Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entwicklung serverloser KI-Architekturen
Die Umsetzung der Prinzipien der serverlosen KI in reale Systeme erfordert eine durchdachte Architektur. Ziel ist die lose Kopplung AWS-Services in modulare, intelligente Pipelines, die elastisch skalieren und in Echtzeit reagieren.
Dieser Abschnitt enthält Anleitungen zur Zusammenstellung cloudnativer KI-Systeme mithilfe AWS serverloser Dienste, einschließlich generativer KI-Orchestrierung, Echtzeit-Inferenz und Edge-Computing. Jedes Architekturmuster entspricht einem gängigen Anwendungsfall im Unternehmen, wodurch Relevanz und Anwendbarkeit gewährleistet sind.
In diesem Abschnitt
Grundlegende Architekturmuster
In einer herkömmlichen ereignisgesteuerten Anwendungsarchitektur ist das System in vier logische Schichten gegliedert, die Probleme voneinander trennen und gleichzeitig Skalierbarkeit und Reaktionsfähigkeit ermöglichen. Auf der obersten Ebene verarbeitet die Anwendungsebene Benutzerinteraktionen und Benutzeroberflächenereignisse APIs, wodurch häufig domänenspezifische Ereignisse im System ausgelöst werden. Darunter verwaltet die Orchestrierungsebene Workflows, Geschäftsregeln und die Ereignissequenz mithilfe von Tools wie Zustandsmaschinen oder serverlosen Workflows. Die Service-Schicht enthält modulare, wiederverwendbare Funktionen oder Microservices, die auf Ereignisse reagieren und die Kernlogik ausführen. Im Grunde ist die Datenschicht für Persistenz, Streaming und Eventsourcing verantwortlich. Die Datenschicht nutzt Dienste wie Datenbanken, Objektspeicher oder Ereignisprotokolle, um Änderungsereignisse auszusenden und zu verarbeiten. Zusammen unterstützen diese Schichten eine lose gekoppelte, skalierbare und wartbare Architektur, in der Ereignisse den Datenfluss über den gesamten Stack steuern.
Serverlose KI-Systeme bestehen ebenfalls aus lose gekoppelten, ereignisgesteuerten Diensten, die unabhängig voneinander skaliert, weiterentwickelt und wiederhergestellt werden können. Um diese Systeme konsistent und skalierbar zu gestalten, ist es wichtig, die Architektur als fünf verschiedene Ebenen zu betrachten. Jede Schicht erfüllt eine bestimmte Funktion und ist direkt einer eigens dafür AWS-Services vorgesehenen Ebene zugeordnet. Das folgende Diagramm zeigt jede Ebene.
