Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
# Best Practices
Wir empfehlen, dass Sie sich an bewährte Methoden für Speicher und Technik halten. Diese bewährten Methoden können Ihnen helfen, das Beste aus Ihrer datenzentrierten Architektur herauszuholen.
## Bewährte Speicherpraktiken für Big Data
Die folgende Tabelle beschreibt eine gängige bewährte Methode zum Speichern von Dateien für eine Big-Data-Verarbeitungslast auf Amazon S3. Die letzte Spalte ist ein Beispiel für eine Lebenszyklusrichtlinie, die Sie festlegen können. Wenn [Amazon S3 Intelligent-Tiering](https://aws.amazon.com/s3/storage-classes/intelligent-tiering/) aktiviert ist (was automatische Speicherkosteneinsparungen ermöglicht, wenn sich die Datenzugriffsmuster automatisch ändern), müssen Sie die Richtlinie nicht manuell festlegen.
| | | |
| --- |--- |--- |
| **Name der Datenschicht** | **Beschreibung** | **Beispiel für eine Lebenszyklus-Richtlinienstrategie** |
| Raw | Enthält unverarbeitete Rohdaten
**Hinweis**: Bei einer externen Datenquelle handelt es sich bei der Rohdatenebene in der Regel um eine 1:1 -Kopie der Daten. AWS Die Daten können jedoch anhand von Schlüsseln partitioniert werden, die auf AWS-Region oder Datum während des Aufnahmevorgangs basieren. | [Verschieben Sie Dateien nach einem Jahr in die Speicherklasse S3 Standard-IA.](https://docs.aws.amazon.com/AmazonS3/latest/userguide/storage-class-intro.html) Archivieren Sie die Dateien nach zwei Jahren in S3 Standard-IA in [Amazon Simple Storage Service Glacier (Amazon S3 Glacier](https://docs.aws.amazon.com/amazonglacier/latest/dev/introduction.html)).
Amazon Glacier (ursprünglicher eigenständiger, vault-basierter Service) akzeptiert ab dem 15. Dezember 2025 keine Neukunden mehr, ohne dass dies Auswirkungen auf Bestandskunden hat.
Amazon Glacier ist ein eigenständiger Service APIs , der Daten in Tresoren speichert und sich von den Speicherklassen Amazon S3 und Amazon S3 Glacier unterscheidet. Ihre vorhandenen Daten bleiben in Amazon Glacier auf unbestimmte Zeit sicher und zugänglich. Es ist keine Migration erforderlich. Für kostengünstige, langfristige Archivierungsspeicherung AWS empfiehlt sich die [Amazon S3 Glacier-Speicherklasse](https://aws.amazon.com/s3/storage-classes/glacier/), die mit S3-Bucket-Basis, voller AWS-Region Verfügbarkeit APIs, geringeren Kosten und AWS Serviceintegration ein hervorragendes Kundenerlebnis bieten. Wenn Sie erweiterte Funktionen wünschen, sollten Sie eine Migration zu Amazon S3 Glacier-Speicherklassen in Betracht ziehen, indem Sie unseren [AWS Lösungsleitfaden für die Übertragung von Daten aus Amazon S3-Depots in Amazon S3 Glacier-Speicherklassen](https://aws.amazon.com/solutions/guidance/data-transfer-from-amazon-s3-glacier-vaults-to-amazon-s3/) verwenden. |
| Stage | Enthält verarbeitete Zwischendaten, die für den Verbrauch optimiert sind
**Beispiel**: Von CSV nach Apache Parquet konvertierte Rohdateien oder Datentransformationen | Sie können Daten nach einem bestimmten Zeitraum oder gemäß den Anforderungen Ihrer Organisation löschen.
