainieren eines ML-Modells verwendet wurden, oder eine signifikante Änderung der Eingabedaten im Laufe der Zeit. Datendrift kann die Gesamtqualität, Genauigkeit und Fairness von ML-Modellvorhersagen beeinträchtigen. Wenn der statistische Charakter der Daten, die ein ML-Modell während der Produktion erhält, von der Art der Basisdaten abweicht, auf denen es trainiert wurde, kann die Genauigkeit der Vorhersagen sinken. Amazon SageMaker Model Monitor kann die Qualität von Amazon SageMaker AI-Machine-Learning-Modellen in der Produktion kontinuierlich überwachen und die Datenqualität überwachen. Die frühzeitige und proaktive Erkennung von Datenabweichungen kann Ihnen dabei helfen, Korrekturmaßnahmen zu ergreifen, z. B. Modelle neu zu schulen, vorgelagerte Systeme zu prüfen oder Datenqualitätsprobleme zu beheben. Model Monitor kann die Notwendigkeit verringern, Modelle manuell zu überwachen oder zusätzliche Tools zu entwickeln.
Amazon SageMaker Clarify
Amazon SageMaker Clarify bietet Einblicke in Modellverzerrungen und Erklärbarkeit. SageMaker Clarify wird häufig während der Vorbereitung von ML-Modelldaten und in der gesamten Entwicklungsphase verwendet. Entwickler können interessante Attribute wie Geschlecht oder Alter angeben, und SageMaker Clarify führt eine Reihe von Algorithmen aus, um jedes Vorhandensein von Verzerrungen in diesen Attributen zu erkennen. Nach der Ausführung des Algorithmus erstellt SageMaker Clarify einen visuellen Bericht mit einer Beschreibung der Ursachen und Messungen möglicher Verzerrungen, sodass Sie Schritte zur Behebung der Verzerrung identifizieren können. Beispielsweise SageMaker könnten in einem Finanzdatensatz, der nur wenige Beispiele für Geschäftskredite an eine Altersgruppe im Vergleich zu anderen enthält, Ungleichgewichte gekennzeichnet werden, sodass Sie ein Modell vermeiden können, das diese Altersgruppe benachteiligt. Sie können auch bereits trainierte Modelle auf Verzerrungen überprüfen, indem Sie ihre Prognosen überprüfen und diese ML-Modelle kontinuierlich auf Verzerrungen überprüfen. Schließlich ist SageMaker Clarify in Amazon SageMaker AI Experiments integriert, um ein Diagramm bereitzustellen, das erklärt, welche Funktionen am meisten zum gesamten Vorhersageprozess eines Modells beigetragen haben. Diese Informationen könnten nützlich sein, um Ergebnisse zur Erklärbarkeit zu erzielen, und sie könnten Ihnen dabei helfen, festzustellen, ob eine bestimmte Modelleingabe mehr Einfluss auf das allgemeine Modellverhalten hat, als sie sollte.
SageMaker Amazon-Modellkarte
Amazon SageMaker Model Card kann Ihnen dabei helfen, wichtige Details zu Ihren ML-Modellen für Governance- und Berichtszwecke zu dokumentieren. Zu diesen Informationen können der Eigentümer des Modells, der allgemeine Zweck, die beabsichtigten Anwendungsfälle, die getroffenen Annahmen, die Risikobewertung eines Modells, Schulungsdetails und Kennzahlen sowie die Bewertungsergebnisse gehören. Weitere Informationen finden Sie unter Modellerklärbarkeit mit Lösungen für AWS künstliche Intelligenz und Machine Learning (AWS Whitepaper).
