Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von DynamoDB mit Amazon S3 zum Exportieren und Importieren von Tabellendaten
Amazon DynamoDB unterstützt den Export von Tabellendaten nach Amazon S3 mithilfe der Funktion Nach S3 exportieren. Sie können Daten in den Formaten DynamoDB JSON und Amazon Ion exportieren. Exportierte Daten sind komprimiert und können mit einem Amazon S3 S3-Schlüssel oder einem AWS Key Management Service (AWS KMS) -Schlüssel verschlüsselt werden. Das Exportieren einer Tabelle verbraucht keine Lesekapazität für die Tabelle und hat auch keine Auswirkungen auf die Tabellenleistung und Verfügbarkeit während des Exports. Sie können in einen S3-Bucket innerhalb des Kontos oder in ein anderes Konto exportieren, auch in einer anderen AWS-Region. Point-in-timeRecovery (PITR) sollte in der Quelltabelle aktiviert werden, bevor Sie einen Export nach Amazon S3 durchführen.
Amazon DynamoDB hat kürzlich Unterstützung für den direkten Import von Tabellendaten aus Amazon S3 hinzugefügt, indem die Funktion Aus S3 importieren verwendet wird. Bisher mussten Sie sich nach dem Exportieren von Tabellendaten mit Export to S3 auf ETL-Tools (Extrahieren, Transformieren und Laden) verlassen, um die Tabellendaten im S3-Bucket zu analysieren, das Schema abzuleiten und in die DynamoDB-Zieltabelle zu laden oder zu kopieren. Dies war ein umständlicher Prozess und bot keine Flexibilität, wenn sich die Tabellendatenstruktur im Laufe der Zeit änderte. Außerdem fielen bei der Verwendung von ETL-Tools wie AWS Glue zusätzliche Gebühren für die Infrastruktur und für die während des Imports verbrauchte Schreibkapazität an.
Die Funktion Aus S3 importieren verbraucht keine Schreibkapazität in der Zieltabelle und unterstützt verschiedene Datenformate, darunter DynamoDB JSON, Amazon Ion und kommagetrennte Werte (CSV). Daten können auch im unkomprimierten oder komprimierten (gzip oder zstd) Format vorliegen.
Sie können Import und Export mithilfe der AWS-Managementkonsole, der AWS-Befehlszeilenschnittstelle (AWS CLI) oder der DynamoDB-API durchführen.
Das folgende Diagramm zeigt, wie die Daten von DynamoDB im Quellkonto zu einem S3-Bucket im Zielkonto und dann zur DynamoDB-Instanz des Zielkontos verschoben werden.
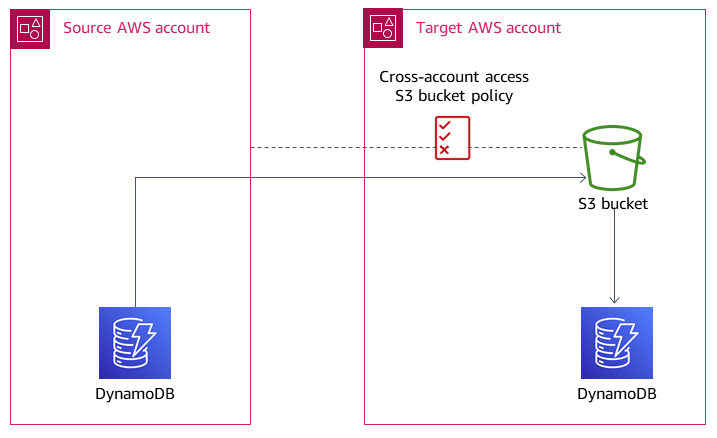
Generell sind die folgenden Schritte erforderlich, um DynamoDB-Tabellen mithilfe von Amazon S3 von einem Konto in ein anderes zu exportieren und zu importieren:
-
Erstellen Sie einen S3-Bucket im Zielkonto und fügen Sie die S3-Bucket-Richtlinie hinzu, um den Zugriff vom Quellkonto aus zu ermöglichen.
-
Wählen Sie im Quellkonto auf der DynamoDB-Konsole Export to S3 aus, wählen Sie die DynamoDB-Quelltabelle aus und geben Sie den S3-Bucket im Zielkonto an. Weitere Informationen finden Sie in der DynamoDB-Dokumentation.
-
Wählen Sie im Zielkonto in der DynamoDB-Konsole Import aus S3 und geben Sie den S3-Bucket im Zielkonto an. Weitere Informationen finden Sie in der DynamoDB-Dokumentation.
Vorteile
-
Es handelt sich um eine serverlose Lösung.
-
Die Lösung funktioniert für große Datensätze bis zu Terabyte.
-
Sie verbraucht keine bereitgestellte Kapazität in den Quell- und Zieltabellen.
-
Es hat keine Auswirkungen auf die Leistung oder Verfügbarkeit der Quelltabelle.
Nachteile
-
Der Import in vorhandene Tabellen wird von dieser Funktion derzeit nicht unterstützt. Der Importvorgang erstellt eine neue Tabelle.