Sie können einige Datenderivate (z. B. eine Apache Avro-Transformation eines ursprünglichen JSON-Formats) nach kürzerer Zeit (z. B. nach 90 Tagen) aus dem Data Lake entfernen. |
| Analysen | Enthält die aggregierten Daten für Ihre spezifischen Anwendungsfälle in einem benutzerfreundlichen Format
**Beispiel: Apache Parquet** | Sie können Daten nach S3 Standard-IA verschieben und die Daten dann nach einem bestimmten Zeitraum oder gemäß den Anforderungen Ihres Unternehmens löschen. |
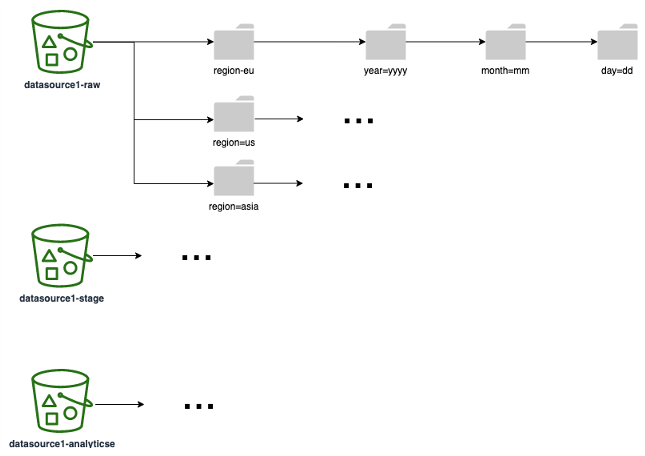
Das folgende Diagramm zeigt ein Beispiel für eine Partitionierungsstrategie (entspricht einem S3-Ordner/-Präfix), die Sie für alle Datenschichten verwenden können. Wir empfehlen Ihnen, eine Partitionierungsstrategie zu wählen, die darauf basiert, wie Ihre Daten im nachgelagerten Bereich verwendet werden. Wenn Berichte beispielsweise auf Ihren Daten basieren (wobei die häufigsten Abfragen im Bericht die Ergebnisse nach Region und Datum filtern), sollten Sie die Regionen und Daten als Partitionen einbeziehen, um die Abfrageleistung und Laufzeit zu verbessern.
## Bewährte technische Verfahren
Technische Best Practices hängen von den spezifischen AWS-Services und verarbeitenden Technologien ab, die Sie für den Entwurf Ihrer datenzentrierten Architektur verwenden. Wir empfehlen Ihnen jedoch, die folgenden bewährten Methoden zu beachten. Diese bewährten Methoden gelten für typische Anwendungsfälle der Datenverarbeitung.
| | |
| --- |--- |
| **Area** | **Bewährte Methode** |
| SQL | Reduzieren Sie die Datenmenge, die abgefragt werden muss, indem Sie Attribute auf Ihre Daten projizieren. Anstatt die gesamte Tabelle zu analysieren, können Sie die Datenprojektion verwenden, um nur bestimmte erforderliche Spalten in der Tabelle zu scannen und zurückzugeben.
Vermeiden Sie nach Möglichkeit große Verknüpfungen, da Verknüpfungen zwischen mehreren Tabellen aufgrund ihrer ressourcenintensiven Anforderungen die Leistung erheblich beeinträchtigen können. |
| Apache Spark | [Optimieren Sie Spark-Anwendungen](https://aws.amazon.com/blogs/big-data/optimizing-spark-applications-with-workload-partitioning-in-aws-glue/) mit Workload-Partitionierung in AWS Glue (AWS Big Data-Blog).
[Optimieren Sie die Speicherverwaltung](https://aws.amazon.com/blogs/big-data/optimize-memory-management-in-aws-glue/) in AWS Glue (AWS Big Data-Blog). |
| Datenbankdesign | Folgen Sie den [bewährten Architekturpraktiken für Datenbanken](https://aws.amazon.com/architecture/databases/?cards-all.sort-by=item.additionalFields.sortDate&cards-all.sort-order=desc&awsf.content-type=*all&awsf.methodology=*all) (AWS Architecture Center). |
| Bereinigung von Daten | Verwenden Sie das [serverseitige Bereinigen von Partitionen](https://docs.aws.amazon.com/glue/latest/dg/partition-indexes.html) mit dem`catalogPartitionPredicate`. |
| Skalierung | Verstehen und implementieren Sie die [horizontale Skalierung](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/wat.concept.horizontal-scaling.en.html). |