Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Analyse von Kohäsion und Kopplung für die Datenbankzerlegung
Dieser Abschnitt hilft Ihnen bei der Analyse von Kopplungs- und Kohäsionsmustern in Ihrer monolithischen Datenbank, um deren Zerlegung zu steuern. Zu verstehen, wie Datenbankkomponenten interagieren und voneinander abhängen, ist entscheidend für die Identifizierung natürlicher Bruchstellen, die Bewertung der Komplexität und die Planung eines schrittweisen Migrationsansatzes. Diese Analyse deckt verborgene Abhängigkeiten auf, hebt Bereiche hervor, die für eine sofortige Trennung geeignet sind, und hilft Ihnen, die Zerlegungsbemühungen zu priorisieren und gleichzeitig die Transformationsrisiken zu minimieren. Indem Sie sowohl die Kopplung als auch den Zusammenhalt untersuchen, können Sie fundierte Entscheidungen über die Reihenfolge der Trennung der Komponenten treffen, um die Systemstabilität während des gesamten Transformationsprozesses aufrechtzuerhalten.
In diesem Abschnitt werden folgende Themen behandelt:
Über Kohäsion und Kopplung
Die Kopplung misst den Grad der Interdependenz zwischen Datenbankkomponenten. In einem gut konzipierten System möchten Sie eine lose Kopplung erreichen, bei der Änderungen an einer Komponente nur minimale Auswirkungen auf andere haben. Kohäsion misst, wie gut die Elemente innerhalb einer Datenbankkomponente zusammenarbeiten, um einem einzigen, genau definierten Zweck zu dienen. Ein hoher Zusammenhalt bedeutet, dass die Elemente einer Komponente eng miteinander verwandt sind und sich auf eine bestimmte Funktion konzentrieren. Bei der Zerlegung einer monolithischen Datenbank müssen Sie sowohl den Zusammenhalt innerhalb einzelner Komponenten als auch die Kopplung zwischen ihnen analysieren. Diese Analyse hilft Ihnen dabei, fundierte Entscheidungen darüber zu treffen, wie Sie die Datenbank aufschlüsseln und gleichzeitig die Systemintegrität und Leistung aufrechterhalten können.
Die folgende Abbildung zeigt eine lose Kopplung mit hoher Kohäsion. Die Komponenten in der Datenbank arbeiten zusammen, um eine bestimmte Funktion auszuführen, und Sie minimieren die Auswirkungen von Änderungen auf eine einzelne Komponente. Dies ist der ideale Zustand.
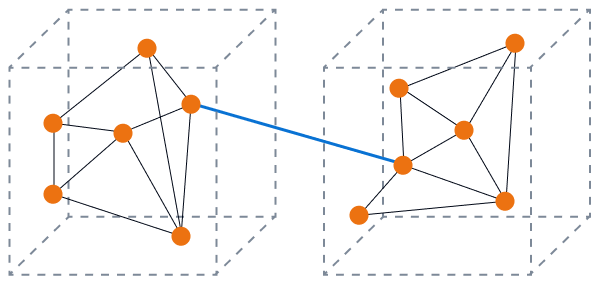
Das folgende Bild zeigt eine hohe Kopplung bei geringer Kohäsion. Die Datenbankkomponenten sind getrennt, und es ist sehr wahrscheinlich, dass sich Änderungen auf andere Komponenten auswirken.
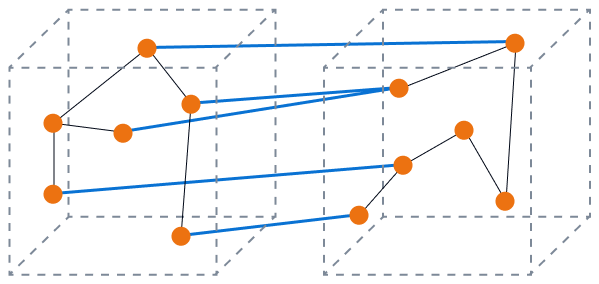
Übliche Kopplungsmuster in monolithischen Datenbanken
Es gibt mehrere Kopplungsmuster, die häufig vorkommen, wenn eine monolithische Datenbank in Microservice-spezifische Datenbanken zerlegt wird. Das Verständnis dieser Muster ist entscheidend für erfolgreiche Initiativen zur Datenbankmodernisierung. In diesem Abschnitt werden die einzelnen Muster, ihre Herausforderungen und bewährte Methoden zur Reduzierung der Kopplung beschrieben.
Kopplungsmuster bei der Implementierung
Definition: Komponenten sind auf Code- und Schemaebene eng miteinander verbunden. Wenn Sie beispielsweise die Struktur einer customer Tabelle ändernorder, wirkt sich dies aufinventory, und billing Dienste aus.