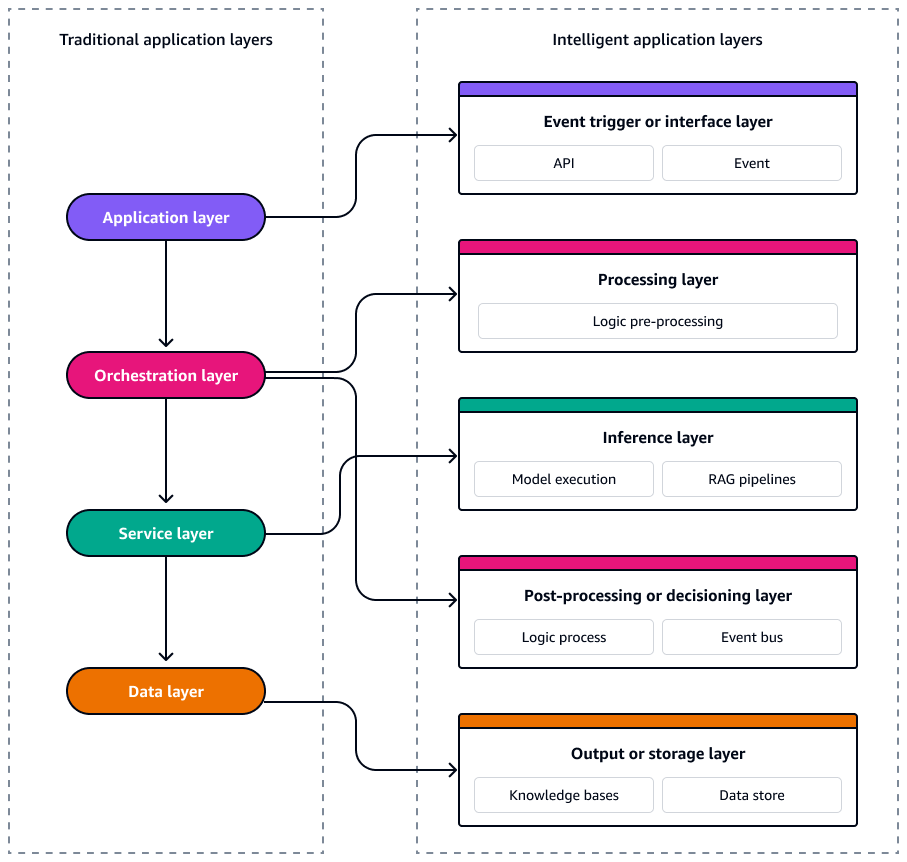
Diese fünf Ebenen bilden die Blaupause für die Entwicklung intelligenter, ereignisgesteuerter Anwendungen, die robust, beobachtbar und sowohl im Hinblick auf Kosten als auch Leistung optimiert sind.
Ereignisauslöser oder Schnittstellenebene
Der Event-Trigger oder die Schnittstellenebene ist der Einstiegspunkt zu Ihrem serverlosen KI-System. Er erfasst Benutzerinteraktionen, Systemereignisse oder Datenänderungen und gibt sie als strukturierte Ereignisse in die Architektur aus. Es ermöglicht eine asynchrone Orchestrierung und entkoppelt Upstream-Eingaben von der Downstream-Verarbeitungslogik.
Zu den Aufgaben der Event-Trigger-Ebene gehören:
-
Erfassen Sie Benutzeraktionen wie Klicks, Nachrichten und Uploads
-
Senden Sie Domain-Ereignisse oder Änderungsbenachrichtigungen aus
-
Normalisieren Sie eingehende Daten für den nachgelagerten Verbrauch
AWS-Services Zu den häufig verwendeten Layern gehören die folgenden:
-
Amazon API Gateway akzeptiert Benutzereingaben über REST oder WebSocket APIs.
-
Amazon EventBridge leitet interne oder externe Ereignisse mithilfe einer Schemaregistrierung weiter.
-
Amazon Simple Storage Service (Amazon S3) wird bei der Objekterstellung ausgelöst, z. B. beim Hochladen von Dokumenten und Mediendateien.
-
Amazon Kinesis und Amazon Managed Streaming for Apache Kafka (Amazon MSK) nehmen Streaming-Ereignisse in großem Umfang auf.
Beispiel: Eine Kundendienstanfrage, die über ein Webformular eingereicht wird, löst eine EventBridge Regel aus, die einen nachgelagerten Amazon Bedrock-Workflow für Agenten einleitet.
Verarbeitungsebene
Die Verarbeitungsschicht transformiert oder reichert Daten an, bevor sie an das KI-Modell weitergegeben werden. Sie erledigt Vorverarbeitungsaufgaben wie Eingabevalidierung, Formatierung, Metadaten-Tagging, Spracherkennung und Datenanreicherung mithilfe von Nachschlagetabellen oder externen Tabellen. APIs
Zu den Aufgaben der Verarbeitungsebene gehören:
-
Validieren und normalisieren Sie die Roheingabe.
-
Extrahieren oder fügen Sie Metadaten wie Sprache und Kunden-ID ein.
-
Routing- oder Verzweigungslogik auf der Grundlage von Datenattributen.
AWS-Services Zu den üblicherweise für diese Ebene verwendeten Funktionen gehören:
-
AWS Lambdaist eine zustandslose, ereignisgesteuerte Berechnung für Transformationslogik.