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler
Data Wrangler kann als Teil der Datenaufbereitung und des Feature-Engineering-Prozesses in der PRA verwendet werden. AWS Es unterstützt die Verschlüsselung von Daten im Ruhezustand und bei der Übertragung mithilfe von IAM-Rollen und -Richtlinien AWS KMS, um den Zugriff auf Daten und Ressourcen zu kontrollieren. Es unterstützt die Datenmaskierung über AWS Glue unseren Amazon SageMaker Feature Store. Wenn Sie Data Wrangler mit integrieren AWS Lake Formation, können Sie detaillierte Datenzugriffskontrollen und -berechtigungen durchsetzen. Sie können Data Wrangler sogar mit Amazon Comprehend verwenden, um personenbezogene Daten im Rahmen Ihres umfassenderen ML-Ops-Workflows automatisch aus Tabellendaten zu löschen. Weitere Informationen finden Sie unter Automatisches Redigieren von personenbezogenen Daten für maschinelles Lernen mithilfe von Amazon SageMaker Data Wrangler
Die Vielseitigkeit von Data Wrangler hilft Ihnen dabei, sensible Daten für viele Branchen zu maskieren, z. B. Kontonummern, Kreditkartennummern, Sozialversicherungsnummern, Patientennamen sowie medizinische und militärische Aufzeichnungen. Sie können den Zugriff auf sensible Daten einschränken oder sie unkenntlich machen.
AWS Funktionen, die bei der Verwaltung des Datenlebenszyklus helfen
Wenn personenbezogene Daten nicht mehr benötigt werden, können Sie den Lebenszyklus und die time-to-live Richtlinien für Daten in vielen verschiedenen Datenspeichern verwenden. Berücksichtigen Sie bei der Konfiguration von Richtlinien zur Datenspeicherung die folgenden Speicherorte, die möglicherweise personenbezogene Daten enthalten:
-
Datenbanken wie Amazon DynamoDB und Amazon Relational Database Service (Amazon RDS)
-
Amazon-S3-Buckets
-
Protokolle von und CloudWatch CloudTrail
-
Zwischengespeicherte Daten aus Migrationen in AWS Database Migration Service ()AWS DMS und Projekten AWS Glue DataBrew
-
Backups und Schnappschüsse
Mithilfe der folgenden AWS-Services Funktionen können Sie Richtlinien zur Datenaufbewahrung in Ihren AWS Umgebungen konfigurieren:
-
Amazon S3 Lifecycle — Eine Reihe von Regeln, die Aktionen definieren, die Amazon S3 auf eine Gruppe von Objekten anwendet. In der Amazon S3 Lifecyle-Konfiguration können Sie Ablaufaktionen erstellen, die festlegen, wann Amazon S3 abgelaufene Objekte in Ihrem Namen löscht. Weitere Informationen finden Sie unter Verwalten Ihres Speicher-Lebenszyklus.
-
Amazon Data Lifecycle Manager — Erstellen Sie in Amazon EC2 eine Richtlinie, die die Erstellung, Aufbewahrung und Löschung von Amazon Elastic Block Store (Amazon EBS) -Snapshots und EBS-gestützten Amazon Machine Images () automatisiert. AMIs
-
DynamoDB Time to Live (TTL) — Definieren Sie einen Zeitstempel pro Element, der festlegt, wann ein Element nicht mehr benötigt wird. Kurz nach dem Datum und der Uhrzeit des angegebenen Zeitstempels löscht DynamoDB das Element aus Ihrer Tabelle.
-
Einstellungen für die Aufbewahrung von CloudWatch Protokollen in Logs — Sie können die Aufbewahrungsrichtlinie für jede Protokollgruppe auf einen Wert zwischen 1 Tag und 10 Jahren anpassen.
-
AWS Backup— Stellen Sie Datenschutzrichtlinien zentral bereit, um Ihre Backup-Aktivitäten für eine Vielzahl von AWS Ressourcen zu konfigurieren, zu verwalten und zu steuern, darunter S3-Buckets, RDS-Datenbankinstanzen, DynamoDB-Tabellen, EBS-Volumes und vieles mehr. Wenden Sie Backup-Richtlinien auf Ihre AWS Ressourcen an, indem Sie entweder Ressourcentypen angeben oder zusätzliche Granularität bieten, indem Sie sie auf der Grundlage vorhandener Ressourcen-Tags anwenden. Prüfen und dokumentieren Sie die Backup-Aktivitäten von einer zentralen Konsole aus, um die Einhaltung der Backup-Compliance-Anforderungen zu gewährleisten.
AWS-Services und Funktionen, die bei der Segmentierung von Daten helfen
Datensegmentierung ist der Prozess, bei dem Sie Daten in separaten Containern speichern. Dies kann Ihnen dabei helfen, für jeden Datensatz differenzierte Sicherheits- und Authentifizierungsmaßnahmen vorzusehen und den Umfang der Gefährdung Ihres gesamten Datensatzes zu verringern. Anstatt beispielsweise alle Kundendaten in einer großen Datenbank zu speichern, können Sie diese Daten in kleinere, besser verwaltbare Gruppen unterteilen.