Auswirkungen der Modernisierung: Jeder Microservice benötigt ein eigenes Datenbankschema und eine eigene Datenzugriffsebene.
Herausforderungen:
-
Änderungen an gemeinsam genutzten Tabellen wirken sich auf mehrere Dienste aus
-
Hohes Risiko unbeabsichtigter Nebenwirkungen
-
Höhere Komplexität der Tests
-
Es ist schwierig, einzelne Komponenten zu modifizieren
Bewährte Verfahren zur Reduzierung der Kopplung:
-
Definieren Sie klare Schnittstellen zwischen Komponenten
-
Verwenden Sie Abstraktionsebenen, um Implementierungsdetails zu verbergen
-
Implementieren Sie domänenspezifische Schemas
Temporales Kopplungsmuster
Definition: Operationen müssen in einer bestimmten Reihenfolge ausgeführt werden. Beispielsweise kann die Auftragsabwicklung erst fortgesetzt werden, wenn die Inventaraktualisierungen abgeschlossen sind.
Auswirkungen der Modernisierung: Jeder Microservice benötigt eine autonome Datensteuerung.
Herausforderungen:
-
Aufhebung synchroner Abhängigkeiten zwischen Diensten
-
Leistungsengpässe
-
Schwer zu optimieren
-
Eingeschränkte Parallelverarbeitung
Bewährte Methoden zur Reduzierung der Kopplung:
-
Implementieren Sie nach Möglichkeit asynchrone Verarbeitung
-
Verwenden Sie ereignisgesteuerte Architekturen
-
Entwerfen Sie gegebenenfalls auf Konsistenz
Muster der Einsatzkopplung
Definition: Systemkomponenten müssen als eine Einheit bereitgestellt werden. Beispielsweise erfordert eine geringfügige Änderung der Zahlungsverarbeitungslogik eine erneute Bereitstellung der gesamten Datenbank.
Auswirkungen der Modernisierung: Unabhängige Datenbankbereitstellungen pro Service
Herausforderungen:
-
Bereitstellungen mit hohem Risiko
-
Begrenzte Einsatzhäufigkeit
-
Komplexe Rollback-Verfahren
Bewährte Verfahren zur Reduzierung der Kopplung:
-
Unterteilen Sie sich in unabhängig voneinander einsetzbare Komponenten
-
Implementieren Sie Datenbank-Sharding-Strategien
-
Verwenden Sie blaugrüne Bereitstellungsmuster
Muster für die Domänenkopplung
Definition: Geschäftsdomänen teilen sich Datenbankstrukturen und Logik. Beispielsweise teilen sich die inventory Domänen customerorder, und Tabellen und gespeicherte Prozeduren gemeinsam.
Auswirkungen der Modernisierung: Domänenspezifische Datenisolierung
Herausforderungen:
-
Komplexe Domänengrenzen
-
Es ist schwierig, einzelne Domänen zu skalieren
-
Verworrene Geschäftsregeln
Bewährte Verfahren zur Reduzierung der Kopplung:
-
Identifizieren Sie klare Domänengrenzen
-
Trennen Sie die Daten nach Domänenkontext
-
Implementieren Sie domänenspezifische Dienste
Gemeinsame Kohäsionsmuster in monolithischen Datenbanken
Es gibt mehrere Kohäsionsmuster, die häufig bei der Bewertung von Datenbankkomponenten im Hinblick auf ihre Zerlegung gefunden werden. Das Verständnis dieser Muster ist entscheidend für die Identifizierung gut strukturierter Datenbankkomponenten. In diesem Abschnitt werden jedes Muster, seine Merkmale und bewährte Verfahren zur Stärkung des Zusammenhalts beschrieben.
Funktionelles Kohäsionsmuster
Definition: Alle Elemente unterstützen direkt die Ausführung einer einzigen, genau definierten Funktion und tragen dazu bei. Beispielsweise verarbeiten alle gespeicherten Prozeduren und Tabellen in einem Zahlungsverarbeitungsmodul nur zahlungsbezogene Vorgänge.
Auswirkungen der Modernisierung: Ideales Muster für das Design von Microservice-Datenbanken
Herausforderungen:
-
Identifizierung klarer funktionaler Grenzen
-
Trennung von Komponenten mit gemischten Verwendungszwecken
-
Beibehaltung der alleinigen Verantwortung
Bewährte Verfahren zur Stärkung des Zusammenhalts:
-
Gruppieren Sie verwandte Funktionen
-
Entfernen Sie Funktionen, die nicht miteinander verwandt sind
-
Definieren Sie klare Komponentengrenzen
Sequentielles Kohäsionsmuster
Definition: Die Ausgabe eines Elements wird zur Eingabe für ein anderes. Beispielsweise fließen die Validierungsergebnisse für eine Bestellung in die Auftragsabwicklung ein.
