Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entkopplung von Tabellenbeziehungen während der Datenbankzerlegung
Dieser Abschnitt enthält Anleitungen zum Aufschlüsseln komplexer Tabellenbeziehungen und JOIN-Operationen bei der Zerlegung monolithischer Datenbanken. Eine Tabellenverknüpfung kombiniert Zeilen aus zwei oder mehr Tabellen auf der Grundlage einer zugehörigen Spalte zwischen ihnen. Das Ziel der Trennung dieser Beziehungen besteht darin, die hohe Kopplung zwischen Tabellen zu reduzieren und gleichzeitig die Datenintegrität zwischen Microservices aufrechtzuerhalten.
In diesem Abschnitt werden folgende Themen behandelt:
Strategie zur Denormalisierung
Die Denormalisierung ist eine Strategie für den Datenbankentwurf, bei der bewusst Redundanz eingeführt wird, indem Daten tabellenübergreifend kombiniert oder dupliziert werden. Bei der Aufteilung einer großen Datenbank in kleine Datenbanken kann es sinnvoll sein, einige Daten dienstübergreifend zu duplizieren. Wenn beispielsweise grundlegende Kundendaten wie Name und E-Mail-Adressen sowohl in einem Marketingservice als auch in einem Bestellservice gespeichert werden, entfällt die Notwendigkeit, ständig serviceübergreifende Abfragen durchzuführen. Der Marketingservice benötigt möglicherweise Kundenpräferenzen und Kontaktinformationen für die Kampagnenausrichtung, während der Bestellservice dieselben Daten für die Auftragsabwicklung und Benachrichtigungen benötigt. Dies führt zwar zu einer gewissen Datenredundanz, kann aber die Serviceleistung und Unabhängigkeit erheblich verbessern, sodass das Marketingteam seine Kampagnen durchführen kann, ohne auf Kundenanfragen in Echtzeit angewiesen zu sein.
Konzentrieren Sie sich bei der Implementierung der Denormalisierung auf Felder, auf die häufig zugegriffen wird und die Sie anhand einer sorgfältigen Analyse der Datenzugriffsmuster identifizieren. Sie können Tools wie Oracle AWR Berichte oder verwenden, um zu verstehenpg_stat_statements, welche Daten häufig zusammen abgerufen werden. Fachexperten können auch wertvolle Einblicke in natürliche Datengruppierungen geben. Denken Sie daran, dass Denormalisierung kein all-or-nothing Ansatz ist, sondern nur doppelte Daten, die nachweislich die Systemleistung verbessern oder komplexe Abhängigkeiten reduzieren.
Reference-by-key Strategie
Eine reference-by-key Strategie ist ein Datenbankentwurfsmuster, bei dem Beziehungen zwischen Entitäten durch eindeutige Schlüssel aufrechterhalten werden, anstatt die eigentlichen zugehörigen Daten zu speichern. Anstatt herkömmlicher Fremdschlüsselbeziehungen speichern moderne Microservices oft nur die eindeutigen Identifikatoren verwandter Daten. Anstatt beispielsweise alle Kundendaten in der Bestelltabelle zu speichern, speichert der Bestellservice nur die Kundennummer und ruft bei Bedarf zusätzliche Kundeninformationen über einen API-Aufruf ab. Dieser Ansatz gewährleistet die Unabhängigkeit des Dienstes und gewährleistet gleichzeitig den Zugriff auf zugehörige Daten.
CQRS-Muster
Das CQRS-Muster (Command Query Responsibility Segregation) trennt die Lese- und Schreibvorgänge eines Datenspeichers. Dieses Muster ist besonders nützlich in komplexen Systemen mit Hochleistungsanforderungen, insbesondere solchen mit asymmetrischen read/write Lasten. Wenn Ihre Anwendung häufig Daten aus mehreren Quellen kombiniert benötigt, können Sie anstelle komplexer Verknüpfungen ein spezielles CQRS-Modell erstellen. Anstatt beispielsweise Inventory Tabellen bei jeder Anfrage zu Pricing verknüpfenProduct, sollten Sie eine konsolidierte Product Catalog Tabelle verwalten, die die erforderlichen Daten enthält. Die Vorteile dieses Ansatzes können die Kosten der zusätzlichen Tabelle überwiegen.