-
AWS Step Functionsorchestriert mehrstufige Vorverarbeitungsaufgaben.
-
Amazon Comprehend bietet Spracherkennung, Entitätserkennung oder Stimmungsanalyse als Teil der Vorverarbeitung.
Beispiel: Hochgeladene Versicherungsansprüche werden vor der KI-Zusammenfassung mithilfe von Lambda und Amazon Comprehend nach personenbezogenen Daten (PII) und Dokumenttypen gescannt.
Inferenzschicht
Als Herzstück des KI-Systems führt die Inferenzschicht die Inferenz für maschinelles Lernen (ML) oder Foundation Model (FM) aus. Sie kann je nach Anwendungsfall ein oder mehrere Modelle — generativ, prädiktiv oder klassifizierend — umfassen.
Die Inferenzschicht hat unter anderem folgende Aufgaben:
-
Führen Sie die ML- oder FM-Modellinferenz aus.
-
Generieren Sie Vorhersagen, Klassifizierungen oder generierte Inhalte.
-
Integrieren Sie gegebenenfalls den Kontext Retrieval Augmented Generation (RAG).
AWS-Services Zu den häufig verwendeten Layern gehören die folgenden:
-
Amazon Bedrock bietet grundlegende Model-Inferenz (Text, Bild, multimodal) von Anbietern wie Anthropic, Amazon (für Amazon Nova) und. Meta Mistral
-
Amazon SageMaker Serverless Inference führt benutzerdefinierte ML-Modelle in großem Maßstab aus.
-
Amazon Bedrock Agents bietet Argumentation und zielorientierte Orchestrierung, die auf einem Large Language Model (LLM) basiert.
Beispiel: Ein Amazon Bedrock-Agent verwendet Amazon Nova Pro, um mithilfe von RAG eine Antwort auf eine komplexe Support-Anfrage zu generieren, die auf Unternehmenswissen basiert.
Nachbearbeitungs- oder Entscheidungsebene
Die Nachverarbeitungs- oder Entscheidungsebene verfeinert die Inferenzergebnisse oder bearbeitet sie. Sie kann die Antwort formatieren, die Ausgabe protokollieren, nachgelagerte Aktionen aufrufen oder Entscheidungen auf der Grundlage von Modellsicherheit, Klassifizierungen oder externen Geschäftsregeln treffen.
Zu den Aufgaben der Nachbearbeitungs- oder Entscheidungsebene gehören:
-
Formatieren Sie die AI-Ausgabe für nachgeschaltete Systeme oder Displays.
-
Bedingte Logik oder Anruf auslösen APIs.
-
Leiten Sie angereicherte Daten zur Speicherung oder Analyse weiter.
AWS-Services Zu den häufig verwendeten Layern gehören die folgenden:
-
Lambda kann Ergebnisse formatieren, Transformationen anwenden oder aufrufen. APIs
-
Amazon Simple Notification Service (Amazon SNS) und EventBridge senden weitere Ereignisse auf der Grundlage der Modellausgabe aus.
-
Step Functions wendet eine Kettenlogik an, z. B. eskaliert die Support-Anfrage, wenn die Stimmung gleich „wütend“ ist.
Beispiel: Eine Produktempfehlung von einem LLM wird mithilfe einer Lambda-Funktion mit dem Echtzeitbestand abgeglichen, bevor die Empfehlung an den Benutzer gesendet wird.
Ausgabe- oder Speicherebene
Schließlich kümmert sich die Ausgabe- oder Speicherschicht um die Bereitstellung der Ergebnisse an Benutzer oder Systeme und speichert strukturierte Ausgaben für Prüfungen, Analysen oder Feedback-Schleifen.
Zu den Aufgaben der Ausgabe- oder Speicherschicht gehören:
-
Geben Sie KI-Ergebnisse über APIs oder an Endbenutzer zurück UIs.
-
Strukturierte Ausgaben und Protokolle beibehalten
-
In Data Lakes oder Weiterbildungs-Pipelines einspeisen.