Auswirkungen der Modernisierung: Erfordert eine sorgfältige Workflow-Analyse und Datenflussabbildung
Herausforderungen:
-
Verwaltung von Abhängigkeiten zwischen den Schritten
-
Umgang mit Ausfallszenarien
-
Aufrechterhaltung der Prozessreihenfolge
Bewährte Verfahren zur Stärkung des Zusammenhalts:
-
Dokumentieren Sie klare Datenflüsse
-
Implementieren Sie die richtige Fehlerbehandlung
-
Entwerfen Sie klare Schnittstellen zwischen den Schritten
Muster des kommunikativen Zusammenhalts
Definition: Elemente arbeiten mit denselben Daten. Beispielsweise arbeiten alle Funktionen zur Verwaltung von Kundenprofilen mit Kundendaten.
Auswirkungen der Modernisierung: Hilft bei der Identifizierung von Datengrenzen für die Trennung von Diensten, um die Kopplung zwischen Modulen zu verringern
Herausforderungen:
-
Bestimmung des Dateneigentums
-
Verwaltung des gemeinsamen Datenzugriffs
-
Wahrung der Datenkonsistenz
Bewährte Verfahren zur Stärkung des Zusammenhalts:
-
Definieren Sie klare Dateneigentumsrechte
-
Implementieren Sie die richtigen Datenzugriffsmuster
-
Entwerfen Sie eine effektive Datenpartitionierung
Prozedurales Kohäsionsmuster
Definition: Elemente werden gruppiert, weil sie in einer bestimmten Reihenfolge ausgeführt werden müssen, sie aber möglicherweise nicht funktionell zusammenhängen. Bei der Auftragsverarbeitung wird beispielsweise eine gespeicherte Prozedur, die sowohl die Auftragsvalidierung als auch die Benutzerbenachrichtigung verarbeitet, einfach deshalb gruppiert, weil sie nacheinander ablaufen, obwohl sie unterschiedlichen Zwecken dienen und von separaten Diensten verarbeitet werden könnten.
Auswirkungen der Modernisierung: Erfordert eine sorgfältige Trennung der Verfahren unter Beibehaltung des Prozessablaufs
Herausforderungen:
-
Aufrechterhaltung des korrekten Prozessablaufs nach der Zersetzung
-
Identifizierung echter funktionaler Grenzen im Vergleich zu prozeduralen Abhängigkeiten
Bewährte Verfahren zur Stärkung des Zusammenhalts:
-
Separate Verfahren, die auf ihrem funktionalen Zweck und nicht auf der Reihenfolge ihrer Ausführung basieren
-
Verwenden Sie Orchestrierungsmuster, um den Prozessablauf zu verwalten
-
Implementieren Sie Workflow-Management-Systeme für komplexe Abläufe
-
Entwerfen Sie ereignisgesteuerte Architekturen, um Prozessschritte unabhängig voneinander abzuwickeln
Temporales Kohäsionsmuster
Definition: Die Elemente sind durch zeitliche Anforderungen miteinander verknüpft. Wenn beispielsweise eine Bestellung aufgegeben wird, müssen mehrere Vorgänge gleichzeitig ausgeführt werden: Inventarprüfung, Zahlungsabwicklung, Auftragsbestätigung und Versandbenachrichtigung müssen alle innerhalb eines bestimmten Zeitfensters erfolgen, um einen konsistenten Bestellstatus aufrechtzuerhalten.
Auswirkungen der Modernisierung: In verteilten Systemen ist möglicherweise eine besondere Behandlung erforderlich
Herausforderungen:
-
Koordination der zeitlichen Abhängigkeiten zwischen verteilten Diensten
-
Verwaltung verteilter Transaktionen
-
Bestätigung des Abschlusses des Prozesses für mehrere Komponenten
Bewährte Verfahren zur Stärkung des Zusammenhalts:
-
Implementieren Sie geeignete Planungsmechanismen und Timeouts
-
Verwenden Sie ereignisgesteuerte Architekturen mit klarer Sequenzbehandlung
-
Achten Sie bei der Planung auf Konsistenz mit den Vergütungsmustern
-
Implementieren Sie Saga-Muster für verteilte Transaktionen
Logisches oder zufälliges Kohäsionsmuster
Definition: Elemente werden logisch so kategorisiert, dass sie dieselben Dinge bewirken, auch wenn sie schwache oder keine bedeutungsvollen Beziehungen haben. Ein Beispiel ist das Speichern von Kundenauftragsdaten, Lagerbestandszahlen und Marketing-E-Mail-Vorlagen in demselben Datenbankschema, da sie sich alle auf Vertriebsabläufe beziehen, obwohl unterschiedliche Zugriffsmuster, Lebenszyklusmanagement und Skalierungsanforderungen gelten. Ein anderes Beispiel ist die Kombination von Auftragszahlungsabwicklung und Produktkatalogverwaltung innerhalb derselben Datenbankkomponente, da beide Teil des E-Commerce-Systems sind, obwohl sie unterschiedliche Geschäftsfunktionen mit unterschiedlichen betrieblichen Anforderungen erfüllen.