Stellen Sie sich ein Szenario vor ProductPrice, in dem, und Inventory Dienste häufig Produktinformationen benötigen. Anstatt diese Dienste so zu konfigurieren, dass sie direkt auf gemeinsam genutzte Tabellen zugreifen, sollten Sie einen speziellen Product Catalog Dienst erstellen. Dieser Dienst unterhält eine eigene Datenbank, die die konsolidierten Produktinformationen enthält. Er dient als zentrale Informationsquelle für produktbezogene Anfragen. Wenn sich Produktdetails, Preise oder Lagerbestände ändern, können die jeweiligen Dienste Ereignisse veröffentlichen, um den Product Catalog Service zu aktualisieren. Dies sorgt für Datenkonsistenz und gewährleistet gleichzeitig die Unabhängigkeit der Dienste. Die folgende Abbildung zeigt diese Konfiguration, bei der Amazon
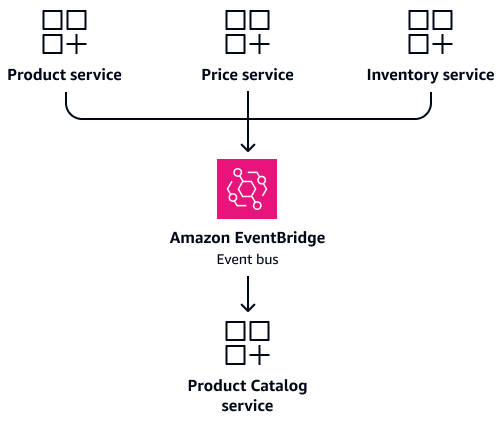
Wie im nächsten Abschnitt beschriebenEreignisbasierte Datensynchronisierung, sollten Sie das CQRS-Modell anhand von Ereignissen auf dem neuesten Stand halten. Wenn sich Produktdetails, Preise oder Lagerbestände ändern, veröffentlichen die jeweiligen Dienste Ereignisse. Der Product Catalog Service abonniert diese Ereignisse und aktualisiert seine konsolidierte Ansicht. Dies ermöglicht schnelle Lesevorgänge ohne komplexe Verknüpfungen und gewährleistet die Unabhängigkeit des Dienstes.
Ereignisbasierte Datensynchronisierung
Die ereignisbasierte Datensynchronisierung ist ein Muster, bei dem Änderungen an Daten erfasst und als Ereignisse weitergegeben werden, sodass verschiedene Systeme oder Komponenten synchronisierte Datenzustände beibehalten können. Wenn sich Daten ändern, veröffentlichen Sie ein Ereignis, um abonnierte Dienste zu benachrichtigen, anstatt alle zugehörigen Datenbanken sofort zu aktualisieren. Wenn ein Kunde beispielsweise seine Lieferadresse im Service ändert, führt ein CustomerUpdated Ereignis dazu, dass der Customer Service und der Order Service entsprechend dem Zeitplan der einzelnen Delivery Services aktualisiert werden. Bei diesem Ansatz werden starre Tabellenverknüpfungen durch flexible, skalierbare, ereignisgesteuerte Updates ersetzt. Einige Dienste verfügen möglicherweise kurzzeitig über veraltete Daten, der Nachteil besteht jedoch in einer verbesserten Systemskalierbarkeit und Dienstunabhängigkeit.
Implementierung von Alternativen zu Tabellenverknüpfungen
Beginnen Sie Ihre Datenbankzerlegung mit Lesevorgängen, da diese in der Regel einfacher zu migrieren und zu validieren sind. Sobald die Lesepfade stabil sind, können Sie die komplexeren Schreibvorgänge in Angriff nehmen. Bei kritischen Hochleistungsanforderungen sollten Sie die Implementierung des CQRS-Musters in Betracht ziehen. Verwenden Sie eine separate, optimierte Datenbank für Lesevorgänge und verwalten Sie eine weitere Datenbank für Schreibvorgänge.
Bauen Sie belastbare Systeme auf, indem Sie Wiederholungslogik für dienstübergreifende Aufrufe hinzufügen und entsprechende Caching-Ebenen implementieren. Überwachen Sie die Serviceinteraktionen genau und richten Sie Warnmeldungen für Probleme mit der Datenkonsistenz ein. Das Endziel ist nicht überall perfekte Konsistenz — es geht darum, unabhängige Dienste zu schaffen, die eine gute Leistung erbringen und gleichzeitig eine akzeptable Datengenauigkeit für Ihre Geschäftsanforderungen gewährleisten.
Der entkoppelte Charakter von Microservices führt zu folgenden neuen Komplexitäten im Datenmanagement:
-
Daten werden verteilt. Daten befinden sich jetzt in separaten Datenbanken, die von unabhängigen Diensten verwaltet werden.
-
Die Echtzeitsynchronisation zwischen Diensten ist oft nicht praktikabel und erfordert letztendlich ein Konsistenzmodell.
-
Operationen, die zuvor innerhalb einer einzigen Datenbanktransaktion stattfanden, umfassen jetzt mehrere Dienste.
