Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Temperaturskalierung
Bei Klassifikationsproblemen wird davon ausgegangen, dass die vorhergesagten Wahrscheinlichkeiten (Softmax-Ausgabe) die tatsächliche Korrektheitswahrscheinlichkeit für die vorhergesagte Klasse darstellen. Obwohl diese Annahme für Modelle vor einem Jahrzehnt vernünftig gewesen sein mag, trifft sie auf die heutigen modernen neuronalen Netzwerkmodelle nicht zu (Guo et al. 2017). Der Verlust der Verbindung zwischen den Wahrscheinlichkeiten für die Modellvorhersage und der Zuverlässigkeit von Modellvorhersagen würde die Anwendung moderner neuronaler Netzwerkmodelle auf reale Probleme wie Entscheidungssysteme verhindern. Die genaue Kenntnis des Konfidenzwerts von Modellvorhersagen ist eine der wichtigsten Einstellungen zur Risikokontrolle, die für die Entwicklung robuster und vertrauenswürdiger Anwendungen für maschinelles Lernen erforderlich sind.
Moderne neuronale Netzwerkmodelle verfügen in der Regel über große Architekturen mit Millionen von Lernparametern. Die Verteilung der Vorhersagewahrscheinlichkeiten in solchen Modellen ist oft stark verzerrt, entweder auf 1 oder 0, was bedeutet, dass das Modell zu selbstsicher ist und der absolute Wert dieser Wahrscheinlichkeiten bedeutungslos sein könnte. (Dieses Problem ist unabhängig davon, ob der Datensatz ein Klassenungleichgewicht enthält.) In den letzten zehn Jahren wurden verschiedene Kalibrierungsmethoden zur Erstellung eines Konfidenzwerts für Prognosen entwickelt. Dabei wurden Nachbearbeitungsschritte durchgeführt, um die naiven Wahrscheinlichkeiten des Modells neu zu kalibrieren. In diesem Abschnitt wird eine Kalibrierungsmethode beschrieben, die als Temperaturskalierung bezeichnet wird. Dabei handelt es sich um eine einfache, aber effektive Technik zur Rekalibrierung von Vorhersagewahrscheinlichkeiten (Guo et al. 2017). Die Temperaturskalierung ist eine Einzelparameter-Version von Platt Logistic Scaling (Platt 1999).
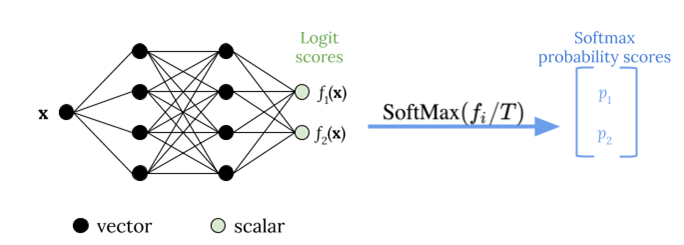
Die Temperaturskalierung verwendet einen einzigen skalaren Parameter T > 0, wobei T die Temperatur ist, um die Logit-Werte neu zu skalieren, bevor die Softmax-Funktion angewendet wird, wie in der folgenden Abbildung dargestellt. Da für alle Klassen dasselbe T verwendet wird, weist die Softmax-Ausgabe mit Skalierung eine monotone Beziehung zur unskalierten Ausgabe auf. Wenn T = 1 ist, stellen Sie die ursprüngliche Wahrscheinlichkeit mit der Softmax-Standardfunktion wieder her. In Modellen mit zu großer Sicherheit, bei denen T > 1 ist, haben die neu kalibrierten Wahrscheinlichkeiten einen niedrigeren Wert als die ursprünglichen Wahrscheinlichkeiten und sind gleichmäßiger zwischen 0 und 1 verteilt.
Die Methode, um eine optimale Temperatur T für ein trainiertes Modell zu ermitteln, besteht darin, die negative Log-Wahrscheinlichkeit für einen ausgehaltenen Validierungsdatensatz zu minimieren.
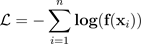
Es wird empfohlen, die Temperaturskalierungsmethode als Teil des Modelltrainingsprozesses zu integrieren: Extrahieren Sie nach Abschluss eines Modelltrainings den Temperaturwert T mithilfe des Validierungsdatensatzes und skalieren Sie dann die Logit-Werte mithilfe von T in der Softmax-Funktion neu. Basierend auf Experimenten mit Textklassifizierungsaufgaben unter Verwendung von BERT-basierten Modellen skaliert die Temperatur T normalerweise zwischen 1,5 und 3.
Die folgende Abbildung veranschaulicht die Methode der Temperaturskalierung, bei der der Temperaturwert T angewendet wird, bevor der Logit-Score an die Softmax-Funktion übergeben wird.
Die durch Temperaturskalierung kalibrierten Wahrscheinlichkeiten können ungefähr den Konfidenzwert von Modellvorhersagen darstellen. Dies kann quantitativ bewertet werden, indem ein Zuverlässigkeitsdiagramm erstellt wird (Guo et al. 2017), das die Übereinstimmung zwischen der Verteilung der erwarteten Genauigkeit und der Verteilung der Prognosewahrscheinlichkeiten darstellt.
Die Temperaturskalierung wurde auch als wirksames Mittel zur Quantifizierung der gesamten Vorhersageunsicherheit der kalibrierten Wahrscheinlichkeiten bewertet, sie ist jedoch nicht robust, um epistemische Unsicherheiten in Szenarien wie Datendriften zu erfassen (Ovadia et al. 2019). Angesichts der einfachen Implementierung empfehlen wir Ihnen, die Temperaturskalierung auf die Ausgabe Ihres Deep-Learning-Modells anzuwenden, um eine robuste Lösung zur Quantifizierung prädiktiver Unsicherheiten zu entwickeln.