AWS-Services Zu den häufig verwendeten Layern gehören die folgenden:
-
Amazon S3 speichert Inferenzprotokolle, Zusammenfassungen oder generierte Inhalte.
-
Amazon DynamoDB bietet Schlüsselwertspeicher mit niedriger Latenz für sitzungsspezifische KI-Ausgaben.
-
Amazon OpenSearch Service bietet indexstrukturierte Ausgaben für Such- und Analysezwecke.
-
API Gateway und WebSocket APIs liefert Rückantworten an Frontend- oder Mobilclients.
Beispiel: Eine von Amazon Bedrock generierte Zusammenfassung eines Rechtsdokuments wird in Amazon S3 gespeichert und in OpenSearch Service indexiert, um eine semantische Unternehmenssuche zu ermöglichen.
Überlegungen zum Design auf allen Ebenen
Die folgenden wichtigen Entwurfsüberlegungen und -muster gelten für alle Architekturebenen:
-
Resilienz — Jede Ebene sollte ausfallen und es unabhängig voneinander erneut versuchen (z. B. Dead-Letter-Queues (DLQs) auf Lambda).
-
Beobachtbarkeit — Senden Sie strukturierte Logs, Traces und Metriken aus jeder Phase an Amazon, um Verhaltensabweichungen CloudWatch zu erkennen.
-
Sicherheit — Verwenden Sie AWS Identity and Access Management(IAM) die Rollentrennung und AWS Key Management Service(AWS KMS) für die schichtübergreifende Datenverschlüsselung.
-
Kostenoptimierung — Verwenden Sie nach Möglichkeit die asynchrone Ausführung und wählen Sie Modelle mit der richtigen Größe aus.
-
Erweiterbarkeit — Durch den modularen Aufbau können Dienste unabhängig voneinander ersetzt oder aktualisiert werden.
Diese fünf Ebenen bilden eine modulare, skalierbare und serverlose Referenzarchitektur für KI-gestützte Workloads. AWS Jede Ebene kann unabhängig voneinander entwickelt, bereitgestellt und optimiert werden, was eine schnelle Iteration, operative Exzellenz und eine klare Trennung zwischen den einzelnen Geschäftsbereichen ermöglicht.
Durch die Verwendung dieses mehrschichtigen Musters als Entwurfsgrundlage können Unternehmen ihren Ansatz für serverlose KI standardisieren und den Weg vom Prototyp bis zur Produktion mit Zuversicht beschleunigen.
Überlegungen zum Architekturdesign
AWS Mit der serverlosen KI-Architektur können Sie intelligente Anwendungen erstellen, die modular, skalierbar und produktionsfähig sind. Ganz gleich, ob Sie Modelle am Netzwerkrand einsetzen, mehrstufige Inferenz-Pipelines orchestrieren oder generative KI-Assistenten entwickeln — sie AWS-Services können die nächste Generation von KI-nativen Anwendungen unterstützen.
Beachten Sie bei der Entwicklung einer serverlosen KI-Architektur die folgenden zentralen Designschwerpunkte und bewährten Methoden:
-
Sicherheit — Verwenden Sie fein abgestufte IAM-Rollen, verschlüsseln Sie Eingabeaufforderungen und Ausgaben und schränken Sie den API-Zugriff ein.
-
Beobachtbarkeit — Integrierte und benutzerdefinierte Protokolle für CloudWatch jede AWS X-Ray Pipeline-Phase.
-
Skalierbarkeit — Verwenden Sie nur serverlose Komponenten wie Lambda, Amazon Bedrock und SageMaker Serverless Inference.
-
Latenz — Nutzen Sie Lambda @Edge, bereitgestellte Parallelität oder asynchrone Inferenz.
-
Modularität — Entwerfen Sie Pipelines mithilfe von Ereignisauslösern und isolierten Funktionen für jede Aufgabe.
-
Wiederverwendbarkeit — Parametrisieren Sie Eingabeaufforderungen, verwenden Sie gemeinsam genutzte Lambda-Ebenen und entkoppeln Sie Logik mithilfe von Step Functions.