Auswirkungen der Modernisierung: Sollte überarbeitet oder neu organisiert werden
Herausforderungen:
-
Identifizierung besserer Organisationsmuster
-
Überflüssige Abhängigkeiten aufbrechen
-
Restrukturierung von Komponenten, die willkürlich gruppiert wurden
Bewährte Verfahren zur Stärkung des Zusammenhalts:
-
Reorganisieren Sie sich auf der Grundlage echter funktionaler Grenzen und Geschäftsbereiche
-
Entfernen Sie willkürliche Gruppierungen, die auf oberflächlichen Beziehungen basieren
-
Implementieren Sie die richtige Trennung der Elemente auf der Grundlage der Geschäftskapazitäten
-
Passen Sie die Datenbankkomponenten an ihre spezifischen betrieblichen Anforderungen an
Implementierung niedriger Kopplung und hoher Kohäsion
Bewährte Methoden
Die folgenden bewährten Verfahren können Ihnen dabei helfen, eine geringe Kopplung zu erreichen:
-
Minimiert die Abhängigkeiten zwischen Datenbankkomponenten
-
Verwenden Sie klar definierte Schnittstellen für die Interaktion mit Komponenten
-
Vermeiden Sie gemeinsame Status- und globale Datenstrukturen
Die folgenden bewährten Methoden können Ihnen dabei helfen, eine hohe Kohäsion zu erreichen:
-
Gruppieren Sie zusammengehörige Daten und Vorgänge
-
Stellen Sie sicher, dass für jede Komponente eine einzige, klare Verantwortung besteht
-
Halten Sie klare Grenzen zwischen verschiedenen Geschäftsbereichen aufrecht
Phase 1: Ordnen Sie Datenabhängigkeiten zu
Ordnen Sie Datenbeziehungen zu und identifizieren Sie natürliche Grenzen. Sie können Tools verwenden, um beispielsweise die Datenbank zu visualisieren SchemaSpy
Sie können Ihre Datenbankschemas auch in eine Graphdatenbank oder in ein Jupiter Notizbuch exportieren. Anschließend können Sie Algorithmen für Clustering oder miteinander verbundene Komponenten anwenden, um natürliche Grenzen und Abhängigkeiten zu identifizieren. Andere AWS Partner Tools, wie z. B. CAST Imaging
Phase 2: Analysieren Sie Transaktionsgrenzen und Zugriffsmuster
Analysieren Sie Transaktionsmuster, um die Eigenschaften Atomizität, Konsistenz, Isolation und Dauerhaftigkeit (ACID) aufrechtzuerhalten und zu verstehen, wie auf Daten zugegriffen und wie sie verändert werden. Sie können Datenbankanalyse- und Diagnosetools wie Oracle Automatic Workload Repository (AWR)
KI-Tools wie können Ihnen helfen vFunction
Phase 3: Identifizieren Sie eigenständige Tabellen
Suchen Sie nach Tabellen, die zwei Hauptmerkmale aufweisen:
-
Hohe Kohäsion — Die Inhalte der Tabelle stehen in engem Zusammenhang
-
Geringe Kopplung — Sie haben nur minimale Abhängigkeiten von anderen Tabellen.
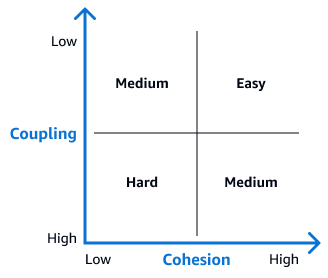
Anhand der folgenden Kopplungs- und Kohäsionsmatrix können Sie erkennen, wie schwierig es ist, die einzelnen Tabellen zu entkoppeln. Tabellen, die im oberen rechten Quadranten dieser Matrix erscheinen, eignen sich ideal für anfängliche Entkopplungsversuche, da sie sich am leichtesten trennen lassen. In einem ER-Diagramm weisen diese Tabellen nur wenige Fremdschlüsselbeziehungen oder andere Abhängigkeiten auf. Nachdem Sie diese Tabellen entkoppelt haben, gehen Sie zu Tabellen mit komplexeren Beziehungen über.
Anmerkung
Die Datenbankstruktur spiegelt häufig die Anwendungsarchitektur wider. Tabellen, die auf Datenbankebene einfacher zu entkoppeln sind, entsprechen in der Regel Komponenten, die sich auf Anwendungsebene leichter in Microservices umwandeln lassen.