Sie können die physische und logische Trennung verwenden, um personenbezogene Daten zu segmentieren:
-
Physische Trennung — Das Speichern von Daten in separaten Datenspeichern oder das Verteilen Ihrer Daten auf separate AWS Ressourcen. Obwohl die Daten physisch getrennt sind, sind beide Ressourcen möglicherweise für dieselben Prinzipale zugänglich. Aus diesem Grund empfehlen wir, die physische Trennung mit der logischen Trennung zu kombinieren.
-
Logische Trennung — Das Isolieren von Daten mithilfe von Zugriffskontrollen. Verschiedene Jobfunktionen erfordern unterschiedliche Zugriffsebenen auf Teilmengen personenbezogener Daten. Ein Beispiel für eine Richtlinie, die eine logische Trennung implementiert, finden Sie Zugriff auf bestimmte Amazon DynamoDB-Attribute gewähren in diesem Handbuch.
Die Kombination aus logischer und physischer Trennung bietet Flexibilität, Einfachheit und Granularität bei der Erstellung identitäts- und ressourcenbasierter Richtlinien, um einen differenzierten Zugriff auf verschiedene Aufgabenbereiche zu ermöglichen. Beispielsweise kann es betrieblich komplex sein, Richtlinien zu erstellen, die verschiedene Datenklassifizierungen logisch in einem einzigen S3-Bucket trennen. Die Verwendung spezieller S3-Buckets für jede Datenklassifizierung vereinfacht die Konfiguration und Verwaltung von Richtlinien.
AWS-Services und Funktionen, die dabei helfen, Daten zu entdecken, zu klassifizieren oder zu katalogisieren
Einige Unternehmen haben noch nicht damit begonnen, ELT-Tools (Extract, Load and Transform) in ihrer Umgebung zu verwenden, um ihre Daten proaktiv zu katalogisieren. Diese Kunden befinden sich möglicherweise in einer frühen Phase der Datenermittlung und möchten besser verstehen, in welchen Daten sie speichern und verarbeiten AWS und wie sie strukturiert und klassifiziert sind. Sie können Amazon Macie verwenden, um Ihre PII-Daten in Amazon S3 besser zu verstehen. Amazon Macie kann Ihnen jedoch nicht bei der Analyse anderer Datenquellen wie Amazon Relational Database Service (Amazon RDS) und Amazon Redshift helfen. Sie können zwei Methoden verwenden, um die anfängliche Erkennung zu Beginn einer größeren Datenzuordnungsaufgabe
-
Manueller Ansatz — Erstellen Sie eine Tabelle mit zwei Spalten und so vielen Zeilen, wie Sie benötigen. Schreiben Sie in die erste Spalte eine Datencharakterisierung (z. B. Benutzername, Adresse oder Geschlecht), die sich möglicherweise im Header oder Hauptteil eines Netzwerkpakets oder in einem von Ihnen bereitgestellten Dienst befinden kann. Bitten Sie Ihr Compliance-Team, die zweite Spalte auszufüllen. Geben Sie in der zweiten Spalte „Ja“ ein, wenn die Daten als persönlich betrachtet werden, und „Nein“, wenn dies nicht der Fall ist. Geben Sie alle Arten von personenbezogenen Daten an, die als besonders sensibel gelten, z. B. Daten zu religiösen Konfessionen oder Gesundheitsdaten.
-
Automatisierter Ansatz — Verwenden Sie die von bereitgestellten Tools. AWS Marketplace Ein solches Tool ist Securiti
. Diese Lösungen bieten Integrationen, mit denen sie Daten verschiedener AWS Ressourcentypen sowie Ressourcen auf anderen Cloud-Serviceplattformen scannen und entdecken können. Viele dieser Lösungen können kontinuierlich ein Inventar von Datenbeständen und Datenverarbeitungsaktivitäten in einem zentralen Datenkatalog sammeln und verwalten. Wenn Sie sich bei der automatisierten Klassifizierung auf ein Tool verlassen, müssen Sie möglicherweise die Erkennungs- und Klassifizierungsregeln anpassen, um sie an die Definition personenbezogener Daten in Ihrem Unternehmen anzupassen.
