Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Arbeitsablauf für Evaluatoren und Reflect-Refine-Schleifen
Dieser Workflow bietet eine Feedback-Schleife, in der ein LLM ein Ergebnis generiert und ein anderer das Ergebnis bewertet oder kritisiert. Dies fördert Selbstreflexion, Optimierung und iterative Verbesserungen.
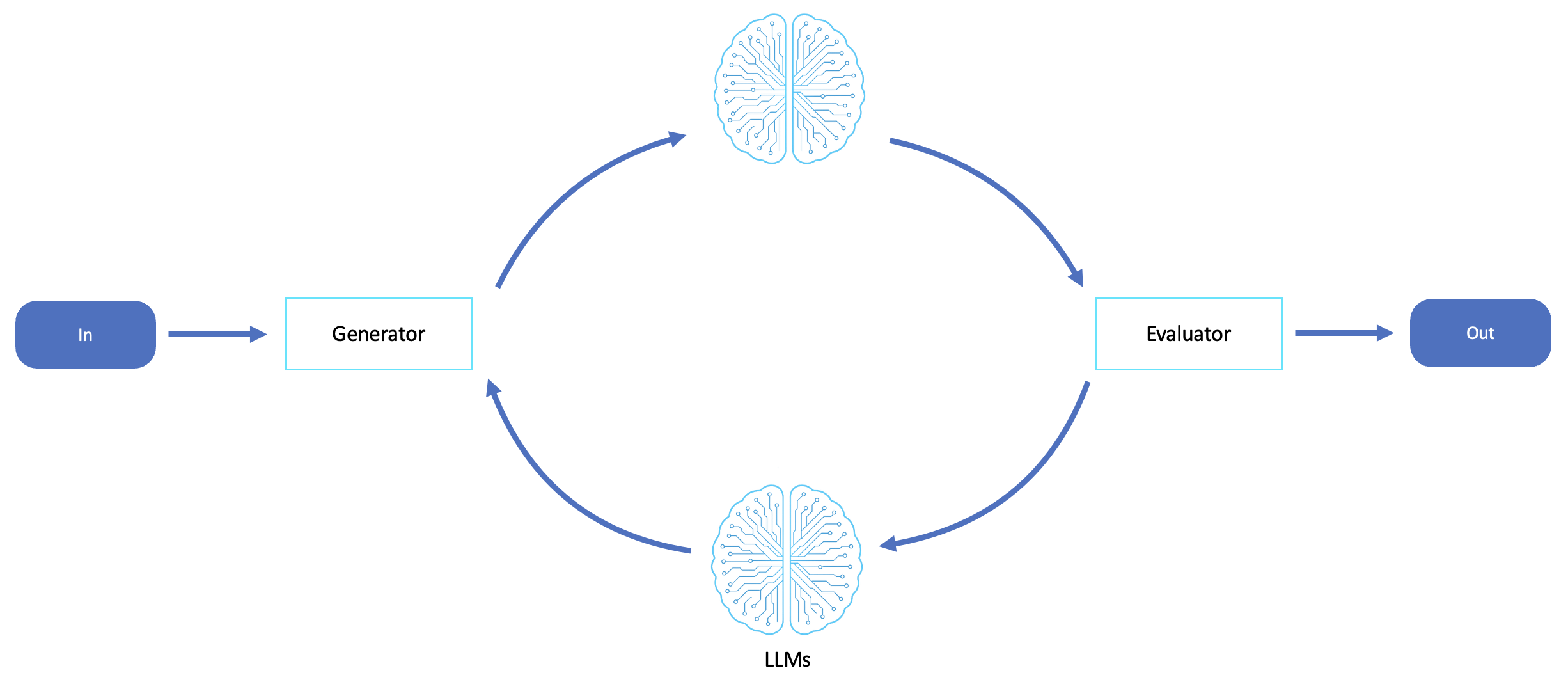
Der Arbeitsablauf für Evaluatoren ist ideal für Szenarien, in denen Qualität, Genauigkeit und Ausrichtung der Ergebnisse wichtig sind und in denen die Generierung in einem Durchgang unzuverlässig oder unzureichend ist. Dieser Workflow eignet sich hervorragend, wenn Agenten ihre Ergebnisse selbst kritisieren, iterieren und verfeinern müssen — entweder, um einen höheren Korrektheitsstandard zu erreichen oder um auf der Grundlage von Feedback verbesserte Alternativen zu untersuchen.
Dieser Workflow ist besonders effektiv, wenn:
-
Das Ergebnis umfasst subjektive Qualitätskennzahlen (z. B. Stil, Ton und Lesbarkeit) oder objektive Kriterien (z. B. Richtigkeit, Sicherheit und Leistung).
-
Der Mitarbeiter muss Kompromisse abwägen, Einschränkungen abwägen oder auf ein Ziel hin optimieren.
-
Sie benötigen integrierte Redundanz und Qualitätssicherung, insbesondere in regulierten, kundenorientierten oder kreativen Bereichen.
-
Human-in-the-loop Eine Überprüfung ist teuer oder nicht verfügbar, und eine unabhängige Validierung ist erwünscht.
Dieser Workflow wird für die Generierung von Inhalten, die Codesynthese und -überprüfung, die Durchsetzung von Richtlinien, die Überprüfung der Ausrichtung, die Anpassung von Anweisungen und die RAG-Nachbearbeitung verwendet. Er eignet sich auch für Mitarbeiter, die sich selbst verbessern, da kontinuierliches Feedback dazu beiträgt, im Laufe der Zeit bessere Antworten zu entwickeln, um vertrauenswürdige, autonome Entscheidungsschleifen aufzubauen.
Häufige Anwendungsfälle
-
Agenten im roten Team im Vergleich zu Agenten mit blauem Team
-
Agenten, die Code oder Pläne generieren, auswerten und überarbeiten
-
Qualitätssicherung, Erkennung von Halluzinationen und Durchsetzung von Stilen
Capabilities
-
Unterstützt die entkoppelte Generierung und Auswertung mithilfe verschiedener Modelle (z. B. Claude für die Generierung und Mistral für die Bewertung)
-
Feedback wird strukturiert und verwendet, um zu überarbeiteten Ergebnissen zu gelangen
-
Unterstützt mehrere Iterationen oder Konvergenzschwellenwerte