Gehen Sie wie folgt vor, um diesen Herausforderungen zu begegnen:
-
Implementieren Sie eine ereignisgesteuerte Architektur — Verwenden Sie Nachrichtenwarteschlangen und die Veröffentlichung von Ereignissen, um Datenänderungen dienstübergreifend zu verbreiten. Weitere Informationen finden Sie unter Aufbau ereignisgesteuerter Architekturen
auf serverlosem Land. -
Verwenden Sie das Saga-Orchestrierungsmuster — Dieses Muster hilft Ihnen, verteilte Transaktionen zu verwalten und die Datenintegrität zwischen den Diensten aufrechtzuerhalten. Weitere Informationen finden Sie in Blogs unter Erstellen einer serverlosen verteilten Anwendung mithilfe eines Saga-Orchestrierungsmusters
. AWS -
Design for Failure — Integrieren Sie Wiederholungsmechanismen, Schutzschalter und Ausgleichstransaktionen, um Netzwerkprobleme oder Dienstausfälle zu beheben.
-
Verwenden Sie Versionsstempel — Verfolgen Sie Datenversionen, um Konflikte zu lösen und sicherzustellen, dass die neuesten Updates angewendet werden.
-
Regelmäßiger Abgleich — Implementieren Sie regelmäßige Datensynchronisierungsprozesse, catch etwaige Inkonsistenzen aufzudecken und zu korrigieren.
Szenariobasiertes Beispiel
Das folgende Schemabeispiel enthält zwei Tabellen, eine Customer Tabelle und eine Tabelle: Order
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
Das Folgende ist ein Beispiel dafür, wie Sie einen denormalisierten Ansatz verwenden könnten:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
Die neue Order Tabelle enthält denormalisierte Kundennamen und E-Mail-Adressen. Es customer_id wird auf die verwiesen, und es gibt keine Fremdschlüsseleinschränkung für die Tabelle. Customer Im Folgenden sind die Vorteile dieses denormalisierten Ansatzes aufgeführt:
-
Der
OrderService kann die Bestellhistorie mit Kundendetails anzeigen und benötigt keine API-Aufrufe an den Microservice.Customer -
Wenn der
CustomerDienst nicht verfügbar ist, ist derOrderDienst weiterhin voll funktionsfähig. -
Anfragen für die Auftragsabwicklung und Berichterstattung laufen schneller.
Das folgende Diagramm zeigt eine monolithische Anwendung, die Bestelldaten mithilfe vongetOrder(customer_id), getOrder(order_id)getCustomerOders(customer_id), und createOrder(Order
order) API-Aufrufen an den Order Microservice abruft.
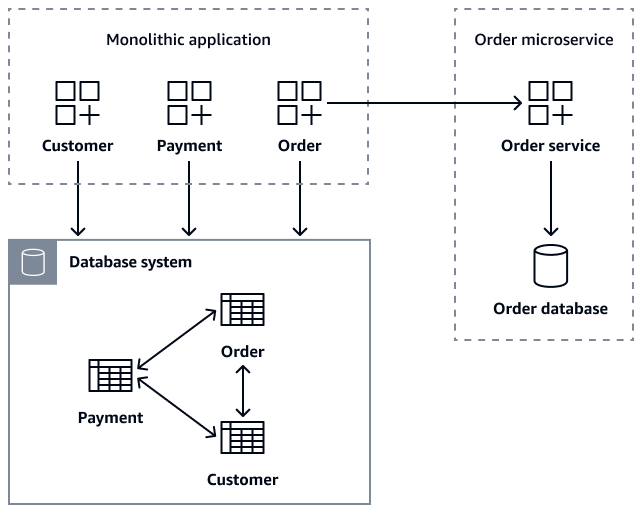
Während der Microservices-Migration können Sie die Order Tabelle in der monolithischen Datenbank als vorübergehende Sicherheitsmaßnahme beibehalten und so sicherstellen, dass die Legacy-Anwendung weiterhin funktionsfähig bleibt. Es ist jedoch entscheidend, dass alle neuen auftragsbezogenen Operationen über die Order Microservice-API geleitet werden, die ihre eigene Datenbank verwaltet und gleichzeitig als Backup in die alte Datenbank schreibt. Dieses Dual-Write-Muster bietet ein Sicherheitsnetz. Es ermöglicht eine schrittweise Migration unter Beibehaltung der Systemstabilität. Nachdem alle Kunden erfolgreich auf den neuen Microservice migriert haben, können Sie die Order Legacy-Tabelle in der monolithischen Datenbank als veraltet markieren. Nach der Zerlegung der monolithischen Anwendung und ihrer Datenbank in separate Customer und Order Microservices wird die Aufrechterhaltung der Datenkonsistenz zur größten Herausforderung.
